
DeepSeek 模型快速體驗,魔搭+函數(shù)計算一鍵部署模型上云
DeepSeek 模型近期在全網(wǎng)引發(fā)了廣泛關(guān)注,熱度持續(xù)攀升。其開源模型 DeepSeek-V3 和 DeepSeek-R1 在多個基準測試中表現(xiàn)優(yōu)異,在數(shù)學(xué)、代碼和自然語言推理任務(wù)上,性能與 OpenAI 的頂尖模型相當(dāng)。對于期待第一時間在本地進行使用的用戶來說,盡管 DeepSeek提供了從1.5B到70B參數(shù)的多尺寸蒸餾模型,但本地部署仍需要一定的技術(shù)門檻。對于資源有限的用戶進一步使用仍有難點。
為了讓更多開發(fā)者第一時間體驗 DeepSeek 模型的魅力,Modelscope 社區(qū) DeepSeek-R1-Distill-Qwen模型現(xiàn)已支持一鍵部署(SwingDeploy)上函數(shù)計算 FC 服務(wù),歡迎開發(fā)者立即體驗。
魔搭+函數(shù)計算,一鍵部署模型上云
SwingDeploy 是魔搭社區(qū)推出的模型一鍵部署服務(wù),支持將魔搭上的各種(包括語音,視頻,NLP等不同領(lǐng)域)模型直接部署到用戶指定的云資源上,比如函數(shù)計算FC(以下簡稱FC)GPU算力實例。本文介紹如何通過魔搭SwingDeploy服務(wù),快速將DeepSeek模型部署到阿里云函數(shù)計算FC平臺的閑置GPU實例,并對部署后的模型進行推理訪問。
函數(shù)計算平臺提供了低成本的閑置 GPU 實例,使用閑置GPU實例,將帶來如下優(yōu)勢:
● 實例快速喚醒:函數(shù)計算平臺會根據(jù)您的實時負載水平,自動將GPU實例進行凍結(jié)。凍結(jié)的實例接受請求前,平臺會自動將其喚醒。要注意,喚醒過程會存在2-5秒的延遲。
● 兼顧服務(wù)質(zhì)量與服務(wù)成本:閑置GPU實例的計費周期不同于按量GPU實例,閑置GPU實例會在實例閑置與活躍期間以不同的單價進行計費,從而大幅降低用戶使用GPU成本。相較于長期自建GPU集群,閑置GPU實例根據(jù)GPU繁忙程度提供降本幅度高達80%以上。
魔搭社區(qū)一鍵部署介紹:https://modelscope.cn/docs/model-service/deployment/intro
函數(shù)計算閑置GPU介紹:https://help.aliyun.com/zh/functioncompute/fc-3-0/user-guide/real-time-inference-scenarios-1
