
數據結構—哈希表
哈希表定義
數學課本中學習過函數的相關知識,給定一個 x,通過一個數學公式,只需要將 x 的值帶入公式就可以求出一個新的值 y。哈希表的建立同函數類似,把函數中的 x 用查找記錄時使用的關鍵字來代替,然后將關鍵字的值帶入一個精心設計的公式中,就可以求出一個值,用這個值來表示記錄存儲的哈希地址。即:
數據的哈希地址=f(關鍵字的值)
注:哈希地址只是表示在查找表中的存儲位置,而不是實際的物理存儲位置。f()是一個函數,通過這個函數可以快速求出該關鍵字對應的的數據的哈希地址,稱之為“哈希函數”。
例如,這里有一個電話簿(查找表),電話簿中有 4 個人的聯系方式:
- 張三 13912345678
- 李四 15823457890
- 王五 13409872338
- 趙六 13805834722
假如想查找李四的電話號碼,對于一般的查找方式最先想到的是從頭遍歷,一一比較。而如果將電話簿構建成一張哈希表,可以直接通過名字“李四”直接找到電話號碼在表中的位置。
在構建哈希表時,最重要的是哈希函數的設計。例如設計電話簿案例中的哈希函數為:每個名字的姓的首字母的 ASCII 值即為對應的電話號碼的存儲位置。這時會發現,張三和趙六兩個關鍵字的姓的首字母都是 Z ,最終求出的電話號碼的存儲位置相同,這種現象稱為沖突。在設計哈希函數時,要盡量地避免沖突現象的發生。對于哈希表而言,沖突只能盡可能地少,無法完全避免。
哈希表的構建
常用的哈希函數的構造方法有 6 種:直接定址法、數字分析法、平方取中法、折疊法、除留余數法和隨機數法。
直接定址法
其哈希函數為一次函數,即兩種形式:H(key)= key 或者 H(key)=a * key + b
其中 H(key)表示關鍵字為 key 對應的哈希地址,a 和 b 都為常數。
例如有一個從 1 歲到 100 歲的人口數字統計表,如表所示:
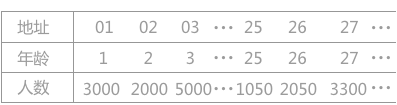
假設其哈希函數為第一種形式,其關鍵字的值表示最終的存儲位置。若需要查找年齡為 25 歲的人口數量,將年齡 25 帶入哈希函數中,直接求得其對應的哈希地址為 25(求得的哈希地址表示該記錄的位置在查找表的第 25 位)。
數字分析法
如果關鍵字由多位字符或者數字組成,就可以考慮抽取其中的 2 位或者多位作為該關鍵字對應的哈希地址,在取法上盡量選擇變化較多的位,避免沖突發生。
例如表中列舉的是一部分關鍵字,每個關鍵字都是有 8 位十進制數組成:

通過分析關鍵字的構成,很明顯可以看到關鍵字的第 1 位和第 2 位都是固定不變的,而第 3 位不是數字 3 就是 4,最后一位只可能取 2、7 和 5,只有中間的 4 位其取值近似隨機,所以為了避免沖突,可以從 4 位中任意選取 2 位作為其哈希地址。
平方取中法
是對關鍵字做平方操作,取中間得幾位作為哈希地址。此方法也是比較常用的構造哈希函數的方法。
例如關鍵字序列為{421,423,436},對各個關鍵字進行平方后的結果為{177241,178929,190096},則可以取中間的兩位{72,89,00}作為其哈希地址。
折疊法
是將關鍵字分割成位數相同的幾部分(最后一部分的位數可以不同),然后取這幾部分的疊加和(舍去進位)作為哈希地址。此方法適合關鍵字位數較多的情況。
例如,在圖書館中圖書都是以一個 10 位的十進制數字為關鍵字進行編號的,若對其查找表建立哈希表時,就可以使用折疊法。
若某書的編號為:0-442-20586-4,分割方式如圖中所示,在對其進行折疊時有兩種方式:一種是移位折疊,另一種是間界折疊:
-
- 移位折疊是將分割后的每一小部分,按照其最低位進行對齊,然后相加,如圖 1(a);
- 間界折疊是從一端向另一端沿分割線來回折疊,如圖 1(b)。

