
提供方耗時(shí)正常,調(diào)用方毛刺頻頻
一 現(xiàn)象
調(diào)用方A -> JSF -> 提供方B
大多數(shù)情況下,調(diào)用方耗時(shí) 和 提供方耗時(shí) 基本沒有差別
個(gè)別情況下,調(diào)用方耗時(shí) 遠(yuǎn)高于 提供方耗時(shí),大概5分鐘20+次
1.調(diào)用方A耗時(shí)如下圖
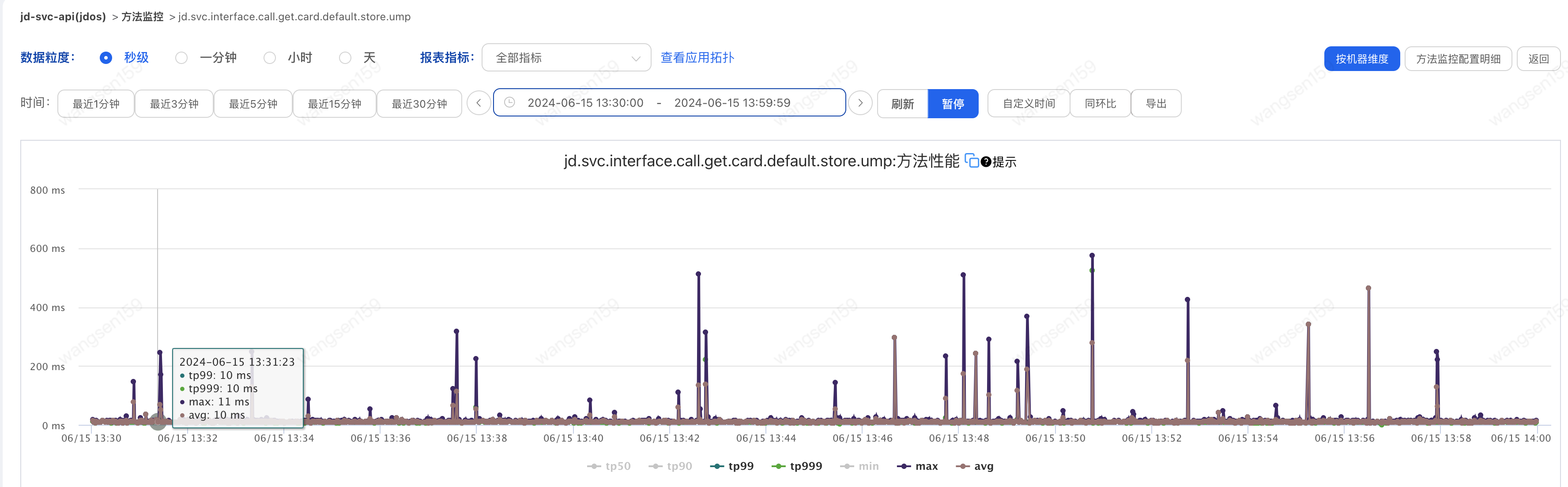
2.提供方B耗時(shí)如下圖

3.調(diào)用方監(jiān)控添加
在調(diào)用JSF接口前后加的監(jiān)控,沒有其他任何邏輯,包括日志打印
4.提供方監(jiān)控添加
在代碼最外層JSF接口加的監(jiān)控,之外沒有任何代碼邏輯
5.耗時(shí)對(duì)比
| 調(diào)用方A平均耗時(shí) | 提供方B平均耗時(shí) | 調(diào)用方A最大耗時(shí) | 提供方B最大耗時(shí) | 調(diào)用方A超100ms數(shù)量 | 提供方B超100ms數(shù)量 | |
| 2024-06-15 13:30:00 至 2024-06-15 13:59:59 | 大部分是低于60ms 有突刺 | 大部分不超過20 | 580ms | 32ms | 24次 | 0 |
二 排查思路
1.數(shù)據(jù)流轉(zhuǎn)環(huán)節(jié)分析
調(diào)用方從請(qǐng)求到接收數(shù)據(jù),除了提供方業(yè)務(wù)耗時(shí),還有其他環(huán)節(jié),分別是
2.初步定位
容器和宿主機(jī)之間由于流量過大,處理壓力大導(dǎo)致的瓶頸
