當 think 遇上 tool:深入解析 Agent 的規劃之道
?? 當 think 遇上 tool:深入解析 Agent 的規劃之道
字數:約 3500 字 | 預計閱讀時間:10 分鐘
大家好,我是 Leon。
AIcoding越來越卷,工具越接越多,但越用越讓我焦慮 —— 特別是某 c....r
它總像一個急著表現的新同事,不問全局、就開始動手執行。我發現它:
- 剛啟動就火力全開:不等我把意圖講完就調工具;
- 重復調用接口:出了錯就死磕一個 API,絲毫沒有“換個思路”的意識;
- 邏輯斷片嚴重:上一秒還在分析,下一秒就不記得自己分析的是什么。
這些坑我踩過太多次,以至于后來我都養成了“先給 AI 做一個冷啟動提示詞”的習慣。
有點像是:
“你別急,我先幫你想好怎么干,你再去動手。”
我們人類其實很擅長“在腦子里先走一遍流程”這件事。
這種能力,說白了就是 規劃(Planning)。AI 不具備,是因為它根本沒有“做計劃”這個意識。
作為一個在 AI 應用開發一線摸爬滾打的算法工程師,我的目標是讓 Agent 擁有它。今天就和大家分享一下最近的學習心得 —— 如何讓你的 Agent 學會「三思而后行」:基于 Anthropic、OpenAI 的最新研究,以及我在實際開發中的踩坑經驗。
一、AI,不擅長“打草稿”這件小事
數據不會騙人,兩個官方實驗直接拉開了差距
實驗1:OpenAI官方的"強行規劃"實驗
在 SOTA 論文里,OpenAI 的研究員干了一件很極致的事——他們不是引導模型去規劃,而是強行命令它:“先規劃,再行動,別自作主張”。
貼一個原話:
"You MUST plan extensively before each function call,
and reflect extensively on the outcomes of the previous function calls.
DO NOT do this entire process by making function calls only,
as this can impair your ability to solve the problem and think insightfully."
多加這一句,SWE-bench 的通過率就提升了 4%。
雖然你可能覺得 4% 不多,但要知道這是在已經很強的模型上拉的提升。
更重要的是——OpenAI 這個實驗不是靠 prompt 魔法,而是配合后訓練(RLHF)來強化這個指令的。
我們用的開源模型,別說RLHF了,連理解都不一定到位……
實驗2:Anthropic的"思考工具"
Anthropic更進一步,他們不只是"要求"模型規劃,而是給了模型一個專門的工具——think tool:
{
"name": "think",
"description": "Use this tool when you need to think through a problem step by step",
"input_schema": {
"type": "object",
"properties": {
"thought": {
"type": "string",
"description": "Your structured thinking process"
}
}
}
}
看起來簡單到令人發指,對吧?但這就是工程學的美妙之處——最優雅的解決方案往往是最簡單的。
直接在 τ-bench 上直接提升了 54% 的完成率。
一個“思考工具”能頂得上半個模型優化?!
然后我意識到一件事:這不是在優化“推理能力”,這是在重塑模型的行為模式——讓它從“習慣執行”變成“先組織認知,再輸出行為”。
Think Tool vs Extended Thinking:不只是"暫停"
這里有個重要的概念需要澄清。很多人會問:"這和Extended Thinking有什么區別?"
