
一鍵部署QwQ-32B推理模型,2種方式簡單、快速體驗
QwQ-32B推理模型正式發布并開源,憑借其卓越的性能和廣泛的應用場景,迅速在全球范圍內獲得了極高的關注度。基于阿里云函數計算 FC提供算力,Serverless+ AI 云原生應用開發平臺 CAP現已提供模型服務、應用模板兩種部署方式輔助您部署QwQ 32B系列模型。您選擇一鍵部署應用模板與模型進行對話或以API形式調用模型,接入AI應用中。歡迎您立即體驗QwQ-32B。
QwQ-32B更小尺寸,性能比肩全球最強開源推理模型
QwQ-32B在一系列基準測試中進行了評估,包括數學推理、編程和通用能力。以下結果展示了QwQ-32B與其他領先模型的性能對比,包括 DeepSeek-R1-Distilled-Qwen-32B、DeepSeek-R1-Distilled-Llama-70B、OpenAI-o1-mini以及原始的DeepSeek-R1-671B。

在測試數學能力的AIME24評測集上,以及評估代碼能力的LiveCodeBench中,千問QwQ-32B表現與DeepSeek-R1-671B相當,遠勝于OpenAI-o1-mini及相同尺寸的R1蒸餾模型。在由Meta首席科學家楊立昆領銜的“最難LLMs評測榜” LiveBench、谷歌等提出的指令遵循能力IFEval評測集、由加州大學伯克利分校等提出的評估準確調用函數或工具方面的BFCL測試中,千問QwQ-32B的得分均超越了DeepSeek-R1-671B。
前置準備
1.首次使用云原生應用開發平臺 CAP會自動跳轉到訪問控制快速授權頁面,滾動到瀏覽器底部單擊確認授權,等待授權結束后單擊返回控制臺。
2.本教程在函數計算中創建的GPU函數,函數運行使用的資源按照函數規格乘以執行時長進行計量,如果無請求調用,則只收取閑置預留模式下預置的快照費用,CAP中的極速模式通過預置實例快照實現毫秒級響應,其技術原理對應函數計算的閑置預留模式,適用于需要快速冷啟動的場景。建議您領取函數計算的試用額度抵扣資源消耗,超出試用額度的部分將自動轉為按量計費,更多計費詳情,請參見計費概述。
方式一:應用模板部署
創建項目
進入CAP控制臺單擊基于模板創建開始創建。
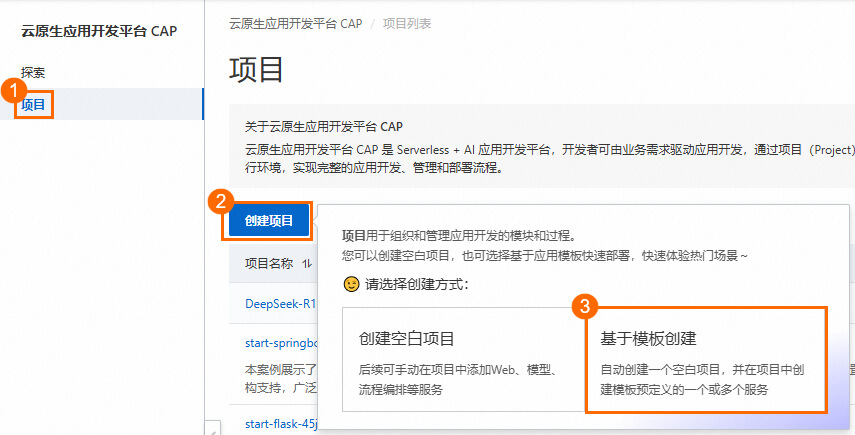
部署模板
1.在搜索欄輸入QWQ進行搜索,單擊基于 Qwen-QwQ 推理模型構建AI聊天助手,進入模板詳情頁,單擊立即部署。

