
第四周學習
1. 通過網絡配置命令,讓主機可以上網。 ip, netmask, gateway, dns,主機名。相關命令總結,最終可以通過這些配置讓你的主機上網。
1.1 使用配置命令讓主機可上網
# 關閉現在使用的網卡,添加一塊新網卡進行配置
[root@rocky9-15 yum.repos.d]# ip link show ens160 #確認現在網卡已經關閉
2: ens160: <BROADCAST,MULTICAST> mtu 1500 qdisc mq state DOWN mode DEFAULT group default qlen 1000
link/ether 00:0c:29:a5:bf:17 brd ff:ff:ff:ff:ff:ff
altname enp3s0
# 新增一塊網卡
3: ens224: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000
link/ether 00:0c:29:a5:bf:21 brd ff:ff:ff:ff:ff:ff
[root@rocky9-15 ~]# ip addr add 10.0.0.111/24 dev ens224 #僅在當前終端生效
[root@rocky9-15 ~]# ip link set ens224 up #啟動網卡
[root@rocky9-15 ~]# ip addr show ens224 | grep "inet"#驗證網卡信息
inet 10.0.0.111/24 scope global ens224
[root@rocky9-15 ~]# ip route show | grep "default" #檢查是否有默認路由
default via 10.0.0.2 dev ens160 proto static metric 100
[root@rocky9-15 system-connections]# ping www.baidu.com #測試聯網
PING www.a.shifen.com (183.2.172.177) 56(84) 比特的數據。
64 比特,來自 183.2.172.177 (183.2.172.177): icmp_seq=1 ttl=128 時間=5.57 毫秒
64 比特,來自 183.2.172.177 (183.2.172.177): icmp_seq=2 ttl=128 時間=5.89 毫秒
64 比特,來自 183.2.172.177 (183.2.172.177): icmp_seq=3 ttl=128 時間=6.07 毫秒
#聯網成功
1.2 使用配置文件讓主機可上網
重啟系統,清除手動設置的ip
[root@rocky9-15 ~]# ip add show ens224#檢查是否存在
3: ens224: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000
link/ether 00:0c:29:a5:bf:21 brd ff:ff:ff:ff:ff:ff
altname enp19s0
下面為一個網卡文件的主要內容
[connection]
id=my-ens224 # 連接的自定義名稱
uuid=8d79afb0-1234-5678-90ab-cdef12345678 # 使用 `uuidgen` 生成的唯一標識符
type=ethernet # 連接類型為以太網
interface-name=ens224 # 綁定的物理網卡名稱
autoconnect=true # 開機自動激活連接
[ethernet]
mac-address=00:11:22:33:44:55 # (可選)指定物理網卡 MAC 地址
[ipv4]
method=manual # 靜態 IP 配置模式
addresses=10.0.0。111/24 # 靜態 IP 地址及掩碼
gateway=10.0.0.1 # 默認網關
dns=8.8.8.8,8.8.4.4 # DNS 服務器列表
dns-search=example.com # (可選)DNS 搜索域
[ipv6]
method=disabled # 禁用 IPv6
2. 解析/etc/sysconfig/network-scripts/ifcfg-eth0配置格式。
注:/etc/sysconfig/network-scripts/ifcfg-eth0 是centos7及更早版本使用的格式了,從后面的版本就改成了/etc/NetworkManager/system-connections文件夾下面了。但是centos8后面的版本仍然支持這個文件格式.
TYPE=Ethernet # 網卡類型為以太網
DEVICE=eth0 # 物理網卡名稱
BOOTPROTO=static # IP分配方式(static/dhcp/none)
IPADDR=192.168.1.100 # 靜態IP地址
NETMASK=255.255.255.0 # 子網掩碼
GATEWAY=192.168.1.1 # 默認網關
DNS1=8.8.8.8 # 主DNS服務器
DNS1=8.8.8.8 # 備DNS服務器
ONBOOT=yes # 開機自動激活
