
ElasticSearch性能原理拆解
逐層拆分ElasticSearch的概念
-
Cluster:集群,Es是一個可以橫向擴展的檢索引擎(部分時候當作存儲數據庫使用),一個Es集群由一個唯一的名字標識,默認為“elasticsearch”。在配置文件中指定相同的集群名,Es會將相同集群名的節點組成一個集群。
-
Node:節點,集群中的任意一個實例對象,是一個節點
-
Index:索引,存放相同類型數據的一個集合,索引有唯一的名字,相比于關系型數據庫,可以理解為一個表(6.0.0廢除type之后)
-
Shard:分片,物理存儲單位,創建一個索引時可以指定分成多少個分片來存儲。每個分片本身也是一個功能完善且獨立的“索引”,可以被放置在集群的任意節點上。
-
Replication:副本,對數據的備份,主要針對分片進行備份,即分片的備份
-
Document:文檔,具體存儲的數據(json結構)
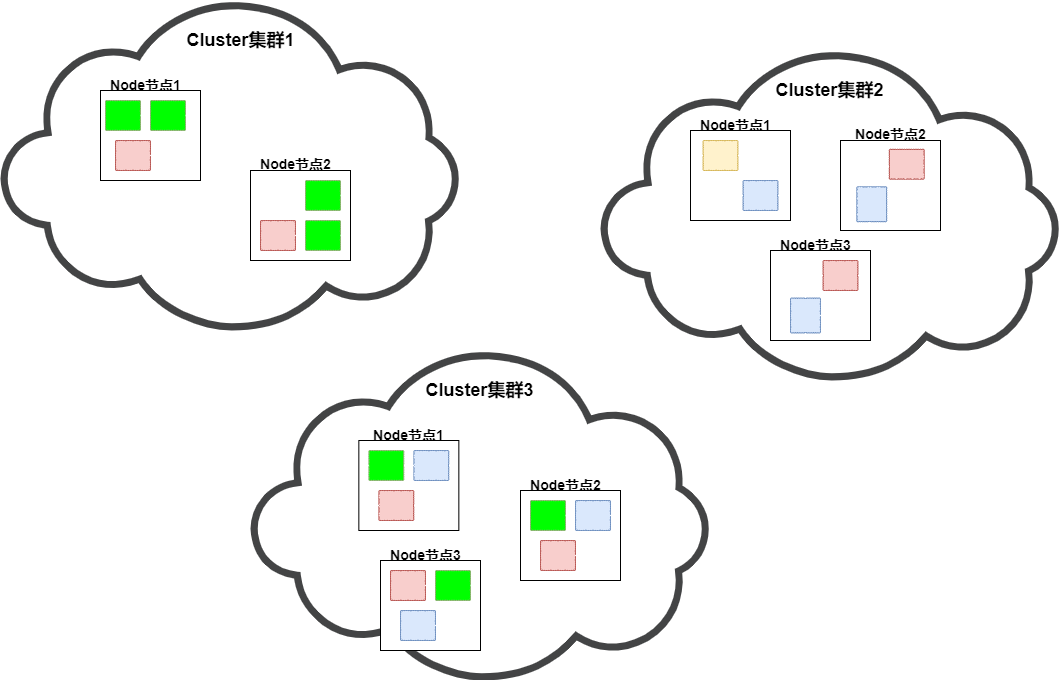
如上圖,每個云朵代表一個Es集群Cluster,集群中由一個個的Es實例Node構成,每個Es實例中存放著一個個的彩色方塊(Shard),同一個集群中相同顏色的方塊(shard)構成一個索引(index)
索引和分片、副本
實際上,索引是一個抽象的邏輯概念,使用時,我們面向的是索引(Index),只需要指定索引名即可。索引背后真正的實體是分片(Shard)。
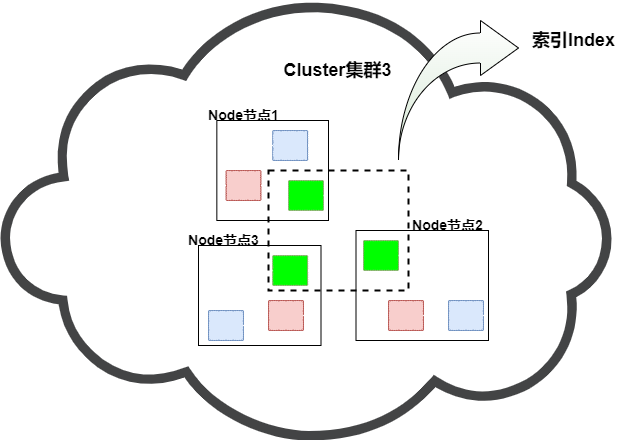
同一集群中,同一索引(Index)可能由多個分片(Shard)組成,這些Shard會分布在不同的節點(Node)中;而副本(Replication)則可以理解為一種特殊的分片,實際上數據是在一個個的分片上的,而副本的主要職責是對分片進行備份,以滿足Es的穩定性。當副本數設置為1時,則代表著每個分片都會有一個副本,且副本中的內容與分片一樣,肩負數據備份以及維穩責任。
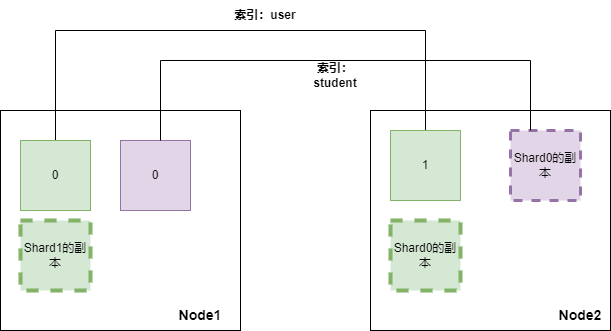
例如我們在2個節點的集群上創建一個名為user的索引和student索引,user索引設置2個分片1個副本,student索引設置1個分片1個副本;那么user索引的兩個shard會各自得到一個副本,副本和shard的內容一致,且均勻的分布在兩個節點上(Es會根據相應的策略來盡可能保證分片和相應的副本不在同一節點中,且保證每個節點的數據都是完整的)。這樣如果當Node1節點崩壞,對于user索引的查詢,會由節點2的 shard1和shard0的副本來承擔,且shard1和shard0的副本的數據之和是一個完整user的數據(等同于shard0和shard1)。
