
HBase一篇入門
HBase入門教程
HBase是一個開源的、分布式的、版本化的非關系型數據庫,是Apache Hadoop生態系統的重要組成部分。本文將全面介紹HBase的基礎知識,幫助你快速入門。
1. HBase簡介
1.1 什么是HBase?
HBase是建立在HDFS(Hadoop分布式文件系統)之上的分布式、面向列的數據庫。它是Google Bigtable的開源實現,適合存儲非結構化和半結構化的松散數據。

1.2 HBase核心特點
-
海量存儲
- 支持數十億行 × 數百萬列的數據規模
- 單表可以存儲數十億行數據
- 無需預定義列的數量和類型
-
列式存儲
- 數據按列族存儲
- 支持動態列
- 自動分片
-
高可用性
- 底層依托HDFS提供高可用性
- 支持RegionServer之間的故障轉移
- 支持Master的高可用配置
-
線性擴展
- 可以通過增加RegionServer實現擴展
- 自動數據分片
- 負載均衡
-
實時性
- 支持實時讀寫
- 毫秒級延遲
- 隨機訪問
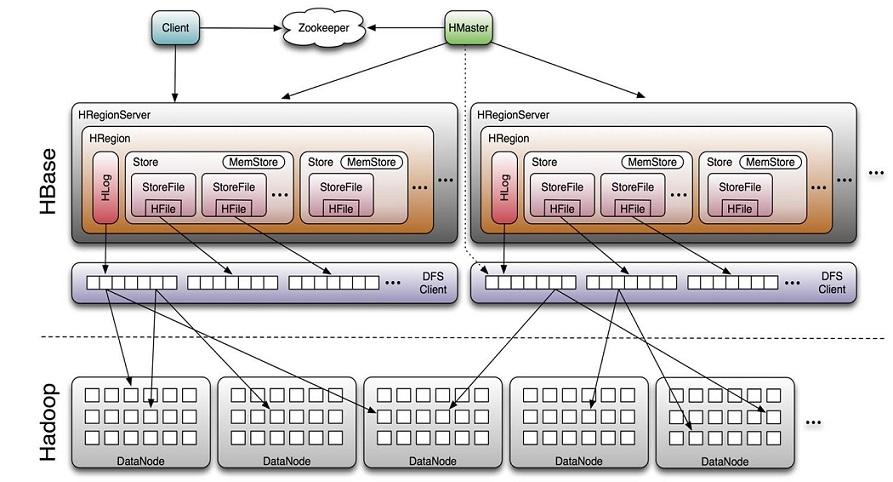
2. HBase vs 傳統關系型數據庫
| 特性 | HBase | 關系型數據庫 |
|---|---|---|
| 數據模型 | 列族模型 | 關系模型 |
| 數據規模 | PB級別 | GB/TB級別 |
| 數據類型 | Bytes | 豐富的數據類型 |
| 事務支持 | 單行事務 | 完整ACID事務 |
| 索引支持 | 主鍵索引 | 支持多種索引 |
| 查詢方式 | Get/Scan/Put | SQL |
| 擴展方式 | 水平擴展 | 垂直擴展為主 |
3. Docker環境搭建
3.1 單節點安裝
# 拉取鏡像
docker pull harisekhon/hbase
# 啟動容器
docker run -d \
--name hbase-standalone \
-p 2181:2181 \
-p 8080:8080 \
-p 8085:8085 \
-p 9090:9090 \
-p 16000:16000 \
-p 16010:16010 \
-p 16020:16020 \
harisekhon/hbase



3.2 驗證安裝
# 進入容器
docker exec -it hbase-standalone bash
# 啟動HBase Shell
hbase shell
# 驗證狀態
status
version
3.3 Mac本地安裝HBase
除了使用Docker安裝,我們還可以直接在Mac本地安裝HBase。以下是詳細步驟:
3.3.1 前置條件
- 安裝Homebrew
# 檢查是否已安裝Homebrew
brew --version
# 如果未安裝,執行以下命令安裝Homebrew
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"
- 確保Java環境
# 檢查Java版本
java -version
# 如果未安裝Java,使用Homebrew安裝
brew install java
# 配置Java環境變量(根據實際安裝路徑調整)
echo 'export JAVA_HOME=$(/usr/libexec/java_home)' >> ~/.zshrc
source ~/.zshrc
3.3.2 安裝HBase
- 使用Homebrew安裝HBase
brew install hbase

- 配置HBase
# HBase配置文件位置
cd /opt/homebrew/Cellar/hbase/2.6.2/libexec/conf
# 編輯hbase-site.xml
vim hbase-site.xml
配置文件內容:(配置一般是存在的,不用動)
<configuration>
<property>
<name>hbase.rootdir</name>
<value>file:///opt/homebrew/var/hbase</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/opt/homebrew/var/zookeeper</value>
</property>
<property>
<name>hbase.zookeeper.property.clientPort</name>
<value>2181</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>localhost</value>
</property>
</configuration>
3.3.3 啟動和停止HBase
- 啟動HBase
# 使用Homebrew服務啟動
brew services start hbase
# 或者直接啟動
/opt/homebrew/opt/hbase/bin/start-hbase.sh
- 停止HBase
# 使用Homebrew服務停止
brew services stop hbase
# 或者直接停止
/opt/homebrew/opt/hbase/bin/stop-hbase.sh

3.3.4 驗證安裝
- 啟動HBase Shell
hbase shell
- 測試基本命令
# 查看狀態
status
# 查看版本
version
# 查看所有表
list
3.3.5 常見問題解決
- 如果啟動HBase Shell時卡住
- 檢查HBase服務狀態:
brew services list | grep hbase - 重啟HBase服務:
