RAG檢索策略深度解析:從BM25到Embedding、Reranker,如何為L(zhǎng)LM選對(duì)“導(dǎo)航系統(tǒng)”?
大家好!今天我們來(lái)聊聊一個(gè)熱門技術(shù)——RAG(檢索增強(qiáng)生成)中至關(guān)重要的“檢索”環(huán)節(jié)。如果你正在探索如何讓你的大型語(yǔ)言模型(LLM)更智能、回答更靠譜,那這篇文章你可千萬(wàn)別錯(cuò)過(guò)。
我們會(huì)一起深入了解幾種主流的檢索策略:從經(jīng)典的BM25,到現(xiàn)代的各類Embedding技術(shù)(稀疏、密集、多向量),再到提升最終效果的Reranker。目標(biāo)是幫你理解它們的工作原理和適用場(chǎng)景,為你構(gòu)建高效RAG系統(tǒng)提供清晰的指引。
正文:
一、RAG與檢索:為什么它是LLM的“神隊(duì)友”???
想象一下,大型語(yǔ)言模型(LLM)就像一個(gè)知識(shí)淵博但有時(shí)會(huì)“腦補(bǔ)”過(guò)度的學(xué)霸。RAG(Retrieval Augmented Generation)技術(shù),就是給這位學(xué)霸配備了一個(gè)超級(jí)智能的“圖書館檢索員”和“事實(shí)核查員”。
-
RAG的工作流程可以簡(jiǎn)化為:當(dāng)用戶提出問(wèn)題時(shí),系統(tǒng)首先驅(qū)動(dòng)“檢索員”去龐大的知識(shí)庫(kù)(比如你的業(yè)務(wù)文檔、專業(yè)數(shù)據(jù)庫(kù)等)中找到最相關(guān)的幾段信息,然后把這些信息連同原始問(wèn)題一起交給LLM這位“學(xué)霸”,讓它基于這些靠譜的材料來(lái)組織和生成答案。
-
檢索的重要性:顯而易見(jiàn),如果“檢索員”找來(lái)的資料驢唇不對(duì)馬嘴,那么即便是最頂尖的LLM也難以給出準(zhǔn)確、有深度的回答——正所謂“Garbage In, Garbage Out”。因此,一個(gè)高效且精準(zhǔn)的檢索模塊是RAG系統(tǒng)成功的基石。
下圖清晰地展示了RAG的基本工作流程:

友情提示: 接下來(lái)的內(nèi)容會(huì)涉及一些技術(shù)概念,我會(huì)盡量用通俗易懂的方式來(lái)解釋,希望能幫助大家輕松理解。
二、經(jīng)典永流傳:BM25——關(guān)鍵詞匹配的“老兵” ??
BM25(Best Matching 25)是一種久經(jīng)考驗(yàn)的排序算法,廣泛應(yīng)用于傳統(tǒng)搜索引擎中。它基于“詞袋模型”,核心思想是通過(guò)關(guān)鍵詞匹配程度來(lái)衡量文檔與查詢的相關(guān)性。
-
核心原理概覽:
-
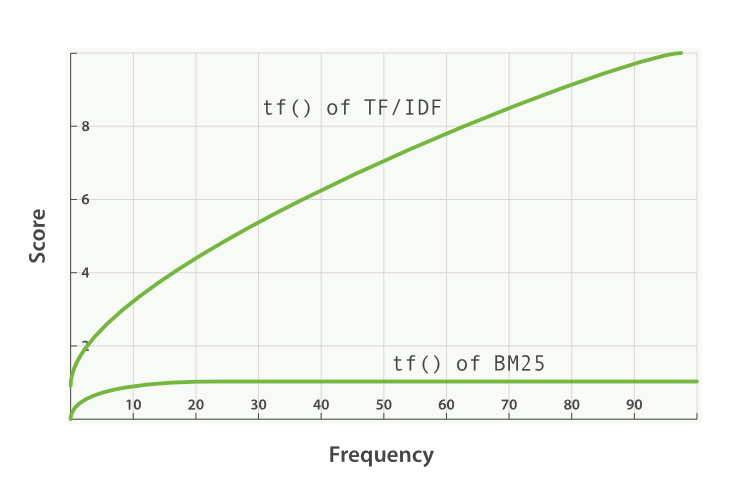
詞頻 (Term Frequency, TF):一個(gè)詞在文檔中出現(xiàn)的次數(shù)越多,通常意味著這篇文檔與該詞相關(guān)性越高。但BM25會(huì)進(jìn)行“飽和度”處理,避免某些超高頻詞過(guò)度影響結(jié)果。可以想象成,一篇文章提到“蘋果”10次,比提到1次更相關(guān),但提到100次和提到50次,在“蘋果”這個(gè)主題上的相關(guān)性增加可能就沒(méi)那么顯著了。
-