Segment
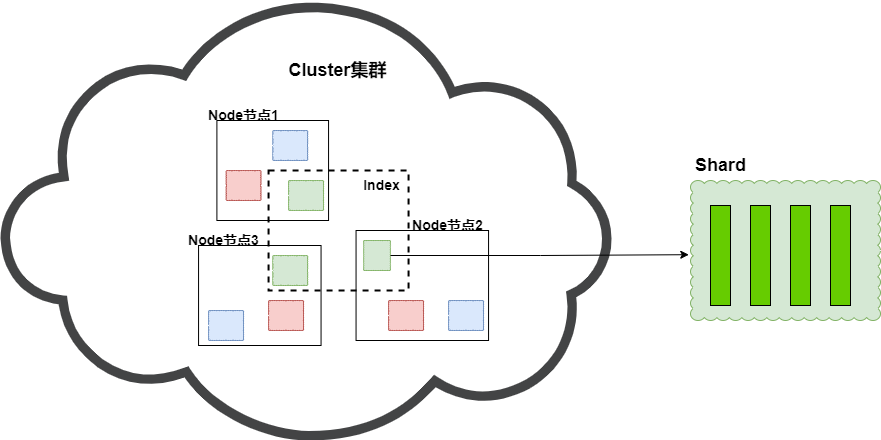
所以對于es來說,分片(shard)才是數據真正的載體,每一個Shard本質上是一個Lucene的索引(Lucene Index)。
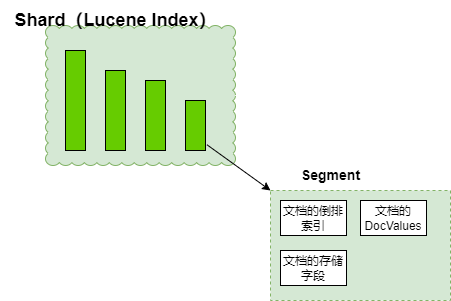
每個Lucene Index(Es的Shard) 是由多個Segment構成 ,Segement才是Lucene和Es查詢性能的核心,Segment主要承載三部分內容:
-
Inverted Index
-
Stored Fields
-
Document Values
Inverted Index(倒排索引)
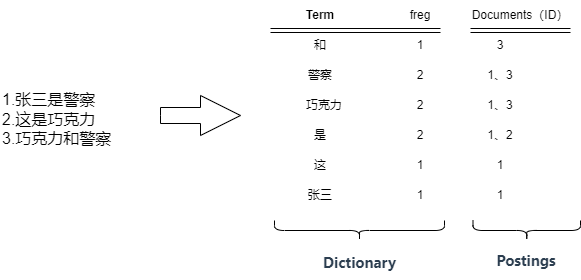
Segment中最重要的就是倒排索引,也是Es能夠快速檢索的根本,它是Segment基于存儲的數據抽離出來的一個能夠快速檢索的數據結構,一個倒排索引的結構主要由一個有序的數據字典Dictionary(包括單詞Term和它出現的頻率)和 單詞Term對應的Postings(文檔的id或位置)組成:
對于倒排索引,Es中是根據字段不同類型進行不同的策略:
-
Text 字段:
- 這些字段用于全文搜索。
- 它們會被分析(分詞),并創建倒排索引。
- 可以包含多個詞項,支持全文搜索和復雜查詢。
-
Keyword 字段:
- 這些字段用于結構化搜索,如過濾、排序、聚合。
- 它們不會被分析,而是以整個字段的值存儲。
- 每個不同的字段值都會在倒排索引中擁有一個獨立的條目。
-
Numeric 字段(如 integer, float, double 等):
- 用于數值搜索,如范圍查詢或數值排序。
- 這些字段的值通常不會被倒排索引,除非明確設置為可搜索。
-
Date 字段:
- 用于日期和時間的搜索。
- 類似于數值字段,它們的值通常不會被倒排索引,除非明確設置為可搜索。
-
Boolean 字段 和 Binary 字段:
- 用于存儲布爾值或二進制數據。
- 通常不會被倒排索引
構建倒排索引主要根據文檔字段的類型主要為text,構建倒排索引的過程是:
- 文檔分析:提取文檔中的文本內容,通常包括標題和上下文。
- 詞項提取:從文本中提取單詞或詞組(分詞器)。
- 詞項標準化:對提取的詞項進行標準化處理,比如轉小寫、去除標點符號、去除停用詞等(分詞器)。
- 詞項索引:為每個詞項分配一個唯一的詞項ID。
