

Hadoop3 在eclipse中訪問(wèn)hadoop并運(yùn)行WordCount實(shí)例
前言:
畢業(yè)兩年了,之前的工作一直沒(méi)有接觸過(guò)大數(shù)據(jù)的東西,對(duì)hadoop等比較陌生,所以最近開(kāi)始學(xué)習(xí)了。對(duì)于我這樣第一次學(xué)的人,過(guò)程還是充滿了很多疑惑和不解的,不過(guò)我采取的策略是還是先讓環(huán)境跑起來(lái),然后在能用的基礎(chǔ)上在多想想為什么。
通過(guò)這三個(gè)禮拜(基本上就是周六周日,其他時(shí)間都在加班啊T T)的探索,我目前主要完成的是:
1.在Linux環(huán)境中偽分布式部署hadoop(SSH免登陸),運(yùn)行WordCount實(shí)例成功。 http://www.rzrgm.cn/PurpleDream/p/4009070.html
2.自己打包hadoop在eclipse中的插件。 http://www.rzrgm.cn/PurpleDream/p/4014751.html
3.在eclipse中訪問(wèn)hadoop運(yùn)行WordCount成功。 http://www.rzrgm.cn/PurpleDream/p/4021191.html
所以我下邊會(huì)分三次記錄下我的過(guò)程,為自己以后查閱方便,要是能幫助到其他人,自然是更好了!
===============================================================長(zhǎng)長(zhǎng)的分割線====================================================================
正文:
在之前的兩篇文章中,我主要是介紹了自己初次學(xué)習(xí)hadoop的過(guò)程中是如何將hadoop偽分布式模式部署到linux環(huán)境中的,以及如何自己編譯一個(gè)hadoop的eclipse插件。如果大家有需要的話,可以點(diǎn)擊我在前言中列出的前兩篇文章的鏈接。
今天,我將在eclipse中,講解如何使用MapReduce。對(duì)于下面的問(wèn)題,我們首先講解的是,如何在eclipse中配置DFS Location,然后講解的是,在配置好的Location上運(yùn)行WordCount實(shí)例。
第一步,配置DFS Location:
1.打開(kāi)eclipse之后,切換到Map/Reduce模式,點(diǎn)擊右下角的“new hadoop Location”圖標(biāo),彈出一個(gè)彈出框,如下圖所示,頁(yè)面中中有兩個(gè)頁(yè)簽需要配置,分別是General和Advanced Parameters。

2.首先,我們先配置General中內(nèi)容。General中主要需要我們進(jìn)行Map/Reduce和HDFS的host的配置。
(1).之前我們?cè)贚inux安裝hadoop時(shí),曾經(jīng)修改了兩個(gè)配置文件,分別是mapred-site.xml和core-site.xml。當(dāng)時(shí)我們?cè)倥渲玫臅r(shí)候,配置的主機(jī)就是localhost和端口號(hào)。這里由于我們是在eclipse遠(yuǎn)程訪問(wèn)你Linux服務(wù)器中的hadoop,所以我們需要將原來(lái)配
置文件中的localhost修改成你服務(wù)器的ip地址,端口號(hào)不變(當(dāng)然你可以參考網(wǎng)上的文章,配置host文件)。