DeepSeek模型介紹
性能對齊OpenAI-o1正式版
DeepSeek-R1 在后訓(xùn)練階段大規(guī)模使用了強化學(xué)習(xí)技術(shù),在僅有極少標注數(shù)據(jù)的情況下,極大提升了模型推理能力。在數(shù)學(xué)、代碼、自然語言推理等任務(wù)上,性能比肩 OpenAI o1 正式版。
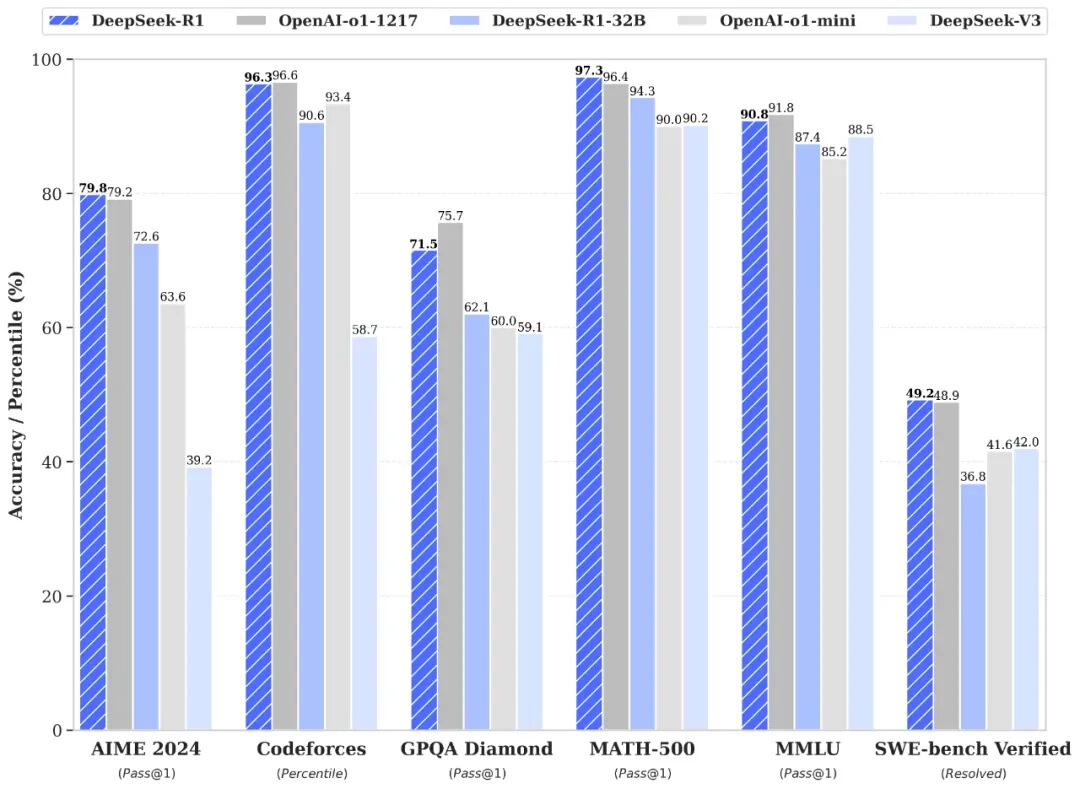
在此,DeepSeek將 DeepSeek-R1 訓(xùn)練技術(shù)全部公開,以期促進技術(shù)社區(qū)的充分交流與創(chuàng)新協(xié)作。
論文鏈接:
https://github.com/deepseek-ai/DeepSeek-R1/blob/main/DeepSeek_R1.pdf
模型鏈接:
https://modelscope.cn/collections/DeepSeek-R1-c8e86ac66ed943
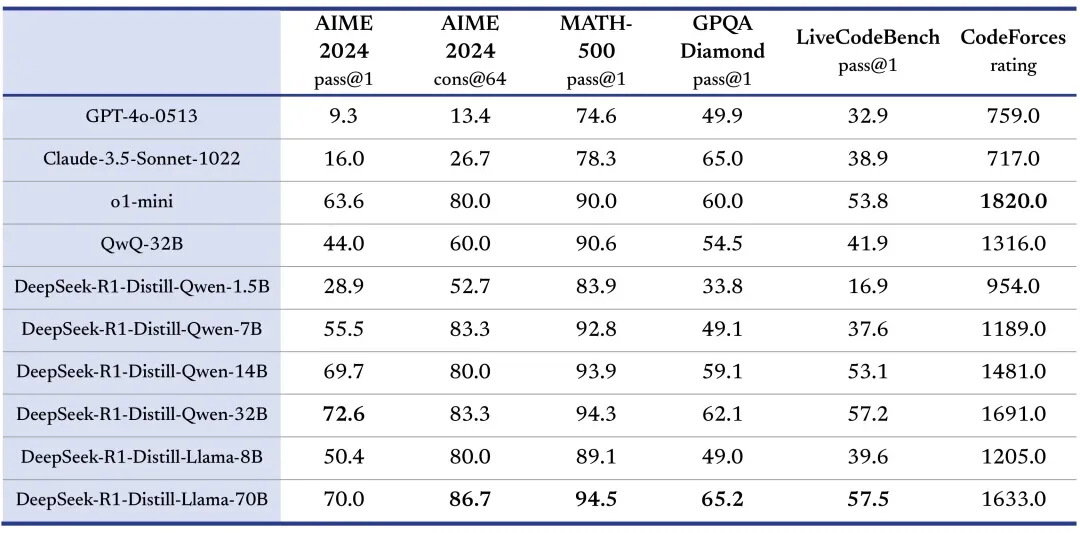
蒸餾小模型超越 OpenAI o1-mini
