
理解Node.js 的重要概念
Node.js是什么
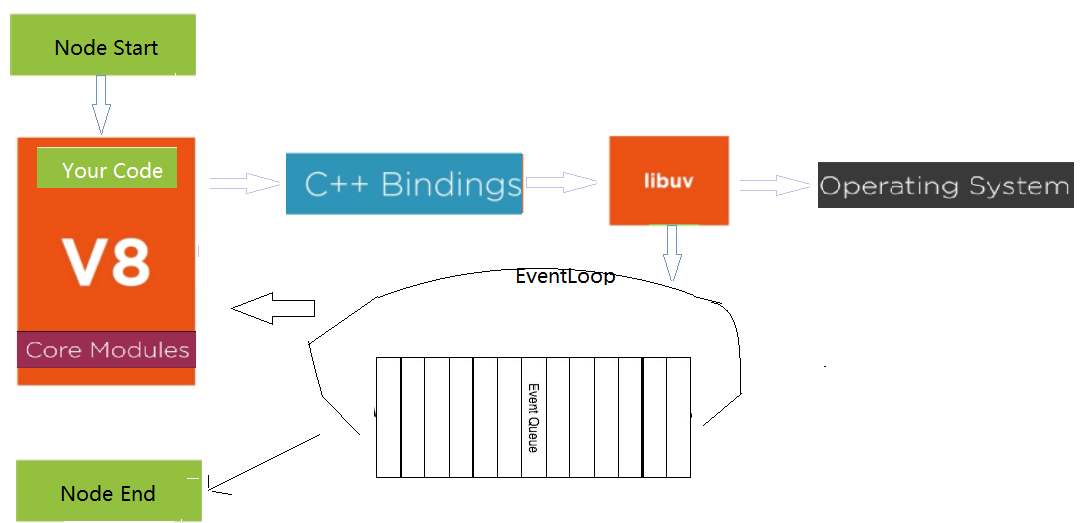
Node.js是JavaScript的運行時(runtime),終于脫離了瀏覽器也能運行JavasScript了。同時,Node.js又暴露fs,http等對象給JS,使JS能夠進行文件讀寫,創建服務器等。Node.js既能運行JS,又賦于了JS更多功能(文件讀寫,創建服務器等),使得JS語言更加通用了。Node.js是怎么做到的?它內嵌了V8,可以編譯和運行JS,也能把JS數據類型轉換成C++數據類型,同時又提供了C++ bind,可以使用JS調用C++,調用libuv(異步I/O)等C++庫,最后提供l了事件循環,替換了V8的默認的事件循環(V8的事件循環是插拔式的),事件循序就是一個C程序,和瀏覽器環境一樣了。看一下Node.js暴露的fs模塊,Node.js項目下的lib文件夾就是Node.js暴露給JS的所有對象,fs.js就是fs對象,文件開頭
const binding = internalBinding('fs');
const { FSReqCallback, statValues } = binding;
internalBinding就是C++ binding。internalBinding('fs'); 就是調用和加載C++實現的fs模塊(src文件夾中node_file.cc文件)。看一個readFile方法最后部分
const req = new FSReqCallback(); req.context = context; req.oncomplete = readFileAfterOpen; binding.open(pathModule.toNamespacedPath(path), flagsNumber, 0o666, req); }
new FSReqCallback() 和binding.open,JS怎么直接使用C++中的函數? 把C++函數放到內置模塊的exports上和 FunctionTemplate。binding.open 就是通過exports實現的,在node_file.cc最后, NODE_BINDING_PER_ISOLATE_INIT(fs, node::fs::CreatePerIsolateProperties), CreatePerIsolateProperties方法SetMethod(target, "open", Open), setMethod設置了open 并綁定C++的open方法,binding.open相當于調用了C++ 的Open方法,還有一個問題,調用binding.open方法時,傳遞過來參數是JS中定義數據類型,C++ 怎么認識呢?C++ 確實不認識JS中的數據類型,需要轉換。使用V8進行轉換, 文件的開始部分
using v8::Array; using v8::BigInt; using v8::Boolean;
new FSReqCallback()是通過V8的FunctionTemplate,V8 template可以動態生成JS中沒有函數, 供JS使用。還是node_fille.cc,
// Create FunctionTemplate for FSReqCallback Local<FunctionTemplate> fst = NewFunctionTemplate(isolate, NewFSReqCallback); fst->InstanceTemplate()->SetInternalFieldCount( FSReqBase::kInternalFieldCount); fst->Inherit(AsyncWrap::GetConstructorTemplate(isolate_data)); SetConstructorFunction(isolate, target, "FSReqCallback", fst);
FSReqCallback模版調用NewFSReqCallback, NewFSReqCallback又調用了FSReqCallback,
void FSReqCallback::Reject(Local<Value> reject) { MakeCallback(env()->oncomplete_string(), 1, &reject); } void FSReqCallback::Resolve(Local<Value> value) { Local<Value> argv[2] { Null(env()->isolate()), value }; MakeCallback(env()->oncomplete_string(), value->IsUndefined() ? 1 : arraysize(argv), argv); }
FSReqCallback模版創建一個對象,有Resolve和Reject方法,同時oncomplete賦上回調函數readFileAfterOpen。看回bind.open使用的C++open方法,
if (argc > 3) { // open(path, flags, mode, req) FSReqBase* req_wrap_async = GetReqWrap(args, 3);AsyncCall(env, req_wrap_async, args, "open", UTF8, AfterInteger,
uv_fs_open, *path, flags, mode);
AsyncCall就是調用libuv的open方法,它是異步的,完成后,就把AfterInteger放到事件隊列中,事件循環取出執行AfterInteger。node程序執行時,主程序執行完以后,就會啟動事件循環,
void AfterInteger(uv_fs_t* req) { FSReqBase* req_wrap = FSReqBase::from_req(req); if (after.Proceed()) req_wrap->Resolve(Integer::New(req_wrap->env()->isolate(), result)); }
req_wrap就是FSReqCallback對象,調用了它的Resove方法,MakeCallback第一個參數env()->oncomplete_string() 就是oncomplete, 最終執行了在fs.js中綁定的JS的回調函數(req.oncomplete = readFileAfterOpen;), 當然JS的執行還是調用V8來執行。
事件循環
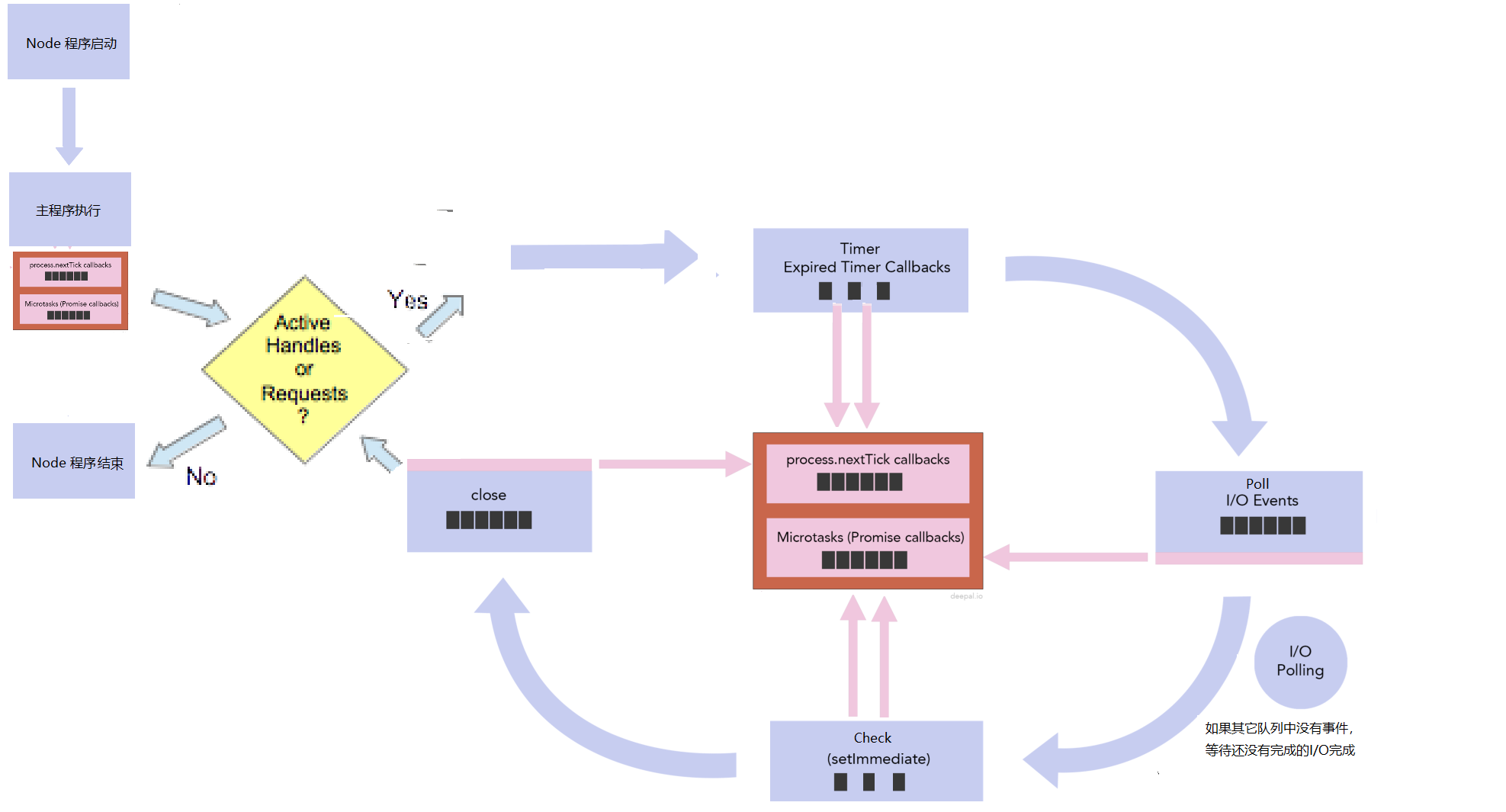
Node.js的事件循環并不是循環一個隊列 ,而是循環多個隊列,不同類型的事件放到不同的隊列中。libuv中提供了time,poll,check和close callbak等隊列,Node.js本身提供nextTick隊列和microtasks隊列。timer隊列放的是過期的setTimeout, setInterval的回調函數,poll隊列放的是I/O相關的回調函數,check隊列放的是setImmediate注冊的回調函數。close隊列放的是close事件的回調函數,比如socket.on('close', callback); callback就放到這個隊列中。nextTick隊列就是process.nexttick的回調函數和microtasks隊列是promise回調函數。
node index.js,index.js開始執行(同步代碼執行),執行完成后,Node.js就會檢查nextTick隊列和microtasks隊列,nextTick隊列的優先級比microtasks隊列優先高,先把nextTick隊列中的所有事件都執行完,再執行microtasks隊列中的所有事件,如果microtasks隊列中的事件又調用了process.nextTick, 等microtasks隊列中的所有事件都執行完畢,Node.js又會返回執行nextTick隊列中的事件,直到nextTick和microtasks隊列中所有事件都執行完,再看在index.js執行的過程中有沒有添加事件到libuv隊列中,就是看有沒有active handle 或 active request。如果沒有,就不會開啟事件循環,如果有,就開啟事件循環,事件循環按照 timer -> poll -> check -> close callbacks 的順序循環,到timer和check階段時,每執行完隊列中的一個事件,就會檢查nextTick隊列和microtask隊列,而poll和check階段,是把該隊列中的所有事件都執行完,再檢查nextTick隊列和microtask隊列。都是先檢查process.nextick隊列,再檢查microtask隊列,只有next tick隊列中的所有事件都執行完畢,才會執行microtask隊列中的事件,process.nextick隊列的優先級比microtaks隊列的高。循環完一遍,再看有沒有active handle或active request,如果沒有,Node.js程序退出,如果有,接著按timer -> poll -> check -> close callbacks 的順序循環,只要有active handle或active request, Node.js程序就永遠執行。handle代表長期存在的對象,例如計時器,TCP/UDP 套接字,requests表示短暫的操作,例如讀取或寫入文件或建立網絡連接。
