
《掰開揉碎講編程-長篇》一文讀懂 哈希表

博主粉絲群介紹: ① 群內(nèi)初中生、高中生、本科生、研究生、博士生遍布,可互相學(xué)習(xí),交流困惑。
② 熱榜top10的常客也在群里,也有數(shù)不清的萬粉大佬,可以交流寫作技巧,上榜經(jīng)驗,漲粉秘籍。
③ 群內(nèi)也有職場精英,大廠大佬,可交流技術(shù)、面試、找工作的經(jīng)驗。
進(jìn)群免費贈送寫作秘籍一份,助你由寫作小白晉升為創(chuàng)作大佬。
進(jìn)群贈送CSDN評論防封腳本,送真活躍粉絲,助你提升文章熱度。
群公告里還有全網(wǎng)大賽and約稿匯總/博客提效工具集/CSDN自動化運營腳本 有興趣的加文末聯(lián)系方式,備注自己的CSDN昵稱,拉你進(jìn)群,互相學(xué)習(xí)共同進(jìn)步。
- 刷算法題的時候,別人的題解總是:"加個哈希表,O(n)秒了"。而你還在糾結(jié):哈希表是什么?為什么能加速?怎么用? 這篇文章就是來解答這些問題的。
前置知識要求
| 知識點 | 重要程度 | 說明 |
|---|---|---|
| 數(shù)組基礎(chǔ) | 必需 ? | 需要了解數(shù)組的基本操作和時間復(fù)雜度 |
| 時間復(fù)雜度 | 必需 ? | 需要理解 O(1)、O(n) 等概念 |
| 基礎(chǔ)編程語法 | 推薦 | 會使用一門編程語言即可 |
| 鏈表 | 加分項 | 了解更佳,不了解也不影響 |
- 必需:沒有這個基礎(chǔ)很難理解本文
- 推薦:有這個基礎(chǔ)學(xué)習(xí)更輕松
- 加分項:了解更好,不了解也不影響
為什么叫 Hash?
Hash 的英文原意就是"切碎、混雜"。想象你在燉一鍋大雜燴(hash):胡蘿卜、土豆、紅肉、白肉……很多復(fù)雜叫不出名的食材混合在一起煮,最后成了一鍋湯。
這個過程就是哈希。
原本各有特點的食材(數(shù)據(jù)),經(jīng)過烹煮(哈希函數(shù)),變成了一鍋融合的湯(Hash 值)。
哈希的本質(zhì):把不能當(dāng)索引的東西(字符串、對象)變成能當(dāng)索引的數(shù)字,但對外呈現(xiàn)為鍵值對,更符合人類思維。
和數(shù)組有什么關(guān)系?
數(shù)組是怎么組織數(shù)據(jù)的?
通過序號(索引),像門牌號一樣:
數(shù)組:[蘋果, 芒果, 葡萄, 草莓, 西瓜]
索引: 0 1 2 3 4
問題來了:我想找到"葡萄"要怎么找?
方法 1:暴力查找(遍歷挨個比對)
第1步:看索引0 → "蘋果" 不是
第2步:看索引1 → "芒果" 不是
第3步:看索引2 → "葡萄" 找到了!
時間復(fù)雜度:O(n) —— 最壞情況要找 n 次
但如果我知道索引呢?
直接訪問:數(shù)組[2] → "葡萄" 一次搞定!
時間復(fù)雜度:O(1) —— 直達(dá),不用挨個找
矛盾點
- 問題:我現(xiàn)在有"葡萄"這個名字,但不知道它在索引幾
- 理想狀態(tài):能不能通過"葡萄"這個名字,直接算出它在索引 2?
哈希表就是來解決這個問題的!
哈希表的做法
用哈希函數(shù)把"葡萄"變成索引
第一步:設(shè)計一個哈希函數(shù)(就像燉湯的配方)
hash("葡萄") = 2 ← 把"葡萄"這個字符串"煮"成數(shù)字2
?
第二步:存儲時
"葡萄" → hash("葡萄") = 2 → 存到數(shù)組[2]的位置
?
第三步:查找時
想找"葡萄"?
→ hash("葡萄") = 2
→ 直接去數(shù)組[2]拿
→ 時間復(fù)雜度:O(1)!