網(wǎng)絡(luò)波動(dòng)
一步一步排除,先看網(wǎng)絡(luò)
3.找證據(jù)
3.1 找監(jiān)控
找到監(jiān)控相關(guān)的技術(shù)同學(xué),回答說沒有網(wǎng)絡(luò)的監(jiān)控
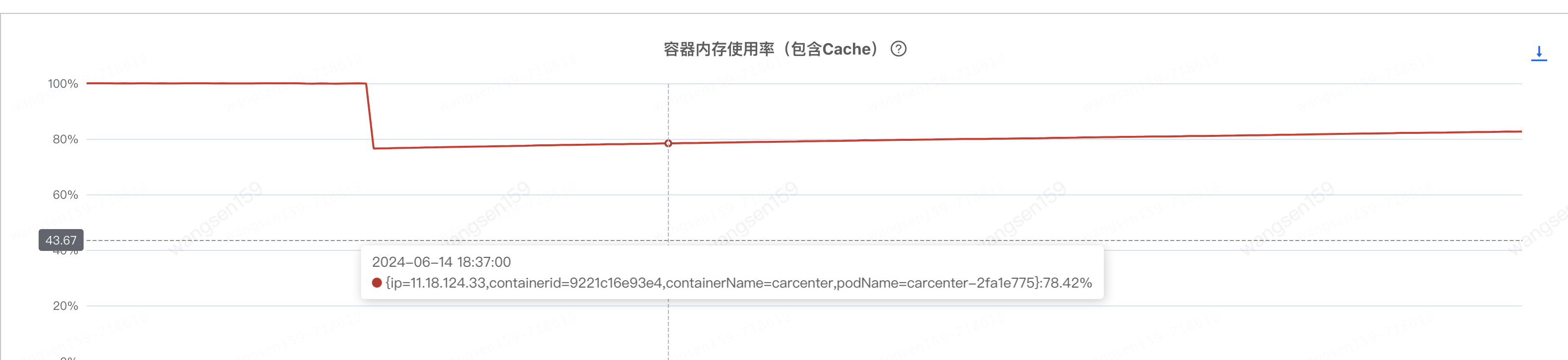
于是找到了JDOS的同學(xué),排查后提供了一種懷疑方向,如下圖
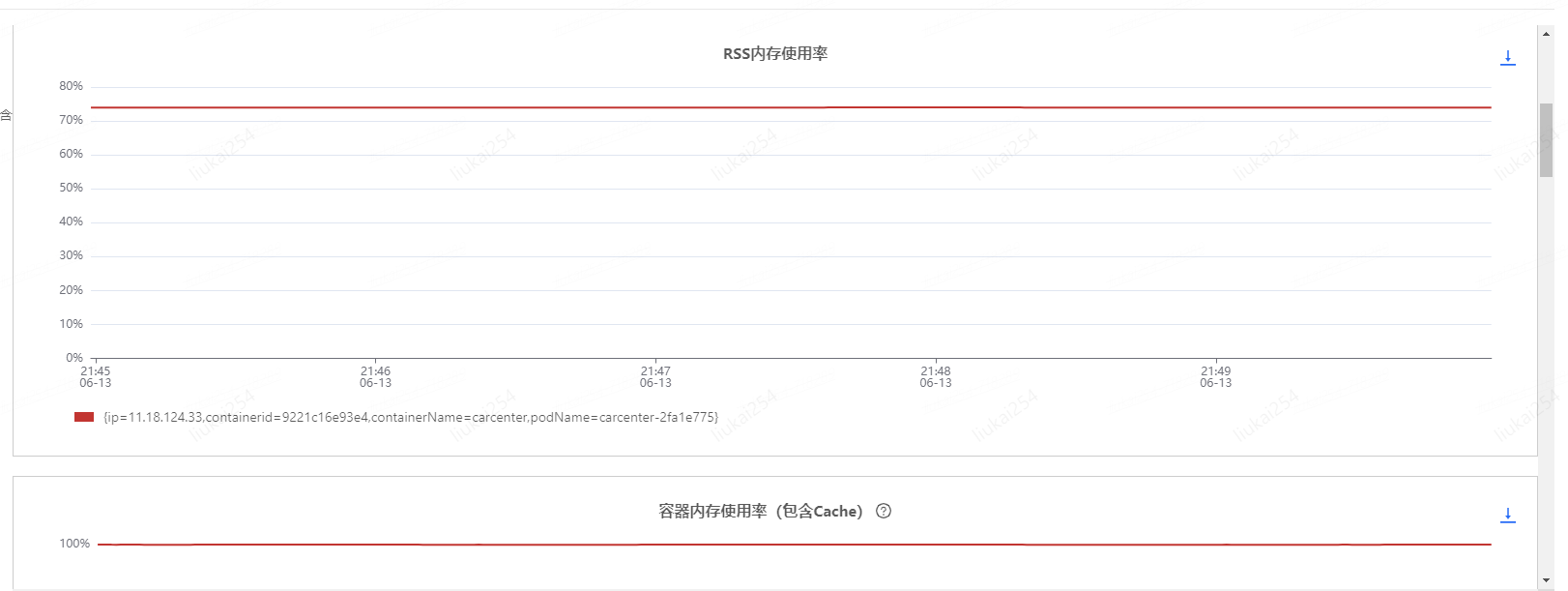
容器內(nèi)存使用率(包含cache)基本一直保持在99%以上,建議先確定該指標(biāo)的影響,并降低該指標(biāo)
3.1.2 指標(biāo)含義
指標(biāo)定義文檔解釋如下
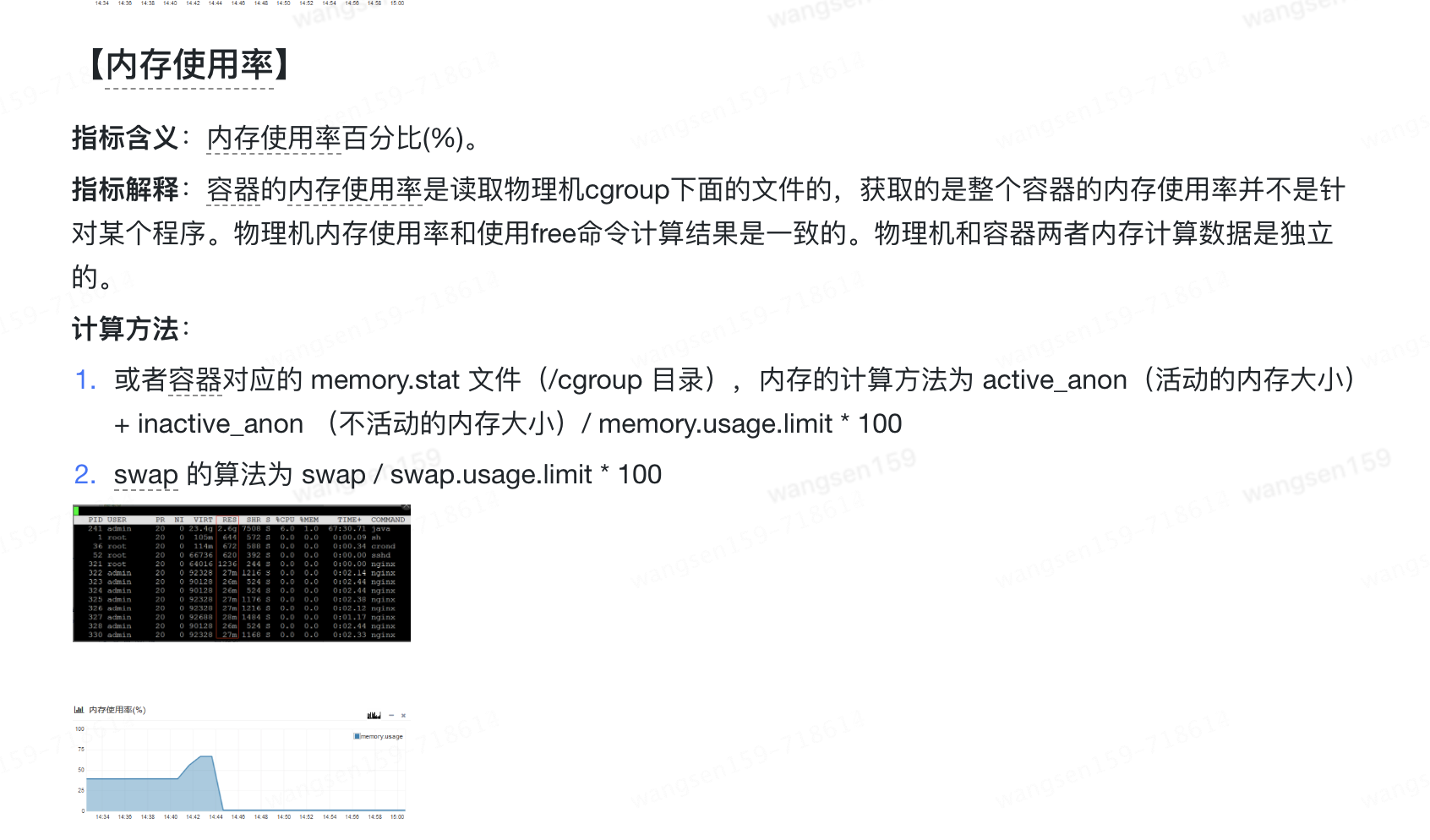
還是看不太懂指標(biāo)的含義,懵B狀態(tài)
提工單咨詢,給出的解決方案如下

java應(yīng)用,無ngix,還是懵,繼續(xù)求助
最后得出結(jié)論:
這個(gè)之前在營銷中心那邊有遇到C++ 使用page cache 還有使用zgc的 需要參考一下cache這個(gè)指標(biāo),其他的場景 目前看 系統(tǒng)會(huì)在物理內(nèi)存不夠用的時(shí)候 釋放cache;
這個(gè)是指有的c++應(yīng)用底層接口直接使用了pagecache,java可以忽略
更詳細(xì)解釋:
內(nèi)存那部分是這樣的,每個(gè)容器的 Memory Cgroup 在統(tǒng)計(jì)每個(gè)控制組的內(nèi)存使用時(shí)包含了兩部分,RSS 和 Page Cache。