- 構建倒排表:為每個詞項創建倒排表,記錄詞項在文檔中的位置和頻率。
在Elasticsearch中,每個字段的倒排索引是獨立的,這意味著對于每個字段,Elasticsearch都會維護一個單獨的倒排表,該倒排表包含了該字段中詞項的文檔映射信息。
Stored Fields(存儲字段)
在索引文檔時,Es是會保存原始內容的,原始文檔內容在Es中表現為JSON, 而使用Es時,多是基于一個JSON中的某幾個字段進行檢索,大部分情況是不需要原始JSON內容的,但是若無特殊指定,Es每次檢索是需要把完整的JSON在查詢結果中通過_source進行攜帶:
{ "_index": "ariticle", "_type": "_doc", "_id": "1", "_version": 1, "_seq_no": 0, "_primary_term": 1, "found": true, "_source": { //不進行查詢指定,默認所有字段通過_source返回 "user": "張三", "title": "這是一個示例文章", "context": "這是文章中的上下文以及具體的文章內容XXX" } }
大批量的字段返回,除造成了額外的網絡傳輸消耗外,在Es內部,也需要對整個文檔進行序列化,造成資源浪費。
Stored Fields(存儲字段)是一種特殊的字段類型,可以在文檔中指定多個字段并將字段的原始內容進行額外存儲,形成一個和_source平級的內容,檢索時不需要序列化整個文檔,直接讀取額外的存儲空間內容即可。
使用方法是在設計索引mapping時通過store屬性進行字段指定。
使用 store Fields后,可將指定的字段額外被Segment存儲一份,檢索時直接讀取
//在索引創建時就固定常用哪些字段 { "ariticle": { "aliases": { }, "mappings": { "_doc": { "properties": { "title": { //默認沒有store屬性,默認值就是false "type": "text", }, "context": { //默認沒有store屬性,默認值就是false "type": "text" }, "user": { //明確指定store屬性為true "type": "keyword", "store": true } } } } } //同樣的查詢 { "query": { "match_all": {} }, "from":0, "size":10 } //返回結果 { "_index": "ariticle", "_type": "_doc", "_id": "1", "_version": 1, "found": true, "fields": { //此時多了名稱為fields的字段,并且沒有了_source "user": [ //user的stroe屬性設置為true,因此顯示在結果中 "張三" ] } }