對比總結(jié)
| 查找方式 | 普通數(shù)組遍歷 | 哈希表 |
|---|---|---|
| 操作 | 從頭到尾挨個比對 | 通過哈希函數(shù)直接定位 |
| 過程 | 蘋果 → 芒果 → 葡萄 | hash("葡萄")=2 → 數(shù)組[2] |
| 時間復(fù)雜度 | O(n) | O(1) |
| 特性 | 普通數(shù)組 | 哈希表(基于數(shù)組) |
|---|---|---|
| 底層結(jié)構(gòu) | 數(shù)組 | 數(shù)組 |
| 索引是什么 | 必須是連續(xù)的數(shù)字 0,1,2,3... | 任意類型(通過哈希函數(shù)轉(zhuǎn)成數(shù)字) |
| 存儲方式 | arr[0] = value |
hash("key")→ 索引 →arr[索引] = value |
| 查找速度 | O(1)(知道索引)不知道 O(n) | O(1) 平均 / O(n) 最壞 |
哈希表在代碼中長什么樣?(Java)
在 Java 中,哈希表的表現(xiàn)形式為鍵值對(Key-Value)
// Java 中的 HashMap
HashMap<String, String> fruitMap = new HashMap<>();
?
// 存儲:鍵 → 值
fruitMap.put("apple", "蘋果");
fruitMap.put("grape", "葡萄");
fruitMap.put("mango", "芒果");
?
// 查找:通過鍵直接拿到值
String result = fruitMap.get("grape"); // 返回 "葡萄"
鍵值對是什么?
就像字典一樣:
英文(Key 鍵) 中文(Value 值)
─────────────────────────────
apple → 蘋果
grape → 葡萄
mango → 芒果
- Key(鍵):用來查找的"鑰匙",比如 "apple"
- Value(值):存儲的實際數(shù)據(jù),比如 "蘋果"
底層怎么存的?
還是用數(shù)組!
用戶看到的(鍵值對形式):
"apple" → "蘋果"
"grape" → "葡萄"
?
底層實際存儲(數(shù)組):
[ null, null, "葡萄", "蘋果", null ]
0 1 2 3 4
↑ ↑
hash("grape") hash("apple")
= 2 = 3
過程:
- 你存入
"apple" → "蘋果" - 哈希函數(shù)計算:
hash("apple") = 3 - 把 "蘋果" 存到數(shù)組的
[3]位置 - 查找時:
hash("apple") = 3,直接去[3]拿
- 因為封裝,我們可以不關(guān)注具體實現(xiàn),實現(xiàn)也不是本文的重點,我們已經(jīng)明白了哈希,接下來將講在算法中如何使用哈希
哈希表中常用的方法有哪幾個?
| 方法 | 描述 | 示例代碼 |
|---|---|---|
put(K key, V value) |
向 HashMap 中添加一個鍵值對,如果鍵已存在,則覆蓋原有值。 |
map.put("key1", "value1"); |
get(Object key) |
根據(jù)給定的鍵返回對應(yīng)的值,如果鍵不存在,則返回 null。 |
String value = map.get("key1"); |
containsKey(Object key) |
檢查 HashMap 中是否包含指定的鍵。 |
boolean contains = map.containsKey("key1"); |
containsValue(Object value) |
檢查 HashMap 中是否包含指定的值。 |
boolean contains = map.containsValue("value1"); |
remove(Object key) |
刪除指定鍵的鍵值對,返回該鍵的值,如果鍵不存在則返回 null。 |
map.remove("key1"); |
clear() |
清空 HashMap 中的所有鍵值對。 |
map.clear(); |
size() |
返回 HashMap 中鍵值對的數(shù)量。 |
int size = map.size(); |
isEmpty() |
判斷 HashMap 是否為空。 |
boolean isEmpty = map.isEmpty(); |
keySet() |
返回 HashMap 中所有鍵的集合。 |
Set keys = map.keySet(); |
values() |
返回 HashMap 中所有值的集合。 |
Collection values = map.values(); |
entrySet() |
返回 HashMap 中所有鍵值對的集合。 |
Set> entrySet = map.entrySet(); |
| getOrDefault | 根據(jù)鍵 key 獲取對應(yīng)的值,如果鍵不存在,則將值變?yōu)?defaultValue。 |
map.getOrDefault("key1", "defaultValue"); |
實戰(zhàn):刷 LeetCode 時怎么用哈希表得到更好的時間復(fù)雜度?