除留余數法
若已知整個哈希表的最大長度 m,可以取一個不大于 m 的數 p,然后對該關鍵字 key 做取余運算,即:H(key)= key % p。
在此方法中,對于 p 的取值非常重要,由經驗得知 p 可以為不大于 m 的質數或者不包含小于 20 的質因數的合數。
隨機數法
是取關鍵字的一個隨機函數值作為它的哈希地址,即:H(key)=random(key),此方法適用于關鍵字長度不等的情況。
注意:這里的隨機函數其實是偽隨機函數,隨機函數是即使每次給定的 key 相同,但是 H(key)都是不同;而偽隨機函數正好相反,每個 key 都對應的是固定的 H(key)。
構建方法的選擇
如此多的構建哈希函數的方法,在選擇的時候,需要根據實際的查找表的情況采取適當的方法。通常考慮的因素有以下幾方面:
-
-
- 關鍵字的長度。如果長度不等,就選用隨機數法。如果關鍵字位數較多,就選用折疊法或者數字分析法;反之如果位數較短,可以考慮平方取中法;
- 哈希表的大小。如果大小已知,可以選用除留余數法;
- 關鍵字的分布情況;
- 查找表的查找頻率;
- 計算哈希函數所需的時間(包括硬件指令的因素)
-
處理沖突的方法
對于哈希表的建立,需要選取合適的哈希函數,但是對于無法避免的沖突,需要采取適當的措施去處理。通常用的處理沖突的方法有以下幾種:
開放定址法、再哈希法、鏈地址法、建立一個公共溢出區
開放定址法
開放定址法 H(key)=(H(key)+ d)MOD m(其中 m 為哈希表的表長,d 為一個增量) 當得出的哈希地址產生沖突時,選取以下 3 種方法中的一種獲取 d 的值,然后繼續計算,直到計算出的哈希地址不在沖突為止,這 3 種方法為:
-
-
- 線性探測法:d=1,2,3,…,m-1
- 二次探測法:d=12,-12,22,-22,32,…
- 偽隨機數探測法:d=偽隨機數
-
例如,在長度為 11 的哈希表中已填寫好 17、60 和 29 這 3 個數據(如圖 2(a) 所示),其中采用的哈希函數為:H(key)=key MOD 11,現有第 4 個數據 38 ,當通過哈希函數求得的哈希地址為 5,與 60 沖突,則分別采用以上 3 種方式求得插入位置如圖 (b)所示:
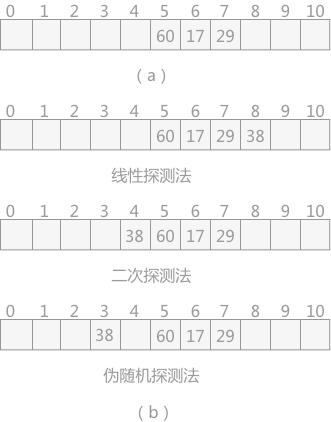
在線性探測法中,當遇到沖突時,從發生沖突位置起,每次 +1,向右探測,直到有空閑的位置為止;二次探測法中,從發生沖突的位置起,按照 +12,-12,+22,…如此探測,直到有空閑的位置;偽隨機探測,每次加上一個隨機數,直到探測到空閑位置結束。
再哈希法
當通過哈希函數求得的哈希地址同其他關鍵字產生沖突時,使用另一個哈希函數計算,直到沖突不再發生。
鏈地址法
將所有產生沖突的關鍵字所對應的數據全部存儲在同一個線性鏈表中。例如有一組關鍵字為{19,14,23,01,68,20,84,27,55,11,10,79},其哈希函數為:H(key)=key MOD 13,使用鏈地址法所構建的哈希表如圖 所示:
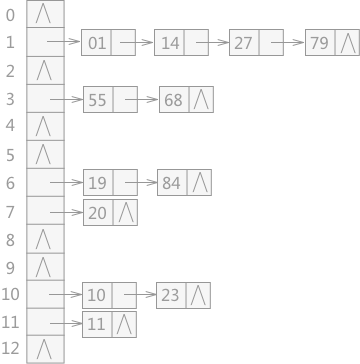
至于建立緩沖區:建立兩張表,一張為基本表,另一張為溢出表。基本表存儲沒有發生沖突的數據,當關鍵字由哈希函數生成的哈希地址產生沖突時,就將數據填入溢出表。

 浙公網安備 33010602011771號
浙公網安備 33010602011771號