事實上不論設不設置store屬性為true,Elasticsearch都是會把原始文檔進行存儲的,當store為false時(默認配置),這些field只存儲在"_source" field中,我們進行檢索時,通過DSL來控制_source中返回的字段原文內容;但是當使用了store Fields時,會對相應字段的內容多存儲一份,檢索時針對使用了store Fields的字段,不需要序列化整個文檔,相比通過指定返回字段查詢效率會快很多,代價就是需要額外的存儲一份內容,且內容在定義時就固定,不如在DSL中使用 _source 指定內容靈活。
Document Values
Document Values主要用于 排序、聚合、腳本索引中,Document Values對數據內容進行列式存儲,便于快速進行 sort、aggs操作;
這里Docvalus是相當于倒排索引的正排索引,它作用于除Text類型之外的類型字段,倒排索引的優勢 在于查找包含某個項的文檔,而對于從另外一個方向的相反操作并不高效,即:確定哪些項是否存在單個文檔里。這種場景下,就需要類似Mysql那種列式存儲,構建一個正排索引
Doc Terms ----------------------------------------------------------------- Doc_1 | brown, dog, fox, jumped, lazy, over, quick, the Doc_2 | brown, dogs, foxes, in, lazy, leap, over, quick, summer Doc_3 | dog, dogs, fox, jumped, over, quick, the -----------------------------------------------------------------
DocValues是在索引時與倒排索引同時生成的,并且是不可變的,需要持久化到磁盤中。Doc values 是不支持對需要分詞的字段進行列存儲的(例如text),然而,這些字段仍然可以使用聚合,是因為使用了fielddata 的數據結構。與 doc values 不同,fielddata 構建和管理 100% 在內存中,常駐于 JVM 內存堆。