const fs = require("fs");
Promise.resolve().then(() => console.log('promise1 resolved'));
Promise.resolve().then(() => {
console.log('promise2 resolved');
process.nextTick(() => console.log('next tick inside promise'));
});
process.nextTick(() => console.log('next tick1'));
setImmediate(() => console.log('set immedaite1'));
setTimeout(() => {
console.log('setTimeout 1');
Promise.resolve().then(() => {
console.log('setTimeout1 Promise');
})
}, 0)
setTimeout(() => console.log('setTimeout 2'), 0);
fs.readFile(__filename, () => {
console.log("readFile");
});
for (let i = 0; i < 2000000000; i++) {}
執行結果如下
/* next tick1 promise1 resolved promise2 resolved // microtasks隊列添加next tick inside promise到nexttick隊列。microtasks所有事件完成后,node再一次執行nextTick隊列中的事件。執行完microtasks和nextTick的所有事件之后,事件循環移動到timer階段 next tick inside promise setTimeout 1 // setTimeout 1把setTimeout1 Promise放到micorTask隊列,此時timer隊列一個事件也執行完了,就檢查micorTask隊列,正好執行setTimeout1 Promise,再回到timer隊列繼續執行,setTimeout2執行了。 setTimeout1 Promise set timeout2 // 這個有點奇怪,不應該是先(readFile),再(set immedaite1)嗎?這是因為io隊列的放置方式有點特別,是在I/O polling 階段放置的。 set immedaite1 readFile */
當事件循環到poll階段,隊列中有I/O事件,它會把隊列中的所有I/O事件都執行完畢,但第一次進來的時候,I/O隊列是空,就要到I/O polling, I/O polling 會檢查每一個I/O有沒有完成,比如readFile有沒有完成,在上面的程序中,它肯定是完成了,就把readFile放到I/O隊列中,到底I/O polling 要polling多長時間?如果沒有active handle 和active request,就不polling了,如果有close事件,也不polling了,但如果有active handle 和active request,但沒有close事件呢?這要看Timer, setImmediate 有沒有?如果有setImmediate,它也不會polling,如果沒有,再看timer有過期的事件要處理,如果有,它也不會polling,如果沒有,node會計算,到過期時間的間隔,然后等待這個間隔,如果沒有setimeout和setimmediate,它會一直在這里polling,polling也就解釋了服務器程序一直不停止的原因。在上面的程序中,有setImmediate,所有先執行了set Immediate 1, 再一次循環中,執行readFile。
注意一個seTimeout 設為0,
setTimeout(function() { console.log('setTimeout') }, 0); setImmediate(function() { console.log('setImmediate') });
以上程序的輸出結果并不能被保證。node.js內部最小的timeout是1ms,即使寫了0,node.js也會把它變成1ms。當用setTimeout或setInterval 添加一個定時器時,Node.js會把定時器和相應的回調函數放到定時器堆中。每一次事件循環執行到timer階段,都會調用系統時間,到堆中看看有沒有定時器過期,如果有,就會把對應的回調函數,放到隊列中。獲到系統時間可能需要小于1ms,也可能大于1ms的時間。如果時間少于1ms,timer 并不過期,事件循環就會到setImmediate,如果獲取時間大于1ms,過期了,它就會執行setTimeout的回調函數。怎樣計算過期時間?setTimeout 返回一個timeOut對象,它有兩個屬性,一個是_idleTimeout, 就是setTimeout第二個參數 0ms, 一個是_idleStart:它是Node程序啟動后,執行setTimeout語句時創建的時間。只要執行到timer階段,拿獲取到的系統時間減去這兩個時間,就會計算出有沒有過期。
異步I/O
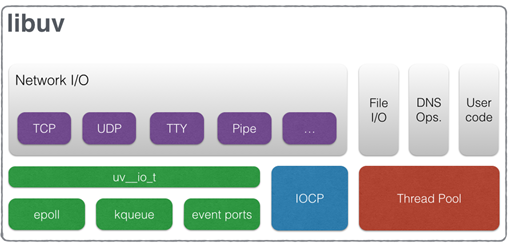
Node.js所有I/O是異步的(libuv庫提供的),但實現方式卻不相同,這是因為底層的操作系統并不完全支持異步I/O。網絡I/O,Linux提供epoll,Mac提供了kqueue,windows提供了IOCP( IOCP (Input Output Completion Port)),它們原生支持異步,但文件I/O不行,Linux并不支持完全異步的文件讀取,只能使用線程池。只要I/O不能通過原生異步(epoll/kqueue/IOCP)來解決,就使用線程池. Node.js會盡最大可能地使用原生異步I/O, 對于那些阻塞的或非常復雜才能解決的I/O類型,它使用線程池。高CPU消耗的功能也是使用線程池,比如壓縮,加密。node.js 默認開啟4個線程
看一下下面的代碼,https網絡I/O,crytpo(加密)高CPU消耗,fs 文件I/O
const https = require('https');
const crypto = require('crypto');
const fs = require('fs');
const start = Date.now();
function doRequest() {
https.request('https://www.baidu.com/', res => {
res.on('data', () => {})
res.on('end', () => {console.log('http:', Date.now() - start)})
}).end();
}
function doPbkdf() {
crypto.pbkdf2('a', 'b', 100000, 512, 'sha512', () => {console.log('pbkdf', Date.now() - start)})
}
doRequest();
fs.readFile(__filename, () => { console.log('fs:', Date.now() - start);})
doPbkdf();
doPbkdf();
doPbkdf();
doPbkdf();
執行結果是
http: 113 pbkdf 416 fs: 417 pbkdf 424 pbkdf 430 pbkdf 451
https是網絡I/O,不走線程池,它調用epoll就返回了,等操作系統返回結果,它執行多少時間,就是多少時間,和其它函數沒有關系。但Pbkdf和fs需要創建線程,由于默認4個線程,有一個pbkdf函數在等待中。
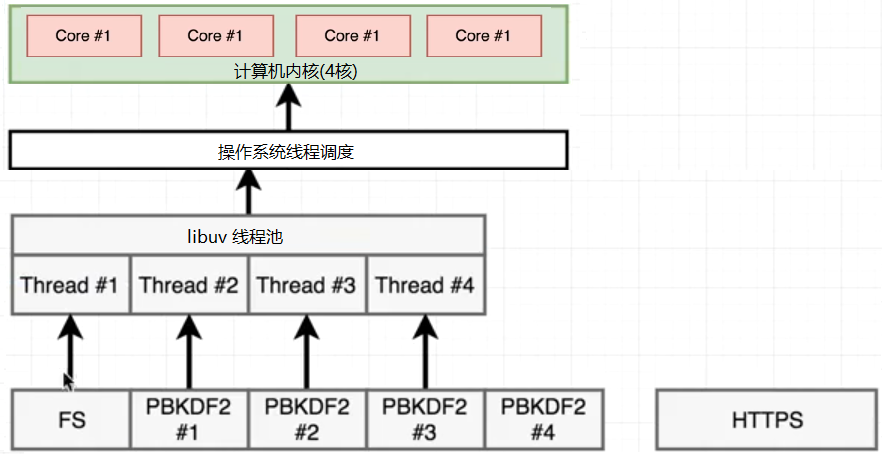
由于fs.readFile是JS層面的內容,分為好幾個步驟來完成的,比如先open文件,再read文件。open后就把open的回調函數(read)放到循環隊列中,fs占用的線程就釋放了,所以它不會一直占用線程,libuv把這個線程給了#4,加密一直占用一個線程,當事件循環執行到read時,沒有線程了,FS線程只能等待,
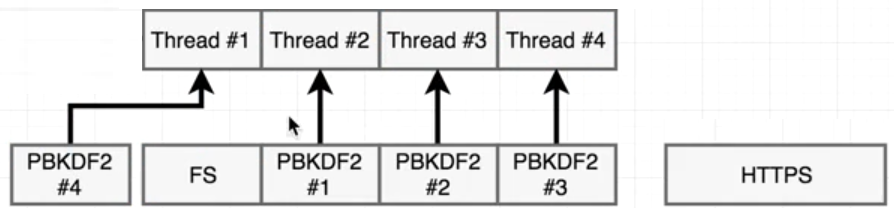
只用當一個pdkb2完成,才能有空余的線程,才能分給FS,所以結果中有一個hash比fs先返回了,現在4個線程4個任務,等待操作系統皇返回結果就可以了。libuv也會調度線程,用戶態線程的調度。可以改變線程的個數,在文件的開頭process.env.UV_THREADPOOL_SIZE = 5; 這時5個任務,5個線程,libuv不用調度線程,哪個執行完,哪個先返回。再次執行