HWADDR=00:0C:29:13:5D:74 # (可選)綁定MAC地址
USERCTL=no # 禁止非root用戶控制
3. 基于配置文件或命令完成bond0配置
3.1、bond0 簡介
bond0 的定義與核心特性
?bond0? 是 Linux 系統中用于 ?多網卡綁定?(NIC bonding)的邏輯接口技術,通過將多個物理網卡聚合為一個虛擬接口,實現以下核心功能:
- ?冗余備份?:當某塊物理網卡故障時,自動切換到其他可用網卡,保障網絡高可用性
- ?帶寬擴容?:通過多網卡并行傳輸數據,提升整體吞吐量(取決于綁定模式)
- ?負載均衡?:將網絡流量分散到不同物理網卡,避免單點性能瓶頸
bond0 的工作模式
bond0 的實際行為由 ?綁定模式?(mode)決定,常見模式包括:
- ?mode=0(balance-rr)?
輪詢(Round-Robin)策略,數據包依次通過各物理網卡發送,最大化帶寬利用率,適合負載均衡場景 - ?mode=1(active-backup)?
主備模式,僅主網卡處于活動狀態,備份網卡在主網卡故障時接管,適合高可靠性需求 - ?其他模式?
如 mode=4(802.3ad,動態鏈路聚合)需交換機支持 LACP 協議
bond0 的典型應用場景
- ?服務器高可用?
數據庫、文件服務器等需持續在線服務,通過 bond0 避免單網卡故障導致服務中斷 - ?網絡帶寬優化?
視頻流、大規模數據傳輸場景中,使用 mode=0 或 mode=4 提升吞吐性能 - ?虛擬化環境?
虛擬機或容器宿主機通過 bond0 提供穩定的底層網絡連接
3.2 使用命令進行搭建bond0
3.2.1、環境準備
關閉VM僅主機模式的dhcp分配,添加兩塊新的網卡,選擇僅主機模式
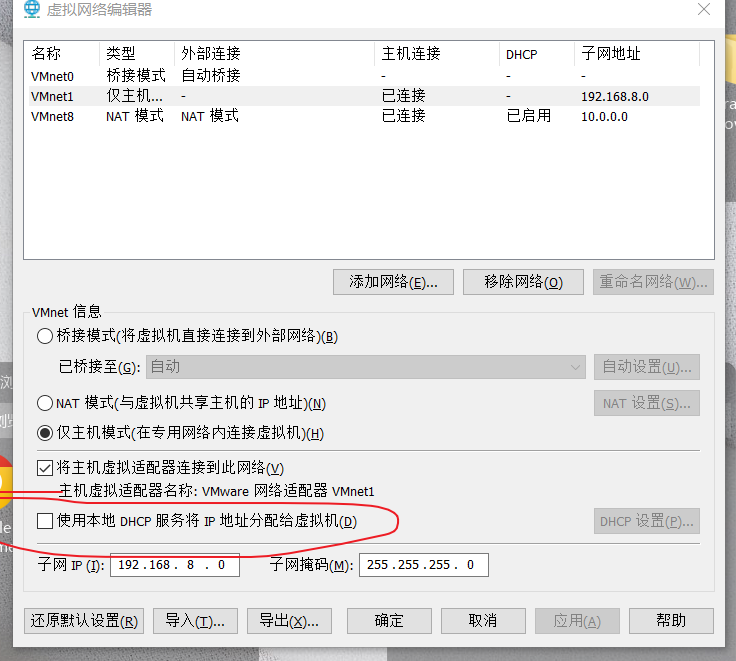
添加新網卡
eth3和eth4是我們新增的網卡
把新增的網卡激活下
nmcli device connect eth4 #激活eth4網卡
nmcli device connect eth3#激活eth3網卡
[root@openEuler-19 ~]# nmcli con
NAME UUID TYPE DEVICE
eth3 4c166a35-3580-4750-b684-62f943fa10ec ethernet eth3
eth4 5ac191ff-eb2d-4098-ab31-e38be9f47079 ethernet eth4
eth0 5fb06bd0-0bb0-7ffb-45f1-d6edd65f3e03 ethernet eth0
eth1 86692a40-9cd9-4893-8ea5-a63dfbdfb672 ethernet eth1
lo 161c12ae-267e-4af5-b43b-38b702cbd5a5 loopback lo
定制bond配置
[root@openEuler-19 network-scripts]# cat ifcfg-bond0
NAME=bond0
TYPE=bond
DEVICE=bond0
BOOTPROTO=none
IPADDR=192.168.8.122
PREFIX=24
BONDING_OPTS="mode=1 miimon=100 fail_over_mac=1"
定制網卡配置
[root@openEuler-19 network-scripts]# cat > /etc/sysconfig/network-scripts/ifcfg-eth3 <<-eof
NAME=eth3
DEVICE=eth3
BOOTPROTO=none
MASTER=bond0
SLAVE=yes
ONBOOT=yes
eof
[root@openEuler-19 network-scripts]# cat > /etc/sysconfig/network-scripts/ifcfg-eth4 <<-eof
NAME=eth4
DEVICE=eth4
BOOTPROTO=none
MASTER=bond0
SLAVE=yes
ONBOOT=yes
eof
重啟網卡查看效果
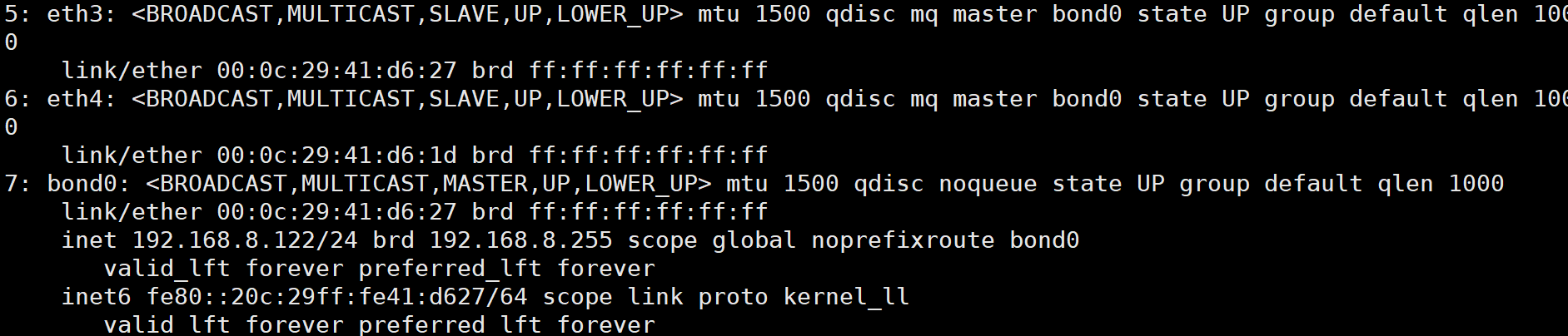
cat /proc/net/bonding/bond0 查看是否成功綁定網卡
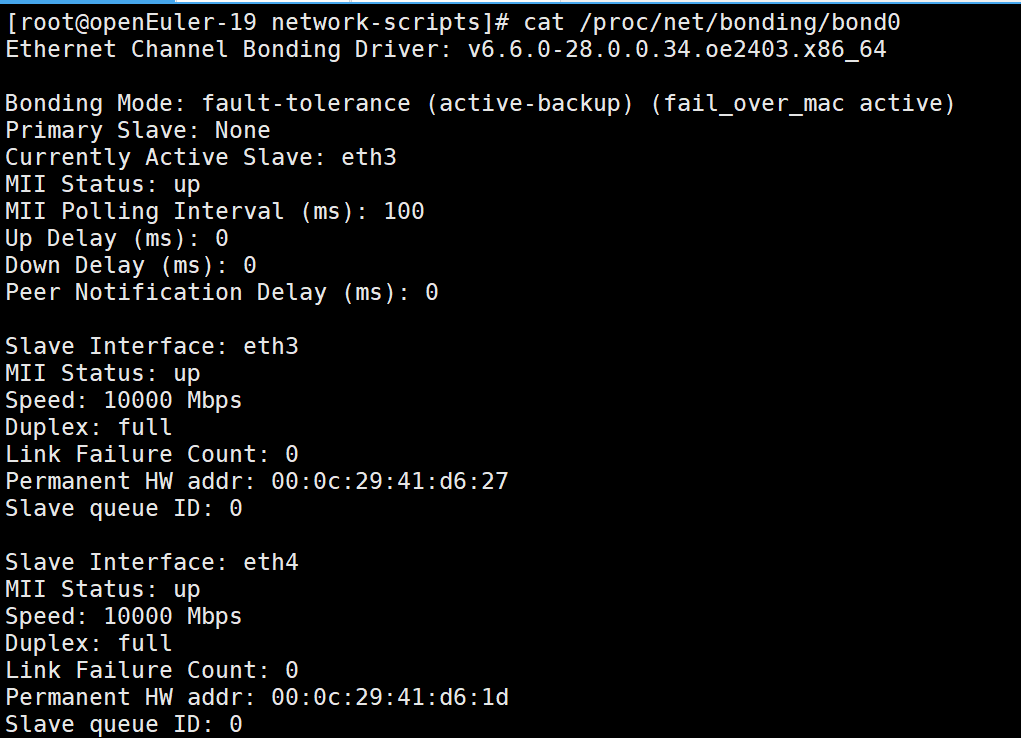
可以看到bond0的環境已經搭建完成
進行網絡測試

確保只有我們的bond0網卡和bond0的綁定網卡再啟動
可以看到在連通網絡時,關閉了eth3網卡,另外一塊備用網卡eth4會起作用,并沒有流量異常。
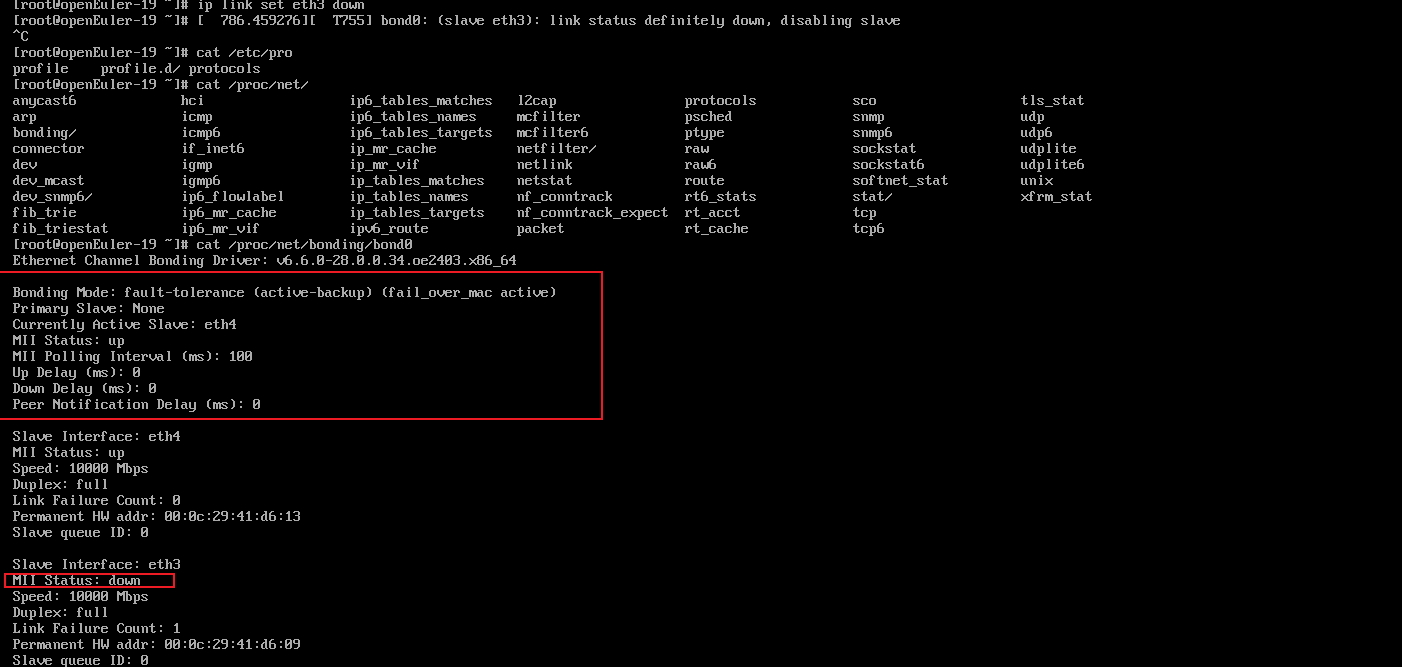
4. 通過ifconfig命令結果找到ip地址.
ifconfig是我們net-tools擴展包里的一個命令,需要先安裝net-tools
[root@rocky9-15 ~]# yum install -y net-tools
上次元數據過期檢查:23:02:34 前,執行于 2025年05月25日 星期日 22時52分40秒。
軟件包 net-tools-2.0-0.64.20160912git.el9.x86_64 已安裝。
依賴關系解決。
無需任何處理。
完畢!