brew services restart hbase - 檢查日志:
tail -f /opt/homebrew/var/log/hbase/hbase.log
- 端口沖突問題
- 檢查端口占用:
lsof -i:2181(ZooKeeper端口) - 檢查端口占用:
lsof -i:16000(HBase Master端口) - 修改配置文件中的端口設置
- 內存配置
- 編輯
/opt/homebrew/opt/hbase/libexec/conf/hbase-env.sh - 調整內存設置:
export HBASE_HEAPSIZE=4G
3.3.6 開發工具集成
- Java API使用
<!-- Maven依賴 -->
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>2.4.12</version>
</dependency>
- REST API訪問
- HBase REST服務默認端口:8080
- 啟動REST服務:
/opt/homebrew/opt/hbase/bin/hbase rest start - 訪問測試:
curl http://localhost:8080/version/cluster
4. HBase數據模型
4.1 核心概念
-
表(Table)
- HBase中數據的邏輯存儲單元
- 表由行和列組成
-
行鍵(Row Key)
- 每行數據的唯一標識
- 按字典順序排序
- 所有操作都基于行鍵
-
列族(Column Family)
- 表在物理上分割的單元
- 必須在創建表時定義
- 同一列族的數據存儲在一起
-
列限定符(Column Qualifier)
- 列族中的具體列
- 可以動態添加
- 格式:列族:列限定符
-
單元格(Cell)
- 由行鍵、列族、列限定符和時間戳唯一確定
- 存儲具體的數據值
-
時間戳(Timestamp)
- 每個單元格的版本號
- 默認為寫入時的系統時間
4.2 數據模型示例
讓我們通過一個用戶信息表的例子來理解HBase的數據模型:
- 表的基本結構
- 表名:
user_table - 包含兩個列族:
info和address info列族存儲基本信息(姓名、年齡、性別)address列族存儲地址信息(城市、國家)
- 數據存儲示例
表名: user_table
┌──────────┬───────────────────────────┬────────────────────┐
│ Row Key │ Column Family: info │ Column Family: add │
├──────────┼───────┬───────┬──────────┼─────────┬──────────┤
│ │ name │ age │ gender │ city │ country │
├──────────┼───────┼───────┼──────────┼─────────┼──────────┤
│ user1 │ Tom │ 25 │ male │ Beijing │ China │
│ user2 │ Jerry │ 30 │ female │ Shanghai│ China │
└──────────┴───────┴───────┴──────────┴─────────┴──────────┘
- 數據訪問方式
# 獲取user1的所有信息
get 'user_table', 'user1'
# 獲取user1的name信息
get 'user_table', 'user1', 'info:name'
# 獲取user1的城市信息
get 'user_table', 'user1', 'address:city'
- 數據模型解析
- Row Key(行鍵): 'user1', 'user2' 是每行數據的唯一標識
- Column Family(列族):
- 'info': 存儲個人基本信息
- 'address': 存儲地址相關信息
- Column Qualifier(列限定符):
- info列族下有:name, age, gender
- address列族下有:city, country
- Cell(單元格): 每個具體的值
- 例如:'Tom'是row key為'user1',列族'info'下的'name'列的值
- 實際存儲格式
Key Value
user1:info:name Tom
user1:info:age 25
user1:info:gender male
user1:address:city Beijing
user1:address:country China
user2:info:name Jerry
user2:info:age 30
user2:info:gender female
user2:address:city Shanghai
user2:address:country China
這種結構的優勢:
- 可以輕松添加新的列,不影響現有數據
- 不同行可以有不同的列
- 按列族物理存儲,適合針對特定列族的查詢
- 支持數據多版本(每個Cell可以有多個時間戳的值)
5. 基本操作命令
5.1 表操作
# 創建表
create 'user_table', 'info', 'address'
# 列出所有表
list
# 描述表結構
describe 'user_table'
# 禁用表(在刪除表之前必須先禁用)
disable 'user_table'
# 刪除表(只能刪除已經禁用的表)
drop 'user_table'
# 如果需要重新啟用表
enable 'user_table'
