

mysql語句性能分析
1.開啟慢查詢
slow_query_log = 1 //開啟 slow_query_log_file = mysql_slow_query.log //日志文件位置 long_query_time = 1 //1s
通過開啟慢查詢?nèi)罩荆梢杂涗洺^long_query_time定義時間的sql語句
2.show profiles
SHOW PROFILES;
SHOW PROFILE FOR QUERY 1; //指定查看某個查詢詳細(xì)信息
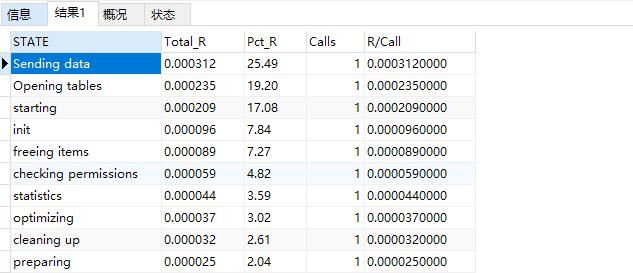
或者直接查詢INFORMATION_SCHEMA表
SELECT STATE , SUM(DURATION) AS Total_R, ROUND( 100 * SUM(DURATION) / (SELECT SUM(DURATION) FROM INFORMATION_SCHEMA.PROFILING WHERE QUERY_ID = 16 ) , 2 ) AS Pct_R , COUNT(*) AS Calls , SUM(DURATION) / COUNT(*) AS "R/Call" FROM INFORMATION_SCHEMA.PROFILING WHERE QUERY_ID = 16 GROUP BY STATE ORDER BY Total_R DESC
3.explain
EXPLAIN SELECT * FROM orders WHERE SenderName like '%123%' UNION ALL SELECT * FROM orders WHERE SenderName like '%wang%'