簡單題:難度 1
給你一個整數(shù)數(shù)組 nums 。
如果一組數(shù)字 (i,j) 滿足 nums[i] == nums[j] 且 i < j ,就可以認(rèn)為這是一組 好數(shù)對 。
返回好數(shù)對的數(shù)目。
示例 1:
輸入:nums = [1,2,3,1,1,3]
輸出:4
解釋:有 4 組好數(shù)對,分別是 (0,3), (0,4), (3,4), (2,5) ,下標(biāo)從 0 開始
示例 2:
輸入:nums = [1,1,1,1]
輸出:6
解釋:數(shù)組中的每組數(shù)字都是好數(shù)對
示例 3:
輸入:nums = [1,2,3]
輸出:0
提示:
1 <= nums.length <= 100
1 <= nums[i] <= 100
- 算法小白,第一眼看過去肯定是用雙重循環(huán)暴力破解,但咱們已經(jīng)學(xué)過哈希了,應(yīng)該能想到這道題要用哈希來做。
答案

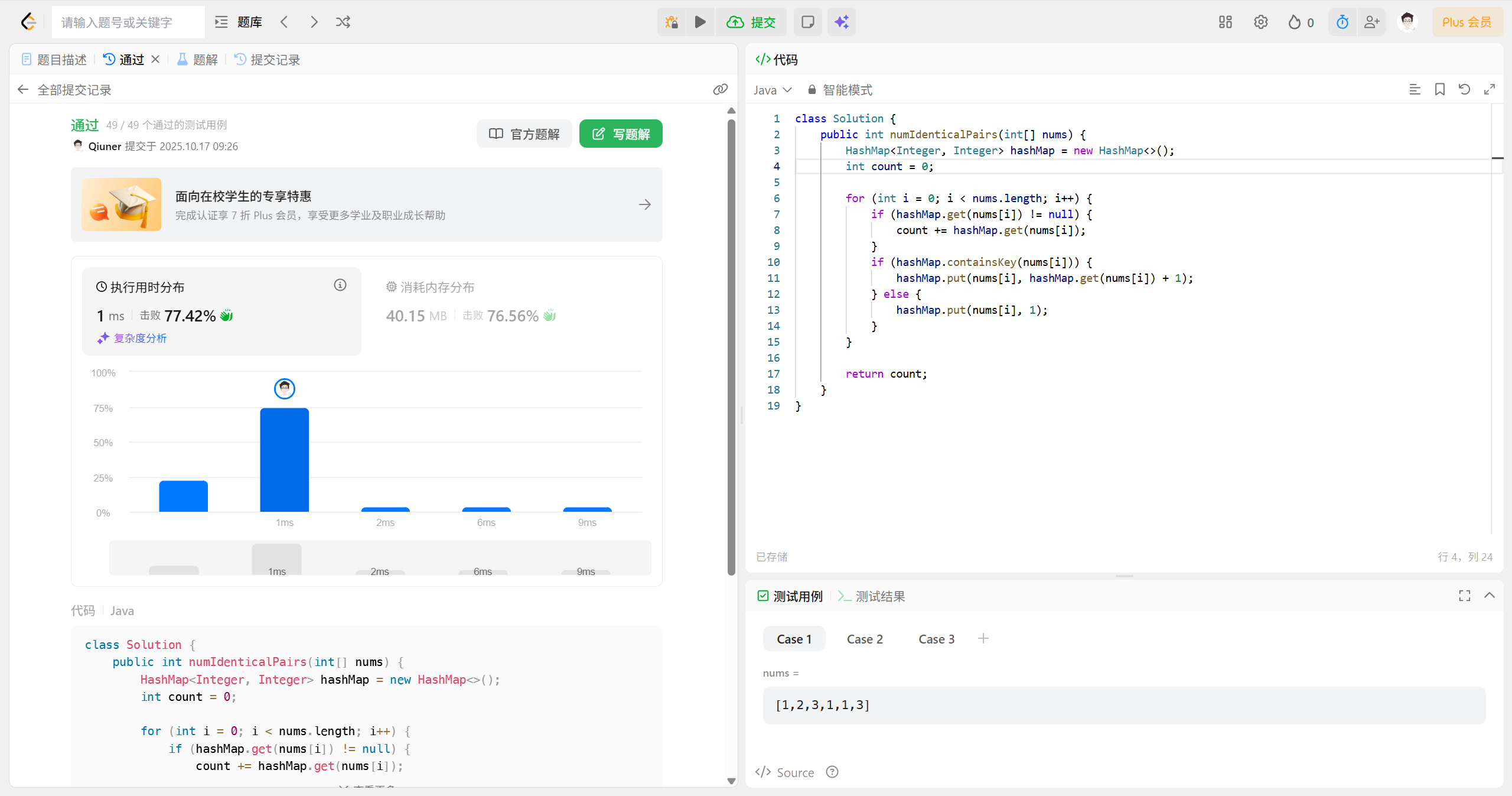
class Solution {
// 定義方法,輸入為整數(shù)數(shù)組,返回滿足條件的配對數(shù)量
public int numIdenticalPairs(int[] nums) {
// 創(chuàng)建一個 HashMap 來存儲每個數(shù)字出現(xiàn)的次數(shù)
HashMap<Integer, Integer> hashMap = new HashMap<>();
int count = 0; // 用來記錄符合條件的配對數(shù)
// 遍歷數(shù)組中的每個元素
for (int i = 0; i < nums.length; i++) {
// 如果該數(shù)字已經(jīng)出現(xiàn)在哈希表中,累加已有的配對數(shù)
if (hashMap.get(nums[i]) != null) {
count += hashMap.get(nums[i]);
}
// 更新該數(shù)字在哈希表中的出現(xiàn)次數(shù)
if (hashMap.containsKey(nums[i])) {
hashMap.put(nums[i], hashMap.get(nums[i]) + 1);
} else {
hashMap.put(nums[i], 1);
}
}
return count; // 返回符合條件的配對數(shù)
}
}
通用小技巧
不知道你有沒有一個感覺,覺得我文中的代碼是可以化簡的?