- Extended Thinking發生在AI開始響應之前,像是在心里打草稿
- Think Tool發生在AI開始響應之后,像是在工作過程中主動停下來整理思路
| 模式 | 思考發生時間 | 可控性 | 記錄性 |
|---|---|---|---|
| Extended Thinking | 回復之前 | 黑盒 | 無法追蹤 |
| Think Tool | 回復之中 | 顯式觸發 | 可記錄、可分析 |
Think Tool更適合處理那些需要分析外部信息的復雜場景,比如:
- 分析工具調用的返回結果
- 在長鏈工具調用中保持邏輯一致性
- 在政策繁復的環境中確保合規性
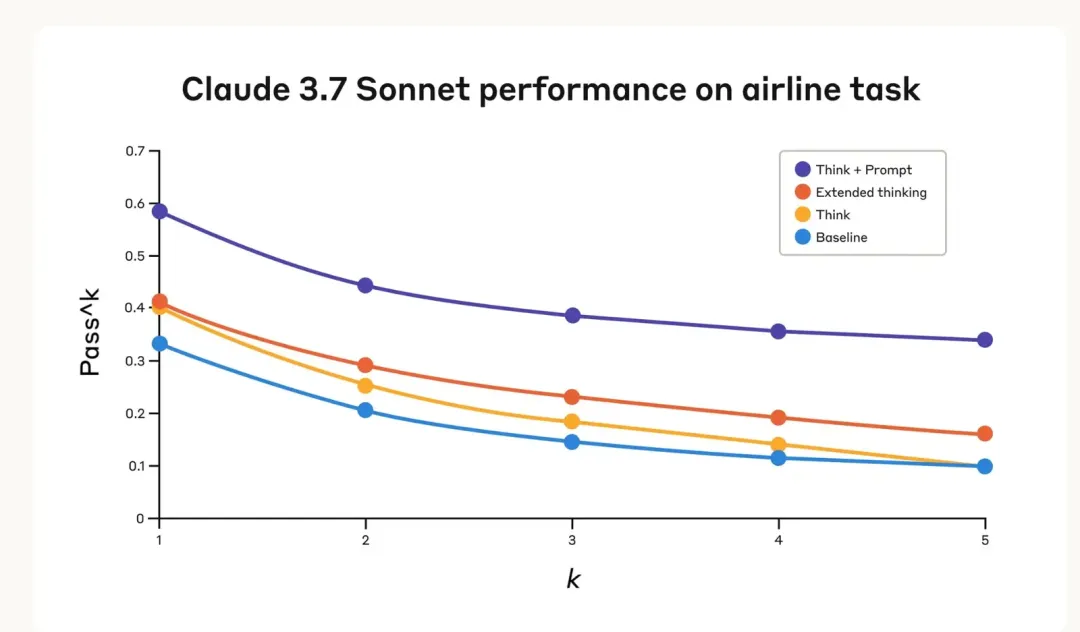
54%的性能提升背后,是AI從"盲目執行"到"深思熟慮"的質的飛躍。
你可能會覺得:一個工具調用而已,至于這么講究嗎?
但我想說的是,在我不斷試錯的過程中發現,只有讓“思考”成為流程的一部分,Agent 才不再是一個隨機響應的黑盒,而是一個可以協同的思考體。
這就是我為什么把“規劃能力”當成是 Agent 的第一性能力——只有它擁有了“畫施工圖”的本領,才有可能成為我們真正意義上的智能助手。
二、三大主流規劃方案:各有千秋
那么,如何讓AI學會規劃呢?目前業界主流的方案有三種,各有千秋
| 方案 | 代表 | 實現方式 | 我的評價 |
|---|---|---|---|
| Prompt顯式規劃 | OpenAI | 在Prompt中要求輸出規劃步驟 | 簡單直接,但效果限于OAI的后訓練模型 |
| 結構化思考工具 | Anthropic | 定義think工具讓模型主動調用 | 可靠性高無限制,首選 |
| 獨立規劃模塊 | OpenManus | 專門的Planning Flow生成計劃 | 適合超復雜任務,但重炮打蚊子 |
為什么“思考工具”是當前優選?
