ElasticSearch安裝和簡單使用
ElasticSearch
ES安裝
Linux下安裝ES,
-
下載:官網下載想要的版本的安裝包(.tar.gz),上傳到指定目錄里,解壓,
-
修改配置文件:修改
./elasticsearch-7.16.1/config目錄下的elasticsearch.yml配置文件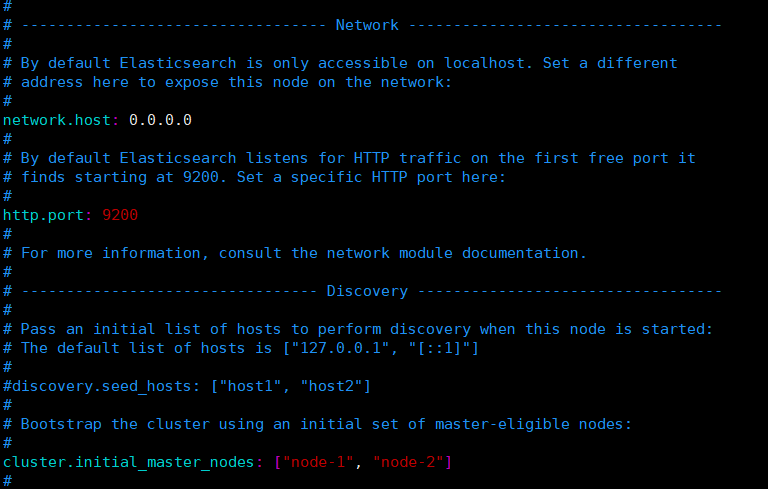
- network.host: 0.0.0.0 表示任何IP都可以訪問,實際開發中會設置為具體的IP
elasticsearch.yml,ES的配置文件;jvm.options,ES的JVM配置文件;log4j2.properties,ES的日志配置文件;
-
啟動:進入
./elasticsearch-7.16.1/bin下,以user-es用戶啟動es,su user-es ./elasticsearch.(如果以root用戶啟動會報錯) -
檢查:使用postman訪問
http://192.168.1.244:9200/,如果返回以下信息證明本機可以訪問服務器的es了。{ "name": "poc-2", "cluster_name": "elasticsearch", "cluster_uuid": "x3o3mnyAQW2nOsbByCTdPw", "version": { "number": "7.16.1", "build_flavor": "default", "build_type": "tar", "build_hash": "5b38441b16b1ebb16a27c107a4c3865776e20c53", "build_date": "2021-12-11T00:29:38.865893768Z", "build_snapshot": false, "lucene_version": "8.10.1", "minimum_wire_compatibility_version": "6.8.0", "minimum_index_compatibility_version": "6.0.0-beta1" }, "tagline": "You Know, for Search" }
ES的基本概念
? ES是基于Lucene的搜索服務器,它提供了一個分布式多用戶能力的全問搜索引擎,且ES支持RestFulweb風格的url訪問。ES是基于Java開發的開源搜索引擎,設計用于云計算,能夠達到實時搜索,穩定、可靠、快速。此外,ES還提供了數據聚合分析功能,但在數據分析方面,es的時效性不是很理想,在企業應用中一般還是用于搜索。ES自2016年起已經超過Solr等,成為排名第一的搜索引擎應用。
ES的特性
速度快、易擴展、彈性、靈活、操作簡單、多語言客戶端、X-Pack、hadoop/spark強強聯手、開箱即用。
- 分布式:橫向擴展非常靈活
- 全文檢索:基于lucene的強大的全文檢索能力;
- 近實時搜索和分析:數據進入ES,可達到近實時搜索,還可進行聚合分析
- 高可用:容錯機制,自動發現新的或失敗的節點,重組和重新平衡數據
- 模式自由:ES的動態mapping機制可以自動檢測數據的結構和類型,創建索引并使數據可搜索。
- RESTful API:JSON + HTTP
基本概念
? ES中有幾個基本概念:索引(index)、類型(type)、文檔(document)、映射(mapping)等。我們將這幾個概念與傳統的關系型數據庫中的庫、表、行、列等概念進行對比,如下表:
| 關系型數據庫 | ES |
|---|---|
| 數據庫 database | 索引 index |
| 表 table | 類型 type (ES6.0之后被廢棄,es7中完全刪除) |
| 表結構 schema | 映射 mapping |
| 行 row | 文檔 document |
| 列 column | 字段 field |
| 索引 | 反向索引 |
| SQL | 查詢DSL |
| select * from table | get http://... |
| update table set | PUT http://... |
| DELETE | DELETE http://...... |
倒排索引
一個文檔,首先被分詞為多個關鍵字,每個關鍵字有一個編號。然后,建立文檔與關鍵字的映射關系。最后,檢索的時候根據關鍵字本身做索引排序。
索引
索引是ES的一個邏輯存儲,對應關系型數據庫中的庫,ES可以把索引數據存放到服務器中,也可以sharding(分片)后存儲到多臺服務器上。每個索引有一個或多個分片,每個分片可以有多個副本。
