
統計學習方法學習Day01
學習了統計學習方法的第一章
1.5正則化與交叉驗證
(1)正則化的目的是模型選擇的一個經典方法,正則化的是要使風險最小化的策略。正則化實在經驗風險上加上一個正則化項,正則化項主要是防止模型在訓練過程中出現過擬合的現象,一般正則項是由參數向量的L1,L2范式(注:L1是數據集中所有數據的絕對值的和/數據的個數,而L2是數據集中所有數據平方的和開根號/數據的個數)。
正則化為什么可以防止過擬合的數學解釋

在公式中存在經驗損失和正則化項,在選擇模型的過程中一般選擇經驗損失最小的,而要選擇最小的損失,我們需要對公式中的所有未知元素求偏導,是他們的偏導等于零從而來獲得他們中的極小值,在極小值中進行比較就可以取得最小值.
而在進行上述操作的過程中,我們便可以將其與KKT及非線性規劃最優解進行比較,發現正則化和帶條件的優化是一致的,從而發現正則化對于模型選擇的重要性。
(2)交叉驗證便是對模型的檢驗,在選擇好模型后,我們便需要對模型進行訓練,測試和驗證,這就需要我們將數據分為訓練集,測試集和驗證集,一般在數據充足的情況下,我們將依次將數據集分為90%,5%,5%給各個集。在驗證方法上我們也分為簡單驗證方法,s折驗證方法和留一驗證方法。
簡單驗證方法就是將數據集分為兩份,一份交給模型訓練,一份交給驗證
S折驗證方法就是,將數據集分為S分只留一份驗證,其余交給模型測試。如圖
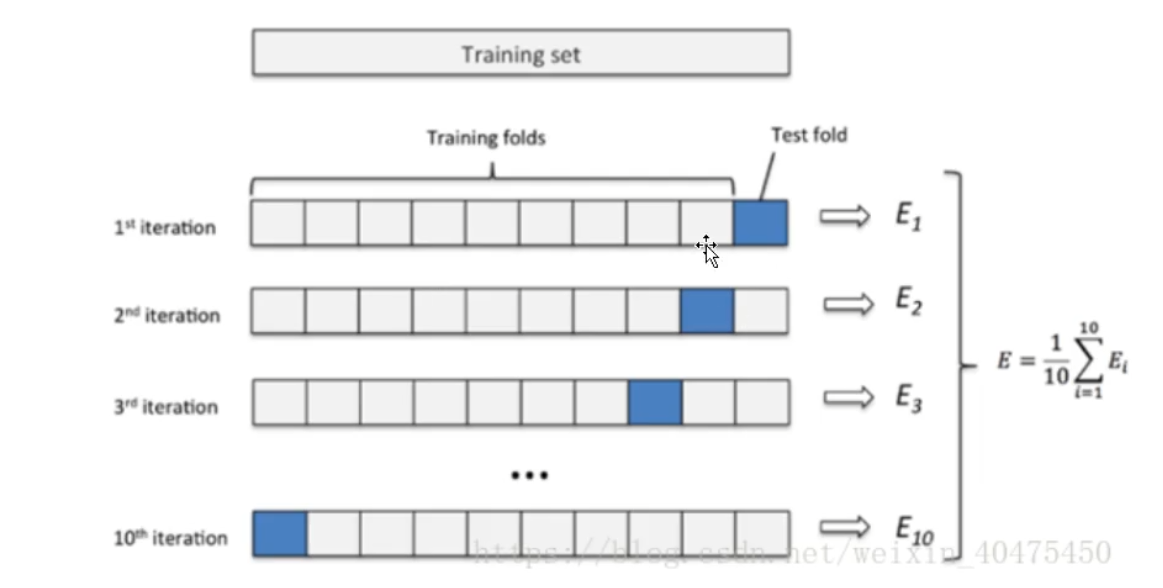
而留一是S折的特殊情況,每一份數據極為一折。

 浙公網安備 33010602011771號
浙公網安備 33010602011771號