然后直接輸入ifconfig即可查看我們網卡的ip地址
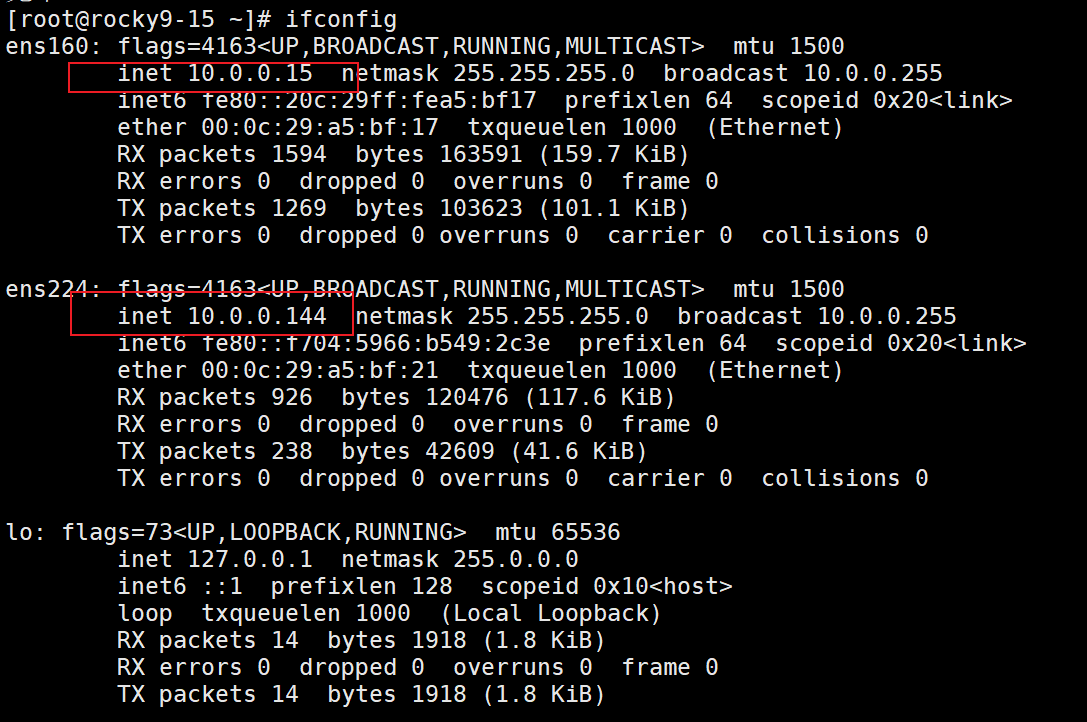
5. 使用腳本判斷 你主機所在網絡內在線的主機IP有哪些? ping通則在線。
#!/bin/bash
# 獲取本機IP和網段
LOCAL_IP=$(hostname -I | awk '{print $1}')
NETWORK=$(echo $LOCAL_IP | cut -d'.' -f1-3)
# 掃描1-254范圍IP
echo "掃描網段: ${NETWORK}.0/24"
for i in {1..254}; do
ip="${NETWORK}.${i}"
# 設置1秒超時,發送1個ICMP包
ping -c 1 -W 1 $ip > /dev/null 2>&1 && \
echo -e "\033[32m[在線]\033[0m $ip" || \
echo -e "\033[31m[離線]\033[0m $ip"
done
但是這個腳本有一些問題就是,假如我的子網并不是/24,可以是/16或者是/28;那這樣的話,這個腳本實際就失效了
6. 使用while read line和/etc/passwd,計算用戶id總和。
#!/bin/bash
total=0
# 逐行讀取/etc/passwd文件
while IFS=: read -r username _ uid _; do
# 累加用戶ID(第3個字段)
total=$((total + uid))
done < /etc/passwd
echo "系統所有用戶ID總和為: $total"
7. 總結索引數組和關聯數組,字符串處理,高級變量使用及示例。
7.1、索引數組
- ?基礎定義?
- 通過整數下標訪問元素(從0開始計數)
- 聲明方式:
array=(value1 value2 value3)注意數據與數據之間是空格隔開 - 支持稀疏存儲(非連續下標)
? 2、核心操作
[root@rocky9-15 week4]# array=(1 5 7 89 14) #定義一個數組
[root@rocky9-15 week4]# echo ${array[1]} # 輸出第二個元素:5
5
[root@rocky9-15 week4]# echo ${array[@]} #輸出全部元素
1 5 7 89 14
[root@rocky9-15 week4]# echo ${#array[@]} #獲取數組長度
5
- ?特殊用法?
- 動態修改元素:
files[2]="newfile"
[root@rocky9-15 week4]# array[1]=666 #將5改為666
[root@rocky9-15 week4]# echo ${array[1]} # 輸出第二個元素:666
666
-
獲取所有索引:
${!files[@]}(適用于稀疏數組)[root@rocky9-15 week4]# array[10]=9999 #將數組第11個元素賦值為9999,在shell的數組是允許下標索引不連續的,所以我們可以直接中間索引直接直接給索引11直接賦值的,這樣的話我們的數組就變成了一個稀疏數組。 [root@rocky9-15 week4]# echo ${!array[@]} 0 1 2 3 4 10 -
切片操作:
${files[@]:1:2}(從索引1開始取2個元素)[root@rocky9-15 week4]# echo ${array[@]:1:2} 666 7
7.2、關聯數組
1、定義
在Bash中,關聯數組(Associative Array)是一種以?字符串作為鍵?(而非數字索引)的鍵值對數據結構,類似于其他語言中的字典(Dictionary)或映射(Map)。
2、 聲明關聯數組
必須使用 declare -A 顯式聲明,否則會被視為普通數組
[root@rocky9-15 week4]# declare -A personMap # 聲明一個關聯數組
3、初始化與賦值
[root@rocky9-15 week4]# personMap=( [name]="test" [age]=23 [city]="GUANZHOU" ) #賦值
[root@rocky9-15 week4]# echo ${personMap[name]}
test
[root@rocky9-15 week4]# personMap[sex]="nan" #動態賦值
[root@rocky9-15 week4]# echo ${personMap[sex]}
nan
[root@rocky9-15 week4]# for key in "${!personMap[@]}";do #遍歷鍵值對
> echo "Key:$key,Value:${personMap[$key]}"
> done
Key:city,Value:GUANZHOU
Key:age,Value:23
Key:sex,Value:nan
Key:name,Value:test
4、刪除元素
[root@rocky9-15 week4]# unset personMap[age] #刪除鍵為age的條目
[root@rocky9-15 week4]# echo ${personMap[age]}
7.3、字符串處理
字符串截取

[root@rocky9-15 ~]# string=abc12342341
[root@rocky9-15 ~]# echo ${string#a*3} #刪除abc123子串,保留42341
42341
[root@rocky9-15 ~]# echo ${string#c*3} #匹配不到子串,輸出全部
abc12342341
[root@rocky9-15 ~]# echo ${string#*c1*3} #匹配abc123子串,輸出全部42341
42341
[root@rocky9-15 ~]# echo ${string##a*3} #匹配abc123423子串,輸出全部41
41
[root@rocky9-15 ~]# echo ${string%3*1} #匹配341子串,輸出abc12342
abc12342
[root@rocky9-15 ~]# echo ${string%%3*1} #匹配342341子串,輸出abc12
abc12
字符串截取賦值
[root@rocky9-15 ~]# file=/var/log/nginx/access.log
[root@rocky9-15 ~]# filename=${file##*/} #匹配到access.log
[root@rocky9-15 ~]# echo $filename
access.log
[root@rocky9-15 ~]# filedir=${file%/*} #匹配到/var/log/nginx
[root@rocky9-15 ~]# echo $filedir
/var/log/nginx
字符串替換
[root@rocky9-15 ~]# str="apple, tree, apple tree, apple"
[root@rocky9-15 ~]# echo ${str/apple/APPLE} #將字符串的第一個apple替換成為APPLE
APPLE, tree, apple tree, apple
[root@rocky9-15 ~]# echo ${str//apple/APPLE} #將字符串的所有apple替換成為APPLE
APPLE, tree, APPLE tree, APPLE
7.4 、高級變量
-
默認值處理:
${var:-default}(變量為空時使用默認值) -
錯誤檢查:
${var:?error_msg}(變量未定義時報錯退出) -
條件賦值:
${var:=value}(為空時賦值并返回)[root@rocky9-15 ~]# unset name [root@rocky9-15 ~]# echo ${name:-"test"} #變量為空時返回默認值(不修改變量) test [root@rocky9-15 ~]# echo $name [root@rocky9-15 ~]# echo ${count:=10} #變量為空時賦值并返回默認值 10 [root@rocky9-15 ~]# echo $count 10 [root@rocky9-15 ~]# echo ${path:?"路徑未定義"} #變量為空時報錯退出 -bash: path: 路徑未定義 [root@rocky9-15 ~]# echo ${title:+"高級教程"} #變量非空時替換值 高級教程
8. 求10個隨機數的最大值與最小值。
#!/bin/bash
random_numbers=() #創建空數組存儲數據
# 生成10個隨機數并存入數組
for i in {1..10}; do
random_numbers[i-1]=$((RANDOM % 100))
done
max_num=${random_numbers[0]} # 初始化為第一個元素
min_num=${random_numbers[0]} # 初始化為第一個元素
for i in {1..10}; do #通過循環遍歷查找出最大值和最小
if [ ${random_numbers[i-1]} -gt $max_num ]; then
max_num=${random_numbers[i-1]}
fi
if [ ${random_numbers[i-1]} -lt $min_num ]; then
min_num=${random_numbers[i-1]}
fi
done
echo "最大值: $max_num"
echo "最小值: $min_num"
9. 使用遞歸調用,完成階乘算法實現。
#!/bin/bash
# 定義階乘函數
factorial() {
# 參數檢查:如果輸入小于等于1,直接返回1(0!和1!都等于1)
if [ $1 -le 1 ]; then
echo 1
else
# 遞歸調用:計算(n-1)的階乘
last=$(factorial $(( $1 - 1 )))