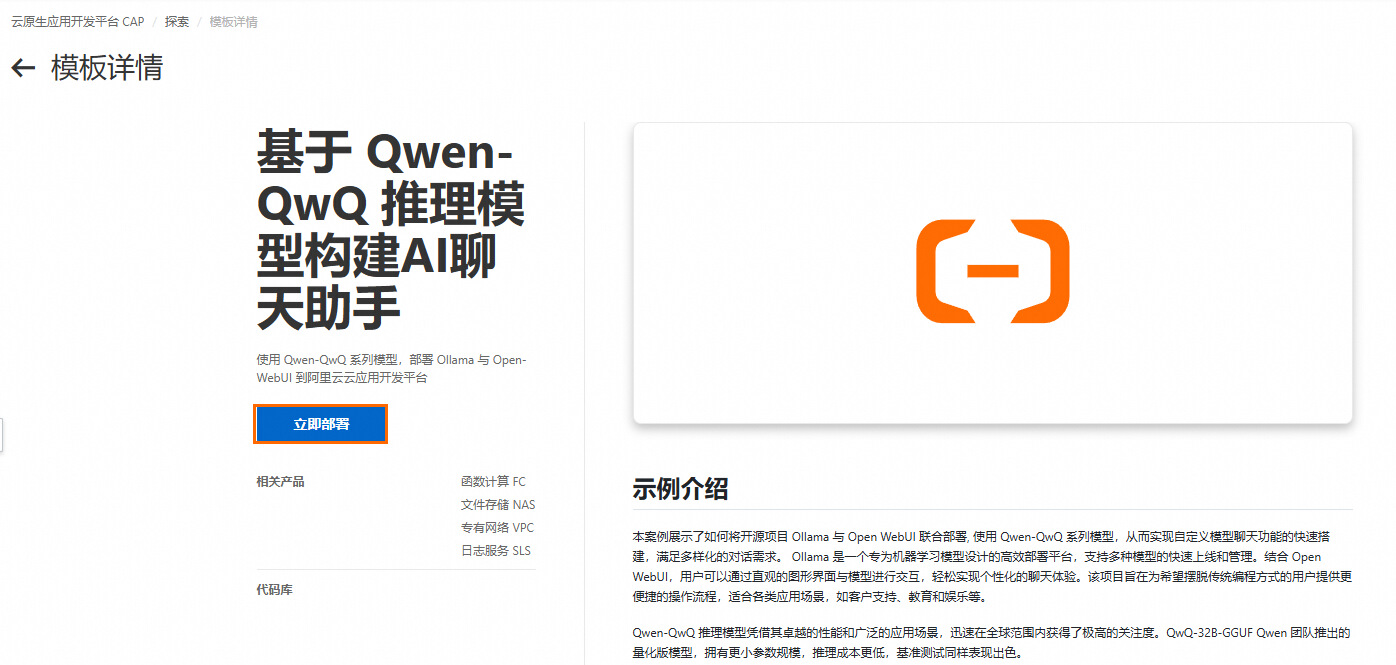
2.選擇地域,目前支持 北京、上海、杭州,單擊部署項目,在項目資源預覽對話框中,您可以看到相關的計費項,詳情請見計費涉及的產品。單擊確認部署,部署過程大約持續 10 分鐘左右,狀態顯示已部署表示部署成功。
說明
- 選擇地域時,一般是就近選擇地域信息,如果已經開啟了NAS文件系統,選擇手動配置模型存儲時,請選擇和文件系統相同的地域。
- 如果您在測試調用的過程中遇到部署異常或模型拉取失敗,可能是當前地域的GPU顯卡資源不足,建議您更換地域進行重試。


3.驗證應用
部署完畢后,點擊 Open-WebUI 服務,在訪問地址內找到公網訪問單擊訪問。在OpenWebUI界面體驗QwQ模型進行對話。

方式二:模型服務部署
使用API形式進行模型調用,接入線上業務應用。
創建空白項目
進入CAP控制臺單擊創建空白項目開始創建,并為項目命名。
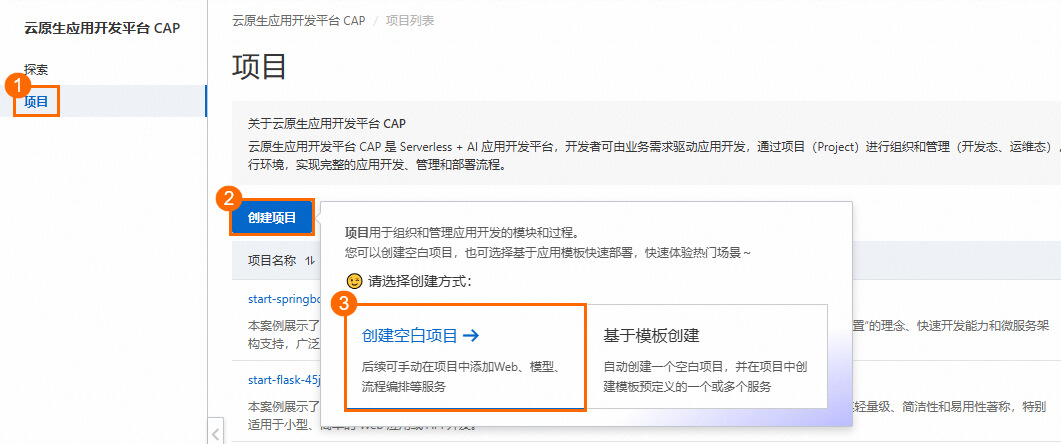