DeepSeek在開源 DeepSeek-R1-Zero 和 DeepSeek-R1 兩個 660B 模型的同時,通過 DeepSeek-R1 的輸出,蒸餾了 6 個小模型開源給社區(qū),其中 7B 和 14B 模型在多項能力上實現(xiàn)了對標 OpenAI o1-mini 效果、展現(xiàn)了較高的生產(chǎn)環(huán)境部署性價比。
部署步驟
函數(shù)計算提供有Ada系列48GB顯存的GPU,供DeepSeek-R1-Distill-Qwen如下參數(shù)版本的模型運行。
本文將繼續(xù)以DeepSeek-R1-Distill-Qwen-7B展現(xiàn)部署步驟,相同的部署步驟可應(yīng)用于1.5B、14B、32B參數(shù)量模型的部署。
前置條件:
● 賬號綁定與授權(quán):https://modelscope.cn/docs/model-service/deployment/swingdeploy-pipeline
部署步驟:
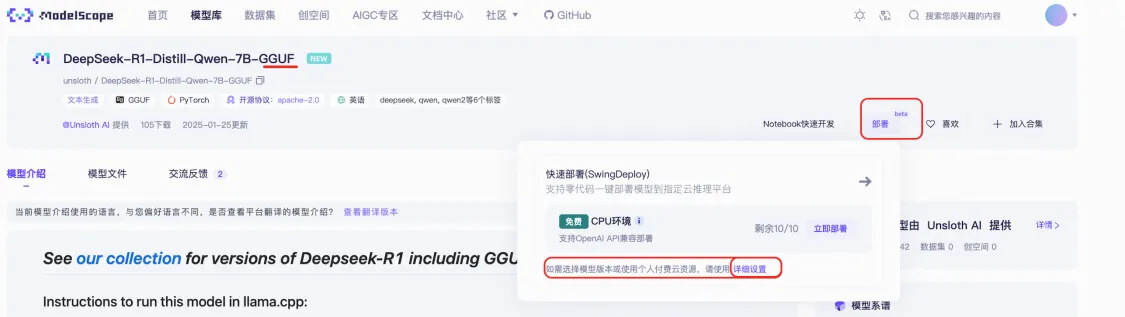