RSS 是每個(gè)進(jìn)程實(shí)際占用的物理內(nèi)存,它包括了進(jìn)程的代碼段內(nèi)存,進(jìn)程運(yùn)行時(shí)需要的堆和棧的內(nèi)存,這部分內(nèi)存是進(jìn)程運(yùn)行所必須的。
Page Cache 是進(jìn)程在運(yùn)行中讀寫磁盤文件后,作為 Cache 而繼續(xù)保留在內(nèi)存中的,它的目的是為了提高磁盤文件的讀寫性能。(Java程序只要操作磁盤讀寫也會(huì)用到 page cache)
有時(shí)會(huì)看到這樣一種情況:容器里的應(yīng)用有很多文件讀寫,你會(huì)發(fā)現(xiàn)整個(gè)容器的內(nèi)存使用量已經(jīng)很接近 Memory Cgroup 的上限值了,但是在容器中我們接著再申請(qǐng)內(nèi)存,還是可以申請(qǐng)出來,并且沒有發(fā)生 OOM。那是因?yàn)槿萜髦杏胁糠质荘ageCache,當(dāng)容器需要更多內(nèi)存時(shí),釋放了PageCache,所以總大小并沒有變化。
結(jié)論:對(duì)于java系統(tǒng)來說,容器內(nèi)存使用率(包含cache)沒有影響(cache會(huì)自動(dòng)釋放)
3.1.3 降低容器內(nèi)存使用率(包含cache)
雖說沒有影響,還是想辦法降低試試效果(非常相信大佬)
看了其他幾個(gè)java集群


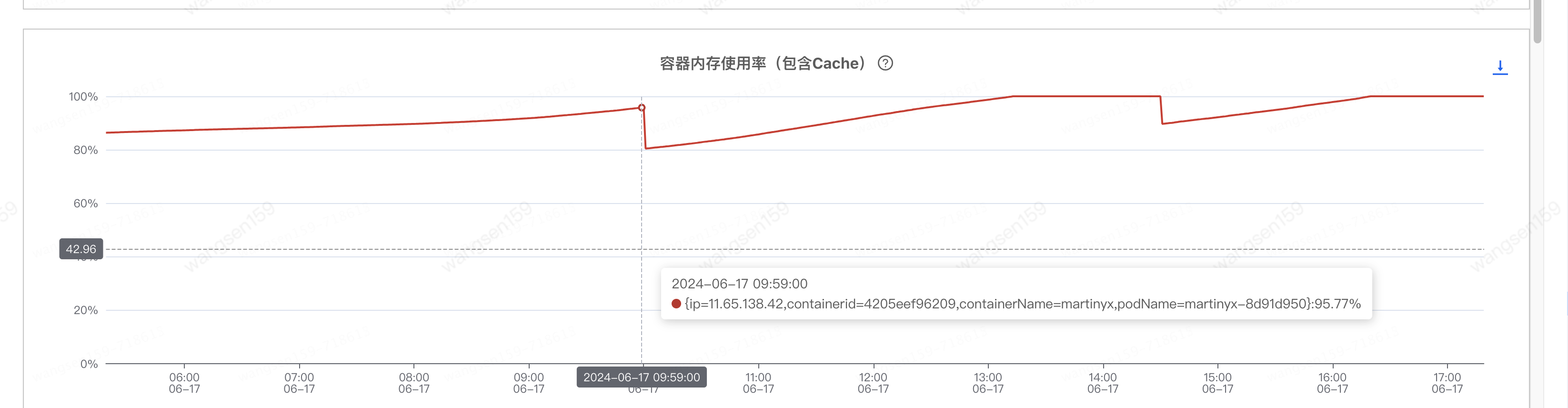
看到最后一個(gè)圖,小小分析了下,發(fā)現(xiàn)三個(gè)小時(shí)會(huì)降低一波,正好和日志清除的時(shí)間間隔一致。
對(duì)提供方B清除日志后發(fā)現(xiàn)果然降低,如下
但是毛刺依然存在!!