fs: 14 http: 138 hash 416 hash 427 hash 444 hash 462
EventEmitter(事件發射器)
EventEmitter和events模塊是純JS層面的內容,它和事件循環沒有關系,和底層的libuv也沒有關系,它只是一種設計模式,事件驅動的編程方式。一個對象擁有emit和on方法,on方法就所有事件函數保存起來,當調用對象的emit,就把保存的函數,都執行一遍,什么都沒有涉及,只是js層面的東西,js主線程執行,
const EventEmitter = require('node:events') const em = new EventEmitter(); em.on('myEvent', data => console.log(data)); console.log('Statement A'); em.emit('myEvent', 'Statement B'); console.log('Statement C')
輸出Statement A, Statement B, Statement C, 程序同步執行,當emit事件時,所有監聽這個事件的回調函數都執行一遍,再執行后面的代碼。我們也可以實現一個EventEmitter。
class EventEmitter { listeners = {}; // key-value pair on(event, fn) { this.listeners[event] = this.listeners[event] || []; this.listeners[event].push(fn); return this; } emit(eventName, ...args) { let fns = this.listeners[eventName]; if (!fns) return false; fns.forEach((f) => { f(...args); }); return true; } }
server.on('request', () => {}), fs.on("data", () => {}) 怎么解釋?當server收到請求或fs讀取到數據后,會把包含server.emit('request')或fs.emit(data) 的回調函數放到事件隊列中,EventLoop循環到它,就在V8中執行了emit方法,也就執行了監聽事件的回調函數。
Buffer
Node.js能夠讀取文件,能夠創建服務器處理HTTP請求,它就要處理二進制數據,因為收到的都是二進制數據,最基本的就是怎么把收到的二進制數據存起來?這就是Buffer的由來,創建Buffer來存儲二進制數據。由于二進制數據都是一個字節一個字節進行分割的,buffer的創建也是字節為單位,想保存多少個字節,就創建多大的buffer。Buffer.alloc(5);就創建了5個字節大小的buffer,由于程序是在內存中運行,buffer就是在內存中開辟了5個字節大小的空間,拿到Buffer.alloc的返回值,就可以操作這個buffer了。由于內存空間的分配是連續的,可以把buffer看成一個數組,數組中的每一個元素都是一個字節大小,只能存儲00000000-11111111之間,就是0-255之間的數字。
const firstBuffer = Buffer.alloc(5); // 默認buffer中所有元素都是0 firstBuffer[0] = 1; // 只能賦值數字 firstBuffer[1] = 2;
const firstBuffer = Buffer.from('abc');
const secondbuffer = Buffer.from('你');
// <Buffer 61 62 63> <Buffer e4 bd a0>
// 在UTF-8下,一個英文占一個字符,一個漢字占3個字節,
console.log(firstBuffer, secondbuffer);
讀取buffer,可以使用數組索引一個字節一個字節地讀取,也可以使用toString()和toJSON()把buffer看成一個整體進行讀取。toJSON() 返回buffer中每一個字節所對應的整數表現形式, 以十進制進行輸出
const stringBuffer = Buffer.from('abc');
console.log(stringBuffer[0])
// { type: 'Buffer', data: [ 97, 98, 99 ] }
// 為了和其它JSON對象進行區分, 永遠有一個type:'Buffer'屬性,data屬性才是整個buffer數據的整數展示形式
console.log(stringBuffer.toJSON())
toString() 就是把buffer中的二進制數字轉成字符串,默認按照utf-8 進行轉化。
const stringBuffer = Buffer.from('abc');
console.log(stringBuffer.toString()); //'abc'
這里一定要注意字符串轉化成buffer的時候用的什么編碼,調用toString轉換回來的時候,就要用什么編碼轉換。Buffer.from('abc') 創建的buffer在內存中表現形式可以描述為 [01100001, 01100010, 01100011]。 當看到一個buffer的時候,應該看到的是0101... 的排列組合,它本身已經無法表示什么意義了。它具體什么意義,就看我們怎么讀取了。如果按utf-16進行讀取
console.log(stringBuffer.toString('utf16le')); // 扡
toString('utf16le') 就是按照utf-16編碼來讀取該buffer。utf-16,每一個字符都占兩個字節,所以它就讀取buffer的前兩個字節:01100001 01100010, utf16le對字節進行操作的時候調換了一個順序,01100001 01100010 轉化成了01100010 01100001, 01100010 01100001 對應的十進制是25185,25185對應的unicode字符是'扡'。讀完前兩個字節,再往下讀,還剩下一個字節, 因為不夠兩個字節,所以就不操作了。
修改buffer的值,可以使用數組索引的方式,和賦值一樣,也可以用write() 方法,它接受一個字符串,用于替換原buffer的內容。
const stringBuffer = Buffer.from('abc');
stringBuffer.write('ABC');
// 如果寫的內容多于原buffer的大小, 多余的內容會被忽略
stringBuffer.write('ABCDEF');
console.log(stringBuffer.toString()); // 'ABC',’DEF‘ 被忽略了
// 如果寫入的內容少于原buffer的內容, 寫入幾個,替換幾個
stringBuffer.write('X');
console.log(stringBuffer.toString()); // 'Xbc' 只替換掉了原buffer中的第一個字符,剩余的內容不會動
除了write()方法,還可以用copy()方法。source.copy(target). 把source中的內容復制到target。只要哪個buffer中有想要的內容,就調用copy(),傳給它需要這些內容的buffer。
const uppcaseBuffer = Buffer.from('ABC');
const lowercaseBuffer = Buffer.from('abc');
uppcaseBuffer.copy(lowercaseBuffer)
console.log(lowercaseBuffer.toString()); // 'ABC'
如果只想替換某一部分內容,只把’A‘ 復制過來替換’a‘,那就給copy()多傳幾個參數 。source.copy(target, targetStart, sourceStart, sourceEnd)。targetStart: 目的地buffer的起始位置,把復制過來的內容從哪個位置開始替換target中的內容。sourceStart, sourceEnd, 就是表示要復制sourceStart 到sourceEnd 之間的內容。
const uppcaseBuffer = Buffer.from('ABC');
const lowercaseBuffer = Buffer.from('abc');
uppcaseBuffer.copy(lowercaseBuffer, 0, 0, 1)
console.log(lowercaseBuffer.toString()); // 'Abc'
File System 文件系統