Fielddata默認是不啟用的,因為text字段比較長,一般只做關鍵字分詞和搜索,很少拿它來進行全文匹配和聚合還有排序,因為大多數這種情況是無意義的,一旦啟用將會把text都加載到內存中,那將帶來很大的內存壓力,導致出現內存熔斷現象(circuit breaker)。
它通過內部檢查(字段的類型、基數、大小等等)來估算一個查詢需要的內存。它然后檢查要求加載的 fielddata 是否會導致 fielddata 的總量超過堆的配置比例。如果估算查詢大小超出限制,就會觸發熔斷,查詢會被中止并返回異常。
fielddata的內存配置在elasticsearch.yml中
indices.breaker.fielddata.limit fielddata級別限制,默認為堆的60% indices.breaker.request.limit request級別請求限制,默認為堆的40% indices.breaker.total.limit 保證上面兩者組合起來的限制,默認堆的70%
Es的緩存
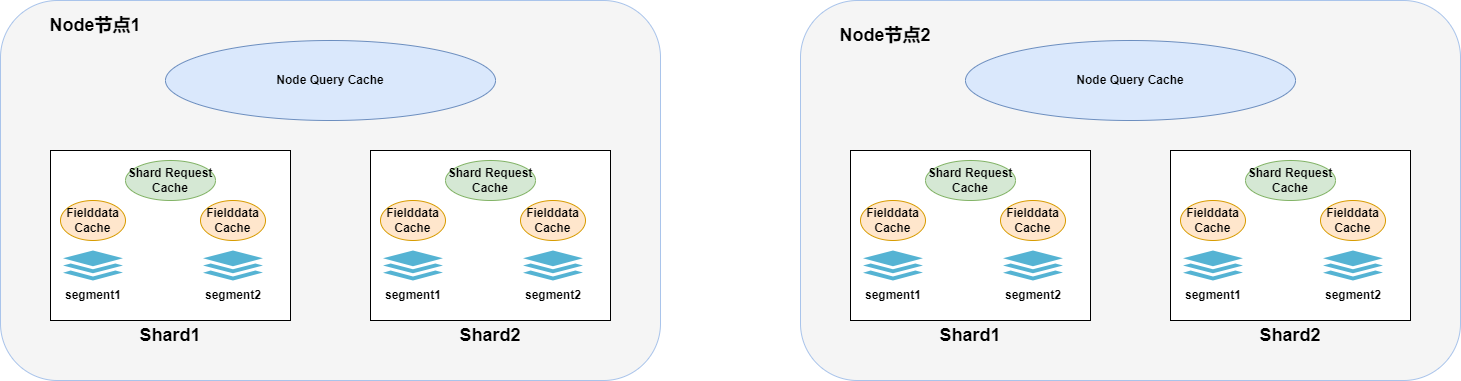
ElasticSearch在查詢時涉及其自身JVM的緩存一共分為三類:
-
Node Query Cache:
- 節點級別的緩存,被所有分片共享。
- 主要用于緩存過濾器的執行結果,通常是壓縮過的bitset,對應滿足查詢條件的文檔ID列表。使用term精確查詢某個值時或者bool配合filter查詢時會觸發
- Node Query Cache 會在底層的段(segment)發生變更時自動使緩存失效,以確保查詢結果的準確性
- 通過elasticsearch.yml配置來控制:
indices.queries.cache.size: 控制查詢緩存的內存大小,默認為節點堆內存的10%。indices.queries.cache.count: 控制緩存的總數量,默認值通常是10000。
-
Shard Request Cache :
- 分片級別的緩存。
- 多使用于聚合(aggs)時,只會緩存DSL查詢中參數
size=0的請求,以完整DSL為緩存鍵,不會緩存hits,但會緩存hits.total以及聚合信息。 - 緩存的生命周期是一個
refresh_interval,即在默認情況下每1秒鐘失效一次。 - 通過elasticsearch.yml配置來控制:
index.requests.cache.enable: 控制是否啟用分片級別的緩存,默認為true。indices.requests.cache.size: 控制請求緩存在JVM堆中的百分比,默認為1%。indices.requests.cache.expire: 配置緩存過期時間,單位為分鐘。