3.2 容器處理性能瓶頸
擴(kuò)容前,CPU和內(nèi)存也處于正常水平
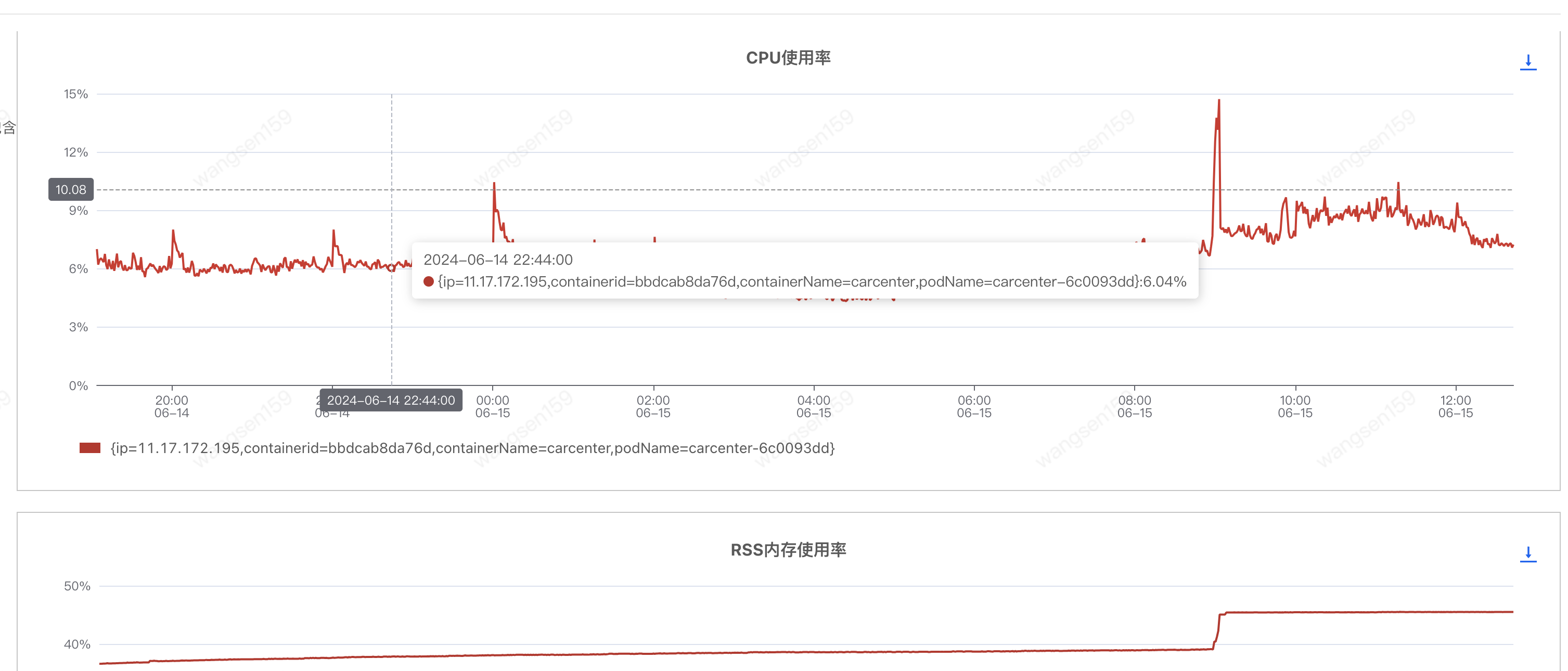
擴(kuò)容后(匯天4臺(tái) -> 匯天8臺(tái)),CPU和內(nèi)存沒啥太多變化
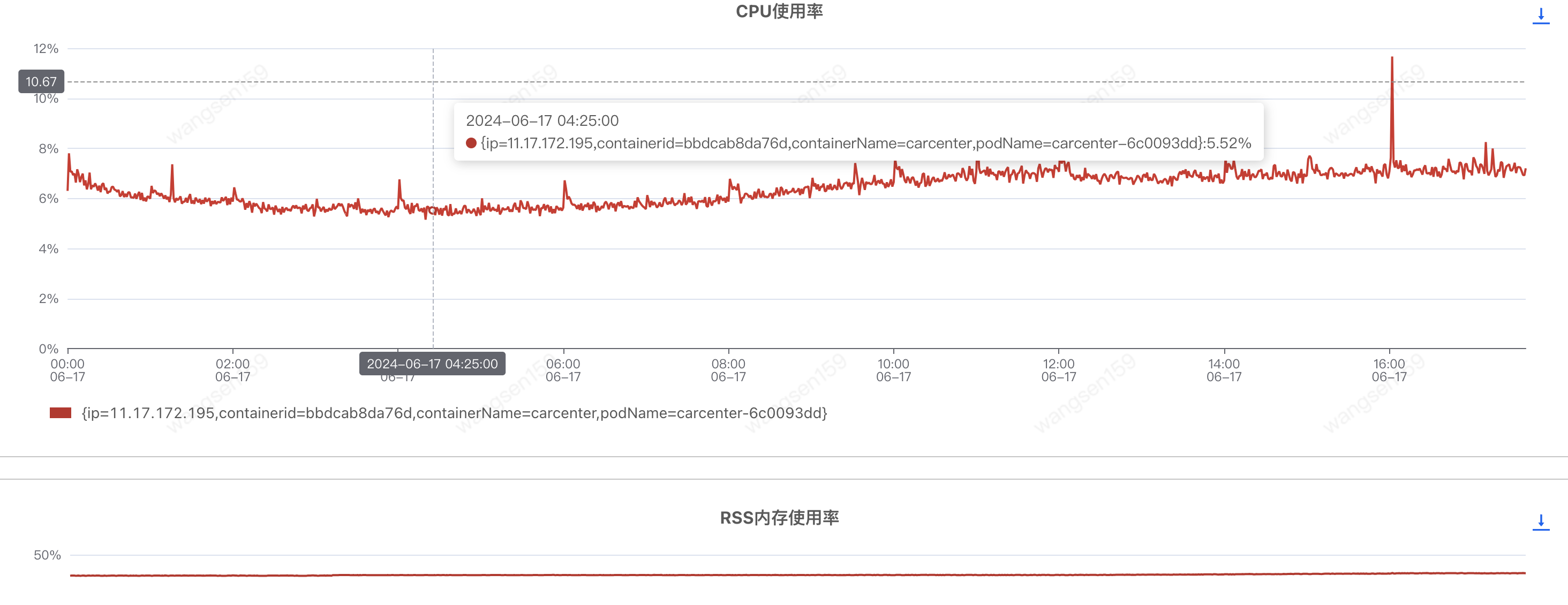
調(diào)用方耗時(shí)如下,基本沒啥變化,頭大
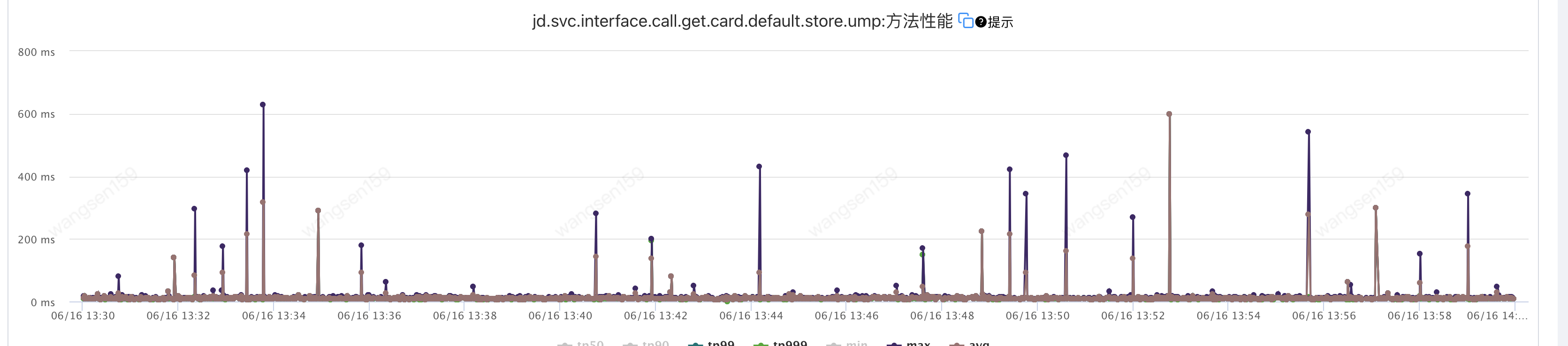
3.3 耗時(shí)分析
運(yùn)維的同事幫忙分析了一波,給出年輕代GC耗時(shí)較高可能會(huì)影響耗時(shí);如下
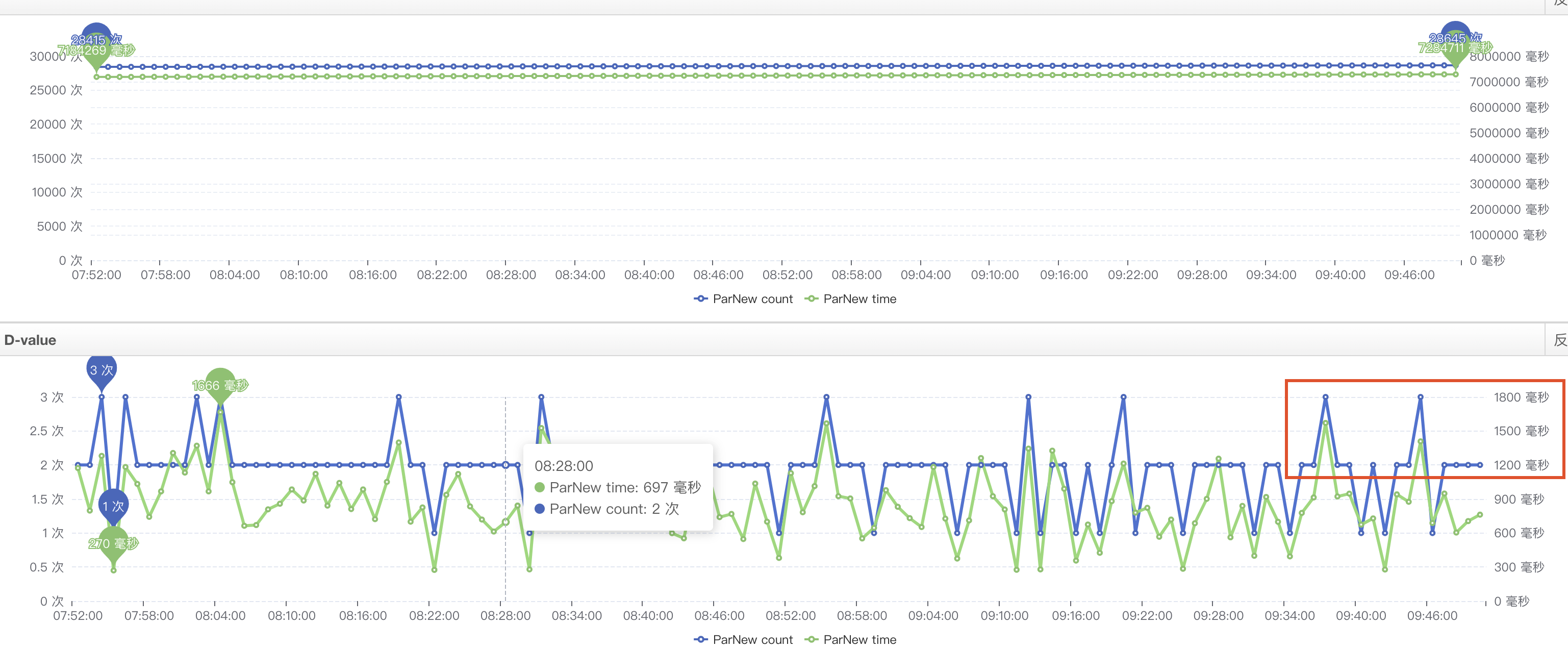
找了兩個(gè)毛刺的數(shù)據(jù),找到對(duì)應(yīng)提供方的機(jī)器,查看那一分鐘內(nèi)有yanggc耗時(shí)(分鐘的粒度),計(jì)算下來,調(diào)用方耗時(shí)比較接近 提供方耗時(shí)+提供方y(tǒng)anggc耗時(shí),但是沒有直接采取措施,主要一下原因