逆文檔頻率 (Inverse Document Frequency, IDF):如果一個(gè)詞在整個(gè)文檔集合中都很罕見(jiàn)(只在少數(shù)文檔中出現(xiàn)),那么它對(duì)于區(qū)分文檔主題就更重要,IDF值就高。比如“量子糾纏”這個(gè)詞遠(yuǎn)比“的”、“是”這類詞更能鎖定專業(yè)文檔。
-
文檔長(zhǎng)度歸一化:用于平衡長(zhǎng)短文檔的得分,避免長(zhǎng)文檔僅僅因?yàn)閮?nèi)容多而獲得不公平的高分。
-
工作方式舉例:當(dāng)用戶搜索“深度學(xué)習(xí)入門教程”時(shí),BM25會(huì)傾向于找出那些更頻繁出現(xiàn)“深度學(xué)習(xí)”、“入門”、“教程”這些詞,且這些詞相對(duì)不那么常見(jiàn)的文檔。
其核心打分邏輯可以用以下公式框架來(lái)表示:
Score(Q, D) = Σ [ IDF(q_i) * ( (k1 + 1) * tf(q_i, D) ) / ( k1 * ( (1 ``- b) + b * (|D| / avgdl) ) + tf(q_i, D) ) ]
這里:
-
Q代表用戶的查詢(Query),由一系列查詢?cè)~q_i組成。 -
D代表被評(píng)分的文檔(Document)。 -
IDF(q_i)是查詢?cè)~q_i的逆文檔頻率,衡量詞的稀有度或重要性。 -
tf(q_i, D)是查詢?cè)~q_i在文檔D中出現(xiàn)的頻率。 -
|D|是文檔D的長(zhǎng)度,而avgdl是整個(gè)文檔集合的平均長(zhǎng)度,它們用于文檔長(zhǎng)度歸一化。 -
k1和b是BM25算法的兩個(gè)可調(diào)參數(shù),通常k1取值在1.2到2.0之間,b通常為0.75。k1控制詞頻飽和度(即詞頻增加對(duì)得分的邊際效應(yīng)),b控制文檔長(zhǎng)度對(duì)得分的影響程度。
這個(gè)公式雖然看起來(lái)有些復(fù)雜,但它精妙地平衡了詞頻、詞的稀有度以及文檔長(zhǎng)度這幾個(gè)核心因素,是BM25算法效果出色的關(guān)鍵。
-
優(yōu)點(diǎn):
-
高效性:算法相對(duì)簡(jiǎn)單,計(jì)算速度快,易于實(shí)現(xiàn)和部署。
-
無(wú)需深度學(xué)習(xí)訓(xùn)練:其核心算法基于統(tǒng)計(jì),不需要大規(guī)模標(biāo)注數(shù)據(jù)進(jìn)行神經(jīng)網(wǎng)絡(luò)模型訓(xùn)練(參數(shù)調(diào)優(yōu)除外)。
-
可解釋性強(qiáng):得分基于明確的詞頻和文檔頻率,容易理解為何某個(gè)文檔被認(rèn)為相關(guān)。
-
精確匹配效果好:對(duì)于關(guān)鍵詞明確的查詢,BM25往往能提供非常好的結(jié)果。
-
局限性:
-
語(yǔ)義鴻溝:嚴(yán)重依賴字面匹配。例如,用戶搜索“AI最佳實(shí)踐”,它可能難以找到包含“人工智能優(yōu)秀范例”的文檔,因?yàn)樗焕斫狻癆I”與“人工智能”、“最佳實(shí)踐”與“優(yōu)秀范例”之間的語(yǔ)義相似性。就像一個(gè)只會(huì)按字查字典的助手,不懂同義詞替換。
-
忽略語(yǔ)序:作為詞袋模型,它不考慮詞語(yǔ)的順序和句子結(jié)構(gòu)。對(duì)它而言,“北京到上海的機(jī)票”和“上海到北京的機(jī)票”可能看起來(lái)差不多。
BM25、全文搜索與倒排索引:它們是如何協(xié)同工作的?
