eBPF筆記(六)——The bpf() System Call
The bpf() System Call
正如你在第1章中看到的,當用戶空間應用程序希望內核代表它們執行某些操作時,它們會使用系統調用API發出請求。因此,如果一個用戶空間應用程序想要將一個eBPF程序加載到內核中,必然涉及一些系統調用。實際上,有一個名為bpf()的系統調用,在本章中我將向你展示如何使用它來加載和與eBPF程序和map交互。
值得注意的是,運行在內核中的eBPF代碼不使用syscalls來訪問map。系統調用接口僅由用戶空間應用程序使用。相反,eBPF程序使用輔助函數來讀取和寫入map;你在前兩章中已經看到了這方面的示例。
如果你繼續自己編寫eBPF程序,很可能你不會直接調用這些bpf()系統調用。本書后面會討論的庫提供了更高級別的抽象,使事情變得更容易。盡管如此,這些抽象通常與你在本章中看到的底層系統調用命令相對應。無論你使用哪個庫,你都需要掌握底層操作——加載程序,創建和訪問map等——你將在本章中看到的操作。
在我向你展示bpf()系統調用的示例之前,讓我們考慮一下bpf()的man頁上說的內容,即bpf()用于“對擴展BPF map或程序執行命令”。它還告訴我們,bpf()的簽名如下:
int bpf(int cmd, union bpf_attr *attr, unsigned int size);
bpf()的第一個參數cmd指定要執行的命令。bpf()系統調用不只是做一件事——有很多不同的命令可以用來操作eBPF程序和map。圖4-1顯示了用戶空間代碼可能使用的一些常見命令的概述,用于加載eBPF程序、創建map、將程序附加到事件,并訪問map中的鍵值對。
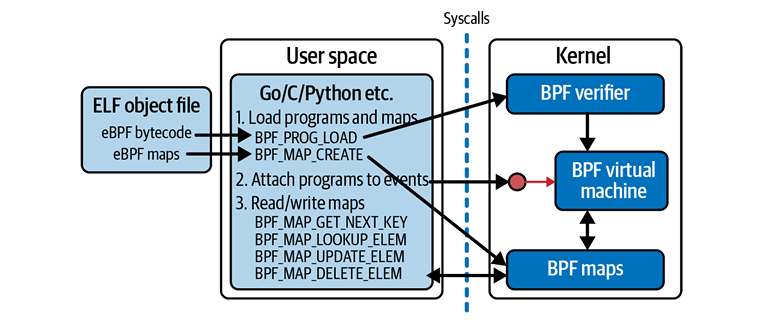
bpf()系統調用的attr參數保存著指定命令所需的任何數據,而size指示attr中有多少字節的數據。
在這個例子中,我將使用一個名為hello-buffer-config.py的BCC程序,它在第2章中看到的示例基礎上進行了擴展。與hello-buffer.py示例類似,這個程序在每次運行時都向perf緩沖區發送一條消息,傳遞有關execve()系統調用事件的內核到用戶空間的信息。這個版本的新功能是允許為每個用戶ID配置不同的消息。
點擊查看完整代碼
#!/usr/bin/python3
# -*- coding: utf-8 -*-
from bcc import BPF
import ctypes as ct
program = r"""
struct user_msg_t {
char message[12];
};
BPF_HASH(config, u32, struct user_msg_t);
BPF_PERF_OUTPUT(output);
struct data_t {
int pid;
int uid;
char command[16];
char message[12];
};
int hello(void *ctx) {
struct data_t data = {};
struct user_msg_t *p;
char message[12] = "Hello World";
data.pid = bpf_get_current_pid_tgid() >> 32;
data.uid = bpf_get_current_uid_gid() & 0xFFFFFFFF;
bpf_get_current_comm(&data.command, sizeof(data.command));
p = config.lookup(&data.uid);
if (p != 0) {
bpf_probe_read_kernel(&data.message, sizeof(data.message), p->message);
} else {
bpf_probe_read_kernel(&data.message, sizeof(data.message), message);
}
output.perf_submit(ctx, &data, sizeof(data));
return 0;
}
"""
b = BPF(text=program)
syscall = b.get_syscall_fnname("execve")
b.attach_kprobe(event=syscall, fn_name="hello")
b["config"][ct.c_int(0)] = ct.create_string_buffer(b"Hey root!")