文件就是0101的二進制序列,不論是文本文件,還是音視頻文件,圖像文件,在計算機中的都是0101......,沒什么區別,真正的區別在于怎么解析這些二進制文件。不可能用記事本打開圖片和視頻文件,只能使用畫圖和視頻軟件來打開圖片和視頻。程序也是一樣,要用正確的庫來操作對應的文件。操作系統默認支持兩種文件,一個是文本文件,一個是可執行文件,想要支持其他文件的操作,就要使用第三方庫,比如,操作視頻用ffmpeg。不論是庫還是圖形化界面安裝的軟件,它們本質上是能對0101......的二進制進行正確的解析。
在Node.js中,有三種不同的方式來操作文件,promise的方式,callback方式和同步的方式。通常情況下,使用promise的方式,考慮性能的時候使用callback,官方說callback比promise快。只有在某些特定的情況下,使用同步方式,比如啟動服務器的時候讀取配置文件,因為它只讀取一次。
const fs = require('node:fs'); // node: 是node命名空間,node下面的什么模塊
// 異步callback 方式,回調函數都是error first的形式
fs.writeFile('./data.txt', '你好', err => {
if (err) { console.error(err); }
console.log('寫入成功');
})
//異步promise的形式
const fsp = require('node:fs/promises')
fsp.writeFile('./text.txt', '你好')
.then(() => {
fsp.readFile('./data.txt')
.then(data => { console.log(data.toString());})
})
.catch(err => { console.log(err); })
// 同步方式
fs.writeFileSync('./text.txt', "你好")
fs.readFileSync('./text.txt')
writeFile()向文件寫數據時,如果沒有文件,就創建文件,如果有文件,就把文件內容清空,再從頭開始寫。想在文件后面追加內容,就要提供option參數, 包含 {encoding, mode, flag}的一個對象,encoding: 指定用什么編碼寫入,文件中永遠都是二進制數據,提供的參數是字符串,就要把字符串轉換成二進制數據,默認UTF-8; mode: 文件的權限模式,默認是可讀,可寫。flag 表示用什么模式去寫,默為是'w', 如果想追加內容,使用 'a' 就可以了。readFile把讀取的二進制數據轉換成字符串時,用什么編碼寫入的,就要用什么編碼轉換。
readFile()和writeFile()簡單好用,但不適合大文件操作,因為它們是把文件一次性讀取到內存中,再一次性寫入到目的地,內存占用過大。為了粒度更小的操作文件,有了fs.open(),fs.read(), fs.write() 和fs.close()。打開文件,讀或寫,關閉文件。打開文件有一個參數是打開方式,只讀,只寫,還是既能讀,又能寫,打開成功返回文件描述符(打開的文件的引用),拿到它,就能操作文件,進行讀寫
const fs = require('node:fs');
const buffer = Buffer.alloc(3);
fs.open('./data.txt', 'r' , (err, fd) => { // r, 以只讀方式打開文件
// 第二個參數buffer:讀到的數據放到buffer中,第三個參數 0,表示從buffer的第0處開始放,buffer類數組
// 第四個參數buffer.length是讀取多少個字節, 通常是把整個buffer都放滿,所以是buffer.length
// 第五個參數 0是從源文件(data.txt)的哪個位置開始讀,第一次讀,肯定是從0開始
// 回調函數中readBytes從源文件中讀取到多少個字節,data讀取到的數據 buffer類型
fs.read(fd, buffer, 0, buffer.length, 0, (err, readBytes, data) => {
console.log(readBytes); //讀取了3個字節
console.log(data.toString()); //你
})
})
buffer是3個字節大小,所以只讀了一個字。為了讀取完整個文件, 在讀取完第一個字后,要讀第二個字,也就是在回調函數中,再調用fs.read(), 不要注意參數,它不再是從源文件的0字節處開始讀,而是從3字節處開始讀取,就是已經讀取buffer要進行累加。 fs.read的回調函數中調fs.read, 自己調用自己,遞歸了,所以要把fs.read 抽成 一個函數。遞歸肯定有結束條件。如果在fs.read()的回調函數中readbytes是0,文件沒有內容可讀了,就結束讀取,并關閉文件
const fs = require('node:fs');
const buffer = Buffer.alloc(3);
// 從源文件的哪里開始讀。
let readBegin = 0;
function myReadFile(fd) {
fs.read(fd, buffer, 0, buffer.length, readBegin, (err, readBytes, data) => {
// 文件內容最終會讀完,所以最后調用fs.read讀取到的字節數readBytes是0.
if (readBytes === 0) {
fs.close(fd);
return;
}
console.log(data.toString());
readBegin += readBytes; // 累加讀取到的數據,下一次讀取的時候從該位置讀取
myReadFile(fd);
})
}
fs.open('./data.txt', 'r', (err, fd) => {
myReadFile(fd);
})
fs.write() 需要fs.open() 以寫'w' 的方式打開文件
const fs = require('node:fs');
const buffer = Buffer.from("你好");
fs.open('./anoterdata.txt', 'w', (err, fd) => {
// 第二個參數buffer是要寫入的內容, 可以全部寫入,也可以拿出一部分寫入,這就是第三個和第四個參數。
// 第三個參數是從buffer中的哪個位置開始讀取,第四個參數是要從buffer讀取多少個字節,一般是全部讀取,0, buffer.length
// 第五個參數是從目的地文件的哪個位置開始寫入
// 回調函數,也是三個參數(err, bytesWritten, buffer),error,表示寫入成功或失敗
fs.write(fd, buffer, 0, buffer.length, 0, (err, bytesWritten, buffer) => {
console.log("寫入成功");
fs.close(fd);
})
})
和fs.read()方法一樣,如果讀取的要寫入的內容過長,還是要遞歸,
const fs = require('fs');
const data = Buffer.from("你好啊");
let begin = 0; // 從哪個位置開始寫入,從data的哪個位置開始讀取
const size = 3; // 一次寫入多少個節字
function write(fd) {
if (begin >= data.length) {
console.log("寫入成功");
fs.close(fd);
return;
}
fs.write(fd, data, begin, size, begin, err => {
begin += size;
write(fd);
})
}
fs.open('./anoterdata.txt', 'w', (err, fd) => {
write(fd);
})
以r+打開文件,可以對文件進行讀寫,如果打開文件不存在,會報錯。創建一個text.text文件,內容寫abcdef. 文件可以進行讀寫,就分為兩種情況下,先讀再寫,先寫再讀。打開文件的時候,有一個offset,默認它是0,就是游標在文件開頭。先讀再寫的時候,先讀把文件內容讀完,游標到了文件末尾,再寫,那就相當于追加內容。
const fs = require('fs');
fs.open('./text.txt','r+', (err,fd) => {
fs.read(fd, (err, bytes, buffer) => {
console.log(buffer.toString())
fs.write(fd, 'write this line', (err,bytes,string) => {
console.log(string)
})
})
})
先寫再讀,由于在默認情況下,打開文件,游標在文件開頭,先寫就意味著覆蓋式寫入,實際寫多少內容,就覆蓋多少內容。寫入完成后,游標停留在寫完的位置而不是文件的末尾,此時再進行讀取,可以讀出未被新內容覆蓋的文檔內容,如果文件內容都覆蓋完了,那什么就讀不出來了。
