
Nifi:初識nifi
寫在前面:
第一次接觸這一系統的時候,只有github上的一坨源碼和官方的英文文檔,用起來只能說是一步一個坑,一踩一個腳印,現在回想那段血淚史,只想 ***,現在用起來算是有了一些經驗和總結,這里就做一下記錄。
對于Nifi的認知
Nifi是什么
個人一直覺得,當我們首次接觸某個新東西時,不論是否要學習它,應該先對這個東西有個清晰的定義邊界,比如我們學習tomcat,我們要知道它是個服務容器,主要的任務邊界就是對JavaWeb的服務提供支持,所以對于小白入手Nifi,我們應該首先搞清楚它是什么。
先來介紹一下這個東西的背景吧;
2006年,Nifi由M國國家安全局(NSA)的Joe Witt創建,2015年7月20日,Apache 基金會宣布Apache NiFi順利孵化成為Apache的頂級項目之一。NiFi初始的項目名稱是Niagarafiles,當NiFi項目開源之后,一些早先在NSA的開發者們創立了初創公司Onyara,Onyara隨之繼續NiFi項目的開發并提供相關的支持。Hortonworks公司收購了Onyara并將其開發者整合到自己的團隊中,形成HDF(Hortonworks Data Flow)平臺。2018年Cloudera與Hortonworks合并后,新的CDH整合HDF,改名為Cloudera Data Flow(CDF),并且在最新的CDH6.2中直接打包,參考《0603-Cloudera Flow Management和Cloudera Edge Management正式發布》,而Apache NiFi就是CFM的核心組件。
上面這一坨花里胡哨的組織、協議、文獻, 其實不用那么在意,只需要知道Apache是啥就夠了。總之上面那坨介紹幫我們解決了第一個問題,
即:這玩意的全稱叫做 Apache-Nifi,它的第一任爹是M國國安局(根兒正苗紅), 現在是Apache的一個頂級開源項目,最終這個Nifi是一個軟件成品,并且有專門的團隊在維護它,運營它。
Nifi能干什么
了解完它的族譜、性質,下面就是個重頭戲,Nifi能干什么;
Apache NiFi 是為數據流設計,它支持高度可配置的指示圖的數據路由、轉換和系統中介邏輯,支持從多種數據源動態拉取數據。簡單地說,NiFi是為自動化系統之間的數據流而生。 這里的數據流表示系統之間的自動化和受管理的信息流。 基于WEB圖形界面,通過拖拽、連接、配置完成基于流程的編程,實現數據采集、處理等功能。
上面這段話,寫的很專業、很術語,翻譯過來無非就是,Nifi是一個專門用來流轉、處理數據的高級分發系統。說白了,就是用來倒騰數據。
舉一個例子:當一個企業或者一個組織,大多數業務都采用信息化的時候,勢必就要使用各式各樣的軟件系統(人事管理系統、財務管理系統、報表管理系統、物流管控系統等等),不同的軟件系統來自于不同的廠家,它們設計的初衷就是各自為政,只負責自己的業務范圍。現在用戶需要想把各個業務塊的數據整合(比如我想把財務、人事、考勤啥的串起來,方便統一查閱、統計),就必然要經過從各個系統中導出數據、匯總數據、處理數據沖突,這些事如果讓人來干,結果可想而知,而Nifi就能充分解決這種場景。
總的來說,Nifi就是一個數據接入、處理、清洗、分發的系統(基于Web方式工作,后臺在服務器上進行調度)。
Nifi的基本架構
nifi的核心概念
1、NiFi的基本設計理念是基于數據流的編程 Flow-Based Programming(FBP)。簡單點理解就是:將數據看作水管中的水,它是順著某個流程管道流動,在這中間,可以在任意節點處堵截這個“水流”,并對它進行改造,然后放回管道繼續向下流去。
以下是Nifi的一些術語對應的FBP概念:
| NiFi術語 | FBP術語 | 描述 |
|---|---|---|
|
FlowFile |
Information Packet |