(2).然后將eclipse中我們剛才打開(kāi)的General頁(yè)簽中的Map/Reduce的host配置成你的mapred-site.xml配置的ip地址和端口號(hào);再將HDFS的host配置成你的core-site.xml配置的ip地址和端口號(hào)。注意,如果你勾選了HDFS中的那個(gè)“Use M/R Master Host”選項(xiàng),那么HDFS的host將默認(rèn)與Map/Reduce中配置的ip地址一致,端口號(hào)可另行配置。
3.然后,我們要配置的是Advanced Parameters這個(gè)選項(xiàng)卡中的內(nèi)容,這里面的內(nèi)容比較多,但是不要緊張哦,因?yàn)槲覀冊(cè)诘谝淮闻渲脮r(shí),可以使用他的默認(rèn)配置。
(1)打開(kāi)這個(gè)選項(xiàng)卡,我們可以瀏覽一下這里面的內(nèi)容,著重看下其中選項(xiàng)值包含“/tmp/.....”這種目錄結(jié)構(gòu)的選項(xiàng),如果我們后邊自己配置的話,其實(shí)要修改的也就是這些項(xiàng)。默認(rèn)的“dfs.data.dir”是在linux服務(wù)器中的“/tmp”目錄下,有時(shí)會(huì)帶上你的root賬號(hào),這個(gè)可以根據(jù)自己的需要。
(2).如果你不想使用上邊的默認(rèn)配置,則我們根據(jù)自己的需要,在我們安裝的hadoop中的hdfs-site.xml文件中,增加對(duì)“dfs.data.dir”這個(gè)選項(xiàng)的配置,對(duì)應(yīng)的目錄自己可以提前建立,我的配置如圖:
<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Put site-specific property overrides in this file. --> <configuration> <property> <name>dfs.data.dir</name> <value>/myself_setted/hadoop/hadoop-1.0.1/myself_data_dir/dfs_data_dir</value> </property> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.permissions</name> <value>false</value> </property> </configuration>
(3).以我的配置為例,如果我在hadoop的服務(wù)器端做了這樣的配置,那么我在Advanced Parameters選項(xiàng)卡中,需要修改下面的的幾個(gè)選項(xiàng)的value值,注意,其實(shí)有個(gè)小技巧,你在配置的時(shí)候,先找到“hadoop.tmp.dir”這個(gè)選項(xiàng),將這個(gè)選項(xiàng)配置成你自定義的目錄位置,然后將Location這個(gè)彈出框關(guān)掉,再選中剛才的那個(gè)Location重新點(diǎn)擊右下角的“Edit hadoop Location”選項(xiàng)(在“new hadoop Location”旁邊),然后再切換到Advanced Parameters選項(xiàng)卡,會(huì)發(fā)現(xiàn)與之相關(guān)的幾個(gè)選項(xiàng)的目錄前綴都會(huì)發(fā)生改變,這時(shí)候你在瀏覽一下其他選項(xiàng),確保目錄前綴都進(jìn)行了修改,就ok了。
dfs.data.dir => /myself_setted/hadoop/hadoop-1.0.1/myself_data_dir/hadoop_tmp_dir/dfs/data