如果你沒有這種感覺,那我建議回過頭去看 哈希表中常用的方法有哪幾個? 這一小結(jié)內(nèi)容
if (hashMap.containsKey(nums[i])) {
hashMap.put(nums[i], hashMap.get(nums[i]) + 1);
} else {
hashMap.put(nums[i], 1);
}
分割線
分割線,你可以自己想想
- 是的,可以變成這種一行的形式
hashMap.put(nums[i], hashMap.getOrDefault(nums[i], 0) + 1);
簡單題:難度 2
給定兩個字符串 s 和 t ,它們只包含小寫字母。
字符串 t 由字符串 s 隨機(jī)重排,然后在隨機(jī)位置添加一個字母。
請找出在 t 中被添加的字母。
- 也很簡單,先把 s 出現(xiàn)過的字母全部 put 到哈希表里面去,然后再來個循環(huán)
答案

import java.util.HashMap;
class Solution {
public char findTheDifference(String s, String t) {
HashMap<Character,Integer> hash = new HashMap();
for(int i=0;i<s.length();i++){
char ch = s.charAt(i);
if (hash.containsKey(ch)) {
hash.put(ch, hash.get(ch) + 1);
} else {
hash.put(ch, 1);
}
}
for(int i=0;i<t.length();i++){
char ch =t.charAt(i);
if(hash.containsKey(ch)){
hash.put(ch,hash.get(ch)-1);
if(hash.get(ch)<0){
return ch;
}
}else{
return ch;
}
}
return ' ';
}
}
如果你看到這段代碼沒有感覺到不對,那你一定沒有仔細(xì)想過通用小技巧。
不難發(fā)現(xiàn)
if (hash.containsKey(ch)) {
hash.put(ch, hash.get(ch) + 1);
} else {
hash.put(ch, 1);
}
這部分代碼可以變成
hash.put(ch, hash.getOrDefault(ch, 0) + 1);
中等題:難度 4
- 這道題需要會回溯算法,哈希只起到一個存儲字母映射的功能。不合適做教學(xué)
- 那就這樣結(jié)束了
為什么會有不同的哈希表?
想象一下,你有 100 個格子,但要存 1000 個東西。哈希函數(shù)把不同的 key 算出了相同的位置,這就是"哈希沖突"。怎么辦?