id : id列數(shù)字越大越先執(zhí)行,id列為null的就表是這是一個結(jié)果集
select_type
- simple:表示不需要union操作或者不包含子查詢的簡單select查詢。有連接查詢時,外層的查詢?yōu)閟imple,且只有一個
- primary:一個需要union操作或者含有子查詢的select,位于最外層的單位查詢的select_type即為primary。且只有一個
- union:union連接的兩個select查詢,第一個查詢是dervied派生表,除了第一個表外,第二個以后的表select_type都是union
- dependent union:與union一樣,出現(xiàn)在union 或union all語句中,但是這個查詢要受到外部查詢的影響
- union result:包含union的結(jié)果集,在union和union all語句中,因為它不需要參與查詢,所以id字段為null
- subquery:除了from字句中包含的子查詢外,其他地方出現(xiàn)的子查詢都可能是subquery
- dependent subquery:與dependent union類似,表示這個subquery的查詢要受到外部表查詢的影響
- derived:from字句中出現(xiàn)的子查詢,也叫做派生表,其他數(shù)據(jù)庫中可能叫做內(nèi)聯(lián)視圖或嵌套select
table : 顯示的查詢表名,如果查詢使用了別名,那么這里顯示的是別名,如果不涉及對數(shù)據(jù)表的操作,那么這顯示為null,如果顯示為尖括號括起來的<derived N>就表示這個是臨時表,后邊的N就是執(zhí)行計劃中的id,表示結(jié)果來自于這個查詢產(chǎn)生。如果是尖括號括起來的<union M,N>,與<derived N>類似,也是一個臨時表,表示這個結(jié)果來自于union查詢的id為M,N的結(jié)果集
partitons :
type : 依次從好到差:system,const,eq_ref,ref,fulltext,ref_or_null,unique_subquery,index_subquery,range,index_merge,index,ALL,除了all之外,其他的type都可以使用到索引,除了index_merge之外,其他的type只可以用到一個索引
- system:表中只有一行數(shù)據(jù)或者是空表,且只能用于myisam和memory表。如果是Innodb引擎表,type列在這個情況通常都是all或者index
- const:使用唯一索引或者主鍵,返回記錄一定是1行記錄的等值where條件時,通常type是const。其他數(shù)據(jù)庫也叫做唯一索引掃描
- eq_ref:出現(xiàn)在要連接過個表的查詢計劃中,驅(qū)動表只返回一行數(shù)據(jù),且這行數(shù)據(jù)是第二個表的主鍵或者唯一索引,且必須為not null,唯一索引和主鍵是多列時,只有所有的列都用作比較時才會出現(xiàn)eq_ref
- ref:不像eq_ref那樣要求連接順序,也沒有主鍵和唯一索引的要求,只要使用相等條件檢索時就可能出現(xiàn),常見與輔助索引的等值查找。或者多列主鍵、唯一索引中,使用第一個列之外的列作為等值查找也會出現(xiàn),總之,返回數(shù)據(jù)不唯一的等值查找就可能出現(xiàn)
- fulltext:全文索引檢索,要注意,全文索引的優(yōu)先級很高,若全文索引和普通索引同時存在時,mysql不管代價,優(yōu)先選擇使用全文索引
- ref_or_null:與ref方法類似,只是增加了null值的比較。實際用的不多
- unique_subquery:用于where中的in形式子查詢,子查詢返回不重復(fù)值唯一值
- index_subquery:用于in形式子查詢使用到了輔助索引或者in常數(shù)列表,子查詢可能返回重復(fù)值,可以使用索引將子查詢?nèi)ブ?/span>
- range:索引范圍掃描,常見于使用>,<,is null,between ,in ,like等運(yùn)算符的查詢中
- index_merge:表示查詢使用了兩個以上的索引,最后取交集或者并集,常見and ,or的條件使用了不同的索引,官方排序這個在ref_or_null之后,但是實際上由于要讀取所個索引,性能可能大部分時間都不如range
- index:索引全表掃描,把索引從頭到尾掃一遍,常見于使用索引列就可以處理不需要讀取數(shù)據(jù)文件的查詢、可以使用索引排序或者分組的查詢
- all:這個就是全表掃描數(shù)據(jù)文件,然后再在server層進(jìn)行過濾返回符合要求的記錄
possible_keys : 查詢可能使用到的索引都會在這里列出來
key : 查詢真正使用到的索引,select_type為index_merge時,這里可能出現(xiàn)兩個以上的索引,其他的select_type這里只會出現(xiàn)一個
key_len : 用于處理查詢的索引長度,如果是單列索引,那就整個索引長度算進(jìn)去,如果是多列索引,那么查詢不一定都能使用到所有的列,具體使用到了多少個列的索引,這里就會計算進(jìn)去,沒有使用到的列,這里不會計算進(jìn)去。留意下這個列的值,算一下你的多列索引總長度就知道有沒有使用到所有的列了。要注意,mysql的ICP特性使用到的索引不會計入其中。另外,key_len只計算where條件用到的索引長度,而排序和分組就算用到了索引,也不會計算到key_len中
ref : 如果是使用的常數(shù)等值查詢,這里會顯示const,如果是連接查詢,被驅(qū)動表的執(zhí)行計劃這里會顯示驅(qū)動表的關(guān)聯(lián)字段,如果是條件使用了表達(dá)式或者函數(shù),或者條件列發(fā)生了內(nèi)部隱式轉(zhuǎn)換,這里可能顯示為func
rows : 執(zhí)行計劃中估算的掃描行數(shù),不是精確值
filtered : 使用explain extended時會出現(xiàn)這個列,5.7之后的版本默認(rèn)就有這個字段,不需要使用explain extended了。這個字段表示存儲引擎返回的數(shù)據(jù)在server層過濾后,剩下多少滿足查詢的記錄數(shù)量的比例,注意是百分比,不是具體記錄數(shù)
Extra : 這個列可以顯示的信息非常多,有幾十種,常用的有
- distinct:在select部分使用了distinc關(guān)鍵字
- no tables used:不帶from字句的查詢或者From dual查詢
- 使用not in()形式子查詢或not exists運(yùn)算符的連接查詢,這種叫做反連接。即,一般連接查詢是先查詢內(nèi)表,再查詢外表,反連接就是先查詢外表,再查詢內(nèi)表
- using filesort:排序時無法使用到索引時,就會出現(xiàn)這個。常見于order by和group by語句中
- using index:查詢時不需要回表查詢,直接通過索引就可以獲取查詢的數(shù)據(jù)
- using join buffer(block nested loop),using join buffer(batched key accss):5.6.x之后的版本優(yōu)化關(guān)聯(lián)查詢的BNL,BKA特性。主要是減少內(nèi)表的循環(huán)數(shù)量以及比較順序地掃描查詢
- using intersect:表示使用and的各個索引的條件時,該信息表示是從處理結(jié)果獲取交集
- using union:表示使用or連接各個使用索引的條件時,該信息表示從處理結(jié)果獲取并集
- using sort_union和using sort_intersection:與前面兩個對應(yīng)的類似,只是他們是出現(xiàn)在用and和or查詢信息量大時,先查詢主鍵,然后進(jìn)行排序合并后,才能讀取記錄并返回
- using temporary:表示使用了臨時表存儲中間結(jié)果。臨時表可以是內(nèi)存臨時表和磁盤臨時表,執(zhí)行計劃中看不出來,需要查看status變量,used_tmp_table,used_tmp_disk_table才能看出來
- using where:表示存儲引擎返回的記錄并不是所有的都滿足查詢條件,需要在server層進(jìn)行過濾。查詢條件中分為限制條件和檢查條件,5.6之前,存儲引擎只能根據(jù)限制條件掃描數(shù)據(jù)并返回,然后server層根據(jù)檢查條件進(jìn)行過濾再返回真正符合查詢的數(shù)據(jù)。5.6.x之后支持ICP特性,可以把檢查條件也下推到存儲引擎層,不符合檢查條件和限制條件的數(shù)據(jù),直接不讀取,這樣就大大減少了存儲引擎掃描的記錄數(shù)量。extra列顯示using index condition
- firstmatch(tb_name):5.6.x開始引入的優(yōu)化子查詢的新特性之一,常見于where字句含有in()類型的子查詢。如果內(nèi)表的數(shù)據(jù)量比較大,就可能出現(xiàn)這個
- loosescan(m..n):5.6.x之后引入的優(yōu)化子查詢的新特性之一,在in()類型的子查詢中,子查詢返回的可能有重復(fù)記錄時,就可能出現(xiàn)這個

 浙公網(wǎng)安備 33010602011771號
浙公網(wǎng)安備 33010602011771號