# 常見錯誤處理:
# 如果直接嘗試刪除啟用狀態的表,會得到錯誤:
# ERROR: Table user_table is enabled. Disable it first.
# 解決方法:先運行 disable 'user_table',然后再運行 drop 'user_table'

5.2 數據操作
# 插入數據
put 'user_table', 'user1', 'info:name', 'Tom'
put 'user_table', 'user1', 'info:age', '25'
put 'user_table', 'user1', 'address:city', 'Beijing'
# 查詢操作:get vs scan
# 1. get:獲取單行數據(精確查詢)
get 'user_table', 'user1' # 獲取整行數據
get 'user_table', 'user1', 'info:name' # 獲取特定列數據
# 2. scan:掃描表數據(范圍查詢)
scan 'user_table' # 掃描整個表
scan 'user_table', {LIMIT => 10} # 只掃描10行
scan 'user_table', {STARTROW => 'user1'} # 從user1開始掃描
scan 'user_table', {STARTROW => 'user1', STOPROW => 'user2'} # 掃描指定范圍
# get和scan的主要區別:
# - get:類似于關系數據庫的主鍵查詢,直接定位到特定行,性能較好
# - scan:類似于關系數據庫的表掃描,可以掃描整表或指定范圍的數據,可以添加過濾條件
# 刪除數據
delete 'user_table', 'user1', 'info:age' # 刪除特定列
deleteall 'user_table', 'user1' # 刪除整行
5.3 查詢性能比較
-
get 查詢
- 適用場景:知道確切的行鍵,需要獲取特定行的數據
- 性能特點:直接定位到行,速度快
- 使用方式:支持單行查詢和特定列的查詢
- 類似于:MySQL中的主鍵查詢
-
scan 查詢
- 適用場景:需要范圍查詢或滿足特定條件的數據
- 性能特點:需要掃描多行數據,相對較慢
- 使用方式:支持全表掃描、范圍掃描、條件過濾
- 類似于:MySQL中的表掃描或范圍查詢
-
scan 限制說明
- 默認限制:無行數限制,但建議不要一次掃描太多數據
- 性能影響:數據量太大會影響查詢性能和服務器負載
- 內存消耗:大量數據會占用大量內存
- 網絡帶寬:返回大量數據會占用大量網絡帶寬
-
scan 控制方法
# 使用LIMIT限制返回行數
scan 'user_table', {LIMIT => 1000} # 只返回1000行
# 使用STARTROW和STOPROW限制范圍
scan 'user_table', {STARTROW => 'user1', STOPROW => 'user2'}
# 使用TIMERANGE限制時間范圍
scan 'user_table', {TIMERANGE => [1588089600000, 1588176000000]}
# 使用FILTER限制結果
scan 'user_table', {FILTER => "ColumnPrefixFilter('name')"}
# 批量大小控制(每次RPC調用返回的行數)
scan 'user_table', {LIMIT => 1000, BATCH => 100} # 每次返回100行,總共返回1000行
-
scan 最佳實踐
- 建議使用LIMIT限制返回行數
- 盡量使用STARTROW和STOPROW限定范圍
- 只獲取需要的列(COLUMNS參數)
- 合理設置批量大小(BATCH參數)
- 添加適當的過濾條件
- 避免全表掃描
-
scan 性能優化示例
# 優化前(不推薦)
scan 'user_table' # 全表掃描
# 優化后(推薦)
scan 'user_table', {
STARTROW => 'user1',
STOPROW => 'user2',
COLUMNS => ['info:name', 'info:age'],
FILTER => "ValueFilter(=, 'binary:Tom')",
LIMIT => 1000,
BATCH => 100
}
6. 應用場景
-
大數據存儲場景
- 日志數據存儲
- 物聯網數據
- 時序數據
-
實時讀寫場景
- 實時推薦系統
- 實時計數器
- 消息系統
-
海量數據檢索
- 電商商品數據
- 用戶行為分析
- 社交數據存儲
7. 性能優化建議
-
行鍵設計優化
- 避免熱點問題
- 保持行鍵長度適中
- 根據查詢模式設計
-
預分區
- 合理的分區策略
- 避免數據傾斜
- 提高寫入性能
-
列族設計
- 控制列族數量(建議1-3個)
- 相關數據放在同一列族
- 合理設置存儲參數
-
內存優化
- 合理設置RegionServer內存
- 優化BlockCache配置
- 監控GC情況
8. 最佳實踐
- 數據建模
- 根據查詢模式設計表
- 避免過多列族
- 合理使用復合行鍵
8.1 數據建模實戰案例