選擇模型服務
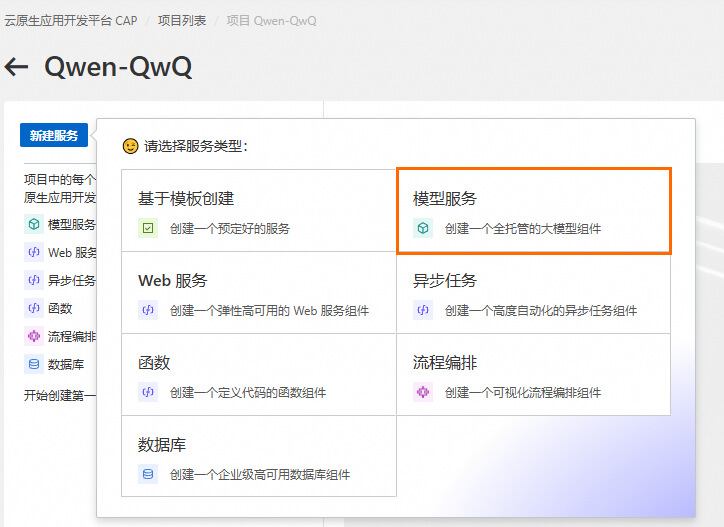
部署模型服務
1.選擇模型QwQ-32B-GGUF,目前僅支持杭州地域。