dfs.name.dir => /myself_setted/hadoop/hadoop-1.0.1/myself_data_dir/hadoop_tmp_dir/dfs/name
dfs.name.edits.dir => /myself_setted/hadoop/hadoop-1.0.1/myself_data_dir/hadoop_tmp_dir/dfs/name
fs.checkpoint.dir => /myself_setted/hadoop/hadoop-1.0.1/myself_data_dir/hadoop_tmp_dir/dfs/namesecondary
fs.checkpoint.edits.dir => /myself_setted/hadoop/hadoop-1.0.1/myself_data_dir/hadoop_tmp_dir/dfs/namesecondary
fs.s3.buffer.dir => /myself_setted/hadoop/hadoop-1.0.1/myself_data_dir/hadoop_tmp_dir/s3
hadoop.tmp.dir => /myself_setted/hadoop/hadoop-1.0.1/myself_data_dir/hadoop_tmp_dir
mapred.local.dor => /myself_setted/hadoop/hadoop-1.0.1/myself_data_dir/hadoop_tmp_dir/mapred/local
mapred.system.dir => /myself_setted/hadoop/hadoop-1.0.1/myself_data_dir/hadoop_tmp_dir/mapred/system
mapred.temp.dir => /myself_setted/hadoop/hadoop-1.0.1/myself_data_dir/hadoop_tmp_dir/mapred/temp
mapreduce.jobtracker.staging.root.dir => /myself_setted/hadoop/hadoop-1.0.1/myself_data_dir/hadoop_tmp_dir/mapred/staging
4.經(jīng)過(guò)上邊的幾步,我們自己的Location已經(jīng)配置完了,這時(shí)候如果沒(méi)有什么問(wèn)題的話,會(huì)在我們的eclipse的左上角“DFS Location”的下面,顯示出我們剛剛配置好的Location,右鍵點(diǎn)擊這個(gè)Location的選擇“Refresh”或者“ReConnect”,如果之前的配置沒(méi)有問(wèn)題的話,會(huì)顯示我們?cè)?a href="http://www.rzrgm.cn/PurpleDream/p/4009070.html" target="_blank">第一篇文章中上傳的a.txt文件,以及我們之前在linux服務(wù)器端運(yùn)行hadoop成功的output文件夾,如下圖。如果沒(méi)有上傳文件,那么只會(huì)顯示“dfs.data.dir”這個(gè)目錄。

第二步,運(yùn)行Word Count實(shí)例:
1.Location配置好之后,我們可以在eclipse中建立一個(gè)MapReduce項(xiàng)目的工程。
(1).利用反編譯軟件,從hadoop-1.0.1的安裝包中反編譯hadoop-examples-1.0.1.jar這個(gè)jar包,將其中的Word Count類取出來(lái),放到你剛才建立的工程中。注意,如果你之前參考的在編譯eclipse的hadoop插件時(shí),參考的是我的第二篇文章的方法,這里需要加一步,右鍵點(diǎn)擊項(xiàng)目選擇buidld Path,對(duì)于以“hadoop-”開(kāi)頭的jar包,除了“hadoop-core-1.0.1.jar”和“hadoop-tools-1.0.1.jar”這兩個(gè)jar包,其余的以“hadoop-”開(kāi)頭的jar包都要?jiǎng)h除掉。主要是因?yàn)槿绻粍h除,會(huì)導(dǎo)致WordCount這個(gè)類方法中的有些累引入的不正確。