Leon's Take: 作為一個追求優雅和通用方案的J人,答案其實很清晰。我們需要的不是一個更聰明的“黑盒”,而是一個更可靠、更可控的“流程”。
-
開源模型友好:對于"請規劃一下"這種模糊指令,開源模型的理解能力參差不齊。但「調用xx工具」這是它們的強項。
-
強制結構化:工具可以強制模型輸出特定字段,比如:
{ "thought": "當前分析", "plan": "分解步驟", "action": "下一步行動", "step_number": "步驟編號" } -
可追溯調試:每次思考都有記錄,出問題時能快速定位。
螞蟻集團的論文也印證了我的想法。他們在構建自己的Agent平臺時,最終選擇了復用Anthropic的 思考工具 思路
螞蟻集團的生產級實踐
螞蟻的工程師們在實際部署中,設計了一個更加工程化的思考工具:
{
"name": "思考和規劃",
"description": "分階段梳理思考、計劃、行動",
"input_schema": {
"properties": {
"thought": {"type": "string"}, // 當前分析
"plan": {"type": "string"}, // 分解步驟
"action": {"type": "string"}, // 下一步建議
"thoughtNumber": {"type": "string"} // 步驟編號
},
"required": ["thought", "plan", "action", "thoughtNumber"]
}
}
這個設計的巧妙之處在于:
- 強制結構化:避免模糊的思考內容
- 步驟追蹤:便于調試和優化
- 行動導向:直接輸出下一步該做什么
- 流式友好:支持實時輸出,提升用戶體驗
特別是thoughtNumber,對于我們這些需要調試和復盤的J人來說,簡直是福音。
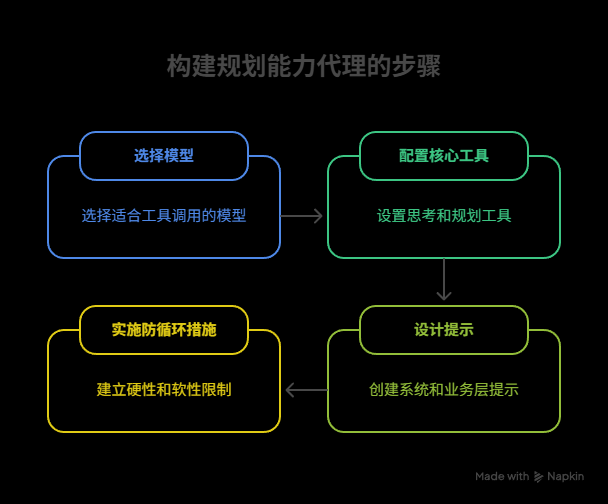
三、實戰指南:四步構建規劃Agent
接下來,我們以構建一個具備規劃能力的Agent為例,提供一套從模型選型到Prompt設計的完整實踐指南。
Step 1: 模型選型——工欲善其事,必先利其器
- 推薦:優先選擇對Function Call(工具調用)優化過的模型,例如
DeepSeek-V3 Function Call版。這類模型能更好地理解和執行工具調用指令。 - 避坑:避免選擇為通用對話設計的模型,如
DeepSeek-R1,它們在多工具連續調用場景下可能表現不佳,且延遲較高。 - 參數設置:建議將生成多樣性參數(如
temperature)設置為一個較低的值,比如0.3。這有助于在保證準確性的前提下,獲得一些有限的創造性,避免模型“胡思亂想”。
Step 2: 核心關鍵工具配置
思考與規劃工具 (think_and_plan)
這是我們為Agent植入的“大腦”。它的定義至關重要。
{
"name": "think_and_plan",
"description": "在執行任何業務操作前必須調用的思考工具。像人類一樣先思考再行動。",
"input_schema": {
"type": "object",
"properties": {
"user_intent": {
"type": "string",
"description": "你對用戶核心需求的理解"
},
"current_situation": {
"type": "string",
"description": "當前狀態分析,包括已有信息和缺失信息"
},
"plan": {