-
Fielddata Cache :
- 分段級別的緩存。
- 用于存儲已分析字段(analyzed fields)的字段數據,如果該字段是
text類型或者沒有為該字段設置doc_values,對于該字段聚合、排序或者腳本訪問時會緩存。 - 一旦觸發
Fielddata加載到內存中,它會保留在那里,直到相關段被刪除或更新。 - 通過es配置文件指定:
indices.fielddata.cache.size: 控制字段數據緩存的大小,默認不限制。indices.breaker.fielddata.limit: 設置 Fielddata 斷路器限制大小,默認為60%的JVM堆內存。
以上為查詢時常用的緩存,多為Es本身JVM的內存進行劃分和使用,另外Es在寫入時還會使用一定的SystemCache,如Recycler Cache、Warmer Cache等。
ElasticSearch的文檔索引過程
集群視角索引文檔
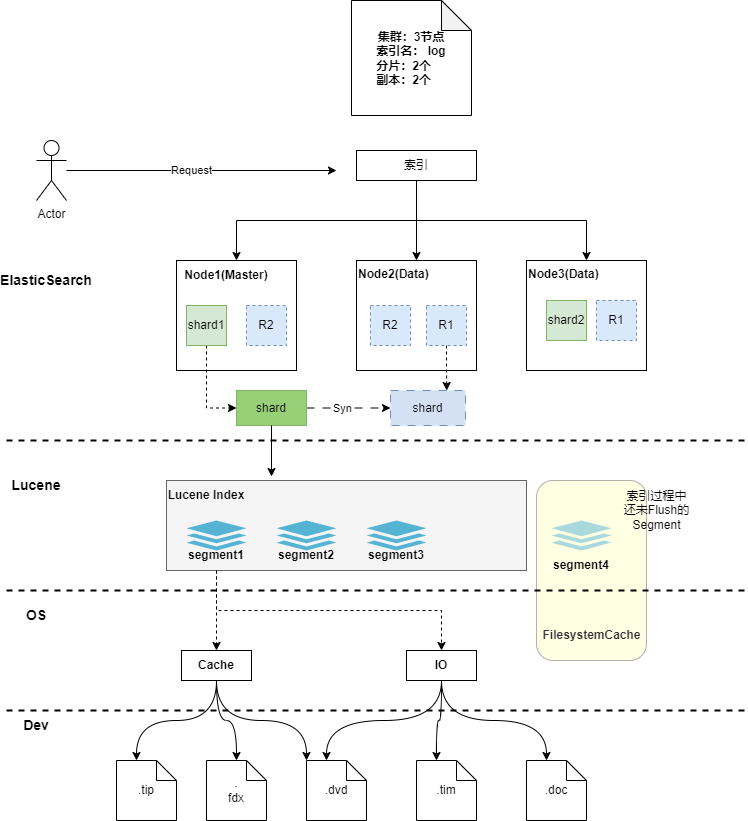
一次新增文檔(索引文檔),在集群視角的流程:
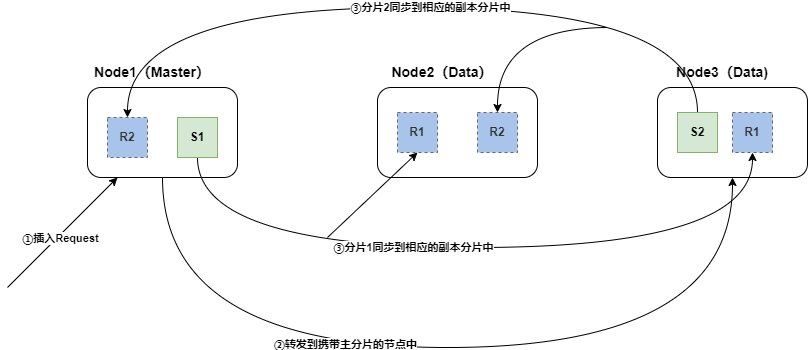
- 客戶端向Es服務(集群)發送新增數據請求,請求首先到達Master節點
- Master節點為每個節點創建一個批量請求,并將這些請求并行轉發到每個包含主分片的節點上。
- 每個節點上的主分片接收到插入請求,主分片進行數據索引并行轉發新文檔(或刪除)到相應的副本分片(跨節點)。 一旦所有的副本分片報告所有操作成功,該節點將向Master節點報告成功,協調節點將這些響應收集整理并返回給客戶端。
分片內部索引時具體在做什么
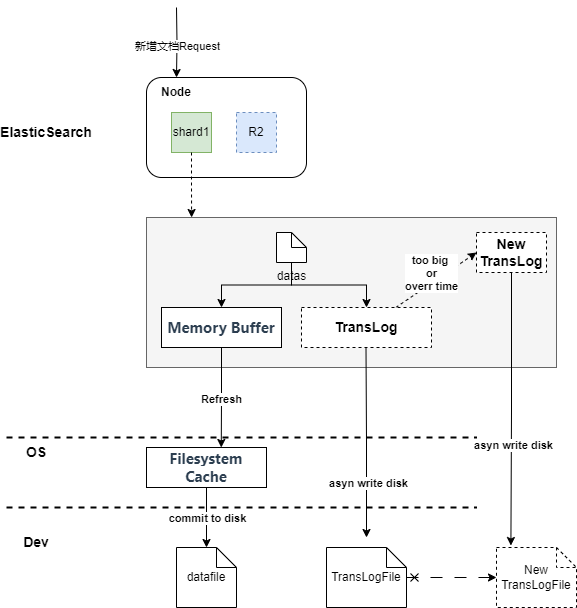
- 當分片所在的節點接收到數據新增請求后,在分片內部,首先會將數據請求寫入到Memory Buffer,然后定時(默認是每隔1秒,可在索引中設置)寫入到Filesystem Cache(系統緩存),從Momery Buffer到Filesystem Cache的過程就是常說的refresh;這也是為什么對于Es的內存配置時不要過大,要預留給操作系統足夠的內存空間的原因,因為這里十分依賴系統內存;
- 同時為保證數據的可靠性,防止數據在Momery Buffer和Filesystem Cache中丟失,Es額外追加了TransLog機制,到達分片的新增請求,數據同時會異步寫入 TransLog 一份(磁盤記錄)。