● 進入DeepSeek-R1-Distill-Qwen-7B模型頁:https://modelscope.cn/models/deepseek-ai/DeepSeek-R1-Distill-Qwen-7B
● 請選擇GGUF格式的量化版本:
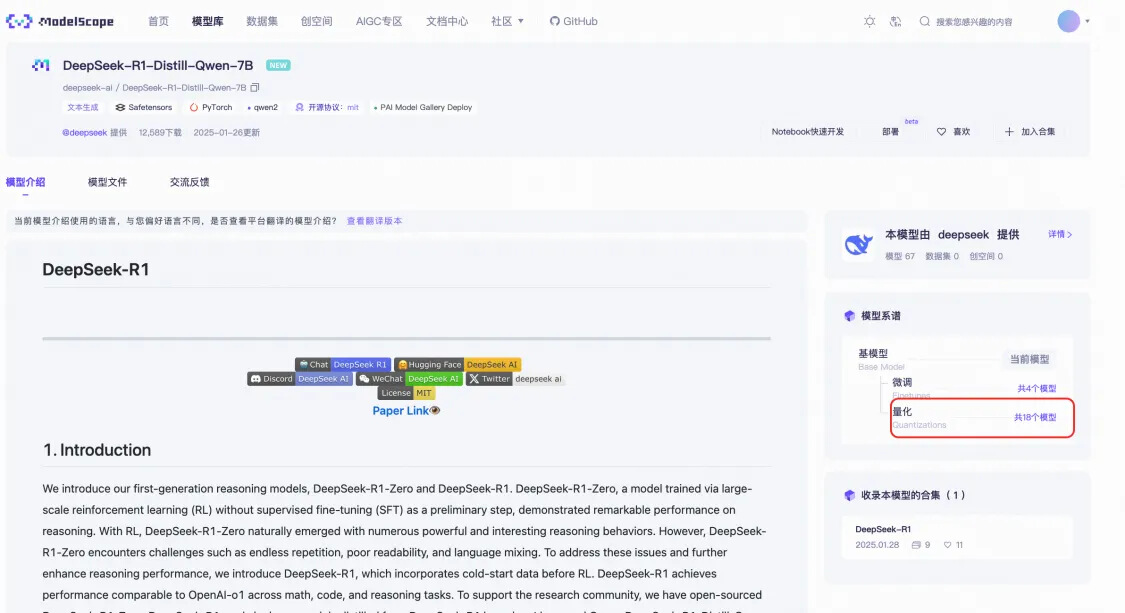
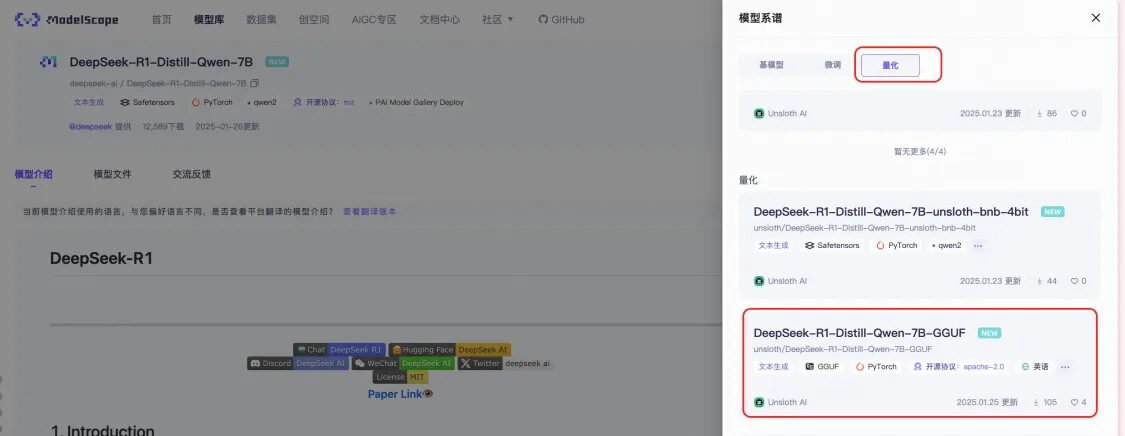
● 進入DeepSeek-R1-Distill-7B-GGUF模型頁后,點擊部署,部署類型選擇付費的FC GPU算力。
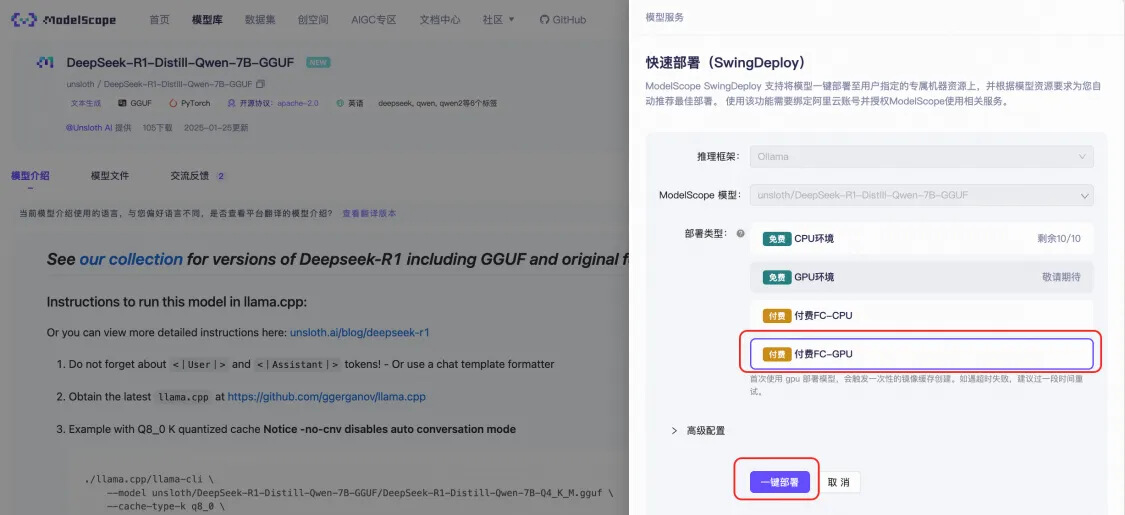

■ 部署地域:可選擇杭州或上海。
■ GPU卡型:默認將DeepSeek模型部署至Ada系列48GB顯存GPU,并開啟閑置GPU模式,以降低您的運行成本。
● 查看部署過程,確認部署成功。
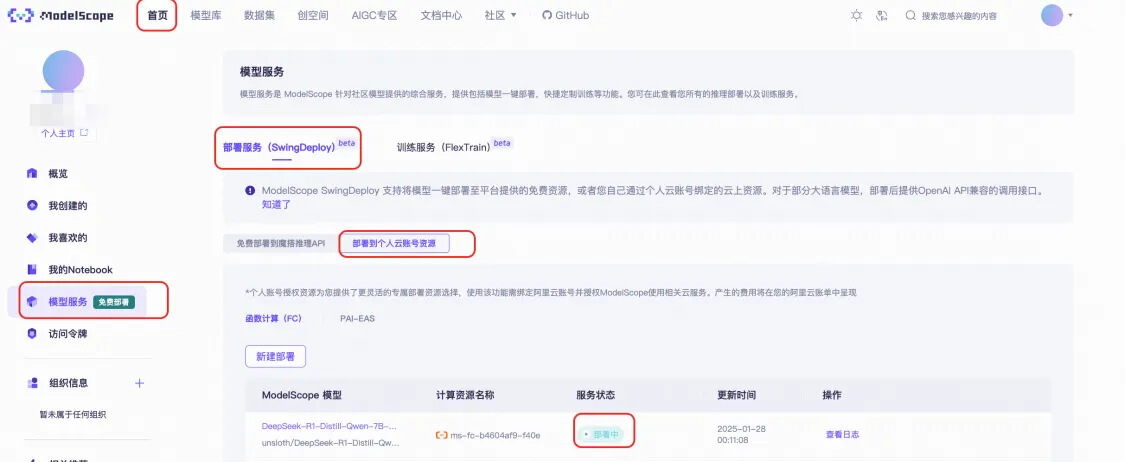
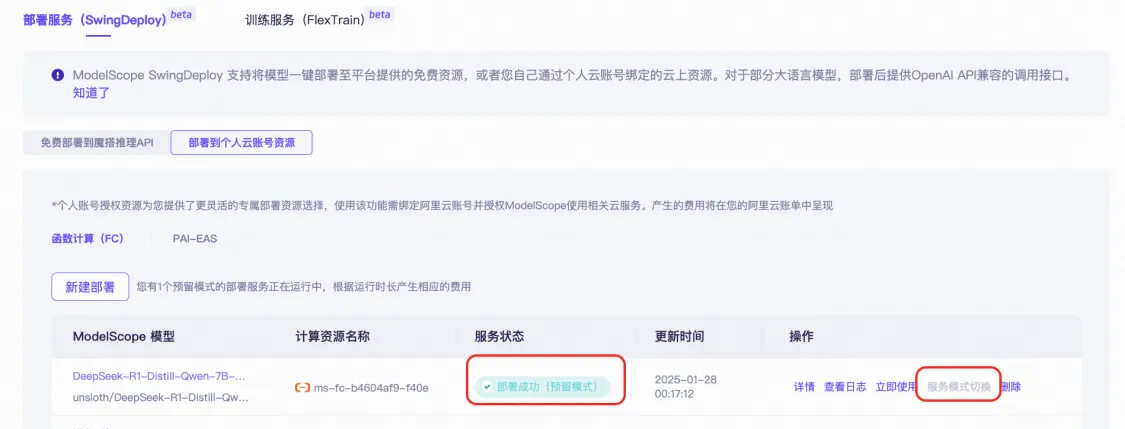
■ 確認狀態(tài)為部署成功(預(yù)留模式),如果不是,請點擊服務(wù)模式切換。
● 模型調(diào)用:
○ 查看調(diào)用代碼示例:
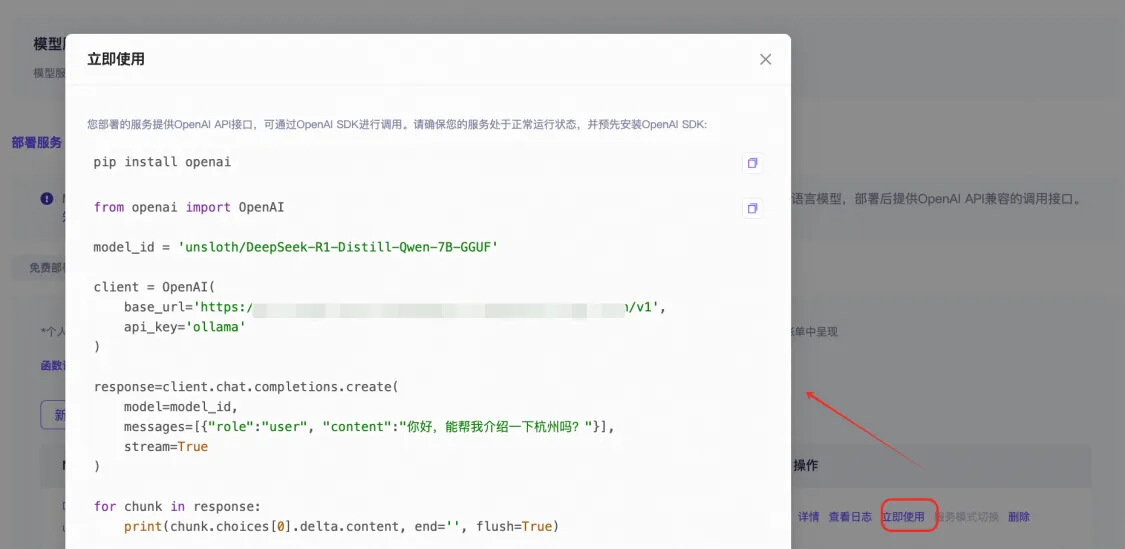