# 返回結果:n * (n-1)!
echo $(( $1 * last ))
fi
}
# 用戶交互部分
read -p "請輸入一個正整數: " num # 提示用戶輸入
result=$(factorial $num) # 調用階乘函數
echo "$num 的階乘是: $result" # 輸出計算結果
[root@rocky9-15 week4]# bash jiecheng.sh
請輸入一個正整數: 6
6 的階乘是: 720
10. 解析進程和線程的區別? 解析進程的結構。
10.1、進程和線程區別
?1. 定義與基本特性
| ?進程? | ?線程? |
|---|---|
| 進程是程序的?一次執行實例?,擁有獨立的內存空間和系統資源(如文件句柄、網絡連接等)。 | 線程是?進程內的一個執行單元?,共享進程的內存和資源,但擁有獨立的棧空間和程序計數器。 |
| ?獨立性強?:一個進程崩潰不會直接影響其他進程。 | ?依賴性強?:一個線程崩潰可能導致整個進程終止。 |
?2. 資源分配?
| ?進程? | ?線程? |
|---|---|
| ?獨立內存空間?:每個進程擁有獨立的虛擬地址空間(代碼段、數據段、堆、棧等)。 | ?共享內存?:線程共享進程的堆和全局變量,僅各自保留獨立的棧。 |
| ?資源開銷大?:進程創建、切換和銷毀需要分配或回收內存、文件描述符等資源,成本較高。 | ?輕量級?:線程的創建、切換和銷毀成本低,因為它們共享進程資源。 |
?3. 執行與切換?
| ?進程? | ?線程? |
|---|---|
| ?進程間切換?:需要保存和恢復整個進程的上下文(如內存映射、寄存器狀態等),?開銷大?。 | ?線程間切換?:僅需保存線程的棧和寄存器狀態,?開銷小?。 |
| 進程是操作系統?調度資源的基本單位?。 | 線程是操作系統?調度的最小執行單位?。 |
?4. 通信機制?
| ?進程? | ?線程? |
|---|---|
| ?進程間通信(IPC)?:必須通過管道(Pipe)、消息隊列(Message Queue)、共享內存(Shared Memory)、信號(Signal)、套接字(Socket)等機制。 | ?線程間通信?:直接讀寫共享內存即可(需通過鎖、信號量等機制同步)。 |
| ?安全性高?:進程間隔離性好,但通信復雜。 | ?效率高?:線程共享內存,通信簡單,但容易導致競態條件(Race Condition)等同步問題。 |
?5. 應用場景?
| ?進程? | ?線程? |
|---|---|
| ?高隔離性和穩定性?:例如瀏覽器每個標簽頁作為獨立進程(崩潰不影響其他標簽頁)。 | ?高并發和性能?:例如 Web 服務器(如 Nginx)通過多線程處理大量并發請求。 |
| ?分布式系統?:不同進程可運行在不同機器上。 | ?計算密集型任務?:利用多核 CPU 并行運算(如科學計算、圖像處理)。 |
?6. 典型比喻?
- ?進程?:類似一家公司,每個公司有獨立的資金、員工、辦公室資源,公司之間需要通過合同或郵件溝通。
- ?線程?:類似公司內的部門,共享公司資源(資金、辦公室),部門間協作效率高,但需要小心資源沖突(如會議室爭搶)。
10.2、進程的結構
進程的結構主要由三個核心部分組成:
?1. 程序段(代碼段)?
- ?定義?:存儲進程需要執行的機器指令代碼,通常是只讀的,防止意外修改。
- ?示例?:如一個運行中的瀏覽器進程包含渲染引擎、網絡請求處理等功能的代碼。
?2. 數據段?
組成:
-
?靜態數據區?:存放全局變量、靜態變量等初始化數據。
-
?堆(Heap)?:動態分配內存區域,用于
malloc或new操作的內存管理。 -
?棧(Stack)?:存儲函數調用時的局部變量、返回地址等信息,每個線程通常有獨立棧。
作用?:為進程運行時提供必要的數據存儲支持。
?3. 進程控制塊(PCB)?
- ?定義?:操作系統為每個進程創建的核心數據結構,記錄進程的管理和調度信息。
- ?關鍵內容:
- ?標識信息?:進程ID(PID)、父進程ID等。
- ?狀態信息?:運行態、就緒態、阻塞態等狀態標記。
- ?控制信息?:程序計數器(指向下一條指令地址)、CPU寄存器值、內存分配表等。
- ?資源信息?:打開的文件列表、I/O設備占用情況。
- ?重要性?:PCB是操作系統感知和管理進程的唯一標識,進程創建時分配,終止時回收。
?結構關系示意圖?
進程
├── 程序段(代碼)
├── 數據段
│ ├── 靜態數據區
│ ├── 堆(動態內存)
│ └── 棧(函數調用)
└── PCB
├── 進程狀態
├── 寄存器值
└── 資源指針...