b["config"][ct.c_int(501)] = ct.create_string_buffer(b"Hi user 501!")
def print_event(cpu, data, size):
data = b["output"].event(data)
print(f"{data.pid} {data.uid} {data.command.decode()} {data.message.decode()}")
b["output"].open_perf_buffer(print_event)
while True:
b.perf_buffer_poll()
$ strace -e bpf ./hello-buffer-config.py
bpf(BPF_BTF_LOAD, {btf="\237\353\1\0\30\0\0\0\0\0\0\0\364\5\0\0\364\5\0\0#\v\0\0\1\0\0\0\0\0\0\10"..., btf_log_buf=NULL, btf_size=4399, btf_log_size=0, btf_log_level=0}, 128) = 3
bpf(BPF_MAP_CREATE, {map_type=BPF_MAP_TYPE_PERF_EVENT_ARRAY, key_size=4, value_size=4, max_entries=128, map_flags=0, inner_map_fd=0, map_name="output", map_ifindex=0, btf_fd=0, btf_key_type_id=0, btf_value_type_id=0, btf_vmlinux_value_type_id=0, map_extra=0}, 128) = 4
bpf(BPF_MAP_CREATE, {map_type=BPF_MAP_TYPE_HASH, key_size=4, value_size=12, max_entries=10240, map_flags=0, inner_map_fd=0, map_name="config", map_ifindex=0, btf_fd=3, btf_key_type_id=1, btf_value_type_id=4, btf_vmlinux_value_type_id=0, map_extra=0}, 128) = 5
bpf(BPF_PROG_LOAD, {prog_type=BPF_PROG_TYPE_KPROBE, insn_cnt=44, insns=0x7f33e9468be8, license="GPL", log_level=0, log_size=0, log_buf=NULL, kern_version=KERNEL_VERSION(6, 5, 13), prog_flags=0, prog_name="hello", prog_ifindex=0, expected_attach_type=BPF_CGROUP_INET_INGRESS, prog_btf_fd=3, func_info_rec_size=8, func_info=0x5770adbd6a20, func_info_cnt=1, line_info_rec_size=16, line_info=0x5770ac5d9040, line_info_cnt=21, attach_btf_id=0, attach_prog_fd=0, fd_array=NULL}, 128) = 6
bpf(BPF_MAP_UPDATE_ELEM, {map_fd=5, key=0x7f33e52f9a10, value=0x7f33e8486a90, flags=BPF_ANY}, 128) = 0
bpf(BPF_MAP_UPDATE_ELEM, {map_fd=5, key=0x7f33e52f9a10, value=0x7f33e8486a90, flags=BPF_ANY}, 128) = 0
bpf(BPF_MAP_UPDATE_ELEM, {map_fd=4, key=0x7f33e52f9a10, value=0x7f33e8486a90, flags=BPF_ANY}, 128) = 0
bpf(BPF_MAP_UPDATE_ELEM, {map_fd=4, key=0x7f33e52f9a10, value=0x7f33e8486a90, flags=BPF_ANY}, 128) = 0
bpf(BPF_MAP_UPDATE_ELEM, {map_fd=4, key=0x7f33e52f9a10, value=0x7f33e8486a90, flags=BPF_ANY}, 128) = 0
bpf(BPF_MAP_UPDATE_ELEM, {map_fd=4, key=0x7f33e52f9a10, value=0x7f33e8486a90, flags=BPF_ANY}, 128) = 0
bpf(BPF_MAP_UPDATE_ELEM, {map_fd=4, key=0x7f33e52f9a10, value=0x7f33e8486a90, flags=BPF_ANY}, 128) = 0
bpf(BPF_MAP_UPDATE_ELEM, {map_fd=4, key=0x7f33e52f9a10, value=0x7f33e8486a90, flags=BPF_ANY}, 128) = 0
bpf(BPF_MAP_UPDATE_ELEM, {map_fd=4, key=0x7f33e52f9a10, value=0x7f33e8486a90, flags=BPF_ANY}, 128) = 0
bpf(BPF_MAP_UPDATE_ELEM, {map_fd=4, key=0x7f33e52f9a10, value=0x7f33e8486a90, flags=BPF_ANY}, 128) = 0
.....