fs.open('./text.txt', 'r+', (err, fd) => {
fs.write(fd, 'write this line', (err, bytes, string) => {
fs.read(fd, (err, bytes, buffer) => {
console.log(buffer.toString())
})
})
})
以w+打開文件,也可以對文件進行讀寫,但w+時,沒有文件會創建新文件,如果有文件,則會清空文件,r+ 則不會清空文件,所以對于w+來說,打開文件時,文件永遠都是空,先讀再寫沒有意義,只有先寫再讀,但先寫之后,游標到了文件末尾,需要把游標放到文件開頭,才能讀取到剛寫的內容。fs.read的第二個參數,可以接受position參數,
const fs = require('fs');
fs.open('./text.txt', 'w+', (err, fd) => {
fs.write(fd, 'write this line', (err, bytes, string) => {
fs.read(fd, { position: 0 }, (err, bytes, buffer) => {
console.log(buffer.toString())
})
})
})
fs.read()和fs.write()方法又太細節了,于是有了用流來操作文件,讀文件創建可讀流,寫文件創建可寫流。可讀流pipe可寫流,就可以實現文件的復制
const fs = require('node:fs'); const readStream = fs.createReadStream('./data.text'); const writeStream = fs.createWriteStream('./anoterdata.txt'); readStream.pipe(writeStream)
fs 使用相對路徑讀取文件時,相對路徑相對的是啟動node 進程時所在的路徑。打開命令行窗口,當在某個路徑下,啟動node 程序,shell 就會把當成路徑傳遞給node程序,fs相對路徑,就是相對的傳遞過來的路徑,比如 當前shell在用戶目錄下,node path/app/index.js 啟動node程序,fs相對的路徑就是 path/app, 可以在程序中,使用process.cwd() 來獲取傳遞過來的路徑,所以fs 讀取建議使用絕對路徑,__dirname配合path.join。
簡單說一下process和path對象。node index.js會創建一個進程,process對象就代表這個進程。因此,可以通過process對象獲取到進程執行相關的信息,比如環境變量,程序執行時的參數,標準輸入,輸入流等。process.env獲取整個環境信息,比如用戶名,PATH環境變量。process.env[變量名],獲取某個環境變量,在linux終端 NODE_ENV=prod node index.js, process.env.NODE_ENV就能獲取到prod。process.argv獲取命令行參數。process.exit()退出程序。path操作文件和目錄的路徑,basename(),
const path = require('path');
const filename = "/home/sam/Documents/node-learning/main.js";
const directoy = "/home/sam/Documents/node-learning/";
// basename(): 獲取路徑的基礎名稱
console.log(path.basename(filename)) // main.js
// basename(filename, '.js'), 第二個參數 去掉指定的后綴
console.log(path.basename(filename, '.js')); // main
// 如果參數是目錄,返回最后一個,后面的/(node-learning/) 會去掉
console.log(path.basename(directoy)) // directoy
path.join和path.resolve(),拼接多個路徑片段,只不過path.join并不是總會返回絕對路徑,如果拼接的字符串是相對路徑的話,它返回的是相對路徑。比如 path.join('./a', 'b') 返回的是'a/b', 并不是絕對路徑, 拼接的字符串是絕對路徑,才返回絕對路徑,resolve() 永運 返回絕對路徑。parse() 解析路徑,返回一個對象
const path = require('path');
const filename = "/home/sam/Documents/node-learning/main.js";
const directoy = "/home/sam/Documents/node-learning/";
/* 參數是文件
{
root: '/',
dir: '/home/sam/Documents/node-learning',
base: 'main.js',
ext: '.js',
name: 'main'
}
*/
console.log(path.parse(filename))
/* 參數是目錄,
{
root: '/',
dir: '/home/sam/Documents',
base: 'node-learning',
ext: '',
name: 'node-learning'
}
*/
console.log(path.parse(directoy))
流
流處理數據,是把數據分割成一塊一塊的進行處理。數據讀取時,讀取到一塊內容,就會發送事件,有機會去處理這一塊內容。讀取一塊數據,處理一塊數據,數據不會一直占用內存中,內存使用效率高,更有可能來處理大文件。數據的寫入也是一塊一塊寫,比如網絡下載,服務器一塊一塊地寫數據,瀏覽器一塊一塊的讀數據,時間高效。在Node.js中,有4種流:
可讀流(readable stream): 從里面讀取數據的流。它負責從數據源里讀取數據(到內存),程序負責從它里面讀取數據,把它看作數據源的抽象。
可寫流(writable stream): 向里面寫入數據的流,程序向可寫流里寫入數據(把內存中的數據寫入到可寫流中),它負責向目的地寫入數據,它是目的地的抽象。
雙向流或雙工流(duplex stream): 既可以從它里面讀取數據,也可以向它里面寫入數據。
轉換流(transform stream):特殊的雙工流,向它里面寫入數據,它可以對寫入的內容進行轉換,然后把數據放到它的讀端,可以從里面讀取到轉換到后的內容。
可讀流
可讀流有兩種模式:pause和flow。pause是默認模式,就是創建可讀流后,它并不會從數據源中讀取數據,
const fs = require('fs');
const readable = fs.createReadStream("a.txt");
setInterval(() => {
// 監聽可讀流讀取了多少數據
console.log(readable.bytesRead, 'bytesRead')
}, 1000);
// readable.on('readable', () => {})
控制臺永遠輸出0,不會讀取數據。繼續使用pause模式,為了讓可讀流從數據源中讀取數據,需要監聽readable事件,打開程序最后一行注釋,控制臺永遠輸出65536 bytes (64kb),程序讀取64kb的內容,也不會再讀了, pause了。這是因為在pause模式下,可讀流使用了緩沖區技術,它內部有一個緩沖區,默認大小64kb,可讀流讀取數據到緩沖區中,當認為數據可讀時,發出readable事件。如果監聽readable 事件,并沒有提供處理函數, 可讀流填充滿緩沖區就不讀了,它并不會從緩沖區中刪除數據。readable事件處理函數就要從緩沖區讀取數據,清空緩沖區,調用可讀流的read()方法。
const fs = require('node:fs');
const readable = fs.createReadStream("a.txt");
readable.on('readable', () => {
console.log('readable event')
let chunk;
// read() 方法,如果從緩沖區讀取不到數據,就會返回null。
while (null !== (chunk = readable.read())) {
console.log(chunk.length)
}
});
read方法還可以接受一個參數,表示一次從緩沖區讀取多少字節,如果沒有提供參數(像上面一樣),就把緩沖區的所有數據全讀取出來,上面的程序中控制臺先輸出65536 就是證明。給read參數提供30000
const fs = require('fs');
const readable = fs.createReadStream("a.txt");
readable.on('readable', () => {
console.log('readable event')