2.單擊資源配置,QwQ-32B-GGUF推薦使用 Ada 系列,可直接使用默認配置。您可以根據業務訴求填寫需要的卡型及規格信息。

3.單擊預覽并部署,在服務資源預覽對話框中,您可以看到相關的計費項,詳情請見計費涉及的產品。單擊確認部署,該階段需下載模型,預計等待10~30分鐘即可完成。

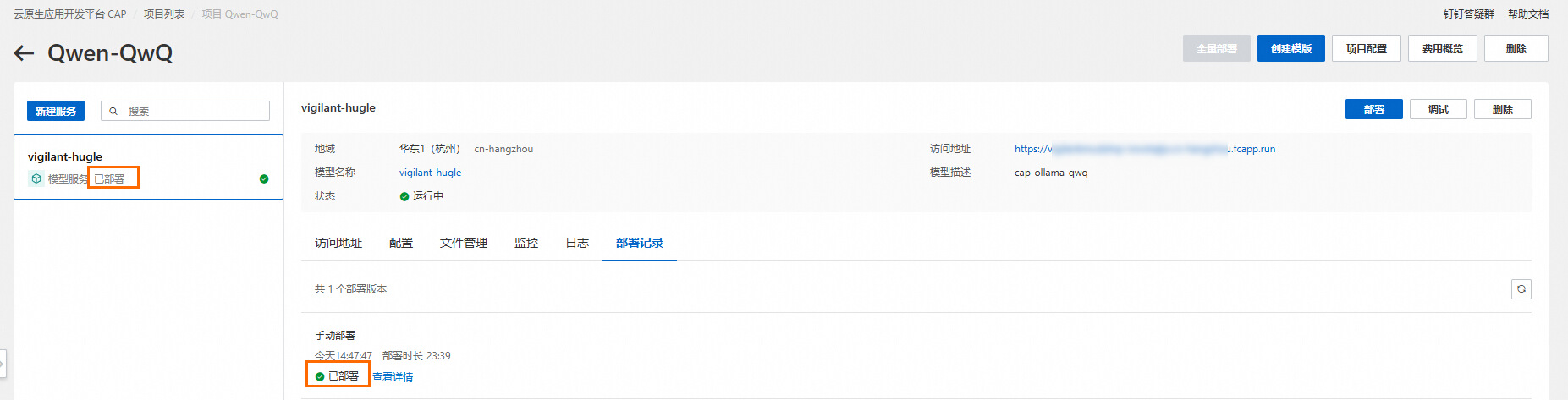
驗證模型服務
單擊調試,即可測試和驗證相關模型調用。


在本地命令行窗口中驗證模型調用。

第三方平臺 API 調用
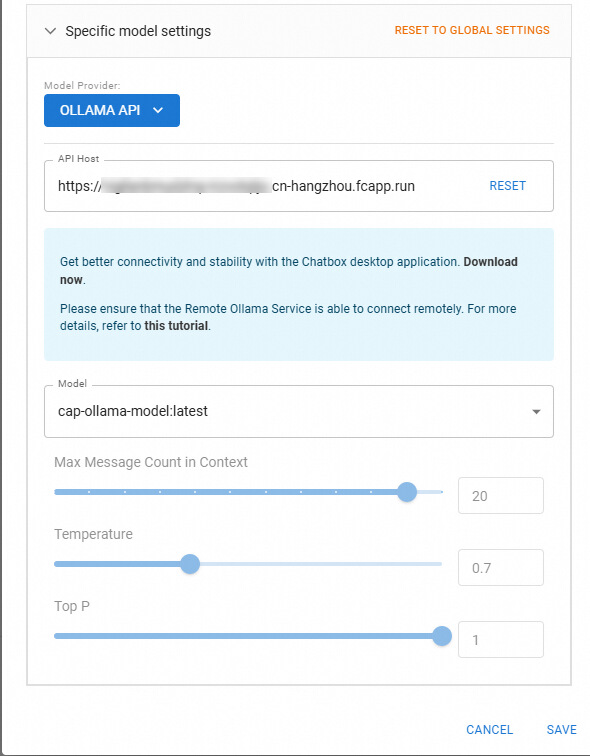
您可以選擇在Chatbox等其他第三方平臺中驗證和應用模型調用,以下以Chatbox為例。

刪除項目
您可以使用以下步驟刪除應用,以降低產生的費用。
1.進入項目詳情 > 點擊刪除,會進入到刪除確認對話框。
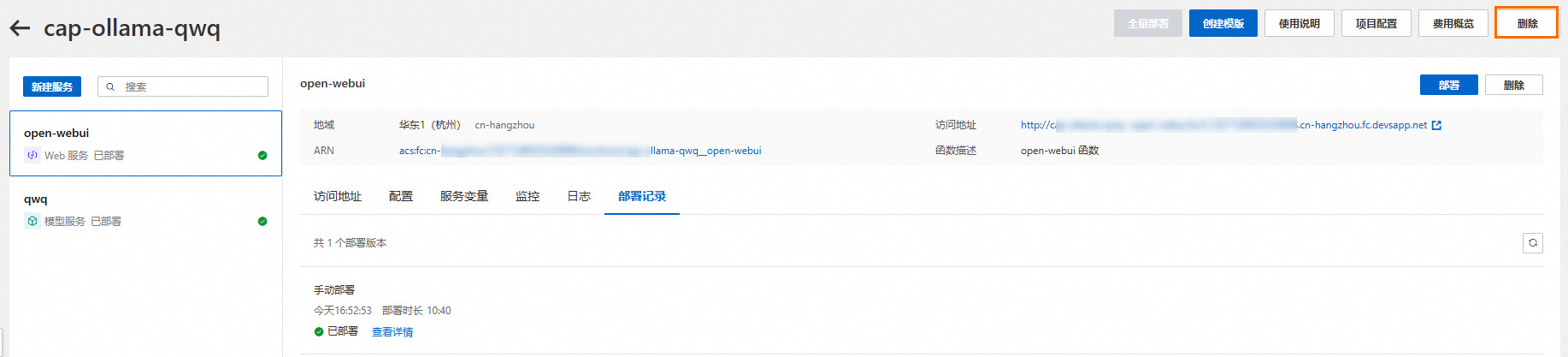
2.您可以看到要刪除的資源。默認情況下,云原生應用開發平臺 CAP會刪除項目下的所有服務。如果您希望保留資源,可以取消勾選指定的服務,刪除項目時只會刪除勾選的服務。

勾選我已知曉:刪除該項目及選中的服務將立刻中斷其所服務的線上業務,并且不可恢復,同時將徹底刪除其所依賴的云產品資源,然后單擊確定刪除。

 浙公網安備 33010602011771號
浙公網安備 33010602011771號