不同的哈希表就是用不同的方法來解決這個問題的。
主要的哈希表種類
鏈表法哈希表(最常見)
- 怎么做? 每個格子里放一個鏈表,沖突了就往鏈表后面加
- 優(yōu)點: 簡單粗暴,永遠(yuǎn)不會"滿"
- 缺點: 鏈表太長查找就慢了
- 誰在用? Java 的 HashMap、Python 的 dict
開放尋址法哈希表
- 怎么做? 沖突了就繼續(xù)往后找空位
- 優(yōu)點: 數(shù)據(jù)緊湊,緩存友好,速度快
- 缺點: 容易"扎堆",刪除操作麻煩
- 誰在用? Python 早期版本、Redis 的字典
布谷鳥哈希(Cuckoo Hashing)
- 怎么做? 用兩個哈希函數(shù),沖突了就把原來的元素"踢走"
- 優(yōu)點: 查找超快,最壞情況也是 O(1)
- 缺點: 插入可能觸發(fā)連鎖反應(yīng)
- 適合: 讀多寫少的場景
一致性哈希(Consistent Hashing)
-
怎么做? 把 key 和服務(wù)器都映射到一個環(huán)上
-
優(yōu)點: 增刪節(jié)點時數(shù)據(jù)遷移量小
-
適合: 分布式系統(tǒng)、負(fù)載均衡
-
缺點:非常多,百度下吧
-
就像選工具箱里的工具,錘子、螺絲刀、扳手各有各的用處。不同的哈希表就是為了應(yīng)對不同的實際需求而生的,永遠(yuǎn)沒有完美的解決方案,永遠(yuǎn)更優(yōu)的解決方案。
- 內(nèi)存敏感?用開放尋址
- 要求簡單穩(wěn)定?用鏈表法
- 分布式場景?用一致性哈希
- 讀操作特別多?考慮布谷鳥哈希
題外話:哈希表的前世今生與永遠(yuǎn)的更優(yōu)
前世
- 1953 年,IBM 的 Hans Peter Luhn 首次提出了哈希的概念
- 真正讓哈希表發(fā)揚光大的是 1968 年的一篇論文,作者是 Robert Morris
- 當(dāng)時計算機(jī)內(nèi)存很貴,程序員們迫切需要一種能快速查找數(shù)據(jù)、又不占太多空間的方法
- 哈希表就是在這種背景下誕生的——用"空間換時間"的智慧
今生
- 現(xiàn)在幾乎所有編程語言都內(nèi)置了哈希表:
- Python 的
dict - Java 的
HashMap - JavaScript 的
Object和Map - C++ 的
unordered_map
- Python 的
- 數(shù)據(jù)庫索引、緩存系統(tǒng)(Redis)、區(qū)塊鏈、密碼學(xué)都在用它
- LeetCode 上大概有幾百道題都能用哈希表
從 1953 年 IBM 的 Hans Peter Luhn 第一次提出哈希的概念,到今天各種花式哈希表遍地開花,這個數(shù)據(jù)結(jié)構(gòu)已經(jīng)走過了 70 多年。
每隔幾年就會冒出新的變種——Robin Hood Hashing、Hopscotch Hashing、Swiss Table...工程師們像煉金術(shù)士一樣,不斷調(diào)整著時間、空間、復(fù)雜度之間的平衡。
也許這就是計算機(jī)科學(xué)的魅力:沒有銀彈,只有權(quán)衡。每一種"更優(yōu)",都只是在特定場景下的"更合適"。
天才
- 筆者在寫這篇博客查閱資料時,偶然看到一個挺有意思的故事。羅格斯大學(xué)有個本科生,安德魯·克拉皮文,有一天他讀到一篇叫《Tiny Pointers》的論文,突然靈光一閃:誒,這個 tiny pointer 的內(nèi)存占用還能再優(yōu)化!
- 于是他開始動手,打算用哈希表來存儲 tiny pointer 指向的數(shù)據(jù)。結(jié)果在折騰的過程中,這哥們居然意外發(fā)現(xiàn)了一種速度更快的方法,這個方法,推翻了計算機(jī)科學(xué)界一個被奉為圭臬的理論——姚氏猜想。
- 1985 年,圖靈獎得主、著名計算機(jī)科學(xué)家姚期智在論文《Uniform Hashing Is Optimal》里說:對于某些特定類型的哈希表,最優(yōu)的查找方法就是"均勻探測"(uniform probing),而且最壞情況下,插入一個元素的時間復(fù)雜度就是 O(x),沒法再快了。而在今年,這條鐵律被打破了。
- 這相當(dāng)于什么呢
- 一個業(yè)余棋手在研究殘局時,發(fā)現(xiàn)了一個被公認(rèn)為"必輸"的棋局其實有破解方法,推翻了世界冠軍級大師的定論。
- 一個土木工程本科生在做畢業(yè)設(shè)計時,找到了一種新的橋梁結(jié)構(gòu),突破了權(quán)威教授論文中"該跨度下的最大承重極限"。
- 一個語言學(xué)學(xué)生在研究方言時,發(fā)現(xiàn)了一個反例推翻了著名語言學(xué)家提出的"某類語法結(jié)構(gòu)在所有人類語言中都不存在"的結(jié)論
- …………
姚期智:我用嚴(yán)密的數(shù)學(xué)證明這是極限。
克拉皮文:哦,我不知道,我就隨便試試。
姚期智:???
- 下圖為:安德魯·克拉皮文
- 論文相關(guān)


 浙公網(wǎng)安備 33010602011771號
浙公網(wǎng)安備 33010602011771號