let chunk;
while (null !== (chunk = readable.read(30000))) {
console.log(chunk.length)
}
});
/** read 從緩沖區中一次讀取30000 byte
readable event
30000
30000
readable event
30000
readable event
125
*/
這時發現一個現象,提前讀取,當buffer 中數量少時,會提前讀取。程序每次從緩沖區拉取數據,當緩沖區的數據較少時,可讀流就會進行讀取操作,填充空余的緩沖區,發出一次readable事件。pause 模式下,監聽readable事件,事件處理函數中調用read()方法,處理數據,如下圖所示
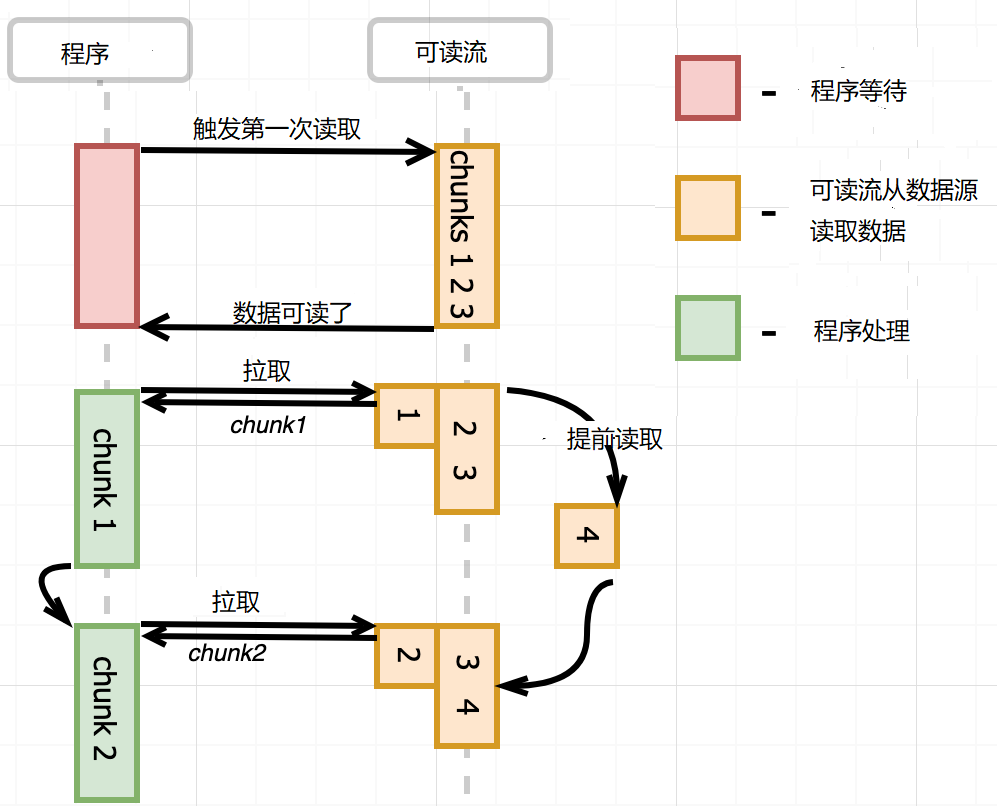
但有時候,異步的數據處理邏輯,需要等到buffer中的數據全部讀取完畢,再觸發下一次讀取,不需要提前讀取,這就要使用once,手動添加readable 事件。
const fs = require('fs');
const stream = fs.createReadStream('a.txt');
stream.once('readable', consume); // 觸發第一次可讀流讀取操作
async function consume() {
let chunk;
// 消費數據,
while ((chunk = stream.read()) !== null) {
await asyncHandle(chunk);
}
//消費完畢,觸發另一次可讀流的讀取操作
stream.once('readable', consume);
}
async function asyncHandle(chunk) {
console.log(chunk);
}
說完pause,再說flow。監聽可讀流的data事件,流就自動轉化成flow模式,不停地從數據源中讀取數據,讀取一塊數據,就發送data事件,它不管你處不處理,也不管你處理的快慢,它就是按自己的速度讀取數據,直到讀完為止。
const fs = require('fs');
const readable = fs.createReadStream("a.txt");
setInterval(() => {
// 監聽可讀流讀取了多少數據
console.log(readable.bytesRead, 'bytesRead')
}, 1000);
readable.on('data', () => {})
控制臺顯示了整個文件的大小,沒有處理data事件,仍然從源中讀取數據。
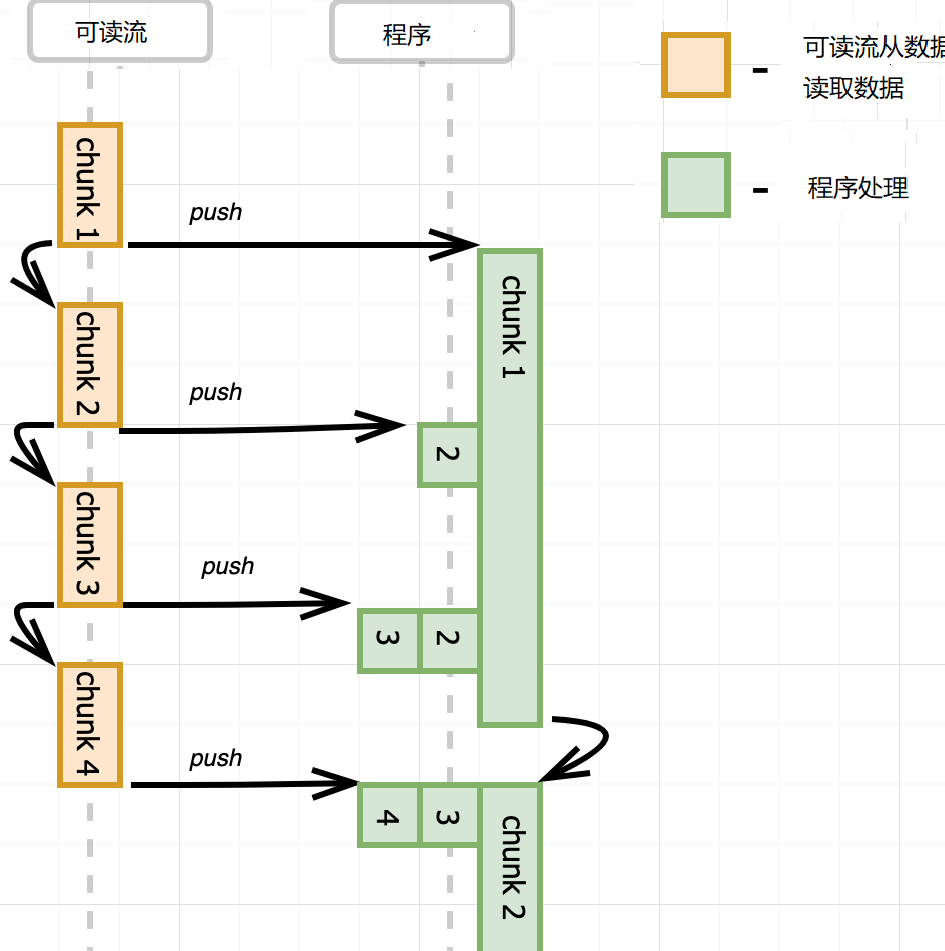
這就有一個問題,可讀流推送數據太快,事件處理函數處理太慢,要么丟失數據,要么無限緩存,消耗大量內存。比如data事件處理函數中,把數據寫入到另外一個文件,寫入很慢。怎么辦?可寫流默認內置了一個緩沖區,數據先寫到緩沖區,再寫入到目的地。如果緩沖區滿了,那不要再寫數據了,等清空緩沖區,再寫入數據,這就是背壓(backpressure)。
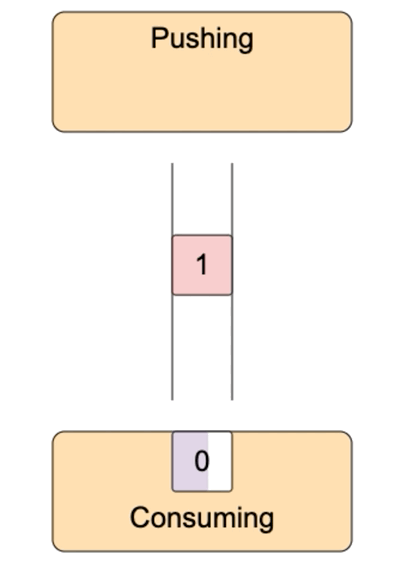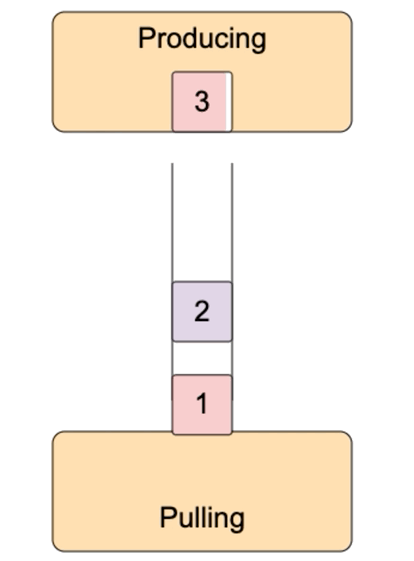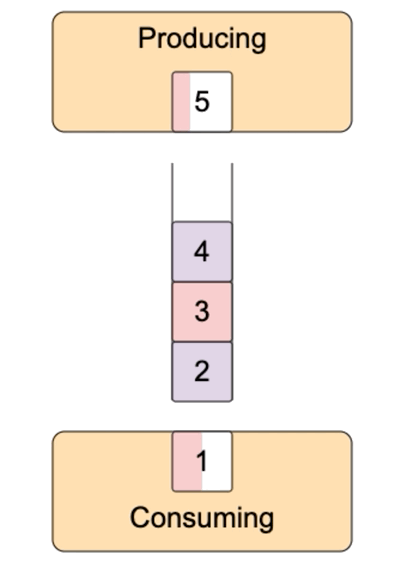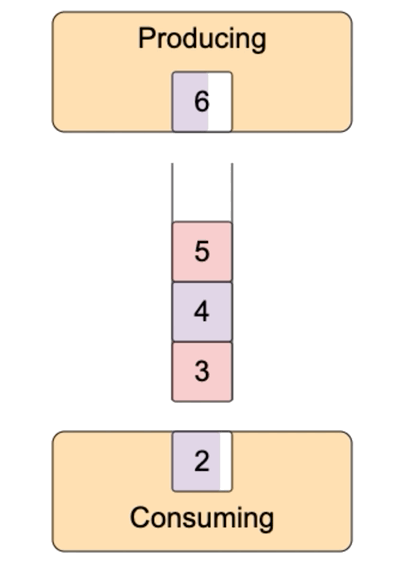
可寫流write方法返回true表示寫入成功后內置的buffer仍有空閑,仍然可以寫入。返回false表示寫入后內置的buffer滿了,不能再寫入了。可寫流寫入到目的地后,內部的buffer就有空閑,它就會發出發出drain事件,收到drain事件,就可以繼續向可寫流中寫入數據了。
const fs = require('fs');
const readable = fs.createReadStream('./biji.txt');
const writeable = fs.createWriteStream('anotehr.txt');
readable.on('data', (data) => {
if (!writeable.write(data)) {
readable.pause();
writeable.on('drain', () => {
readable.resume();
})
}
})
監聽可讀流的data事件,可讀流去讀取數據,同時在事件監聽函數中,調用可寫流的write()方法寫入數據。如果write()返 回false, 可讀流就就要暫停讀取。同時,可寫流要監聽'drain'事件,在事件中調用可讀流的resume()方法。一旦在可讀流的buffer中有空間,可寫流發出'drain'事件,繼續可讀流的讀取數據。Node.js對這些操作進行了抽象,形成了pipe方法,readableStream.pipe(writeStream); 可讀流的內容向可寫流里面寫。同時pipe返回第一個參數,如果第一個參數是轉換流或雙工流,pipe寫到它們的可寫端,由于又返回了它們,它們有可讀端,可以繼續從里面讀取數據,形成pipe的鏈式調用。

雙工流內部有讀緩沖區和寫緩沖區,可讀可寫,寫就寫到它的寫緩沖區中,讀就從它的讀緩沖區中讀取數據,讀緩沖區和寫緩沖區可以沒有任何關系,只有net模塊使用了雙工流。
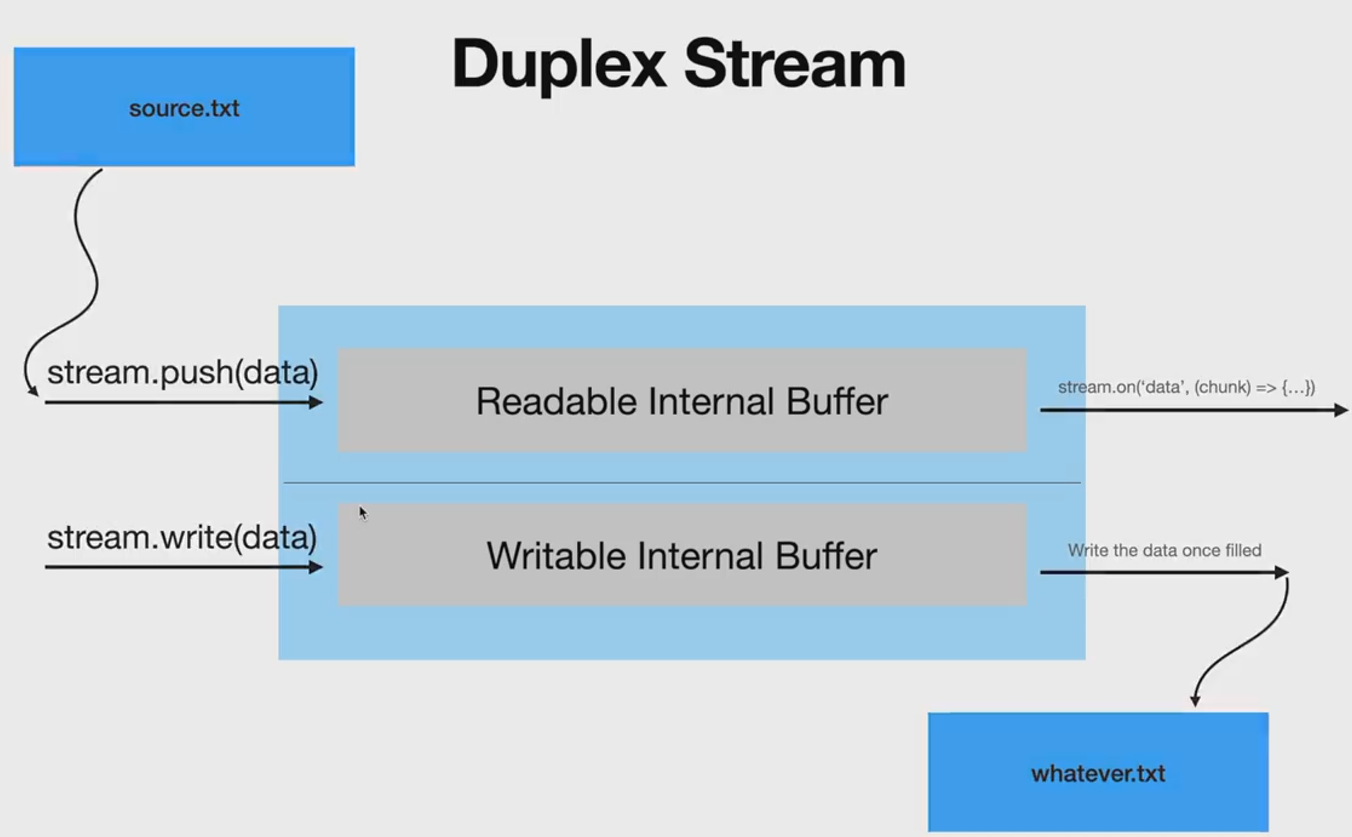
轉化流是特殊的雙工流,調用它的write方法寫入到內部的寫緩沖區中,然后它自己把寫緩沖區中的數據放到它內部的讀緩沖區中,外界監聽可讀流事件讀取轉化流中的數據。寫入的數據成為可讀的數據,當然寫緩沖區數據到讀緩沖區之間,可以對數據做轉化,如果對數據什么都不做,就成了pass through流了。轉化流內部的write和read方法,只是從兩個緩沖區中搬運數據。
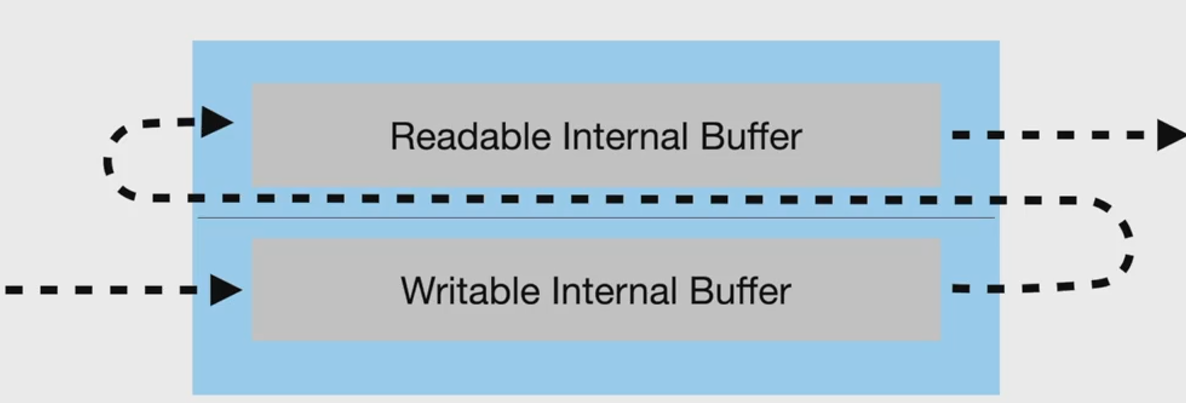
zlib模塊是轉化流,對文件壓縮和解壓縮。
const { createGzip } = require('node:zlib'); const { createReadStream, createWriteStream } = require('node:fs'); const gzip = createGzip(); const source = createReadStream('input.txt'); const destination = createWriteStream('input.txt.gz'); source.pipe(gzip).pipe(destination)
pipe的使用并沒有處理error,如果pipe出現了error怎么辦?使用pipe()方法,并不會關閉流發出事件。事件依然有效,可以監聽source,gzip,destination流的error事件,但這樣不太友好,用pipeline方法,第一個參數是readableStream, 中間參數是0,1,或多個轉化流,后面再跟可寫流,最后一個參數是回調函數,pipeline完成后,執行的回調。source.pipe(gzip).pipe(destination) 換成
const { pipeline } = require('node:stream');pipeline(source, gzip, destination, (err) => { if (err) { console.error('An error occurred:', err); process.exitCode = 1; } });
自定義轉換流就是繼承Transform, 重寫_transfrom方法和可選的_flush方法。 _transform的三個參數是 chunk(數據), encoding(字符編碼), 和callback(回調函數),它的作用就是讀取上游傳遞過來的數據,然后把轉換后的數據再push回去。_flush則是,如果上游發送的數據完了,但在 transform流中還有數據,那就在_flush中把剩余的數據push出去,它接受一個回調函數,也是通知的作用
const { Transform } = require('stream');
class MyTransform extends Transform {
_transform(chunk, encoding, callback) {
var upperChunk = chunk.toString().toUpperCase();
this.push(upperChunk); // 調用push方法,向流中push數據。
callback();
}
}
流還有一種Object 模式,流中流動的是object對象,一個對象一個對象的流動。