8.1.1 電商訂單系統
# 不好的設計:使用隨機訂單ID作為行鍵
# 問題:無法高效查詢某用戶的訂單
create 'order_table', 'info'
put 'order_table', '123456', 'info:user_id', 'user001'
put 'order_table', '123456', 'info:create_time', '2024-03-28'
# 好的設計:復合行鍵(用戶ID + 時間 + 訂單ID)
# Row Key: userId_yearMonth_orderId
create 'order_table', 'info'
put 'order_table', 'user001_202403_000123', 'info:status', 'paid'
put 'order_table', 'user001_202403_000124', 'info:amount', '99.99'
# 查詢某用戶3月的訂單
scan 'order_table', {
STARTROW => 'user001_202403',
STOPROW => 'user001_202404'
}
8.1.2 日志系統
# Row Key: type_date_time_logId
create 'log_table', 'content'
# 寫入不同類型的日志
put 'log_table', 'ERROR_20240328101010_001', 'content:message', 'Connection failed'
put 'log_table', 'INFO_20240328101020_002', 'content:message', 'Server started'
# 查詢某天的錯誤日志
scan 'log_table', {
STARTROW => 'ERROR_20240328',
STOPROW => 'ERROR_20240329'
}
8.1.3 社交媒體消息系統
# 設計1:按時間查詢
# Row Key: timestamp_fromUser_toUser
create 'message_table', 'content'
put 'message_table', '20240328101010_user001_user002', 'content:text', 'Hello!'
# 設計2:按用戶關系查詢
# Row Key: fromUser_toUser_timestamp
create 'message_table', 'content'
put 'message_table', 'user001_user002_20240328101010', 'content:text', 'Hello!'
# 查詢用戶間的聊天記錄
scan 'message_table', {
STARTROW => 'user001_user002',
STOPROW => 'user001_user002_9999999999'
}
8.1.4 用戶行為分析系統
# Row Key: userId_behavior_timestamp
create 'user_behavior', 'action'
# 記錄用戶行為
put 'user_behavior', 'user001_click_20240328101010', 'action:page', 'home'
put 'user_behavior', 'user001_view_20240328101020', 'action:product', 'phone'
put 'user_behavior', 'user001_buy_20240328101030', 'action:product', 'phone'
# 查詢用戶的所有行為
scan 'user_behavior', {
STARTROW => 'user001_',
STOPROW => 'user001_z'
}
8.2 數據建模最佳實踐
-
行鍵設計原則
- 熱點數據分散:避免所有請求都訪問同一個區域
- 相關數據聚集:便于范圍查詢
- 長度適中:不要太長,建議在100字節以內
-
列族使用原則
- 保持列族數量少:建議2-3個
- 相關數據聚合:經常一起訪問的數據放在同一列族
- 訪問頻率分離:不同訪問頻率的數據放在不同列族
-
實用技巧
# 1. 使用分隔符區分行鍵各部分
user001:202403:order123 # 使用冒號分隔
# 2. 使用補零保證字典序
user001:20240328:00000123 # 訂單號補零
# 3. 使用時間戳的反轉值使最新數據排在前面
user001:99999999999-timestamp # 最新數據會排在前面
- 設計注意事項
- 根據實際查詢需求設計行鍵
- 避免使用過長的行鍵
- 合理使用時間戳
- 預估數據增長趨勢
- 考慮數據分布的均衡性
參考資源
結語
HBase作為一個強大的分布式數據庫系統,在大數據生態系統中扮演著重要角色。通過本文的學習,你應該已經掌握了HBase的基礎知識和使用方法。建議在實踐中多加練習,逐步深入理解HBase的各項特性。

 浙公網安備 33010602011771號
浙公網安備 33010602011771號