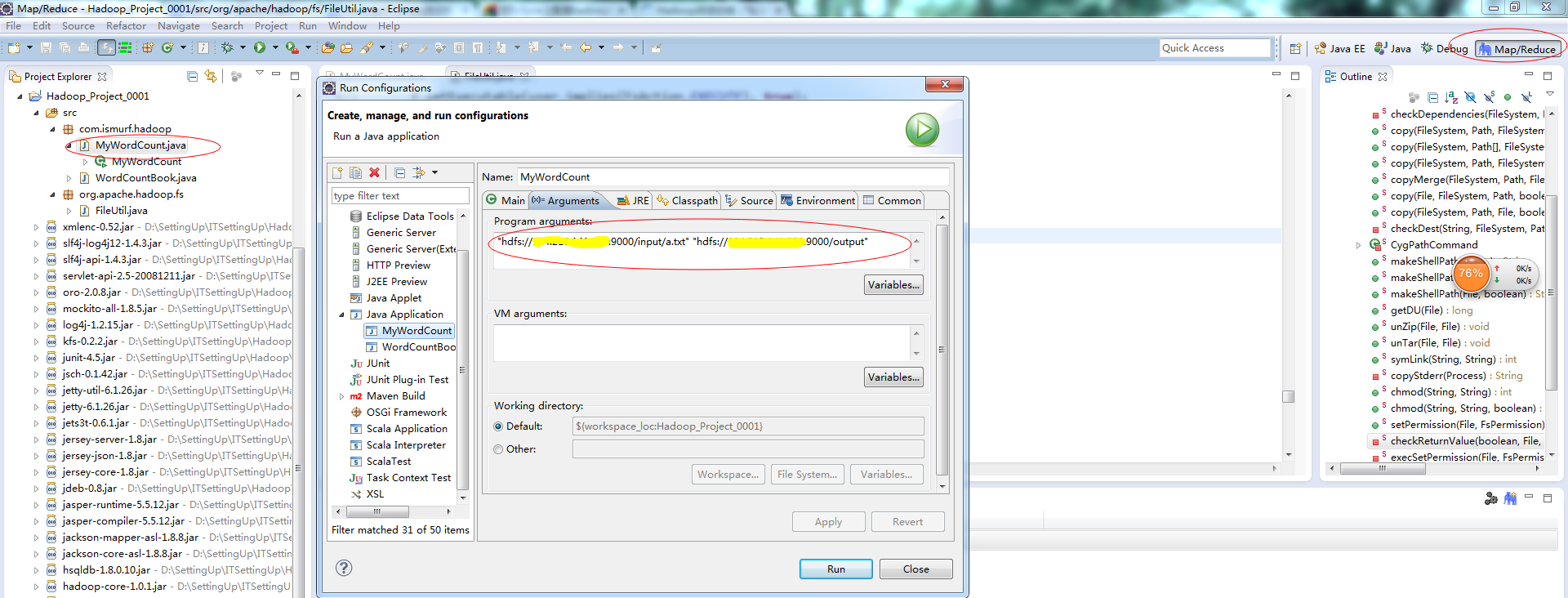
2.項(xiàng)目建立好之后,我們?cè)赪ordCount類中,右鍵選擇“Run Configurations”彈出一個(gè)彈出框,如下圖,然后選中“Arguments”選項(xiàng)卡,在其中的“Program arguments”中配置你的hdfs的input文件的目錄和output目錄,然后點(diǎn)擊“run”,運(yùn)行即可,如果在console中沒(méi)有拋出異常,證明運(yùn)行成功,可選擇左上角的Location,選擇“Refresh”,會(huì)顯示你的output文件夾以及運(yùn)行的結(jié)果文件。
第三步,錯(cuò)誤排除:
1.如果之前的output文件夾存在,你直接在eclipse中運(yùn)行WordCount方法的話,可能console會(huì)報(bào)“output文件夾已經(jīng)存在”這個(gè)錯(cuò)誤,那么你只需要現(xiàn)將Location中的output文件夾刪除,這個(gè)錯(cuò)誤就不會(huì)報(bào)了。
2.如果你運(yùn)行的過(guò)程中報(bào)了“org.apache.hadoop.security.AccessControlException: Permission denied:。。。。”這個(gè)錯(cuò)誤,是由于本地用戶想要遠(yuǎn)程操作hadoop沒(méi)有權(quán)限引起的,這時(shí),我們需要在hdfs-site.xml中配置dfs.permissions屬性修改為false(默認(rèn)為true),可以參考本文上邊關(guān)于“hdfs-site.xml”的配置。
3.如果你運(yùn)行的過(guò)程中報(bào)了“Failed to set permissions of path:。。。。”這個(gè)錯(cuò)誤,解決方法是修改/hadoop-1.0.1/src/core/org/apache/hadoop/fs/FileUtil.java里面的checkReturnValue,注釋掉即可(有些粗暴,在Window下,可以不用檢查)。注意,此處修改時(shí),網(wǎng)上的一般方法是,重新編譯hadoop-core的源碼,然后重新打包。其實(shí)如果想省事兒一點(diǎn)的話,我們可以在項(xiàng)目中建立一個(gè)org.apache.hadoop.fs這個(gè)包,將FileUtil.java這個(gè)類復(fù)制到這個(gè)包里面,按照下邊圖片中的修改方法,修改FileUtil.java就行了。之所以這種方法也行,是因?yàn)閖ava運(yùn)行時(shí),會(huì)優(yōu)先默認(rèn)在本項(xiàng)目的源碼中掃描相同路徑的包,然后才是引入的jar文件中的。

經(jīng)過(guò)上邊的步驟,我想多數(shù)情況下,你已經(jīng)成功的在eclipse中遠(yuǎn)程訪問(wèn)了你的hadoop了,也許在你實(shí)踐的過(guò)程中還會(huì)碰到其他問(wèn)題,只要你耐心的在網(wǎng)上搜索資料,相信一定可以解決的,切記不要太著急。

 浙公網(wǎng)安備 33010602011771號(hào)
浙公網(wǎng)安備 33010602011771號(hào)