11. 結合進程管理命令,說明進程各種狀態。
進程有五個狀態:
創建狀態、就緒狀態 、執行狀態 、阻塞狀態 、終止狀態
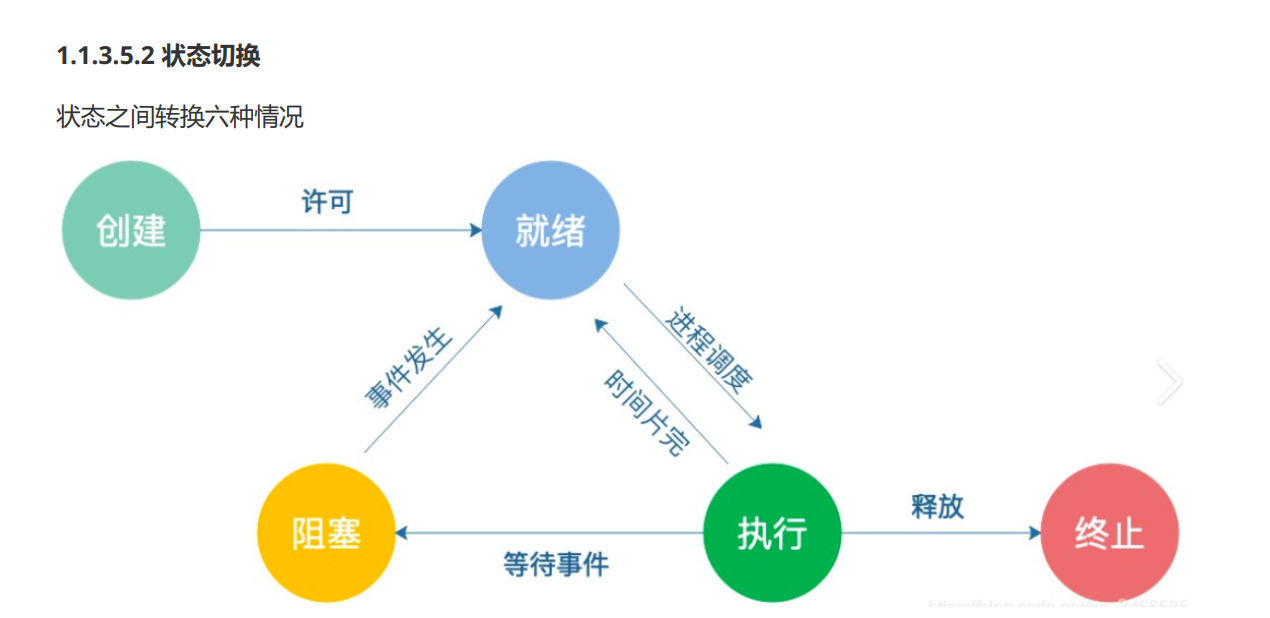
下面是使用命令的具體查看
1、創建狀態(New)
當用戶執行fork()或exec()系統調用時,內核會為新進程分配PCB結構體并初始化。此時進程處于創建態,在ps命令中不可見(內核態操作)。創建完成后立即轉入就緒態。
2. 就緒狀態(Ready)
通過ps -l可查看就緒態進程:
[root@rocky9-15 ~]# ps -l
F S UID PID PPID C PRI NI ADDR SZ WCHAN TTY TIME CMD
4 S 0 5197 5196 0 80 0 - 56052 do_wai pts/2 00:00:00 bash
4 R 0 5450 5197 0 80 0 - 56368 - pts/2 00:00:00 ps
其中S列為R表示就緒態,WCHAN為空說明未阻塞。
3. 執行狀態(Running)
使用top命令實時觀察
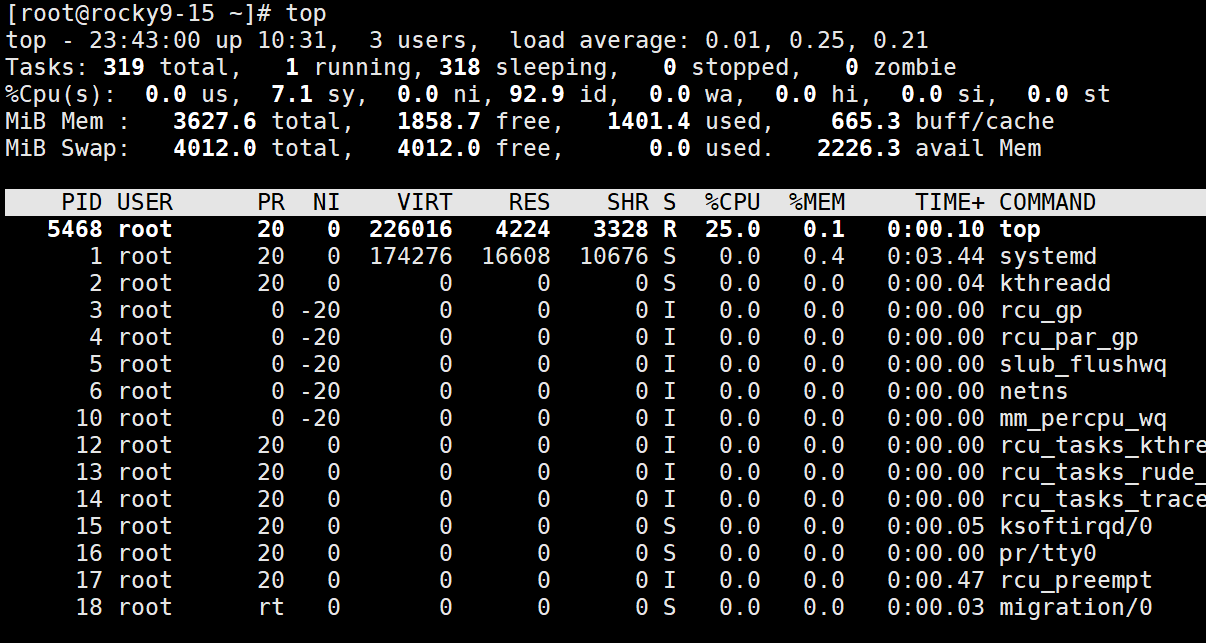
S列顯示R且%CPU>0即為運行態。
4. 阻塞狀態(Blocked)
兩種阻塞類型:
- 可中斷睡眠(S):
ps -l中S列為S - 不可中斷睡眠(D):常見于磁盤IO,
ps -l中S列為D
5. 終止狀態(Terminated)
僵尸進程查看:
[root@rocky9-15 ~]# ps -ef | grep 'defunct'
root 5472 5197 0 23:46 pts/2 00:00:00 grep --color=auto defunct
顯示<defunct>標記的即為僵尸進程。
12. 說明IPC通信和RPC通信實現的方式。
一、IPC(進程間通信)的實現方式
1、共享內存
- 多個進程共享同一塊物理內存區域,實現高效數據交換。需通過信號量或互斥鎖解決并發訪問問題
2、管道(Pipe)與命名管道(FIFO
- 匿名管道:單向通信,僅適用于父子進程或兄弟進程間的數據傳輸,基于文件描述符操作
- 命名管道:通過文件系統路徑標識,支持無親緣關系進程間的通信,采用先進先出隊列機制
3、消息隊列
- 以結構化消息為單位傳遞數據,支持異步通信。消息隊列通過內核維護的鏈表結構管理消息,允許進程按優先級讀
4、信號量(Semaphore)
- 用于進程間同步,通過原子操作控制共享資源的訪問。例如,防止共享內存的讀寫沖突
5、套接字(Socket)
- 支持本地(如Unix Domain Socket)或網絡通信。本地套接字通過文件路徑標識,無需網絡協議棧,傳輸效率高于傳統IPC機制
二、RPC(遠程過程調用)的實現方式
1、?客戶端與服務端存根(Stub)
- ?客戶端存根?:將本地方法調用參數序列化后封裝為網絡傳輸格式,發送至服務端
- 服務端存根?:接收請求并反序列化參數,調用目標方法后返回結果
2、序列化與反序列化 - 使用Protocol Buffers、JSON等協議將參數和返回值轉換為字節流,確保跨語言和跨平臺兼容性
3、網絡傳輸協議
- 基于TCP/IP或HTTP協議實現跨進程通信
- 例如,gRPC采用HTTP/2協議優化性能,支持雙向流式傳輸
4、服務注冊與發現
- 通過注冊中心(如ZooKeeper、Consul)管理服務地址,客戶端動態獲取服務端代理(Proxy),實現負載均衡與故障轉移
5、?跨設備通信實現?
- 在分布式系統中,RPC依賴軟總線驅動處理跨設備調用,通過統一協議實現設備間協同
三、總結
| 特性 | ?IPC? | RPC? |
|---|---|---|
| ?通信范圍? | 本地進程間(單設備內) | 跨設備或遠程進程間 |
| ?依賴機制? | 操作系統內核(如信號量、共享內存) | 網絡協議棧及序列化框架 |
| ?性能? | 高(直接內存訪問) | 較低(涉及網絡傳輸開銷) |
| ?典型場景 | 本地服務協同(如數據庫讀寫) | 微服務、分布式系統調用 |
13. 總結Linux,前臺和后臺作業的區別,并說明如何在前臺和后臺中進行狀態轉換。
13.1、Linux,前臺和后臺作業的區別
一、終端交互性
- 前臺作業?:
獨占終端控制權,運行時阻塞用戶輸入,實時顯示輸出到當前終端。
可通過 Ctrl+C 終止,或 Ctrl+Z 暫停并轉為后臺運行。 - 后臺作業?:
啟動后立即釋放終端(需在命令末尾添加 &),用戶可繼續操作其他任務。
默認輸出仍顯示到終端,可能干擾用戶操作(建議重定向到文件)。
二、?生命周期與控制
-
依賴關系?:
前臺作業的父進程為當前 Shell,關閉終端或會話會直接終止前臺進程。
后臺作業默認依賴當前 Shell,終端退出時可能被終止(可通過 nohup 或 disown 脫離會話)。 -
狀態管理?:
使用 jobs 查看后臺作業列表(包含作業編號及狀態)。
fg %n 將編號為 n 的后臺作業調至前臺,bg %n 恢復暫停的后臺作業運行。
三、?典型場景與操作
-
前臺適用場景?:
需要交互的程序(如 vim、top),或需實時監控輸出的任務。 -
后臺適用場景?:
耗時任務(如編譯、數據處理)或長期運行的服務(配合 nohup command & 實現守護進程)。
四、?核心差異對比圖
| 對比維度 | 前臺作業 | 后臺作業 |
|---|---|---|
| 終端交互性 | 獨占輸入輸出,實時交互 | 釋放終端,用戶可并行操作 |
| 生命周期 | 終端關閉則終止 | 可脫離終端長期運行 |
| 啟動方式 | 直接輸入命令(默認) | 命令末尾添加 & |
| 管理命令 | Ctrl+C/Z、kill PID | jobs、fg、bg、nohup |
13.2、前臺和后臺中進行狀態轉換
[root@rocky9-15 ~]# sleep 60 & #加&號將前臺作業變成后臺作業
[2] 6307
[1] 已完成 sleep 60
[root@rocky9-15 ~]# sleep 100 #前臺作業暫停并轉后臺
^Z
[1]+ 已停止 sleep 100 #按ctrl+Z
[root@rocky9-15 ~]# bg %1 #恢復作業并轉為后臺運行
[1]+ sleep 100 &
[root@rocky9-15 ~]# fg %1 # 將作業號 1 的后臺作業切換到前臺(恢復交互控制)
[root@rocky9-15 ~]# sleep 1000 &
[1] 6313
[root@rocky9-15 ~]# jobs -l # 顯示所有作業及詳細信息(作業號、PID、狀態)
[1]+ 6313 運行中 sleep 1000 &
14. 實現定時任務,每日凌晨1點,刪除指定文件(自己創建即可)
crontab時間字段定義
* * * * *
┬ ┬ ┬ ┬ ┬
│ │ │ │ └─ 星期(0-7,0和7均為周日)
│ │ │ └─── 月份(1-12或英文縮寫)
│ │ └───── 日期(1-31)
│ └─────── 小時(0-23)
└───────── 分鐘(0-59)
[root@rocky9-15 ~]# crontab -l
0 1 * * * rm -rf /test/1.txt
15. 實現定時任務每月月初對指定文件進行壓縮(自己創建文件)
0 0 1 * * tar -czvf archive.tar.gz /homework/
16. 通過shell編程完成,30雞和兔的頭,80雞和兔的腳,分別有幾只雞,幾只兔?