1.yanggc粒度比較粗,分鐘級(jí)
2.一直認(rèn)為FullGC會(huì)導(dǎo)致STW,增加耗時(shí),yangGc不會(huì)有太大影響
3.只有一兩次的數(shù)據(jù)分析,數(shù)據(jù)也沒有那么準(zhǔn)確
4.備戰(zhàn)期間,線上機(jī)器封板,動(dòng)起來比較麻煩,想找下其他原因,雙管齊下
3.4 網(wǎng)絡(luò)對(duì)抓 + PFinder
1.調(diào)用方多臺(tái)機(jī)器,提供方也是多臺(tái)機(jī)器,網(wǎng)絡(luò)抓包要想抓全得N*M,比較費(fèi)勁
2.PFinder也是隨機(jī)抓包
3.毛刺也是隨機(jī)產(chǎn)生的
想保證,抓到毛刺請(qǐng)求,且,PFinder有數(shù)據(jù),采取如下對(duì)策
1.選擇調(diào)用方的一臺(tái)機(jī)器 X 提供方的一臺(tái)機(jī)器,進(jìn)行抓包
2.監(jiān)控調(diào)用方的這臺(tái)機(jī)器的UMP監(jiān)控
3.調(diào)用方的UMP監(jiān)控有毛刺時(shí),查看是否有PFinder監(jiān)控?cái)?shù)據(jù),如果沒有則繼續(xù)抓,有則停止
最后抓到了想要的數(shù)據(jù)
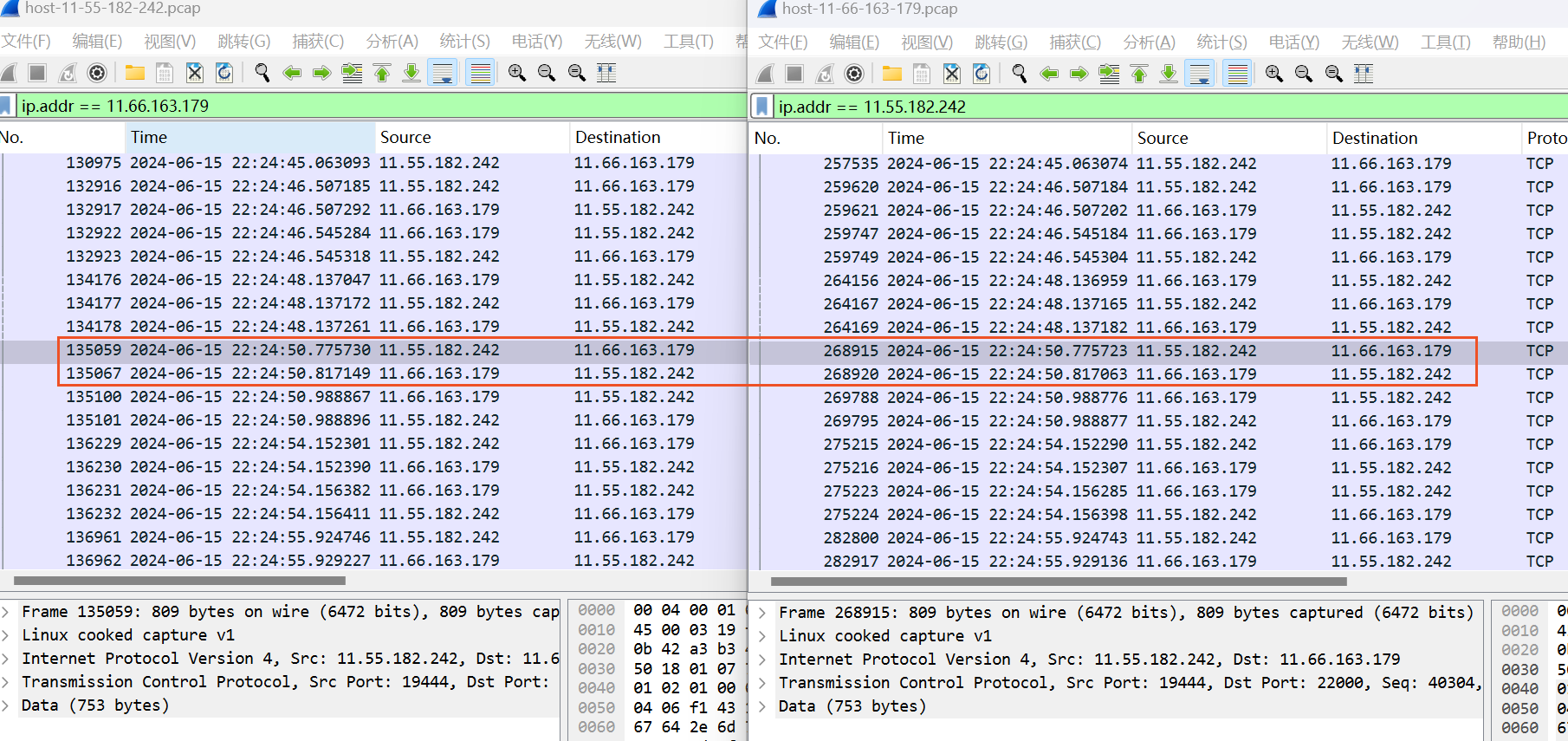
網(wǎng)絡(luò)運(yùn)維的同事幫忙對(duì)抓網(wǎng)絡(luò)包,左邊是調(diào)用方,右邊是提供方,如下
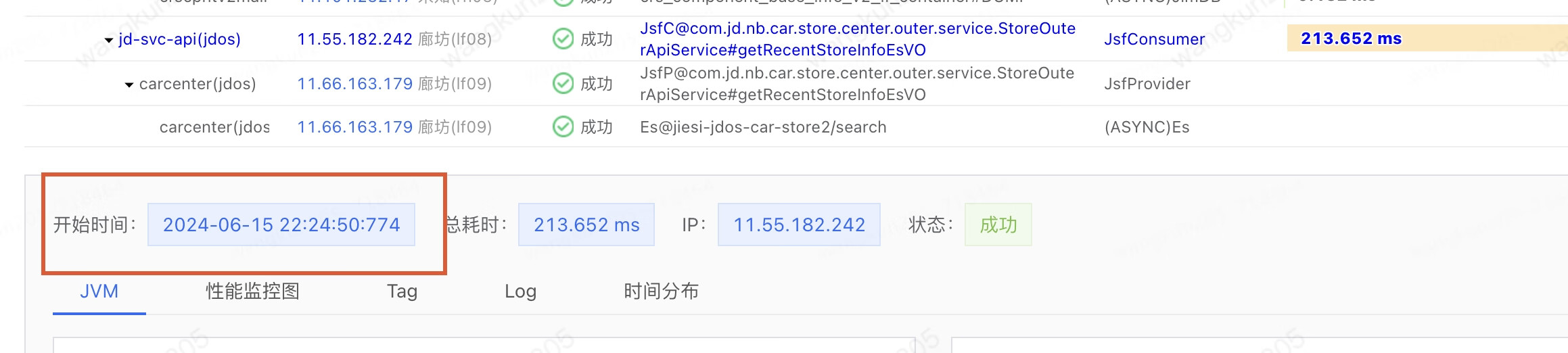
調(diào)用方的PFinder的數(shù)據(jù)如下
提供方代碼開始PFinder的數(shù)據(jù)如下

數(shù)據(jù)分析后結(jié)論如下:
調(diào)用方22:24:50.775730 發(fā)出 22:24:50.988867收到 耗時(shí)213ms
提供方22:24:50.775723收到數(shù)據(jù)包,等到22:24:50.983才處理,22:24:50.988776處理結(jié)束回包
提供方等待208ms左右,實(shí)際處理4.55ms,加起來 213左右,和調(diào)用方耗時(shí)對(duì)應(yīng)上了
網(wǎng)絡(luò)抓包是從容器到容器的抓包
阻塞原因猜測:
1.容器瓶頸,處理不過來 - CPU、內(nèi)存正常,且當(dāng)天下午擴(kuò)容一倍,沒有明顯好轉(zhuǎn)
2.yanggc照成延遲 - 和運(yùn)維同學(xué)張憲波大佬分析的不謀而合,且是有數(shù)據(jù)支撐的
4.處理
1.目的:降低yanggc耗時(shí)(沒有FullGC)
2.當(dāng)前:
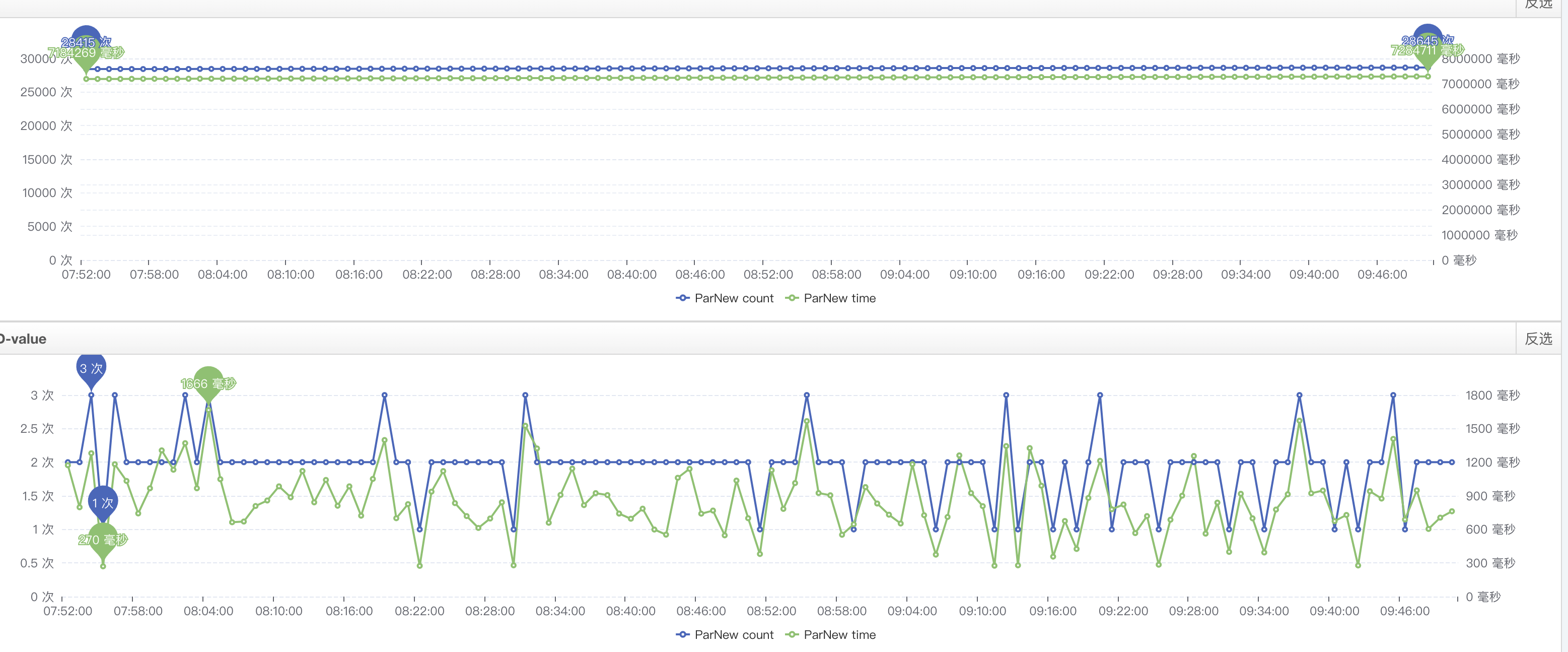
3.方式:
1.增大堆內(nèi)存(年輕代)