const { Transform, Readable } = require('node:stream') class SumProfit extends Transform { constructor(opts = {}) { super({ ...opts, readableObjectMode: true, writeableObjectMode: true }) this.total = 0; } _transform(record, encoding, cb) { this.total += JSON.parse(record).profit; cb(); } _flush(cb) { this.push(this.total.toString() + ' \n') cb() } } // Readable.from創建可讀流,默認是Object模式,流中都是object。一個元素一個object。 // 由于流中只能是字符串,buffer,所以要把對象進行序列化,轉化成字符串 // 可讀流,還會觸發end事件 const objRead = Readable.from([ JSON.stringify({profit: parseInt(Math.random() * 100)}), JSON.stringify({profit: parseInt(Math.random() * 100)}) ]) objRead.pipe(new SumProfit()).pipe(process.stdout)
當可讀流讀取到數據時給轉換流時,一次data事件,一次_transform函數的調用。當可讀流中沒有數據,它就不調_transform了,但轉化流中還存在this.total 數據沒有處理,當可讀流發出end事件之前時,轉換流的_flush方法會被調用,所以正好利用這個機會,在_flush方法中把this.total 放到轉化流的可讀緩沖區。實現可讀流的時候,一定要表示可讀流結束,實現可寫流時,也要表示結束
const { Readable } = require('node:stream') const objRead = new Readable({ objectMode: true }); objRead._read = () => {}; let i = 0; const id = setInterval(() => { objRead.push(JSON.stringify({ profit: parseInt(Math.random() * 100) })); i++ if( i == 10) { objRead.push(null); // push(null) 可讀流讀取數據結束了 clearInterval(id) } }, 100);
Socket 網絡編程
兩臺計算機要進行通信,首先要能找到對方,然后發送消息。操作系統實現了TCP/IP協議,幫我們尋找對方,發送消息。怎樣使用TCP/IP協議呢?Node.js提供了net模塊,可以直接使用TCP的傳輸功能,創建TCP server 和 TCP client,client發送數據給server,server 返回數據給client,實現通信,通信的兩端稱為socket。創建server.js
const net = require('node:net');
const server = net.createServer(); // 創建服務器
// 監聽客戶端連接,連接成功,socket就是對應的客戶端標記
server.on('connection', (socket) => {
//socket是一個雙工流,接收客戶端發送過來的數據,就監聽data事件,
socket.on('data', (data) => {
console.log(data)
})
socket.on('end', () => {
console.log('end')
})
})
// 監聽3000 端口
server.listen(3000, '127.0.0.1', () => {
console.log("server")
})
client.js
const net = require('node:net');
const socket = net.createConnection({ // 連接server
host: 'localhost', port: 3000
}, () => { // 成功連接后,執行回調函數
socket.write('hello')
socket.end() // 斷開連接
})
node server.js, 然后node client.js 成功發送消息。創建一個文件發送和接收服務,server.js
const net = require('net');
const fs = require('node:fs/promises');
const server = net.createServer();
let filehandler;
let writeStream;
server.on('connection', (socket) => {
socket.on('data', async (data) => {
if (!filehandler) {
// data事件觸發太快,而fs.open太慢,比如data 事件發生了5次,
// fs.open才打開,那這5次事件,fs.open就要執行5次。
// 所以,沒有打開文件,就不接收數據了,等打開文件后,把已經接收到數據寫入,再開始接收數據。
socket.pause();
const indexOfDivdier = data.indexOf('-------');
// 客戶端寫過來的數據是 filename: ddddd.txt-----
// 由于是filename: 占10個字節,所以從10開始截取。
const fileName = data.subarray(10, indexOfDivdier).toString();
filehandler = await fs.open(`storage/${fileName}`, 'w');
writeStream = filehandler.createWriteStream();
// 從 ------- 后面開始寫
writeStream.write(data.subarray(indexOfDivdier + 7));
socket.resume()
writeStream.on('drain', () => {
socket.resume()
})
} else {
if (!writeStream.write(data)) {
socket.pause()
}
}
})
socket.on('end', () => {
console.log('end')
filehandler.close()
// 雖然把流關了,但是 filehander 仍然存在
filehandler = null;
writeStream = null;
})
})
server.listen(3000, '127.0.0.1', () => {
console.log("server")
})
client.js
const net = require('net');
const fs = require('node:fs/promises');
const path = require('path');
const socket = net.createConnection({
host:"localhost", port: 3000
}, async () => {
// 啟動客戶端時用 node client text.txt
const filePath = process.argv[2];
// filePath是絕對路徑,所以取basename。
const fileName = path.basename(filePath);
const filehandler = await fs.open(filePath, 'r')
const fileReadStream = filehandler.createReadStream();
// showing the upload process
const fileSize = (await filehandler.stat()).size;
let uploadedPercentage = 0;
let bytesUploaded = 0;
socket.write(`fileName: ${fileName}-------`);
fileReadStream.on('data', data => {
if(!socket.write(data)) {
fileReadStream.pause()
}
bytesUploaded += data.length;
let newPercentage = Math.floor(bytesUploaded / fileSize * 100)
// 因為有太多的data事件,不想展示太多
if(newPercentage % 5 === 0 && newPercentage !== uploadedPercentage) {
uploadedPercentage = newPercentage;
console.log('Uploading.........')