#!/bin/bash
x=30 #動物總頭數
y=80 #動物總腳數
for ((i=1; i<=x; i++))
do
t1=$i #雞頭的數量
t2=$((x-i)) #兔頭的數量
j1=$((t1*2)) #雞腳的數量
j2=$((t2*4)) #兔腳的數量
if [ $((j1 + j2)) -eq $y ]; then # 注意then前加空格
echo "籠子里一共有:$t1只雞"
echo "籠子里一共有:$t2只兔"
exit 0
fi
done
echo "錯誤:沒有找到符合條件的組合"
exit 1
[root@rocky9-15 week4]# bash rabbit.sh
籠子里一共有:20只雞
籠子里一共有:10只兔
17. 結合編程的for循環,條件測試,條件組合,完成批量創建100個用戶,
1)for遍歷1..100
2)先id判斷是否存在
3)用戶存在則說明存在,用戶不存在則添加用戶并說明已添加。
#!/bin/bash
for i in {1..100}
do
user="user$i" #創建新用戶的用戶名
# 進行用戶是否存在的判斷
if id -u "$user" >/dev/null 2>&1; then
echo "$user已經存在,無法創建"
else
useradd $user
echo "$user不存在,已經成功創建該用戶"
fi
done
18. 練習題:練習top,htop, iotop,iostat等課程相關工具的使用
18.1、top
定義
top 是 Linux 中最常用的 ?實時系統監視工具?,用于動態查看進程活動和系統資源使用情況(類似 Windows 的任務管理器)。
?一、核心功能?
| ?功能? | ?說明? |
|---|---|
| ?進程監控? | 實時顯示所有進程的 CPU、內存、優先級等關鍵指標 |
| ?資源統計? | 匯總全局 CPU、內存、交換分區、負載平均值等系統級數據 |
| ?交互操作? | 支持動態排序、終止進程、調整刷新頻率等操作 |
| ?性能診斷? | 快速識別高 CPU/內存占用的進程,定位系統瓶頸 |
?二、界面解析(按下 z 可高亮顏色)?
執行 top 后界面分為兩部分:
?1. 系統概覽區(頭部)
[root@rocky9-15 ~]# top
top - 21:28:21 up 23:12, 3 users, load average: 0.01, 0.04, 0.12
Tasks: 319 total, 1 running, 318 sleeping, 0 stopped, 0 zombie
%Cpu(s): 1.0 us, 0.3 sy, 0.0 ni, 98.5 id, 0.0 wa, 0.2 hi, 0.0 si, 0.0 st
MiB Mem : 3627.6 total, 1934.3 free, 1371.9 used, 577.7 buff/cache
MiB Swap: 4012.0 total, 4008.0 free, 4.0 used. 2255.8 avail Mem
- ?負載平均值(load average)?:1分鐘/5分鐘/15分鐘的平均負載(建議 ≤ CPU核心數)1
- ?CPU 使用率?:用戶態(
us)、內核態(sy)、空閑(id)、I/O 等待(wa)等占比 - ?內存/交換分區?:總量(
total)、空閑(free)、已用(used)、緩存(buff/cache)
?2. 進程列表區(主體)
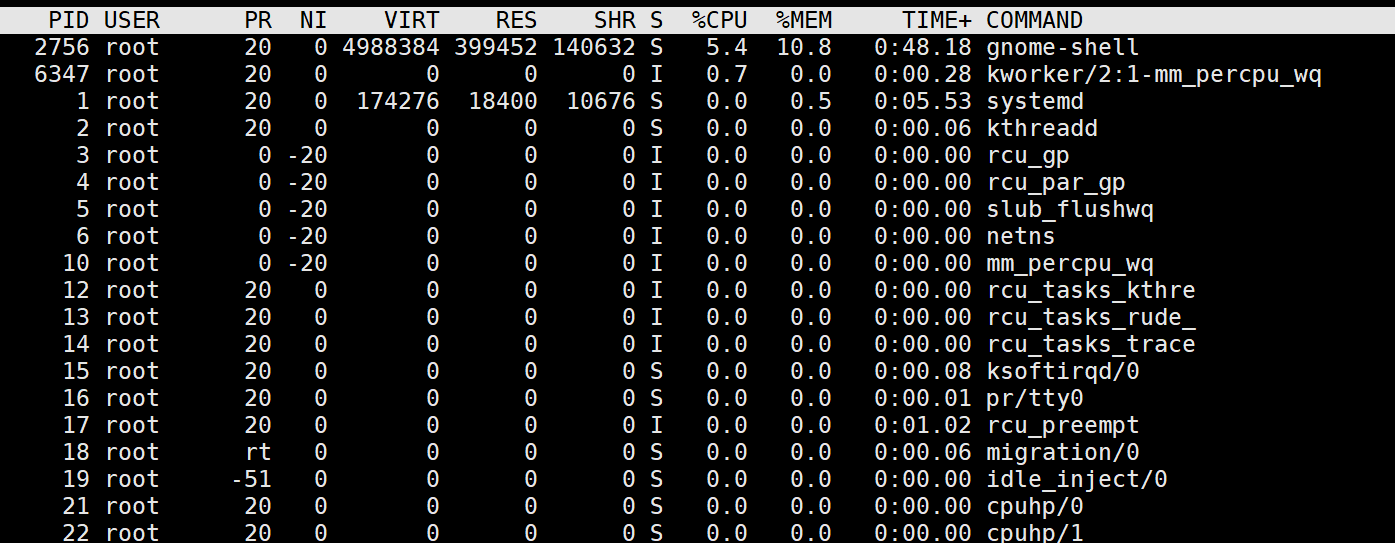
- ?PID?:進程 ID
- ?%CPU?:進程 CPU 使用率(多核下可能超過 100%)
- ?%MEM?:進程物理內存占用百分比
- ?VIRT/RES/SHR?:虛擬內存/物理內存/共享內存(單位 KiB)
- ?S?:進程狀態(
R=運行,S=睡眠,D=不可中斷睡眠,Z=僵尸進程)
?三、常用交互命令?