FlowFile表示在系統中移動的每個對象,對于每個對象,NiFi跟蹤 key/value 屬性字符串的映射及其相關的零個或多個字節的內容。 |
| FlowFile Processor |
Black Box |
處理器實際上執行工作。在[eip]術語中,處理器正在對系統之間的數據路由,轉換或中介進行某種組合。處理器可以訪問給定FlowFile及其內容流的屬性。處理器可以在給定的工作單元中對零個或多個FlowFile進行操作,并提交工作或回滾。 |
| Connection | Bounded Buffer |
Connections提供處理器之間的實際鏈接。它們充當隊列并允許各種進程以不同的速率進行交互。這些隊列可以動態優先化,并且可以在負載上具有上限,從而實現反壓。 |
| Flow Controller | Scheduler |
流控制器維護流程如何連接和管理所有流程使用的線程及其分配的知識。Flow Controller充當促進處理器之間FlowFiles交換的代理。 |
|
Process Group |
subnet |
進程組是一組特定的進程及其連接,可以通過輸入端口接收數據并通過輸出端口發送數據。以這種方式,進程組允許僅通過組合其他組件來創建全新組件。 |
2、應用的方式是:將處理數據的工序做成黑盒處理器,由多個處理器經過連接管道串成一個流程,數據逐個處理器最終以想要的形式流向目的地。
數據進入一個節點(處理器),由該節點(處理器)對數據進行處理,根據不同的處理結果將數據路由到后續的其他節點(處理器)進行處理。這是NiFi的流程比較容易可視化的一個原因。
nifi的基本架構
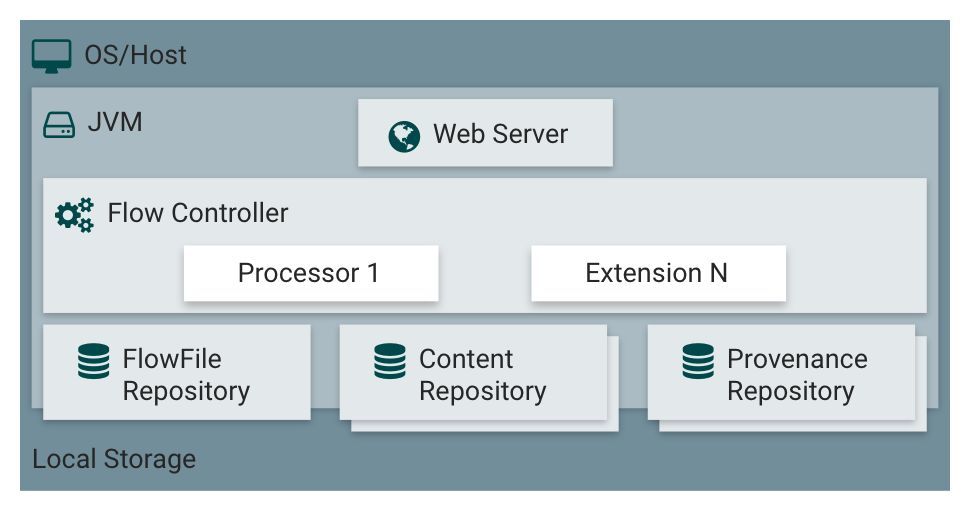
Nifi說白了也是一個Java程序,它需要基于JVM的一套運行環境。
1.Web Server
直接面向用戶的頁面及頁面的交互,承載NiFi基于HTTP的命令和控制API。就是一套完備的Web應用
2.Flow Controller
是NiFi的核心之一,執行具體操作的大腦,負責從線程資源池中給Processor分配可執行的線程,以及其他資源管理調度的工作。管控著整個nIfi的大后方
3.FlowFile Repository
負責保存在目前活動流中FlowFile的狀態,其功能實現是可插拔的。默認的方式是通過一個存儲在指定磁盤分區的持久預寫日志(WAL),來實現此功能。
4.Content Repository
負責保存在目前活動流中FlowFile的實際字節內容,其功能實現是可插拔的。默認的方式是一種相當簡單的機制,即存儲內容數據在文件系統中。多個存儲路徑可以被指定,因此可以將不同的物理路徑進行結合,從而避免達到單個物理分區的存儲上限。
5.Provenance Repository
負責保存所有跟蹤事件數據,同樣此功能是可插拔的,并且默認可以在一個或多個物理分區上進行存儲,在每個路徑下的事件數據都被索引,并且可被查詢。
nifi的性能
NiFi旨在充分利用底層服務器的能力,最大化使用CPU和磁盤這種資源特別有優勢。
對于IO:
期望的吞吐或時延與實際情況可能會存在很大的差異,這取決于系統的配置方式。
鑒于大多數主要NiFi子系統都是可插拔式的,性能取決于部署實施的方式。對于通用需求建議使用開箱即用的默認實現。使用本地磁盤對于所有子系統都可以持久化保存數據,從而保證交付。保守一點假設一臺典型的服務器上的一般磁盤或者RAID卷大約每秒50MB的讀寫速率。則NiFi中的較大類型的數據流可以達到每秒100MB或者更高的吞吐。這是因為添加到NiFi的每個物理分區和content repository會呈線性增長。這將在FlowFile repository和provenance repository的某個點上出現瓶頸。我們計劃在搭建時提供一個基準測試和性能測試模板,允許用戶輕松測試他們的系統并確定瓶頸在哪里。此模板還應使系統管理員可以輕松進行更改并驗證其影響。
對于CPU:
Flow Controller充當引擎,指示特定Processor何時被賦予執行線程。Processor被設計為一旦執行任務完成立即返回線程。Flow Controller有一個配置項,用以表明它維護的各個線程池的可用線程。理想的線程數取決于服務器的CPU核的數量,系統是否正在運行其他服務,以及flow中的處理性質。對于典型的IO很重的flow,使許多線程可用是合理的。
對于內存:
NiFi運行在JVM中,因此受限于JVM提供的內存空間。JVM的GC對于限制總實際堆大小以及優化應用程序運行時間是一個非常重要的因素。定期閱讀相同內容時,NiFi作業可能是I/O密集型的。配置足夠大的磁盤以優化性能。
Nifi的擴展性:
Nifi本身即為可擴展而生,擴展點包括:處理器,控制器服務,報告任務,優先級排序器和用戶界面。
1.類裝載器隔離
對于任何基于組件的系統,隨著規模的擴張,組件之間的依賴會越來越錯綜復雜。為了解決這個問題,NiFi通過提供自定義類裝載器模型,來確保每個擴展組件之間的約束關系被限制在非常有限的程度。因此,在創建擴展組件時,就不用再過多關注其是否會與其他組件產生沖突。
2.Site-to-Site通信協議
NiFi實例之間的首選通信協議是NiFi Site-to-Site(S2S)協議。S2S可以輕松,高效,安全地將數據從一個NiFi實例傳輸到另一個實例。NiFi客戶端庫可以輕松構建并捆綁到其他應用程序或設備中,以通過S2S與NiFi進行通信。S2S中支持基于socket的協議和HTTP(S)協議作為底層傳輸協議,使得可以將代理服務器嵌入到S2S通信中。
Nifi的伸縮性:
1.橫向擴展(集群)
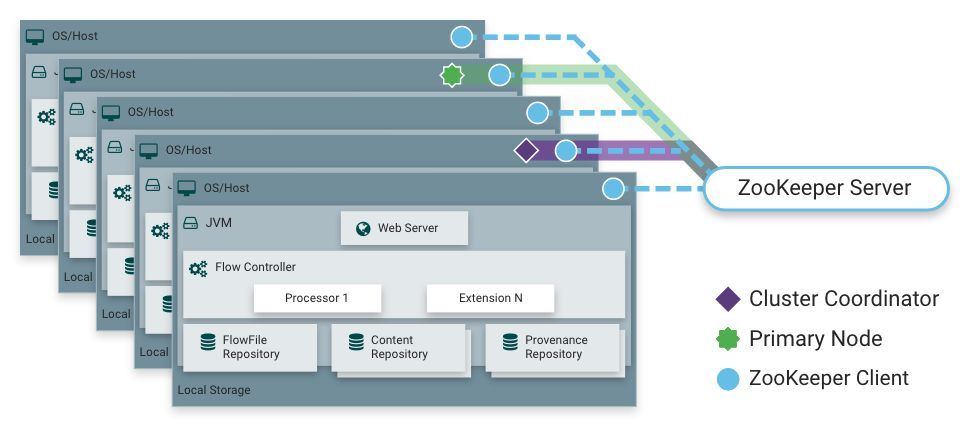
從NiFi 1.0版本開始,NiFi采用Zero-Master集群模式。NiFi集群中的每個節點都對數據執行相同的任務,但每個節點都運行在不同的數據集上。Apache ZooKeeper選擇其中一個節點作為集群協調器,故障轉移由ZooKeeper自動處理。所有集群節點都會向集群協調器報告心跳和狀態信息。集群協調器負責斷開和連接節點。作為DataFlow管理器,您可以通過集群中任何節點的UI與NiFi集群進行交互。您所做的任何更改都會復制到集群中的所有節點,從而允許多個入口點進入集群。
如上所述,NiFi可以通過將許多節點聚集在一起以集群的方式實現橫向擴展。如果單節點被配置為每秒處理數百MB的數據,則集群方式可以達到每秒處理GB級別。這就帶來了NiFi與其獲取數據的系統之間的負載均衡和故障轉移的挑戰。使用基于異步排隊的協議(如消息服務,Kafka等)可以提供幫助。使用NiFi的“site-to-site”功能也非常有效,因為它是一種協議,允許NiFi和客戶端(包括另一個NiFi集群)相互通信,共享有關加載的信息,以及交換特定授權的數據端口。
2.放大和縮小
NiFi還可以非常靈活地放大和縮小。從NiFi框架的角度來看,如果要增加吞吐,可以在配置時增加“Scheduling”選項卡下processor的并發任務數。這允許更多進程同時執行,從而提供更高的吞吐。 另一方面,您可以完美地將NiFi縮小到適合在邊緣設備上運行,因為硬件資源有限,所需的占用空間很小。要專門解決第一英里數據收集挑戰和邊緣用例,您可以使用MiNiFi,參考:https://cwiki.apache.org/confluence/display/NIFI/MiNiFi
1、Nifi:基本認識
2、Nifi:基礎用法及頁面常識
3、Nifi:ExcuseXXXScript組件的使用(一)
4、Nifi:ExcuseXXXScript組件的使用(二)
5、Nifi:ExcuseXXXScript組件的使用(三)
6、Nifi:自定義處理器的開發
7、Nifi:Nifi的Controller Service

 浙公網安備 33010602011771號
浙公網安備 33010602011771號