這三者是構(gòu)建搜索系統(tǒng)的關(guān)鍵組件:
-
全文搜索 (Full-Text Search):這是我們希望達(dá)成的目標(biāo)——在大量文本中找到包含特定信息的文檔。
-
倒排索引 (Inverted Index):這是實(shí)現(xiàn)高效全文搜索的數(shù)據(jù)結(jié)構(gòu)基礎(chǔ)。它像一本書末尾的詳細(xì)“關(guān)鍵詞索引”,記錄了每個(gè)詞出現(xiàn)在哪些文檔中以及相關(guān)位置信息。當(dāng)用戶查詢時(shí),系統(tǒng)可以通過(guò)倒排索引快速定位到包含查詢?cè)~的候選文檔。
-
BM25:在通過(guò)倒排索引找到候選文檔后,BM25算法登場(chǎng),為每個(gè)文檔計(jì)算一個(gè)相關(guān)性得分,然后按分排序,將最相關(guān)的結(jié)果呈現(xiàn)給用戶。

把它們比作在圖書館找特定主題的書籍:
-
你告訴圖書管理員你要找關(guān)于“天體物理學(xué)”的書(用戶查詢)。
-
管理員查閱一個(gè)總卡片索引(倒排索引),迅速告訴你哪些書架(文檔ID)上有包含“天體物理學(xué)”這個(gè)詞的書。
-
你走到這些書架,快速翻閱這些書(BM25評(píng)分過(guò)程),根據(jù)目錄、摘要和提及“天體物理學(xué)”的頻繁程度及重要性,判斷哪幾本最符合你的需求,并把它們按相關(guān)性高低排好。
為了更清晰地理解它們之間的協(xié)作,可以參考下圖:

三、Embedding家族:讓機(jī)器理解文本的“言外之意” ??

為了克服BM25等傳統(tǒng)方法在語(yǔ)義理解上的不足,基于Embedding(嵌入)的檢索策略應(yīng)運(yùn)而生。其核心思想是將文本(無(wú)論是詞語(yǔ)、句子還是整個(gè)文檔)映射到一個(gè)低維、稠密的向量空間中,使得語(yǔ)義相近的文本在向量空間中的距離也相近。
想象一下,每段文字都被翻譯成了一串獨(dú)特的“數(shù)字密碼”(向量)。語(yǔ)義相似的文字,它們的“數(shù)字密碼”在某個(gè)多維空間里就會(huì)靠得很近。這個(gè)概念可以用下圖來(lái)形象理解:

1. 稀疏嵌入 (Sparse Embedding):關(guān)鍵詞與語(yǔ)義的初步融合
- 特點(diǎn):生成的向量維度通常很高(與詞匯表大小相關(guān)),但大部分元素為零,非零元素表示對(duì)應(yīng)詞語(yǔ)的權(quán)重。可以看作是BM25等基于詞頻方法的延伸和智能化,試圖在關(guān)鍵詞匹配的基礎(chǔ)上增加一些語(yǔ)義理解。
下圖直觀地對(duì)比了稀疏嵌入和密集嵌入的主要視覺(jué)特征:

-
代表模型:SPLADE (SParse Lexical AnD Expansion model)
-
工作機(jī)制:SPLADE利用Transformer模型(如BERT)為查詢和文檔中的詞語(yǔ)分配置信度權(quán)重。它不僅考慮文本中實(shí)際出現(xiàn)的詞,還能通過(guò)模型的學(xué)習(xí)能力,“擴(kuò)展”出與原文內(nèi)容語(yǔ)義相關(guān)但未直接出現(xiàn)的詞,并賦予它們相應(yīng)的權(quán)重。好比一個(gè)聰明的助手,你提到“貓”,它不僅關(guān)注“貓”本身,還會(huì)聯(lián)想到“喵”、“鏟屎官”等相關(guān)概念。
這個(gè)過(guò)程大致可以用以下偽代碼思路來(lái)理解:
function get_splade_vector(text, bert_model, vocabulary):
// 1. 將輸入文本分詞并通過(guò)BERT獲取上下文相關(guān)的詞元嵌入
tokens = bert_model.tokenize(text)
contextual_token_embeddings = bert_model.get_contextualized_embeddings(tokens) // 通常是BERT最后一層的輸出
// 2. 初始化一個(gè)與詞匯表等長(zhǎng)的零向量,用于存儲(chǔ)每個(gè)詞的最終權(quán)重
vocab_scores = initialize_vector_with_zeros(size=len(vocabulary))
// 3. 對(duì)每個(gè)文本中的詞元,估算其對(duì)詞匯表中所有詞的貢獻(xiàn)
for each token_embedding in contextual_token_embeddings:
for each word_index in range(len(vocabulary)):
// 實(shí)際SPLADE模型中,這一步會(huì)通過(guò)一個(gè)小型神經(jīng)網(wǎng)絡(luò)(如MLP)和與詞匯表詞嵌入的點(diǎn)積來(lái)計(jì)算貢獻(xiàn)值
// 這里簡(jiǎn)化表示其核心思想:基于當(dāng)前token的上下文信息,判斷它能激活詞匯表中哪些詞
contribution_score = calculate_semantic_contribution(token_embedding, vocabulary_word_embedding[word_index])
// 使用ReLU等激活函數(shù)確保權(quán)重非負(fù),并累加到對(duì)應(yīng)詞匯的得分上
vocab_scores[word_index] += relu(contribution_score)
// 4. (可選)對(duì)累加后的分?jǐn)?shù)進(jìn)行對(duì)數(shù)飽和等處理,形成最終的稀疏向量
final_sparse_vector = apply_log_saturation(vocab_scores)
return final_sparse_vector // 這個(gè)向量中大部分值為0,非零值代表了重要詞及其權(quán)重
上述偽代碼描繪了SPLADE的核心思想:它不是簡(jiǎn)單地統(tǒng)計(jì)詞頻,而是利用深度學(xué)習(xí)模型的能力,為整個(gè)詞匯表中的詞(包括那些在原文本中未直接出現(xiàn)的、但語(yǔ)義相關(guān)的詞)智能地賦予權(quán)重,從而實(shí)現(xiàn)“語(yǔ)義擴(kuò)展”并生成一個(gè)信息量更豐富的稀疏向量。
-
訓(xùn)練方式:通常采用對(duì)比學(xué)習(xí)(讓模型學(xué)習(xí)區(qū)分相關(guān)和不相關(guān)的文檔對(duì))和正則化方法(鼓勵(lì)模型生成稀疏的向量,即盡量減少非零元素的數(shù)量,以提高效率和可解釋性)。
-
優(yōu)勢(shì):相比傳統(tǒng)稀疏方法,SPLADE能更好地捕捉詞匯間的細(xì)微聯(lián)系,實(shí)現(xiàn)一定程度的語(yǔ)義擴(kuò)展,同時(shí)保留了稀疏向量的匹配效率和一定的可解釋性。
-
挑戰(zhàn):雖然有所改進(jìn),但其語(yǔ)義理解的深度和廣度仍可能不及下面要介紹的密集嵌入。
2. 密集嵌入 (Dense Embedding):深度理解語(yǔ)義的“主力軍” ??
-
特點(diǎn):將文本映射到相對(duì)低維(通常幾百到幾千維)的向量空間,向量中的每個(gè)維度都參與編碼文本的整體語(yǔ)義信息,幾乎沒(méi)有零值。這些維度不像稀疏嵌入那樣直接對(duì)應(yīng)具體詞匯,而是共同表達(dá)了文本的抽象語(yǔ)義特征。
-
核心優(yōu)勢(shì):能夠捕捉深層次的語(yǔ)義相似性。即使查詢和文檔使用了完全不同的詞語(yǔ),只要它們?cè)诤x上相近,密集嵌入模型也能識(shí)別出來(lái)。
-
常見(jiàn)代表模型:
-
Sentence-BERT (SBERT):專門用于生成句子級(jí)別語(yǔ)義向量的模型。它通過(guò)對(duì)BERT等預(yù)訓(xùn)練模型進(jìn)行特殊設(shè)計(jì)(例如,使用孿生網(wǎng)絡(luò)結(jié)構(gòu)同時(shí)處理兩個(gè)句子)和微調(diào),使得模型可以直接輸出高質(zhì)量的句子嵌入,非常適合用于計(jì)算句子間的語(yǔ)義相似度。
-
應(yīng)用方式:輸入一個(gè)句子,SBERT輸出一個(gè)固定大小的向量。比較兩個(gè)句子的語(yǔ)義相似度,就可以通過(guò)計(jì)算它們對(duì)應(yīng)向量的余弦相似度等指標(biāo)來(lái)實(shí)現(xiàn)。
SBERT這種雙塔(Siamese Network)架構(gòu)的工作方式可以用下圖簡(jiǎn)化表示:

其中,余弦相似度(Cosine Similarity)是一種常用的衡量向量間方向一致性的方法,其計(jì)算公式如下:
CosineSimilarity(A, B) = (A · B) / (||A|| * ||B||)
這里:
-
A和B分別是兩個(gè)文本(如句子或文檔)的密集向量表示。 -
A · B表示向量A和向量B的點(diǎn)積。 -