"type": "array",
"items": {"type": "string"},
"description": "詳細的執行步驟列表,每步都要具體可執行"
},
"next_action": {
"type": "string",
"description": "基于規劃確定的下一個具體行動"
}
},
"required": ["user_intent", "current_situation", "plan", "next_action"]
}
}
使用邏輯:可以在System Prompt強制模型在每次調用業務工具前,必須先調用此think_and_plan工具。模型需要根據這個工具的輸出來決策下一步的具體行動。
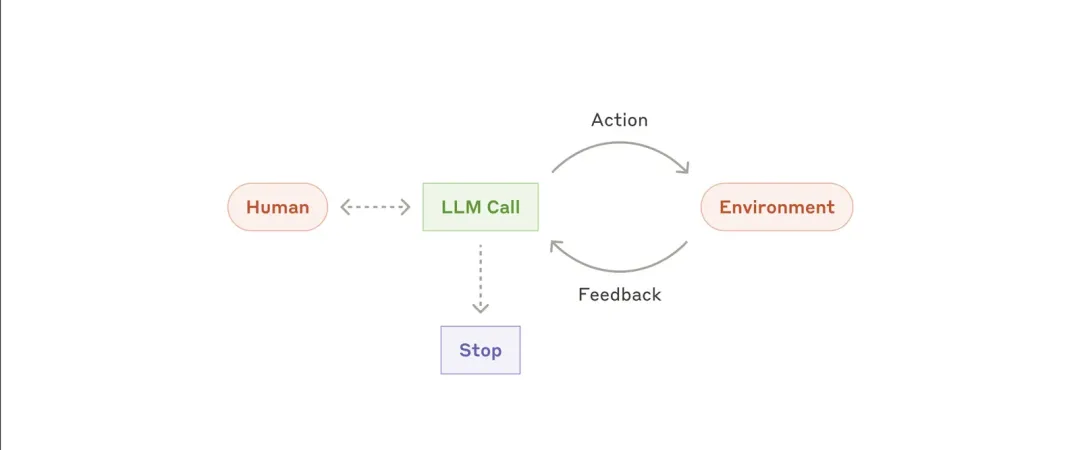
?? 核心經驗:投入在優化工具和工具Prompt描述上的精力,與最終提升用戶體驗的精力,是1:1的。(這句話得是多么痛的領悟...
業務工具描述——像寫API文檔一樣嚴謹
一個常見的失敗模式是Agent遇到問題時,陷入無限循環調用。我們需要一個“熔斷”機制,這和寫普通代碼的異常處理邏輯是相通的,另外給LLM的路徑盡量用絕對路徑等等
? 好的工具描述:
{
"name": "file_analyzer",
"description": "分析文件內容和結構。支持.txt, .csv, .json格式。文件大小限制10MB。",
"when_to_use": "當用戶需要了解文件內容、格式或統計信息時使用",
"limitations": "不支持二進制文件,不能修改文件內容",
"input_schema": {
"properties": {
"file_path": {
"type": "string",
"description": "文件的絕對路徑,例如:/home/user/data.csv"
}
}
}
}
? 糟糕的工具描述:
{
"name": "file_tool",
"description": "處理分析文件內容",
"input_schema": {
"properties": {
"path": "./data.csv"
"type": "string"
}
}
}
區別在哪里?好的描述告訴AI:
- 什么時候用我(使用場景)
- 我能做什么(功能邊界)
- 我做不了什么(限制條件)
- 怎么用我(參數規范)
Step 3: Prompt設計——Agent的"行為準則"
系統級指令
# Agent核心工作流程
你是一個具備規劃能力的AI助手。你的工作流程是:
1. **強制規劃優先**:在調用任何業務工具前,必須先調用`think_and_plan`工具進行思考
2. **循環執行**:規劃 → 執行 → 分析結果 → 重新規劃,直到任務完成
3. **錯誤處理**:工具調用失敗時,必須重新規劃而不是盲目重試
4. **并行限制**:除非明確確認無依賴關系,否則禁止并行調用工具
記住:你不是一個急性子的實習生,而是一個深思熟慮的專業助手。
業務層補充
針對具體場景,我會添加更詳細的指導,舉個栗子:
# 數據分析場景特殊規則
- 處理數據前,必須先用數據概覽工具檢查格式和質量
- 發現數據問題時,要先清理再分析,不要帶病作業
- 生成圖表前,要確認數據的統計特征,避免誤導性可視化
Step 4: 防循環與錯誤處理——給Agent裝上"安全帶"
在實際項目中,我遇到過Agent陷入死循環的情況。比如:
- 調用工具A失敗
- 重新規劃,還是調用工具A
- 再次失敗,再次規劃...