在 top 界面中按以下快捷鍵操作:
| ?快捷鍵? | ?功能? | ?示例? |
|---|---|---|
P |
按 CPU 使用率排序(默認) | 快速定位 CPU 密集型進程 |
M |
按內存使用率排序 | 找出內存泄漏進程 |
k |
終止進程(需輸入 PID) | kill 命令的快捷方式 |
r |
調整進程優先級(nice 值) |
降低高負載進程的優先級 |
1 |
展開顯示所有 CPU 核心的單獨使用率 | 檢查多核負載均衡 |
d |
修改刷新間隔(默認 3 秒) | 輸入 2 改為 2 秒刷新 |
z |
切換顏色高亮 | 增強可讀性 |
q |
退出 top |
18.2、htop
定義:
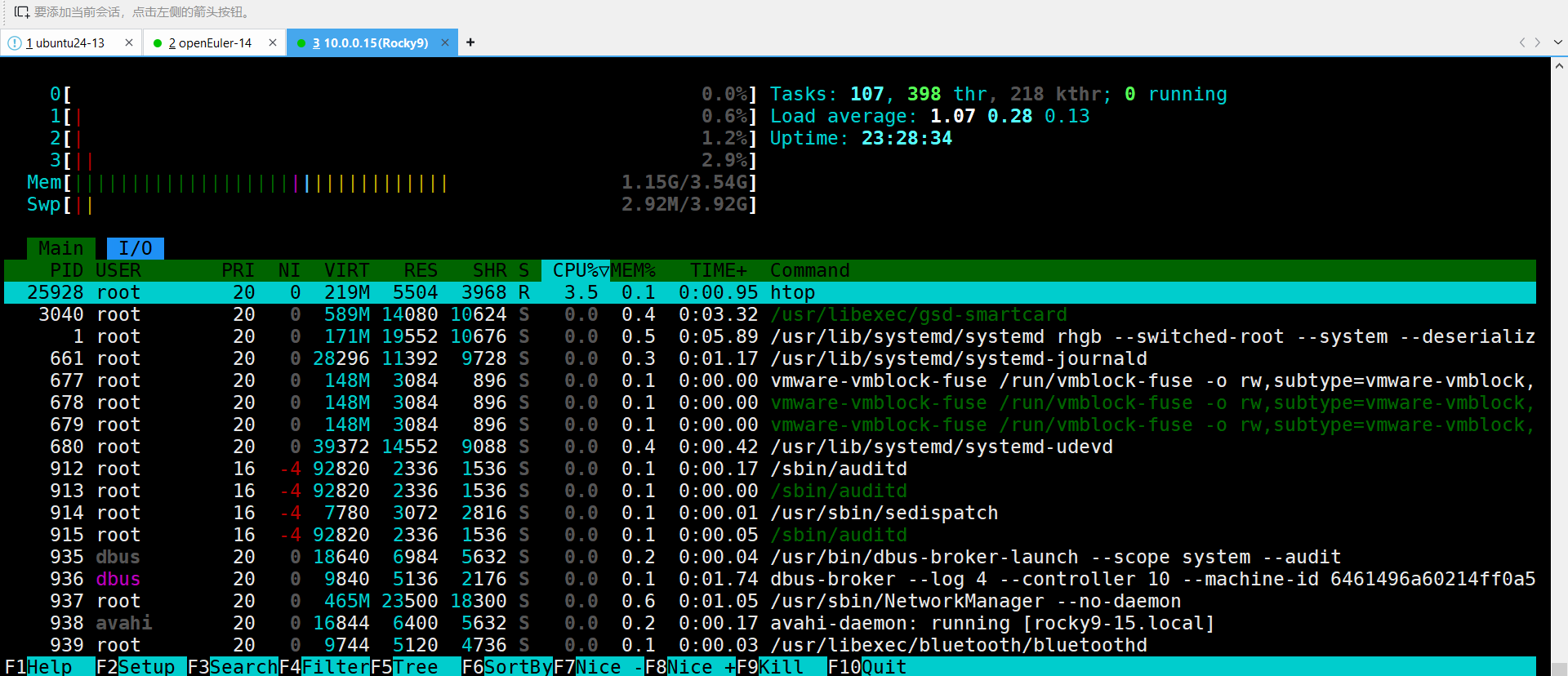
htop? 是 Linux 和類 Unix 系統中廣泛使用的 ?交互式系統監控工具?,可視為傳統 top 命令的增強版,提供更友好的界面和更強大的功能
?一、核心特點?
- ?交互式彩色界面?
支持鼠標操作,以彩色圖表和動態布局直觀展示 CPU、內存、交換分區等資源使用情況。 - ?實時監控與動態更新?
可自定義刷新頻率(默認 1-2 秒),實時跟蹤系統資源和進程活動。 - ?進程管理功能?
支持直接終止進程、調整優先級(nice值)、查看進程樹狀結構等
二、主要功能?
| ?功能? | ?說明? |
|---|---|
| ?資源可視化? | 頂部顯示 CPU、內存、交換分區的使用率圖形(條形圖或數值) |
| ?進程排序? | 支持按 CPU、內存、運行時間等多列排序(快捷鍵 F6) |
| ?搜索與過濾? | 可按進程名、用戶或 PID 快速定位目標進程 |
| ?進程樹狀視圖? | 展示進程間的父子關系(快捷鍵 t) |
| ?批量操作? | 可標記多個進程并統一終止或調整優先級7 |
使用界面
18.3、 iotop
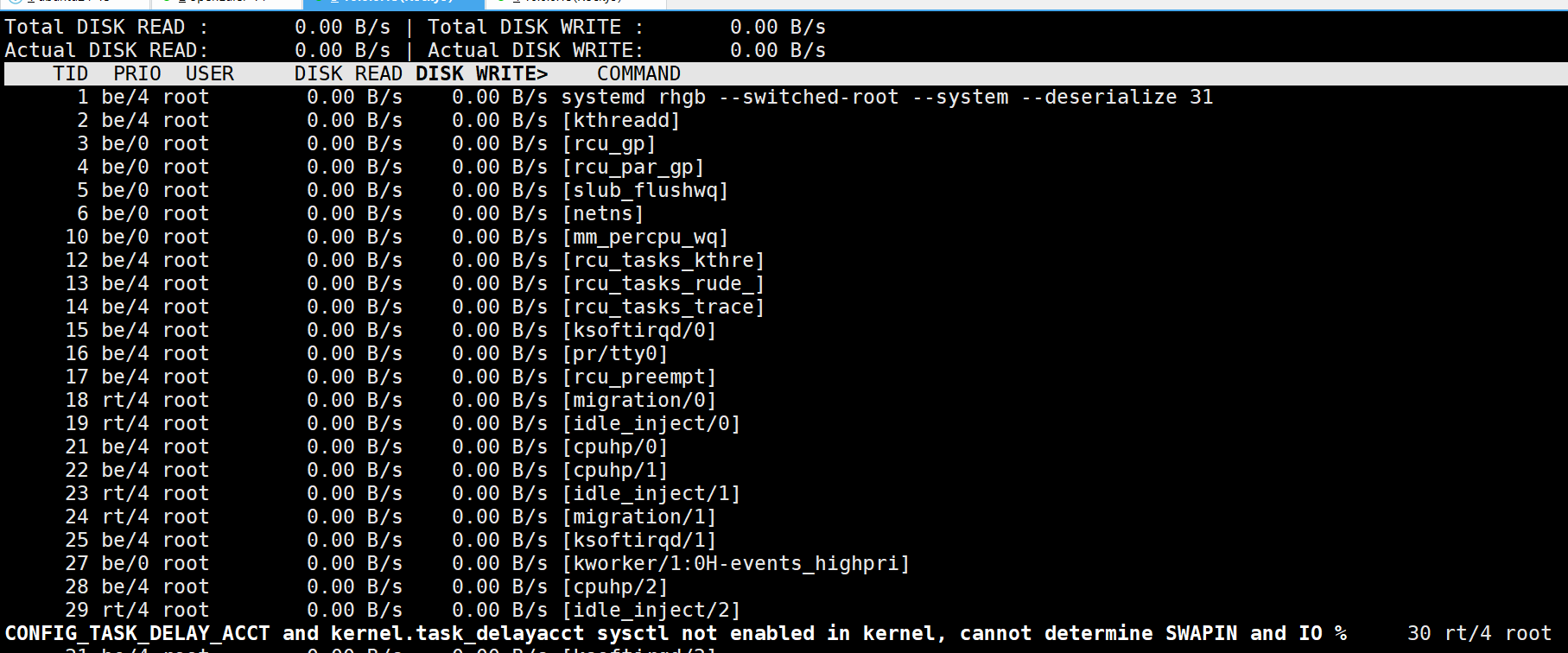
?一、iotop 簡介?
iotop 是一款實時監控磁盤 I/O 使用情況的工具,可顯示進程/線程級別的讀寫帶寬、I/O 優先級等信息,支持交互式操作和批量模式。適合排查高 I/O 負載進程。
?二、基本用法?
?1. 交互模式?