||A||和||B||分別表示向量A和向量B的L2范數(shù)(即向量的長(zhǎng)度)。
余弦相似度的取值范圍在-1到1之間,值越接近1,表示兩個(gè)向量(及其代表的文本語(yǔ)義)越相似。
-
jina-embeddings-v3:一款功能強(qiáng)大的多語(yǔ)言、多任務(wù)文本嵌入模型。
-
突出特性:支持超過(guò)100種語(yǔ)言;能夠處理長(zhǎng)達(dá)8192個(gè)token的長(zhǎng)文本序列(得益于如RoPE旋轉(zhuǎn)位置編碼等技術(shù),讓模型能“記住”更長(zhǎng)的上下文);通過(guò)LoRA Adapters支持針對(duì)不同下游任務(wù)(如檢索、分類、聚類)優(yōu)化嵌入表示,就像給模型換上不同功能的“插件”;支持Matryoshka Embeddings(套娃嵌入),允許用戶根據(jù)需求截?cái)嗲度刖S度以平衡性能和資源消耗,比如你只需要一個(gè)大致方向,就可以用短一點(diǎn)的向量省點(diǎn)力氣。
-
優(yōu)勢(shì):強(qiáng)大的語(yǔ)義表征能力,尤其適合需要理解復(fù)雜語(yǔ)義和上下文的場(chǎng)景。
-
潛在不足:對(duì)于某些關(guān)鍵詞匹配要求極高的場(chǎng)景,其精確度有時(shí)可能不如BM25或稀疏嵌入直接。有時(shí)可能會(huì)因?yàn)檫^(guò)于關(guān)注“大意”而忽略一些關(guān)鍵詞的硬性要求。
3. 多向量嵌入 (Multi-vector Embeddings):捕捉長(zhǎng)文檔中的“微光” ?
-
解決痛點(diǎn):對(duì)于包含多個(gè)主題或很多細(xì)節(jié)的長(zhǎng)文檔,將其壓縮成單一的密集向量有時(shí)會(huì)“平均掉”或丟失局部的重要信息。如果用戶的查詢恰好與長(zhǎng)文檔中的某一小片段高度相關(guān),單向量表示可能無(wú)法有效捕捉這種細(xì)粒度的匹配。這就像試圖用一句話總結(jié)一部長(zhǎng)篇小說(shuō),很多精彩細(xì)節(jié)必然會(huì)丟失。
-
代表模型:ColBERT (Contextualized Late Interaction over BERT)
-
核心思想:“延遲交互” (Late Interaction) 與 “細(xì)粒度相似度建模”
-
工作流程:ColBERT不將查詢和文檔立即壓縮成單一向量。而是先獨(dú)立地為查詢和文檔中的每個(gè)詞元(token)都生成一個(gè)上下文相關(guān)的向量(形成一個(gè)向量序列)。在檢索時(shí),它計(jì)算查詢中每個(gè)詞元向量與文檔中所有詞元向量的相似度,然后通過(guò)一種MaxSim操作(對(duì)每個(gè)查詢?cè)~元,取其與文檔所有詞元的最大相似度,再將這些最大相似度累加)來(lái)得到最終的相關(guān)性得分。
-
效果:這種方式允許模型在更細(xì)的粒度上進(jìn)行匹配,更好地捕捉查詢與文檔局部片段之間的精確關(guān)聯(lián)。就像用放大鏡仔細(xì)比對(duì)兩篇文章中的每個(gè)段落甚至每個(gè)句子,而不是只看它們的整體摘要。
其核心的MaxSim(Maximum Similarity)聚合得分的計(jì)算邏輯可以用以下偽代碼來(lái)表示:
function calculate_colbert_score(query_token_embeddings, document_token_embeddings):
total_max_similarity_score = 0
// 對(duì)查詢中的每一個(gè)詞元嵌入
for q_embedding in query_token_embeddings:
max_similarity_for_this_q_token = 0
// 遍歷文檔中的每一個(gè)詞元嵌入,找到與當(dāng)前查詢?cè)~元最相似的那個(gè)
for d_embedding in document_token_embeddings:
similarity = calculate_cosine_similarity(q_embedding, d_embedding) // 通常用余弦相似度
if similarity > max_similarity_for_this_q_token:
max_similarity_for_this_q_token = similarity
// 將這個(gè)最大相似度值累加到總分中