- 無限循環
解決方案:雙層防護
硬性限制(寫進代碼):
# 偽代碼
max_retries = 3
max_total_calls = 20
timeout = 300 # 5分鐘
if consecutive_failures >= max_retries:
return "連續失敗次數過多,請檢查工具配置或聯系技術支持"
if total_calls >= max_total_calls:
return "調用次數超限,任務可能過于復雜,建議分解后重試"
軟性引導(寫進 Prompt):
# 在think_and_plan工具中添加
"failure_analysis": {
"type": "string",
"description": "如果上一步失敗,分析失敗原因并調整策略。連續失敗3次后必須尋求人工幫助,要求補充必要的上下文信息。"
}
四、爭議與思考:工具 vs 純推理
一個常見的問題是:我們能否用一個更強的推理模型,來代替think工具呢?
Anthropic的結論是:不能,至少目前不行。
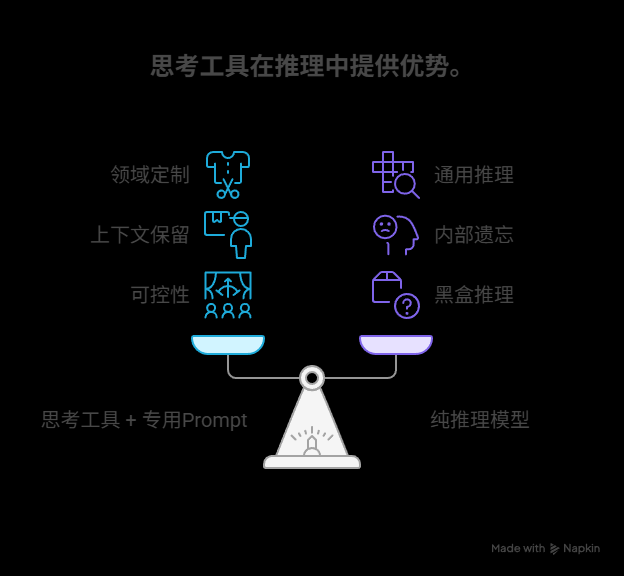
在Claude 3.7上的實驗表明,“思考工具 + 專用Prompt” 的效果,顯著優于單純依賴模型自身推理的模式。
可能的原因:
- 領域定制:工具的Prompt可以針對特定領域(如航空、金融)的思考模式進行深度定制和優化,這是通用推理模式無法比擬的。
- 上下文保留:工具調用會將每一次的思考過程(規劃、反思)完整地保留在上下文中,形成一個清晰的邏輯鏈。而純推理模型為了節省token,可能會在內部“遺忘”或刪減中間的思考步驟。
- 可控性:工具調用是可控的、可追蹤的,而模型內部推理對我們來說是黑盒。
這讓我想起了軟件工程中的一個原則:顯式優于隱式。把思考過程顯式化,總是比依賴黑盒推理更可靠。
結語:從"碼農"到"AI架構師"
寫到這里,我想分享一個感悟。
把“規劃”顯式化這件事很反直覺。畢竟人類的思維是隱性的、靈活的。但 Agent 是個偏執行型的東西,如果不給它立規矩,它就永遠是個胡亂點技能的萌新。
畢竟“聰明”這件事,是在限制中長出來的。
我們未來的能力,也許不在于 Prompt 寫得多 fancy,
而在于我們能不能把模糊的問題,變成清晰的鏈路;
把復雜的世界,變成模型可理解的認知場。
?? 如果你也在做 Agent 系統設計,歡迎一起討論。
我們都在試錯路上,別讓自己一個人踩坑。
參考資料:
[1]https://github.com/openai/openai-cookbook/blob/main/examples/gpt4-1_prompting_guide.ipynb
[2]https://www.anthropic.com/engineering/claude-think-tool
[3]https://github.com/modelcontextprotocol/servers/tree/main/src/sequentialthinking
[4]https://www.anthropic.com/engineering/building-effective-agents

 浙公網安備 33010602011771號
浙公網安備 33010602011771號