Loading BTF Data
對于bpf()的第一次調用有:
bpf(BPF_BTF_LOAD, {btf="\237\353\1\0...}, 128) = 3
這次對bpf()的調用正在將一塊BTF數據加載到內核中,并且bpf()系統調用的返回代碼(在我的例子中是3)是一個指向該數據的文件描述符。
Creating Maps
下一個 bpf() 創建輸出 perf 緩沖區映射
bpf(BPF_MAP_CREATE, {map_type=BPF_MAP_TYPE_PERF_EVENT_ARRAY, key_size=4, value_size=4,
從命令名稱BPF_MAP_CREATE可以猜到,這個調用創建了一個eBPF map。你可以看到這個map的類型是PERF_EVENT_ARRAY,名為output。這個perf事件map中的鍵和值都是4個字節長。此map可以容納的鍵值對數量有一個限制,由max_entries字段定義為四對。我稍后會解釋為什么這個map中有四個條目。返回值4是用戶空間代碼訪問output map的文件描述符。
輸出中的下一個bpf()系統調用創建了config map:
bpf(BPF_MAP_CREATE, {map_type=BPF_MAP_TYPE_HASH, key_size=4, value_size=12, max_entries=10240, map_flags=0, inner_map_fd=0, map_name="config", map_ifindex=0, btf_fd=3,
btf_key_type_id=1,btf_value_type_id=4, btf_vmlinux_value_type_id=0, map_extra=0}, 128) = 5
這個map被定義為一個哈希表map,鍵的長度為4個字節(對應于一個32位整數,可以用來保存用戶ID),值的長度為12個字節(與msg_t結構的長度相匹配)。我沒有指定表的大小,所以它被賦予了BCC的默認大小,即10240個條目。這個bpf()系統調用也返回了一個文件描述符,即5,用于在將來的系統調用中引用這個config map。
你還可以看到字段btf_fd=3,它告訴內核使用之前獲取的BTF文件描述符3。正如你將在第5章中看到的,BTF信息描述了數據結構的布局,將其包含在map的定義中意味著有關于該map中使用的鍵和值類型布局的信息。這些信息被像bpftool這樣的工具用于漂亮地打印map轉儲,使它們更具可讀性——你在第3章中已經看到了一個示例
Loading a Program
bpf(BPF_PROG_LOAD, {prog_type=BPF_PROG_TYPE_KPROBE, insn_cnt=44, insns=0x78bfd9e09be8, license="GPL", log_level=0, log_size=0, log_buf=NULL, kern_version=KERNEL_VERSION(6, 5, 13), prog_flags=0, prog_name="hello", prog_ifindex=0, expected_attach_type=BPF_CGROUP_INET_INGRESS, prog_btf_fd=3, func_info_rec_size=8, func_info=0x5e16c4c71040, func_info_cnt=1, line_info_rec_size=16, line_info=0x5e16c2fb3d90, line_info_cnt=21, attach_btf_id=0, attach_prog_fd=0, fd_array=NULL}, 128) = 6
- prog_type字段描述了程序類型,這里表明它是要附加到一個kprobe上的。你將在第7章中了解更多關于程序類型的信息。
- insn_cnt字段表示“指令計數”,即程序中的字節碼指令數量。
- 組成這個eBPF程序的字節碼指令存儲在insns字段指定的內存地址中。
- 該程序被指定為GPL許可證,以便可以使用GPL許可證的BPF輔助函數。
- 程序名稱為hello。
- 雖然expected_attach_type字段的值為BPF_CGROUP_INET_INGRESS,這聽起來像是與入口網絡流量有關的內>容,但你知道這個eBPF程序將附加到一個kprobe上。實際上,expected_attach_type字段僅用于某些程序類型,而BPF_PROG_TYPE_KPROBE并不是其中之一。BPF_CGROUP_INET_INGRESS只是BPF附加類型列表中的第一個,所以它的值為0。
- prog_btf_fd字段告訴內核要與該程序一起使用哪個先前加載的BTF數據塊。這里的值3對應于你在BPF_BTF_LOAD系統調用中看到的返回的文件描述符(它與用于config map的BTF數據塊相同)。
Modifying a Map from User Space
b["config"][ct.c_int(0)] = ct.create_string_buffer(b"Hey root!")
b["config"][ct.c_int(501)] = ct.create_string_buffer(b"Hi user 501!")