total_max_similarity_score += max_similarity_for_this_q_token
return total_max_similarity_score
簡(jiǎn)單來(lái)說(shuō),就是查詢中的每個(gè)“詞塊”都在文檔的所有“詞塊”中尋找自己的“最佳拍檔”(最相似的那個(gè)),然后把這些“最佳拍檔”的相似度得分加起來(lái),作為查詢和文檔的最終相關(guān)性分?jǐn)?shù)。
ColBERT的這種細(xì)粒度交互和MaxSim聚合過(guò)程可以用下圖示意:

-
優(yōu)勢(shì):對(duì)于長(zhǎng)文檔檢索和需要精確定位信息片段的場(chǎng)景非常有效。
-
資源考量:相比單向量方法,存儲(chǔ)和計(jì)算開(kāi)銷通常更大。
4. bge-m3:追求全面的“多面手” ??
-
模型特點(diǎn):由BAAI(北京智源人工智能研究院)開(kāi)發(fā),是一個(gè)集多語(yǔ)言性、多粒度性、多功能性于一體的文本嵌入模型。
-
核心能力:能夠同時(shí)支持并輸出稀疏檢索(類似BM25的詞權(quán)重)、稠密檢索(高質(zhì)量的語(yǔ)義向量)和多向量檢索(類似ColBERT的細(xì)粒度匹配)所需的不同類型的嵌入。它通過(guò)一種“自知識(shí)蒸餾”(Self-Knowledge Distillation, SKD)框架進(jìn)行訓(xùn)練,使得不同檢索方式的優(yōu)勢(shì)能夠相互促進(jìn),像一個(gè)博采眾長(zhǎng)的學(xué)生,從不同老師那里學(xué)到最好的方法。
-
價(jià)值:為開(kāi)發(fā)者提供了在一個(gè)模型中嘗試和組合多種先進(jìn)檢索策略的便利性,非常適合需要靈活應(yīng)對(duì)不同檢索需求的復(fù)雜RAG場(chǎng)景。
四、混合檢索 (Hybrid Retrieval):集各家之長(zhǎng),效果更上一層樓 ??
既然不同的檢索策略各有千秋(例如,BM25擅長(zhǎng)關(guān)鍵詞精確匹配,Embedding擅長(zhǎng)語(yǔ)義理解),那么將它們結(jié)合起來(lái),是不是能達(dá)到“1+1>2”的效果呢?答案是肯定的,這就是混合檢索的核心思想。
- 常見(jiàn)做法:同時(shí)使用BM25(或其他稀疏檢索方法)和一種或多種Embedding檢索方法,然后將它們各自的檢索結(jié)果進(jìn)行融合排序。
下圖展示了一個(gè)典型的混合檢索流程BGE-M3的效果:

-
融合策略舉例:
-
RRF (Reciprocal Rank Fusion, 倒數(shù)排序融合):一種簡(jiǎn)單但魯棒的融合方法。它不關(guān)心不同檢索系統(tǒng)輸出的原始得分,只關(guān)心每個(gè)文檔在各自結(jié)果列表中的排名。一個(gè)文檔
doc的RRF得分計(jì)算如下:
Score_RRF(doc) = Σ_{s ∈ Systems} (1 / (k + rank_s(doc)))
其中:
-
Systems是所有參與融合的檢索系統(tǒng)的集合。 -
rank_s(doc)是文檔doc在檢索系統(tǒng)s給出的結(jié)果列表中的排名(例如,第一名是1,第二名是2)。 -
k是一個(gè)小常數(shù)(例如,常設(shè)置為60),用于平滑得分,避免排名靠后的文檔得分過(guò)小或排名第一的文檔得分占比過(guò)高。
這種方法的好處是不需要對(duì)不同系統(tǒng)的得分進(jìn)行歸一化,直接利用排名信息進(jìn)行融合。
-
加權(quán)融合 (Weighted Fusion):為不同檢索系統(tǒng)的得分分配不同的權(quán)重(例如,BM25得分權(quán)重0.3,Embedding得分權(quán)重0.7),然后加權(quán)求和得到最終得分。權(quán)重的設(shè)定可以基于經(jīng)驗(yàn),也可以通過(guò)實(shí)驗(yàn)調(diào)優(yōu),甚至用機(jī)器學(xué)習(xí)方法來(lái)學(xué)習(xí)。
-
優(yōu)勢(shì):能夠有效結(jié)合關(guān)鍵詞匹配的準(zhǔn)確性和語(yǔ)義匹配的召回能力,通常能獲得比單一檢索策略更好、更穩(wěn)定的結(jié)果,尤其在處理多樣化查詢(有的偏關(guān)鍵詞,有的偏語(yǔ)義)時(shí)表現(xiàn)更佳。
五、Reranker (重排序器):檢索結(jié)果的“精煉師” ??