}
})
socket.on('drain', () => {
fileReadStream.resume()
})
fileReadStream.on('end', () => {
console.log("The file was successfully uploaded");
socket.end()
})
})
在client和server 同級目錄下,創建text.txt和storage文件夾,node server.js 啟動服務, node client.js text.txt, 文件成功上傳。上面有一個細節需要注意,client在發送消息的時候,先發送filename: ----, 再發送數據,而服務端解析的時候,也是認定先有filename:,占10個字節,然后解析文件名,讀取數據。這就是一種協議,只不過是自己定義的,只要向服務器發送數據,就先發filename:--再發送數據,因為都是0101序列,需要按照某種格式進行解析。只要有人向服務端發送數據,你就要告訴他,先發送filename: ---再發送數據,非常麻煩,于是就出現了標準化的協議,HTTP,FTP等, HTTP協議只是規定了發送消息的格式,好讓客戶端和服務端都能正確的解析數據。
HTTP
http協議只是規定了發送消息的格式。客戶端向服務端發送消息,要有請求頭,如果有數據,還要有請求體,請求頭包含請求方法,請求路徑,如果有請求體,請求頭還要包含請求體的格式。服務端向客戶端發送消息的時候,也要告訴客戶端端發送的是什么。Content-Type表示什么類型,它的值MIME(media type)。media type的格式是 type/subtype,比如text/css,它還有一個可選的key=value, 比如text/html;charset=utf-8. 還有一種type是multipart, 比如文件上傳,multipart/form-data。Content-Length 表示發送了多少個字節。創建http服務器,它就幫你把客戶端發送過來的請求解析完成,封裝了request對象中,同時把客戶端連接封裝到response對象中。http服務器程序,只操作兩個對象,一個是request對象,表示請求,有method, url,headers等屬性, 一個是response對象,用于響應,主要有setHeader,write,end方法,向客戶端寫入數據。當用write的時候,一定要調用end表示結束,因為寫入的都是buffer,客戶端也不知道什么時候結束,就一直等待。get請求比較簡單,就是服務器返回數據。
const http = require('node:http'); //node: 表示它是node內置的module,不是第三方module。
const fs = require("node:fs/promises")
const server = http.createServer()
server.on('request', async (request, response) => {
if (request.url === '/' && request.method === 'GET') {
response.setHeader("content-type", 'text/html');
const fileHanlde = await fs.open('./public/index.html', 'r');
const fileStream = fileHanlde.createReadStream();
fileStream.pipe(response)
}
if (request.url === '/styles.css' && request.method === 'GET') {
response.setHeader("content-type", 'text/css');
const fileHanlde = await fs.open('./public/styles.css', 'r');
const fileStream = fileHanlde.createReadStream();
fileStream.pipe(response)
}
if (request.url === '/scripts.js' && request.method === 'GET') {
response.setHeader("content-type", 'text/javascript');
const fileHanlde = await fs.open('./public/scripts.js', 'r');
const fileStream = fileHanlde.createReadStream();
fileStream.pipe(response)
}
})
server.listen(3000, () => {
console.log('server listening on 3000')
})
post請求會攜帶數據,所以要確定數據類型,不同的類型,不同的處理方式。request對象是一個可讀流,發送過來的數據在流中,只要監聽data事件,就能獲取post發送過來的數據,request有一個header屬性,它有一個content-type,可以知道發送過來的是什么類型。如果是發送的form表單,可以這么處理
function post(req, res) { if (req.headers["content-type"] === "application/x-www-form-urlencoded") { const input = []; req.on("data", (chunk) => { input.push(chunk); }); req.on("end", () => { const parsedInput = Buffer.concat(input).toString() // 告訴客戶端已經寫完了。write只是寫trunk,沒有結束標志 res.end(http.STATUS_CODES[200] + " " + parsedInput); }); } }
如果發送過來的是json數據
function post(req, res) { if (req.headers["content-type"] === "application/json") { const input = []; req.on("data", (chunk) => { input.push(chunk) }); const parsed = JSON.parse(Buffer.concat(data).toString()); if (parsed.err) { error(400, "Bad Request", res); return; } console.log("Received data: ", parsed); res.end('{"data": ' + input + "}"); } }
上傳文件則比較復雜,Browsers embed files being uploaded into multipart messages。 Multipart messages allow multiple pieces of content to be combined into one payload. To handle multipart messages, we need to use a multipart parser. 這里要用到第三方模塊formidable
function post(req, res) { if (/multipart\/form-data/.test(req.headers["content-type"])) { const form = formidable({ multiples: true, uploadDir: "./uploads", }); form.parse(req, (err, fields, files) => { if (err) return err; res.writeHead(200, { "Content-Type": "application/json", }); res.end(JSON.stringify({ fields, files, })); }); } }
http 模塊還能請求別的服務器。它有一個get方法,可以直接發送get請求
const http = require("http");
http.get("http://jsonplaceholder.typicode.com/posts/1",
(res) => res.pipe(process.stdout));
發送post請求,則使用http.request()方法,它的第一 個參數是對象,配置post請求的參數,比如hostname, 第二個參數就是回調函數,接受返回的數據
const http = require('http');
const payload =JSON.stringify({
name: "Beth",
job: "Web"
})
const opts = {
method: "POST",
hostname: "postman-echo.com",
path: "/post",
header: {
"Content-type": "application/json",
'Content-Length': Buffer.byteLength(payload)
}
}
const req = http.request(opts, (res) => {
res.setEncoding('utf8');
res.on('data', (chunk) => {
console.log(`BODY: ${chunk}`);
});
res.on('end', () => {
console.log('No more data in response.');
});
});
req.on('error', (e) => {
console.error(`problem with request: ${e.message}`);
});
// 發送post請求,帶著數據,也可以直接res.end(payload)
req.write(payload);
req.end();
當用http.request,如果調用write方法寫數據時,一定要調end方法,告訴server寫完了, 因為它的發送就transfer coding 是buffer,服務端也不知道寫沒寫完。const request = http.request() request.write(); request.end()。如果不調用end(), 要在request的header里面寫content-length, 告訴服務器器發送了多少數據,服務器直接讀取這么些數據,就可以了。
Node.js 設計模式
API設計要么全同步,要么全異步,如果讀取了數據并緩存,下一次從緩存中讀取數據,它是同步的,可以使用process.nextTick 來讓它變成異步。
function readFileIfRequired(cb) {
if (!content) {
fs.readFile(__filename, 'utf8', function (err, data) {
content = data;
console.log('readFileIfRequired: readFile');
cb(err, content);
});
} else {
process.nextTick(function () {
console.log('readFileIfRequired: cached');
cb(null, content);
});
}
}
代理模式:代理是一個對象,它控制著對另一個對象的訪問。代理對象和被代理對象有相同的接口(方法)。代理攔截對被代理對象的部分或所有操作,然后進行增強或補充這個形為。
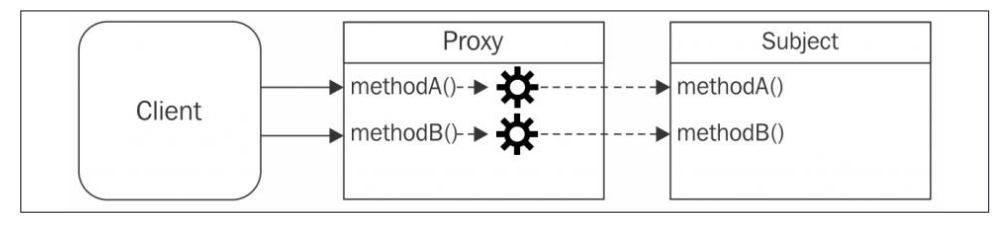
The proxy forwards each operation to the subject, enhancing its behavior with addtional preprocessing or postprocessing. 創建代理對象后,都是直接訪問代理對象,因為代理對象做了增強。
裝飾器模式:動態地增強原對象的功能,我們還是調用原對象,不過執行的是裝飾后的方法。dynamically augmenting the behavior of an existing object.
an adapter converts an object with a given interface so that it can be used in a context where a different interface is expected.

 浙公網安備 33010602011771號
浙公網安備 33010602011771號