對于的bpf()調用是:
bpf(BPF_MAP_UPDATE_ELEM, {map_fd=5, key=0xffffa7842490, value=0xffffa7a2b410,
flags=BPF_ANY}, 128) = 0
簡單明了。
BPF_MAP_UPDATE_ELEM命令用于更新map中的鍵值對。BPF_ANY標志表示如果該鍵在map中不存在,則應創建它。這里有兩個這樣的調用,對應于為兩個不同用戶ID配置的兩個條目
root@wp-virtual-machine:~# bpftool map dump name config
[{
"key": 501,
"value": {
"message": [72,105,32,117,115,101,114,32,53,48,49,33
]
}
},{
"key": 0,
"value": {
"message": "Hey root!"
}
}
]
bpftool如何知道如何格式化這個輸出呢?例如,它如何知道值是一個結構體,包含一個名為message的字段,該字段包含一個字符串?答案是它使用了在定義這個map的BPF_MAP_CREATE系統調用中包含的BTF信息中的定義。你將在下一章中看到BTF如何傳遞這些信息的更多細節。
現在你已經看到了用戶空間如何與內核交互以加載程序和map,并更新map中的信息。在你看到的系統調用序列中,程序還沒有被附加到一個事件上。這一步必須進行,否則程序將永遠不會被觸發。
提醒一下:不同類型的eBPF程序以各種不同的方式附加到不同的事件上!本章后面我會向你展示這個示例中用于附加到kprobe事件的系統調用,而在這種情況下不涉及bpf()。相反,在本章末尾的練習中,我將向你展示另一個示例,其中使用bpf()系統調用將程序附加到原始跟蹤點事件上。
在我們討論這些細節之前,我想討論一下當你停止運行程序時會發生什么。你會發現程序和map會自動卸載,這是因為內核使用引用計數來跟蹤它們。
BPF Program and Map References
你知道,通過bpf()系統調用將BPF程序加載到內核中會返回一個文件描述符。在內核中,這個文件描述符是對該程序的引用。進行系統調用的用戶空間進程擁有這個文件描述符;當該進程退出時,文件描述符被釋放,程序的引用計數減少。當BPF程序沒有引用時,內核會移除該程序。
當你將一個程序pin到文件系統時,會創建一個額外的引用。
Pinning
在之前不使用python加載而是手動加載ebpf程序中使用到了:
bpftool prog load hello.bpf.o /sys/fs/bpf/hello
這些固定的對象并不是持久化到磁盤上的真實文件。它們是在一個偽文件系統上創建的,該文件系統表現得像一個基于磁盤的常規文件系統,具有目錄和文件。但它們實際上是保存在內存中的,這意味著它們在系統重啟后不會保留
如果bpftool允許你加載程序而不固定它,那將毫無意義,因為當bpftool退出時,文件描述符會被釋放,如果引用計數為零,程序將被刪除,因此不會實現任何有用的效果。但是,將程序固定到文件系統意味著程序有一個額外的引用,因此在命令完成后程序仍然保持加載狀態。
當BPF程序附加到將觸發它的鉤子時,引用計數也會增加。這些引用計數的行為取決于BPF程序類型。你將在第7章中了解更多關于這些程序類型的信息,但有些類型與追蹤(如kprobes和tracepoints)相關,并且總是與用戶空間進程相關聯;對于這些類型的eBPF程序,當該進程退出時,內核的引用計數會減少。附加在網絡棧或控制組(cgroups,簡稱“控制組”)中的程序則與任何用戶空間進程無關,因此即使加載它們的用戶空間程序退出,它們仍然保持有效。你已經在使用ip link命令加載XDP程序時看到過這種情況:
wp@wp-virtual-machine:~/projects/learning-ebpf/chapter3$ sudo ip link set dev ens33 xdp obj hello.bp
f.o sec xdp
wp@wp-virtual-machine:~/projects/learning-ebpf/chapter3$ sudo bpftool prog list
...