經(jīng)過(guò)上述一種或多種檢索策略的“粗篩”(召回階段),我們通常會(huì)得到一個(gè)包含較多候選文檔的列表(比如幾百個(gè))。為了進(jìn)一步提升最終喂給LLM的文檔質(zhì)量,Reranker(重排序器)應(yīng)運(yùn)而生。它相當(dāng)于一位“精煉師”或“質(zhì)量品鑒官”,對(duì)初步召回的結(jié)果進(jìn)行更細(xì)致、更精準(zhǔn)的二次排序。
-
與召回階段檢索的區(qū)別:
-
召回模型(如BM25, SBERT等雙塔模型Bi-Encoder):通常獨(dú)立編碼查詢和文檔,然后計(jì)算它們向量表示的相似度。這種方式計(jì)算快,適合從海量數(shù)據(jù)中快速篩選。它們像是兩位考官分別給一篇作文打分,然后取平均。
-
重排序模型(通常是Cross-Encoder交叉編碼器模型):會(huì)將查詢(query)和每個(gè)候選文檔(document)拼接起來(lái),作為一個(gè)整體輸入到一個(gè)更強(qiáng)大的深度模型(如BERT、RoBERTa等)中。模型內(nèi)部通過(guò)復(fù)雜的注意力機(jī)制,讓查詢和文檔的每個(gè)部分都能充分交互,從而更深入地理解兩者之間的細(xì)微語(yǔ)義關(guān)系和相關(guān)性。這更像是一位考官拿到作文題目和作文后,逐字逐句地進(jìn)行比對(duì)和深度分析。
下圖清晰地對(duì)比了Bi-Encoder和Cross-Encoder在架構(gòu)上的核心差異:

-
優(yōu)勢(shì):由于進(jìn)行了更充分的交互和更深層次的語(yǔ)義分析,Reranker通常能達(dá)到比召回模型更高的排序精度。
-
代價(jià):計(jì)算成本遠(yuǎn)高于召回模型。因?yàn)樗枰獙?duì)“查詢-每個(gè)候選文檔”對(duì)都進(jìn)行一次復(fù)雜的模型推理。因此,Reranker一般只用于對(duì)召回階段篩選出的少量(例如前幾十或幾百個(gè))最有希望的文檔進(jìn)行精排。
-
常見(jiàn)模型:包括Cohere Rerank, BAAI開(kāi)發(fā)的bge-reranker系列, Jina AI的Reranker等。這些模型通常針對(duì)重排序任務(wù)進(jìn)行了專門優(yōu)化。
六、總結(jié)與實(shí)踐建議 ??