○ 調(diào)用模型,進行推理:
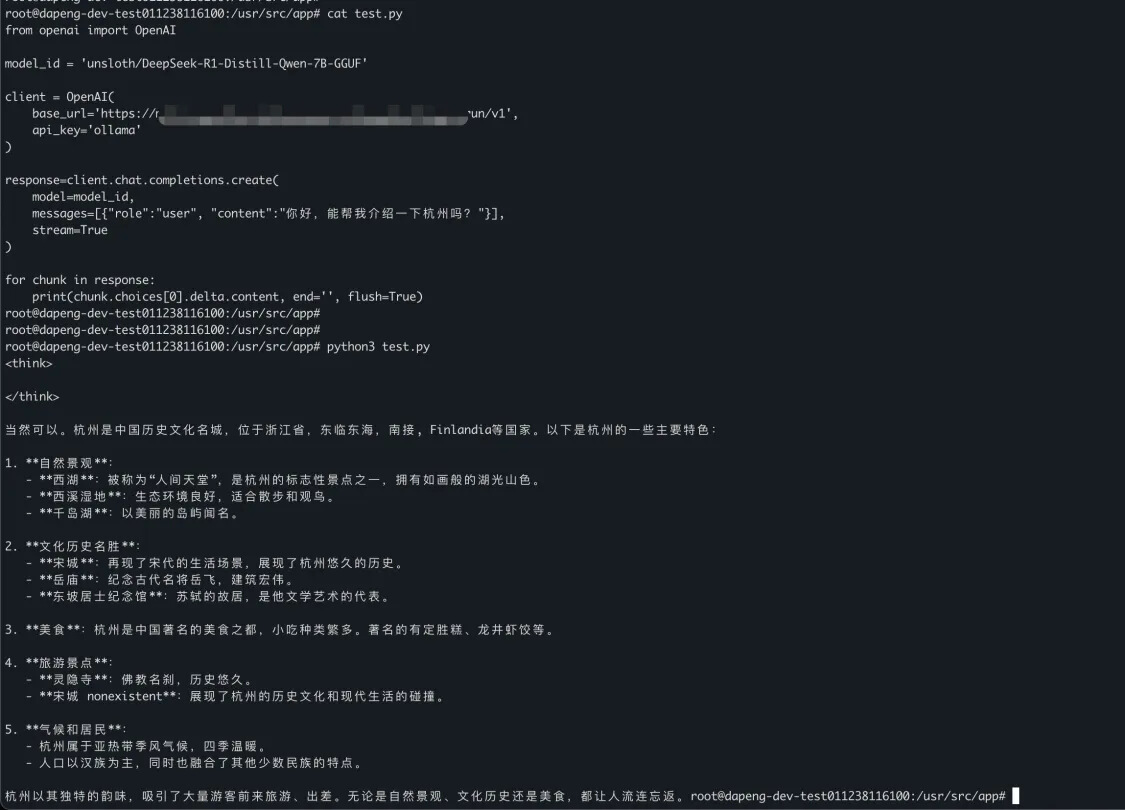
■ 首次調(diào)用由于模型加載導(dǎo)致耗時長,后續(xù)均為熱調(diào)用無此問題。
更進一步了解函數(shù)計算GPU
● FC GPU實例介紹規(guī)格和使用模式介紹:https://help.aliyun.com/zh/functioncompute/fc-3-0/product-overview/instance-types-and-usage-modes
● FC GPU實時推理場景(閑置GPU模式)介紹:https://help.aliyun.com/zh/functioncompute/fc-3-0/use-cases/real-time-inference-scenarios-1
● FC GPU準實時推理場景(按量GPU模式)介紹:https://help.aliyun.com/zh/functioncompute/fc-3-0/use-cases/quasi-real-time-inference-scenarios
● FC GPU異步推理場景介紹:https://help.aliyun.com/zh/functioncompute/fc-3-0/use-cases/offline-asynchronous-task-scenario
● FC GPU鏡像說明:https://help.aliyun.com/zh/functioncompute/fc-3-0/use-cases/image-usage-notes-1
● FC GPU模型存儲最佳實踐:https://help.aliyun.com/zh/functioncompute/fc-3-0/user-guide/gpu-instance-model-storage-best-practices
● FC GPU FAQ(模型托管、模型預(yù)熱):https://help.aliyun.com/zh/functioncompute/fc-3-0/support/faq-about-gpu-accelerated-instances-1
● FC GPU 應(yīng)用模板與示例代碼:https://github.com/devsapp/start-fc-gpu/tree/v3

 浙公網(wǎng)安備 33010602011771號
浙公網(wǎng)安備 33010602011771號