- 當TransLog增長過大(默認為512M)或到達配置的時間時(默認30分鐘),FilesystemCache中的內容被寫入到磁盤中,然后舊的TransLog將被刪除并開始一個新的TransLog。 這個過程被稱作Flush
refresh過程中segment的活動
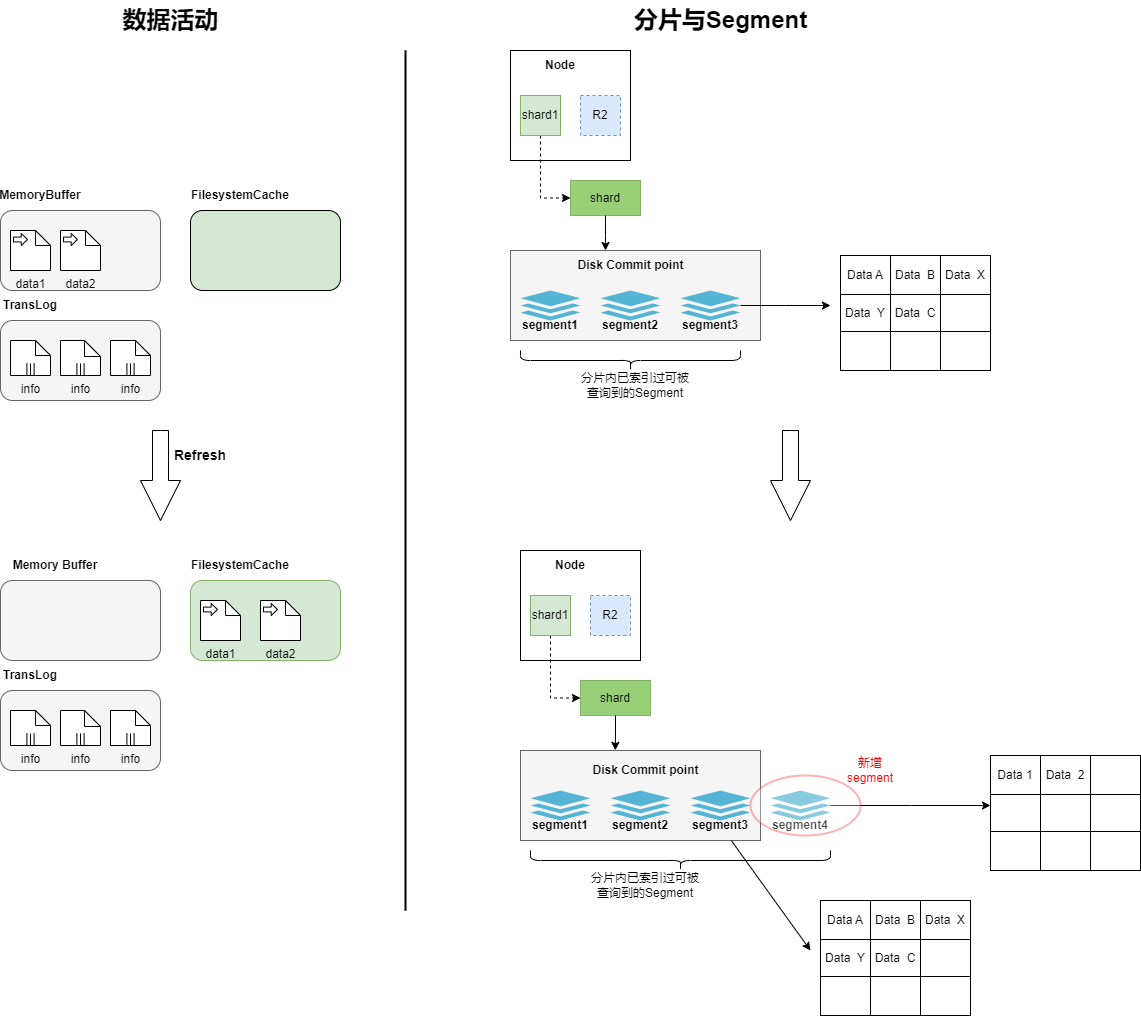
文檔數據被寫入后,首先進入到Memory Buffer和TransLog中,此時shard中的Segment還是之前已經穩定的數據,新寫入的文檔還沒有形成Segment,無法被Es查到。根據 index.refresh_interval 設置 的refresh (沖刷)間隔時間,數據開始進行refresh,Memory Buffer中的文檔被內容分析、分詞,形成一個新的Segment,然后Memory Buffer開始清空,refresh后新生成的Segment是暫存在FilesystemCache中的,所以從存儲上看,新的文檔從Memory Buffer 轉移到了 Filesystem Cache,到此,新插入的文檔數據才可以被Es查詢到
flush過程中segment的活動
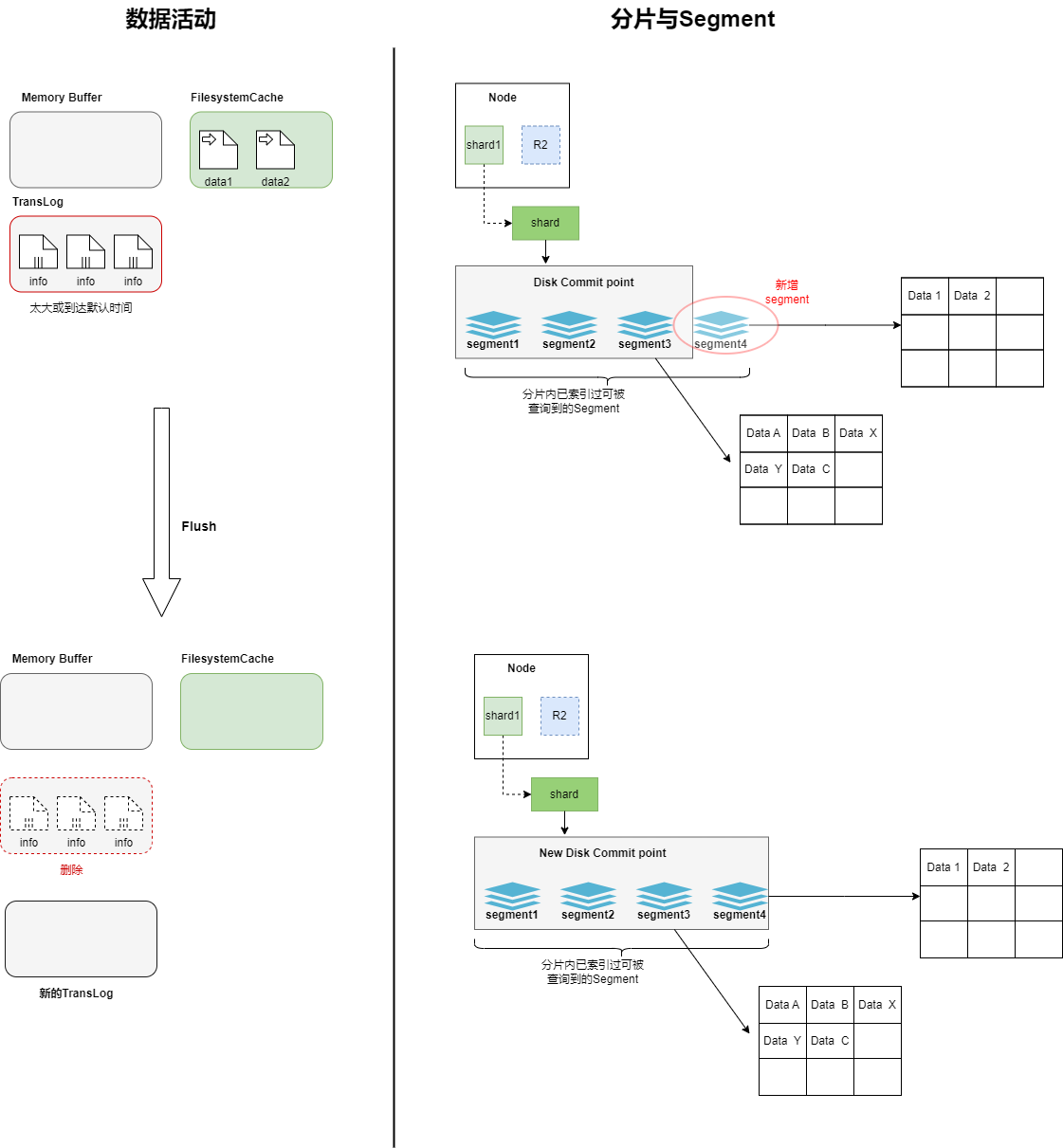
隨著TransLog越來越大,會觸發Flush過程,在這個過程中,FilesystemCache中的內容會被寫入到磁盤中,段的fsync將創建一個new commit point,此時清空Filesystem Cache,然后刪除TransLog,再生成一個新的TransLog,記錄后續的內容
segement的 merge

由于refresh流程每次都會創建一個新的段,refresh的頻繁會導致短時間內的段數量暴增。而段數目太多會帶來較大的麻煩。 每一個段都會消耗文件句柄、內存和cpu運行周期。而且每個搜索請求都必須輪流檢查每個段,所以段越多,搜索也就越慢。于是Es在后他就需要不定期的合并Segment,以減少Segment的數量。
合并進程選擇一小部分大小相似的段,并且在后臺將它們合并成為更大的段(過程中并不會中斷索引和搜索)。合并后的新Segment被Flush到磁盤中,然后打開新的Segment的檢索功能,同時刪除磁盤上舊的Segment。
ElasticSearch的檢索過程
elasticSearch中的檢索一般分為兩類,一類是Get查詢,即通過_id查詢具體的文檔,一類是Search查詢,即向Es發起DSL語句的查詢。這里主要以Search查詢為例