回顧一下我們今天探討的RAG檢索技術(shù):
-
BM25:關(guān)鍵詞檢索的基石,簡(jiǎn)單高效,精確匹配場(chǎng)景下的可靠選擇。
-
Embedding 技術(shù):開(kāi)啟語(yǔ)義理解大門。
-
Sparse Embedding (如SPLADE):在關(guān)鍵詞基礎(chǔ)上融入初步語(yǔ)義,兼顧效率與可解釋性。
-
Dense Embedding (如SBERT, jina-embeddings-v3):強(qiáng)大的語(yǔ)義理解能力,應(yīng)對(duì)復(fù)雜查詢的利器。
-
Multi-vector Embedding (如ColBERT):精細(xì)捕捉長(zhǎng)文檔中的局部信息,避免重要細(xì)節(jié)被稀釋。
-
bge-m3:提供稀疏、密集、多向量一體化解決方案的“多面手”,方便嘗試不同策略。
-
Hybrid Retrieval:融合多種檢索策略優(yōu)勢(shì),提升整體魯棒性和效果,是生產(chǎn)環(huán)境中的常見(jiàn)選擇。
-
Reranker:對(duì)初步結(jié)果進(jìn)行精細(xì)化重排,是提升最終輸入LLM質(zhì)量的關(guān)鍵一環(huán),尤其在高精度要求的場(chǎng)景下。
在實(shí)際項(xiàng)目中如何選擇和組合這些技術(shù)呢?這里有一些建議:
- 起步階段/輕量級(jí)應(yīng)用:
- 可以從 BM25 + 一個(gè)高質(zhì)量的Dense Embedding模型 (如Sentence-BERT的某個(gè)優(yōu)秀變體,或jina-embeddings-v3的基礎(chǔ)版) 開(kāi)始。這種組合能兼顧關(guān)鍵詞匹配和基本的語(yǔ)義理解,投入產(chǎn)出比較高。
- 標(biāo)準(zhǔn)生產(chǎn)環(huán)境/追求更佳效果:
- 強(qiáng)烈推薦 Hybrid Retrieval。例如,BM25結(jié)合一個(gè)強(qiáng)大的Dense Embedding模型(如jina-embeddings-v3的高級(jí)版本或bge-m3),并使用RRF或加權(quán)融合策略。這能更好地應(yīng)對(duì)多樣化的用戶查詢。
- 對(duì)精度要求極高/計(jì)算資源相對(duì)充足:
- 在Hybrid Retrieval的基礎(chǔ)上,引入 Reranker。例如,使用BM25+Dense Embedding進(jìn)行初步召回(如Top 50-200個(gè)結(jié)果),然后用一個(gè)高效的Reranker模型(如bge-reranker)對(duì)這些結(jié)果進(jìn)行精排(如選出Top 3-10個(gè))。
- 特定領(lǐng)域/重視可解釋性:
- 如果需要較好的可解釋性(了解哪些詞或因素對(duì)匹配起到了關(guān)鍵作用),可以考慮 SPLADE 這樣的稀疏語(yǔ)義檢索方法。如果領(lǐng)域?qū)I(yè)性強(qiáng),可能還需要結(jié)合領(lǐng)域詞典或?qū)iT訓(xùn)練的Reranker。
最重要的原則是:沒(méi)有一勞永逸的“最佳”方案,只有最適合當(dāng)前業(yè)務(wù)需求、數(shù)據(jù)特性、資源限制和維護(hù)能力的組合。
建議從小處著手,逐步迭代,通過(guò)實(shí)驗(yàn)來(lái)驗(yàn)證不同策略組合在你的具體場(chǎng)景下的表現(xiàn)。多做AB測(cè)試,用數(shù)據(jù)說(shuō)話。
交流與探討:
希望這篇文章能幫助你對(duì)RAG中的檢索策略有一個(gè)更全面的認(rèn)識(shí)!技術(shù)的探索永無(wú)止境,RAG領(lǐng)域也在飛速發(fā)展。
-
你在RAG項(xiàng)目中嘗試過(guò)哪些檢索方法?在你的實(shí)踐中,遇到了哪些挑戰(zhàn),或者有哪些特別的經(jīng)驗(yàn)和“aha moment”?
-
對(duì)于文中的某項(xiàng)技術(shù)(例如ColBERT的多向量表示如何處理極端長(zhǎng)文檔,或者bge-m3的自知識(shí)蒸餾具體是如何工作的),你有什么特別想深入了解或討論的嗎?
-
你認(rèn)為未來(lái)RAG檢索技術(shù)會(huì)朝著哪些方向發(fā)展?(例如,更智能的端到端檢索模型?更低成本的Reranker?還是其他?)
歡迎在評(píng)論區(qū)留下你的想法和問(wèn)題,我們一起交流學(xué)習(xí),共同進(jìn)步!如果你覺(jué)得這篇文章對(duì)你有幫助,也請(qǐng)不吝點(diǎn)贊和轉(zhuǎn)發(fā),讓更多有需要的朋友看到。??

 浙公網(wǎng)安備 33010602011771號(hào)
浙公網(wǎng)安備 33010602011771號(hào)