直接運行 iotop 進入實時監控界面,默認按 I/O 使用量降序排列。
輸出字段說明:
- ?Total DISK READ/WRITE?:總讀寫帶寬
- ?Actual DISK READ/WRITE?:實際磁盤 I/O 帶寬
- ?TID?:線程 ID
- ?PRIO?:I/O 優先級(由
ionice設置) - ?DISK READ/DISK WRITE?:進程讀寫速率
?2. 常用選項?
| 選項 | 描述 |
|---|---|
-o |
僅顯示有 I/O 活動的進程 |
-b |
批量模式(非交互,適用于日志記錄) |
-d N |
設置刷新間隔為 N 秒(默認 1 秒) |
-p PID |
監控指定進程的 I/O |
-u USER |
監控指定用戶的進程 |
?三、交互快捷鍵?
| 快捷鍵 | 功能 |
|---|---|
| ?←/→? | 切換排序字段(默認按 I/O 排序) |
| ?r? | 反轉排序順序 |
| ?o? | 切換“僅顯示活躍 I/O 進程”模式 |
| ?a? | 顯示累積 I/O 總量 |
| ?p? | 切換進程/線程顯示模式 |
| ?q? | 退出程序 |
使用界面
18.4、iostat
?一、iostat 定義?
iostat (Input/Output Statistics) 是 Linux/Unix 系統中用于監控 ?磁盤 I/O 性能? 和 ?CPU 使用率? 的核心工具,屬于 sysstat 軟件包的組成部分。它通過統計設備活動時間和系統配置數據,幫助用戶快速定位存儲瓶頸或 CPU 負載問題。
?二、功能概述?
- ?磁盤 I/O 監控?
- 提供 ?讀寫吞吐量(MB/s)?、?IOPS(I/O 操作次數/秒)?、?隊列深度? 等關鍵指標
- 支持分析單個磁盤/分區的性能瓶頸(如高延遲或隊列擁塞)
- 顯示內核的 I/O 合并優化效果(如
rrqm/s和wrqm/s)
- ?CPU 使用率監控?
- 統計 ?用戶態(%user)?、?系統態(%system)?、?空閑(%idle)? 及 ?I/O 等待(%iowait)? 的 CPU 時間占比
- 若
%iowait持續高于 5%,通常表明存儲設備成為系統瓶頸
- ?數據分析模式?
- 支持動態刷新數據(如每秒一次),適用于實時監控
- 可結合
sar工具生成長期性能趨勢報告
?三、工具特點?
- ?廣泛適用性?:默認集成于主流 Linux 發行版,需通過安裝
sysstat包激活 - ?輕量級交互?:命令簡潔,支持參數靈活調整輸出(如
-x顯示擴展狀態、-d僅顯示設備利用率) - ?全局視角?:側重系統整體性能分析,不支持進程級深度監控(需結合
iotop等工具)
?四、典型應用場景?
- ?存儲性能瓶頸排查?:識別高延遲磁盤或異常 I/O 負載
- ?CPU 負載分析?:檢測由 I/O 等待導致的 CPU 資源浪費
- ?系統調優參考?:通過歷史數據優化存儲配置(如 RAID 策略、文件系統選擇)
使用界面
19. 練習課程中awk的使用
19.1、AWK 核心概念
AWK 是逐行處理文本的編程工具,基本結構為:
awk 'BEGIN {預處理} 模式 {動作} END {后處理}' 文件
19.2、字段處理基礎
- 默認以空格/制表符分隔列?,用
$1、$2...訪問列:
awk '{print "第一列:", $1, "最后一列:", $NF}' file.txt
root@ubuntu24-13:~# awk -F ":" '{print "第一列:",$1,"最后一列:",$NF}' /etc/passwd #輸出passwd的第一列和最后一列
第一列: root 最后一列: /bin/bash
第一列: daemon 最后一列: /usr/sbin/nologin
第一列: bin 最后一列: /usr/sbin/nologin
第一列: sys 最后一列: /usr/sbin/nologin
第一列: sync 最后一列: /bin/sync
第一列: games 最后一列: /usr/sbin/nologin
第一列: man 最后一列: /usr/sbin/nologin
第一列: lp 最后一列: /usr/sbin/nologin
第一列: mail 最后一列: /usr/sbin/nologin
第一列: news 最后一列: /usr/sbin/nologin
第一列: uucp 最后一列: /usr/sbin/nologin
第一列: proxy 最后一列: /usr/sbin/nologin
第一列: www-data 最后一列: /usr/sbin/nologin
第一列: backup 最后一列: /usr/sbin/nologin
19.3、條件判斷全解析
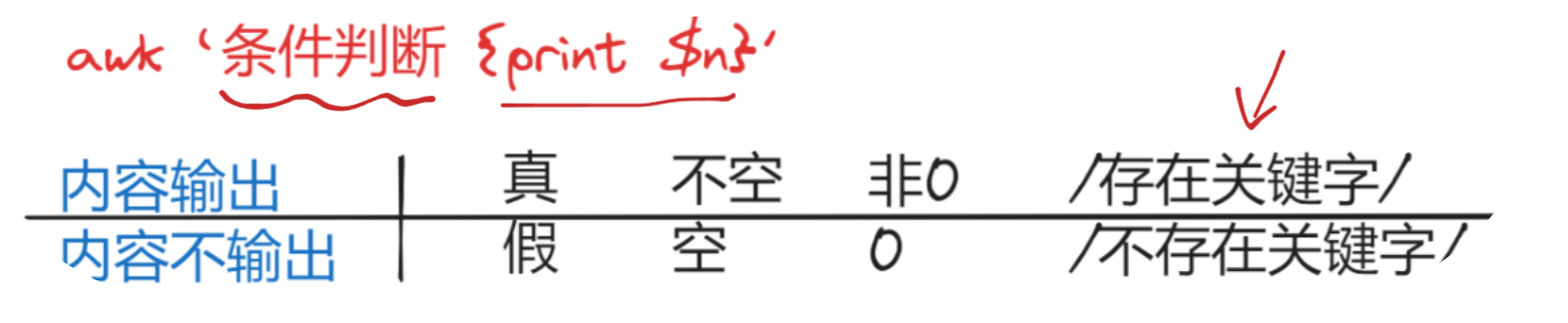
示例:
[root@rocky9-15 week4]# cat employee.txt #創建一個內容文檔
ID Name Age Dept Salary
101 Alice 28 Sales 5000
102 Bob 35 IT 6500
103 Carol 22 HR 4800
104 David 40 IT 7000
105 Eve 31 Sales 5500
[root@rocky9-15 week4]# awk '$4 == "IT" {print $2, $5}' employee.txt #條件為真,輸出內容
Bob 6500
David 7000
[root@rocky9-15 week4]# awk '$4 == "IT_test" {print $2, $5}' employee.txt #條件為假,不輸出內容
[root@rocky9-15 week4]# awk '"" {print $2, $5}' employee.txt #條件為空,不執行
[root@rocky9-15 week4]# awk '" " {print $2, $5}' employee.txt #條件非空,執行
Name Salary
Alice 5000
Bob 6500
Carol 4800
David 7000
Eve 5500
[root@rocky9-15 week4]# awk -v n=0 'n++' employee.txt #第一行的值為0不打印,其余的值都打印
101 Alice 28 Sales 5000
102 Bob 35 IT 6500
103 Carol 22 HR 4800
104 David 40 IT 7000
105 Eve 31 Sales 5500
[root@rocky9-15 week4]# awk -v n=0 '!n++' employee.txt #第一行的值把為0打印,其余的值都不打印
ID Name Age Dept Salary
[root@rocky9-15 week4]# awk '$2 ~/a/ {print $0}' employee.txt #打印文件第二列數值包含a的值
ID Name Age Dept Salary
103 Carol 22 HR 4800
104 David 40 IT 7000
[root@rocky9-15 week4]# awk '$2 !~/a/ {print $0}' employee.txt #打印文件第二列數值把包含a的值
101 Alice 28 Sales 5000
102 Bob 35 IT 6500
105 Eve 31 Sales 5500
[root@rocky9-15 week4]# awk 'BEGIN {sum=0} $4 == "IT" {sum += $5} END {print "IT總工資:",sum}' employee.txt #計算it部門總工資
IT總工資: 13500
[root@rocky9-15 week4]# awk 'NR>1 && $4 != "" {dept[$4] += $5} END {for (d in dept) print d ":", dept[d]}' employee.txt #輸個各個部門的工資
IT: 13500
Sales: 10500
HR: 4800

 浙公網安備 33010602011771號
浙公網安備 33010602011771號