253: xdp name hello tag d35b94b4c0c10efb gpl
loaded_at 2024-05-22T20:31:41+0800 uid 0
xlated 96B jited 64B memlock 4096B map_ids 71,70
btf_id 218
這個程序的引用計數非零,因為在ip link命令完成后,該程序仍然附加在XDP鉤子上。
eBPF映射(maps)也有引用計數,當引用計數降至零時,這些映射會被清理。每個使用映射的eBPF程序都會增加映射的引用計數,用戶空間程序持有映射的文件描述符也會增加引用計數。
有時eBPF程序的源代碼中可能定義了一個程序實際并不引用的映射。假設你想存儲一些關于程序的元數據,你可以將其定義為一個全局變量,正如你在前一章所見,這些信息被存儲在一個映射中。如果eBPF程序不操作這個映射,程序不會自動增加對該映射的引用計數。此時,可以使用BPF(BPF_PROG_BIND_MAP)系統調用將映射與程序關聯,這樣在用戶空間加載程序退出且不再持有文件描述符引用映射時,該映射不會被清理。
映射也可以固定到文件系統上,用戶空間程序可以通過知道映射的路徑來訪問這些映射。
另一種創建對BPF程序引用的方法是使用BPF鏈接(BPF link)。
BPF Links
BPF 鏈接提供了一個抽象層,介于 eBPF 程序和它附加的事件之間。BPF 鏈接本身可以固定到文件系統上,這會為程序創建一個額外的引用。這意味著將程序加載到內核中的用戶空間進程可以終止,但程序仍然會保持加載狀態。用戶空間加載程序的文件描述符會被釋放,減少對程序的引用計數,但由于 BPF 鏈接的存在,引用計數不會變為零。
如果你按照本章末尾的練習操作,你將有機會看到 BPF 鏈接的實際應用。現在,讓我們回到 hello-buffer-config.py 使用的 bpf() 系統調用序列
Additional Syscalls Involved in eBPF
回顧一下,到目前為止,你已經看到了通過 bpf() 系統調用將 BTF 數據、程序和映射,以及映射數據添加到內核中的過程。接下來,strace 輸出顯示的內容與設置 perf 緩沖區有關
本章的其余部分將深入探討使用 perf 緩沖區、環形緩沖區、kprobes 和映射迭代時涉及的系統調用序列。并不是所有的 eBPF 程序都需要執行這些操作,所以如果你趕時間或者覺得內容過于詳細,可以直接跳到本章總結部分。我不會介意的!
Initializing the Perf Buffer
你已經看到了 bpf(BPF_MAP_UPDATE_ELEM) 調用,這些調用向配置映射添加條目。接下來,輸出顯示了一些類似這樣的調用:
bpf(BPF_MAP_UPDATE_ELEM, {map_fd=4, key=0x7f33e52f9a10, value=0x7f33e8486a90, flags=BPF_ANY}, 128) = 0
這些調用看起來與定義配置映射條目的調用非常相似,不同之處在于,此處的映射文件描述符是4,代表輸出的 perf 緩沖區映射。和之前一樣,鍵和值都是指針,所以從這個 strace 輸出中無法知道鍵或值的數值。我看到這個 bpf() 系統調用重復了四次,所有參數的值都相同,不過沒有辦法知道這些指針所持有的值在每次調用之間是否發生了變化。查看這些 BPF_MAP_UPDATE_ELEM 調用會留下關于如何設置和使用緩沖區的一些未解問題。
- 為什么有四次調用 BPF_MAP_UPDATE_ELEM?這是否與輸出映射的最大條目數為四有關?
- 在這四個 BPF_MAP_UPDATE_ELEM 實例之后,strace 輸出中沒有出現更多的 bpf() 系統調用。這似乎有點奇怪,因為映射的存在是為了讓 eBPF 程序每次觸發時寫入數據,而且你已經看到用戶空間代碼顯示了數據。很明顯,這些數據不是通過 bpf() 系統調用從映射中檢索的,那么它是如何獲取的呢?
你還沒有看到任何證據表明 eBPF 程序是如何附加到觸發它的 kprobe 事件上的。為了解釋這些疑問,我需要讓 strace 顯示在運行這個示例時的更多系統調用,如下所示。.
$ strace -e bpf,perf_event_open,ioctl,ppoll ./hello-buffer-config.py
為簡潔起見,我將忽略與本示例的 eBPF 功能無關的 ioctl() 調用。

 浙公網安備 33010602011771號
浙公網安備 33010602011771號