2.擴(kuò)容(已經(jīng)擴(kuò)了一次,沒有明顯變化)
3.mq消費(fèi)流量切到其他分組(一般先反序列化,根據(jù)參數(shù)過濾),減少新對(duì)象創(chuàng)建
4.結(jié)果:
調(diào)用方耗時(shí)如下
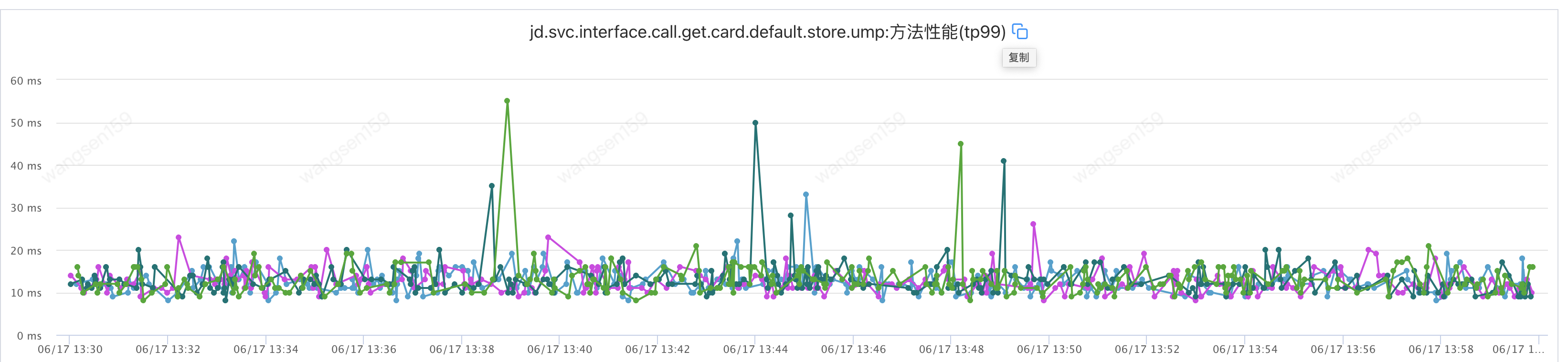
提供方耗時(shí)如下
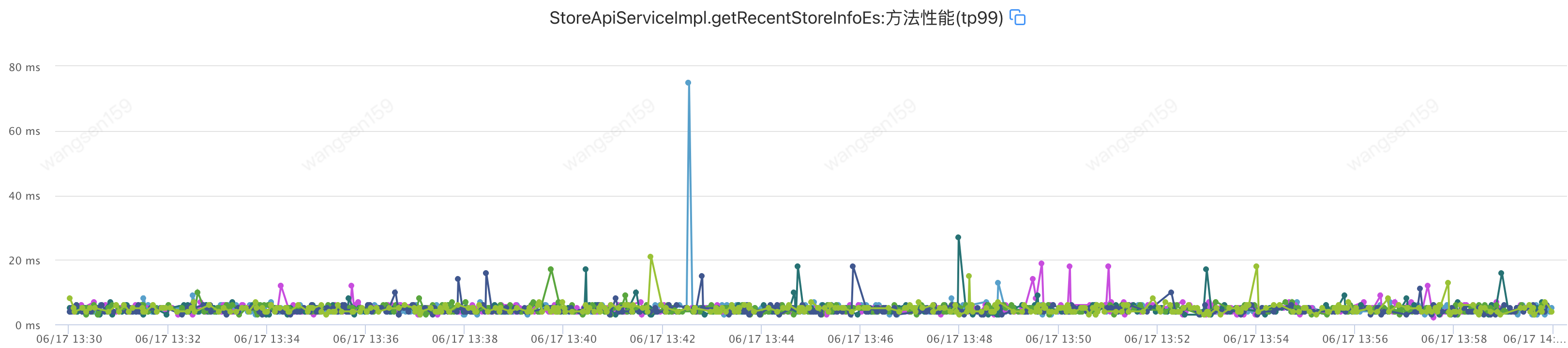
提供方y(tǒng)anggc
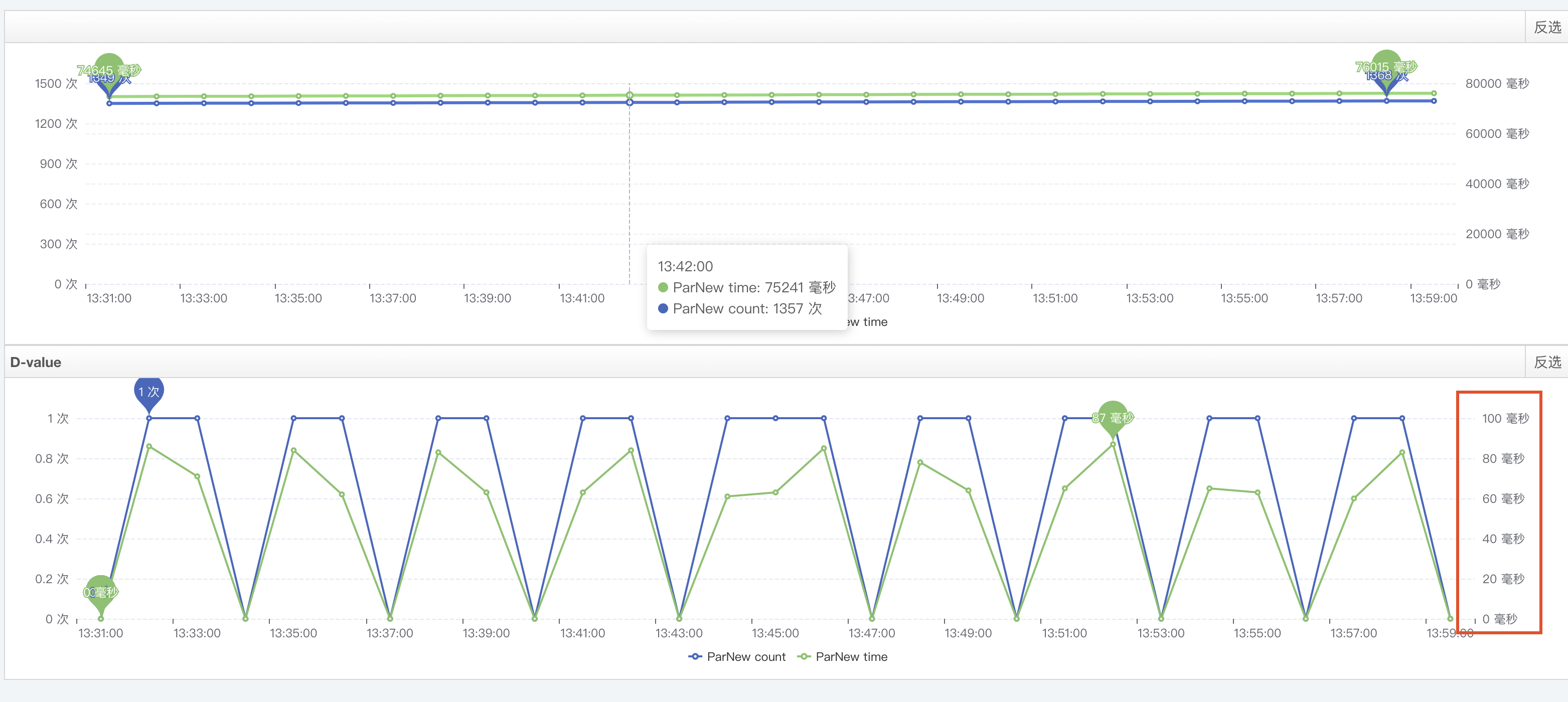
調(diào)整前后調(diào)用方耗時(shí)
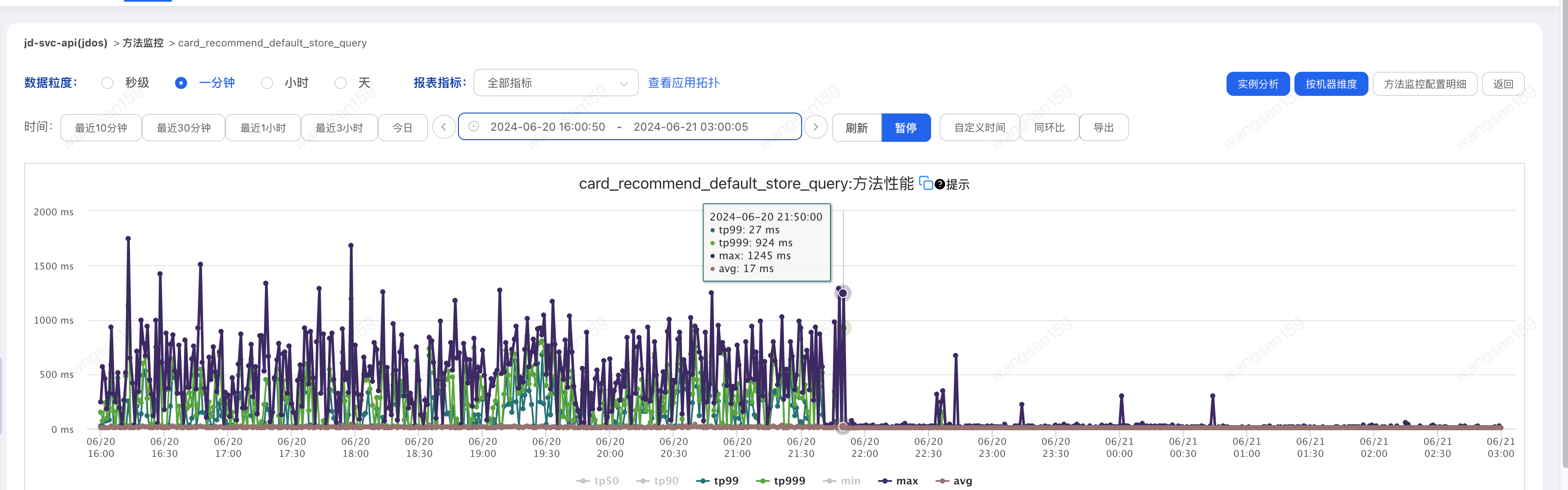
最終提供方和調(diào)用方耗時(shí)不一致的問題得到解決

 浙公網(wǎng)安備 33010602011771號(hào)
浙公網(wǎng)安備 33010602011771號(hào)