文檔
存儲在ES中的主要實體叫文檔,可以理解為關系型數據庫中表的一行數據記錄。每個文檔由多個字段(field)組成。區別于關系型數據庫的是,ES是一個非結構化的數據庫,每個文檔可以有不同的字段,并且有一個唯一標識。
映射
映射是對索引庫中的索引字段及其數據類型進行定義,類似于關系型數據庫中的表結構。ES默認動態創建索引和索引類型的mapping,這就像是關系型數據中的,無需定義表機構,更不用指定字段的數據類型。當然也可以手動指定mapping類型。
ES集群的概念
集群
一個ES集群由多個節點(node)組成, 每個集群都有一個共同的集群名稱 (./elasticsearch-7.16.1/config/elasticsearch.yml中的cluster.name設置)做為標識
節點
一個es實例即為一個節點,一臺機器可以有多個節點,正常使用下每個實例都應該會部署在不同的機器上。ES的配置文件中可以通過node.master、 node.data 來設置節點類型
- node.master: true/false 表示節點是否具有成為主節點的資格
- node.data: true/false 表示節點是否為存儲數據
node節點的組合方式:
- 主節點+數據節點: 默認方式,節點既可以作為主節點,又存儲數據
- 數據節點: 節點只存儲數據,不參與主節點選舉
- 客戶端節點: 不會成為主節點,也不存儲數據,主要針對海量請求時進行負載均衡
分片 shard
如果我們的索引數據量很大,超過硬件存放單個文件的限制,就會影響查詢請求的速度,ES引入了分片技術。一個分片本身就是一個完成的搜索引擎,文檔存儲在分片中,而分片會被分配到集群中的各個節點中,隨著集群的擴大和縮小,ES會自動的將分片在節點之間進行遷移,以保證集群能保持一種平衡。分片有以下特點:
- ES的一個索引可以包含多個分片(shard);
- 每一個分片(shard)都是一個最小的工作單元,承載部分數據;
- 每個shard都是一個lucene實例,有完整的簡歷索引和處理請求的能力;
- 增減節點時,shard會自動在nodes中負載均衡(可配置);
- 一個文檔只能完整的存放在一個shard上
- 一個索引中含有shard的數量,默認值為5,在索引創建后這個值是不能被更改的。
- 優點:水平分割和擴展我們存放的內容索引;分發和并行跨碎片操作提高性能/吞吐量;
- 每一個shard關聯的副本分片(replica shard)的數量,默認值為1,這個設置在任何時候都可以修改。
副本 replica
副本(replica shard)就是shard的冗余備份,它的主要作用:
- 冗余備份,防止數據丟失;
- shard異常時負責容錯和負載均衡;
使用
要先創建索引 put,在創建post mapping映射,然后再post 插入數據,
curl -POST IP:9200/索引名稱/索引類型/_mapping?pretty -d '{
索引類型: {
"properties": {
"title": {
"type": "text",
"store": "true"
},
"description": {
"type": "text",
"index": "false"
},
"price": {
"type": "double"
},
"onSale": {
"type": "boolean"
},
"type": {
"type": "integer"
},
"createDate": {
"type": "date"
}
}
}
}'
{
"title": "test title 001",
"description": "this is a random desc ",
"price": 22.6,
"onSale": "true",
"type": 2,
"createDate": "2018-01-12"
}
或者直接插入數據,通過指定文檔id插入數據。
curl -PUT IP:9200/索引名稱/索引類型/文檔ID -d '{
"title": "test title 003",
"description": "this is a random desc ",
"price": 22.6,
"onSale": "true",
"type": 2,
"createDate": "2018-01-12"
}'
參考
本文來自博客園,作者:永恒&,轉載請注明原文鏈接:http://www.rzrgm.cn/Sun-yuan/p/17398292.html

 浙公網安備 33010602011771號
浙公網安備 33010602011771號