查詢整體過程
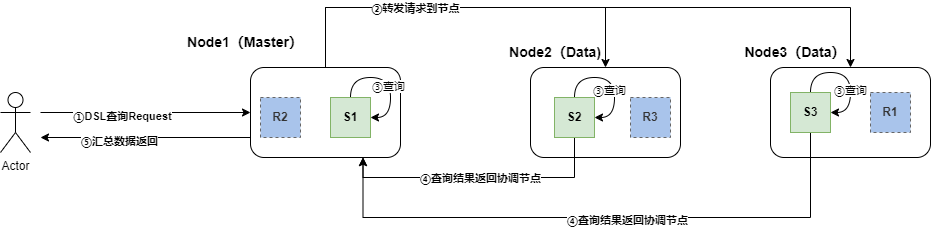
-
客戶端向Es服務(集群)發送指定索引的查詢請求,請求先到達主節點(協調節點)
-
協調節點根據集群部署,將請求轉發到其他節點所對應的索引分片上(優先使用主節點)
- 此過程中Es內存機制會判定是否符合Node Cache的標準,進行Node Cache查詢或緩存查詢
-
各個節點上的分片在其內部進行數據檢索,檢索出符合條件的數據
-
此過程中會根據查詢,判定是否符合Shard Cache標準,進行Cache查詢或緩存內容
-
涉及聚合或分析字段的聚合操作,內部Segment會判定是否fielddata Cache標準,并啟用該緩存
-
-
各分片將檢索出的數據發回主節點,主節點進行匯總后返回給客戶端
也就是說,Es是通過分片將同一索引的數據均勻的散布在集群中,每個分片依賴所處節點設備的硬件資源進行獨立查詢,通過網絡傳輸,將結果返回。
查詢時segment內部具體在做什么
說Segment的查詢之前補充一下上文Segment的內容部分(注意,在Es或者Lucene中提及的Segment是邏輯概念,不等價于磁盤上的段);Segment的組成部分和文檔數據在磁盤上的對應關系:
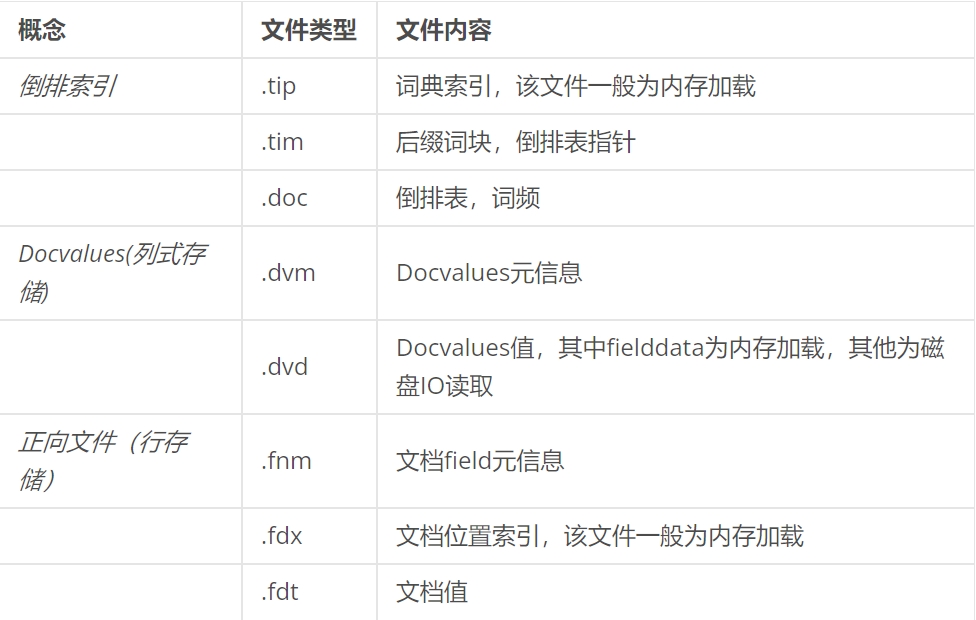
更多文檔類型可以此處查看
-
請求來的shard內部,解析出DSL,轉譯為Lucene的語法
-
通過 commit point記錄分發到segments中,此時的segment分為兩種,一種是經過flush和merge的,我稱之為磁盤版segment(當然不那么準確);還有一種是處在索引過程中的,上文中存在于FilesystemCache中可被查詢的,我稱之為內存版segment。兩者不同之處就在于,前者涉及磁盤IO讀取部分數據來完成查詢,后者不需要IO,直接內存進行查詢
-
每個segment根據詞法分析得出的詞項,進行詞典檢索(詞典的數據.tip文件一般加載在內存中,不需要磁盤IO,非常快),配合倒排表,快速找到相關文檔(這個過程需要磁盤IO)
-
如果涉及數字類型的sum、max、min的聚合或者text的聚合操作,則segment會使用DocValues相關的文件,借助列式存儲的優勢快速運算;fielddata緩存機制也是在此時發揮作用。
-
segment完成檢索后將內容返回到shard中(其他segment也是同理),由shard去進行合并、緩存等操作

 浙公網安備 33010602011771號
浙公網安備 33010602011771號