
Ubuntu上進行Zookeeper集群部署
1.zookeeper下載
版本無特別要求,一般最新穩定版即可。
這里給出3.8.4的下載鏈接。(點擊即可直接下載)
zookeeper官網:https://zookeeper.apache.org/
2.zookeeper安裝與使用
(0)!!! 在開始之前,確保你所有機器的用戶名相同,即hadoop@master、hadoop@salve01、hadoop@salve02 等,要確保@ 前的用戶名相同,避免后續不必要的錯誤
| 準備工作,所有機器上都要有 |
|---|
| 配置好hosts文件 |
| 安裝JAVA(盡量JDK8) |
| 安裝SSH |
| 所有機器上可以互相ping通 |
| master可以免密連接slave節點 |
| 用戶名都相同 |
(1)在自己電腦下載好zookeeper之后,粘貼到虛擬機的Downloads里,鼠標右鍵,點Paste即可粘貼。
注:打開左邊第二個圖標,打開之后點Downloads,再粘貼
(也可以復制鏈接到虛擬機的瀏覽器,直接在虛擬機下載,省的再復制粘貼)

(2)解壓文件、重命名、授權
sudo tar -zxvf ~/Downloads/apache-zookeeper-3.8.4-bin.tar.gz -C /usr/local
cd /usr/local
sudo mv ./apache-zookeeper-3.8.4-bin ./zookeeper //如果你的不是3.8.4,根據實際修改
sudo chown -R hadoop ./zookeeper
(3)配置環境變量
sudo vim ~/.bashrc
進入文件后,按上下方向鍵,翻到最后,插入下面語句(Ctrl+Shift+v 粘貼)
#Zookeeper
export ZOOKEEPER_HOME=/usr/local/zookeeper
export PATH=${ZOOKEEPER_HOME}/bin:$PATH
之后執行source ~/.bashrc 命令刷新環境變量,使配置生效。
(4)新建data和logs目錄(data目錄用來存放數據庫快照,logs目錄用來存放日志文件)
cd /usr/local/zookeeper
mkdir logs
mkdir data
注:logs目錄中的.out文件為運行日志,可以查看報錯信息
(5)配置文件zoo.cfg與myid
注:因為zookeeper使用的配置文件為
zoo.cfg,但是自帶的是zoo_sample.cfg模板文件,因此可以使用mv命令重命名,或者直接vim編寫新文件。

cd /usr/local/zookeeper/conf/
vim zoo.cfg
粘貼下列內容,之后根據自己的實際機器,修改最后幾行的內容
注:最后三行, = 后面的master、slave01名字等與hosts文件中配置的相同,即Hadoop@slave01,@后面的slave01.
# The number of milliseconds of each tick
# zookeeper時間配置中的基本單位 (毫秒)
# Zookeeper 服務器之間或客戶端與服務器之間維持心跳的時間間隔,單位為毫秒
tickTime=2000
# The number of ticks that the initial synchronization phase can take
# 允許follower初始化連接到leader最?時?,它表示tickTime時間倍數
# 表示允許從服務器連接到 leader 并完成數據同步的時間,總的時間長度就是 initLimit * tickTime 秒
initLimit=10
# The number of ticks that can pass between sending a request and getting an acknowledgement
# 允許follower與leader數據同步最?時?,它表示tickTime時間倍數
# 配置 Leader 與 Follower 之間發送消息、請求和應答時間長度,最長不能超過多少個 tickTime 的時間長度,總的時間長度就是 syncLimit * tickTime 秒
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just example sakes.
#zookeper 數據存儲?錄及?志保存?錄(如果沒有指明dataLogDir,則?志也保存在這個?件中)
# Zookeeper 保存數據的數據庫快照的位置
dataDir=/usr/local/zookeeper/data
# 事務日志路徑,若沒提供的話則用 dataDir
dataLogDir=/usr/local/zookeeper/logs
# the port at which the clients will connect
# Zookeeper 服務器監聽的端口,以接受客戶端的訪問請求
#對客戶端提供的端?號
clientPort=2181
# the maximum number of client connections.
# increase this if you need to handle more clients
# 限制連接到 ZK 上的客戶端數量,并且限制并發連接數量,值為 0 表示不做任何限制
#單個客戶端與zookeeper最?并發連接數
#maxClientCnxns=60
# Be sure to read the maintenance section of the administrator guide before turning on autopurge.
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
# The number of snapshots to retain in dataDir
# 自動清理日志,該參數設置保留多少個快照文件和對應的事務日志文件,默認為 3,如果小于 3 則自動調整為 3
# 保存的數據快照數量,之外的將會被清除
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#自動觸發清除任務時間間隔,?時為單位。默認為0,表示不?動清除。
#autopurge.purgeInterval=1
# server.n n是一個數字,表示這個是第幾號服務器,“=”后面可跟主機地址或者IP地址,2888為集群中從服務器(follower)連接到主服務器(leader)的端口,為主服務器(leader)使用;3888為進行選舉(leader)的時使用的端口
server.1=master:2888:3888
server.2=slave01:2888:3888
server.3=slave02:2888:3888
??再次提醒!!!集群部署,需要自行配置最后幾行的server,哪個機器需要zookeeper服務,就填哪個機器名。
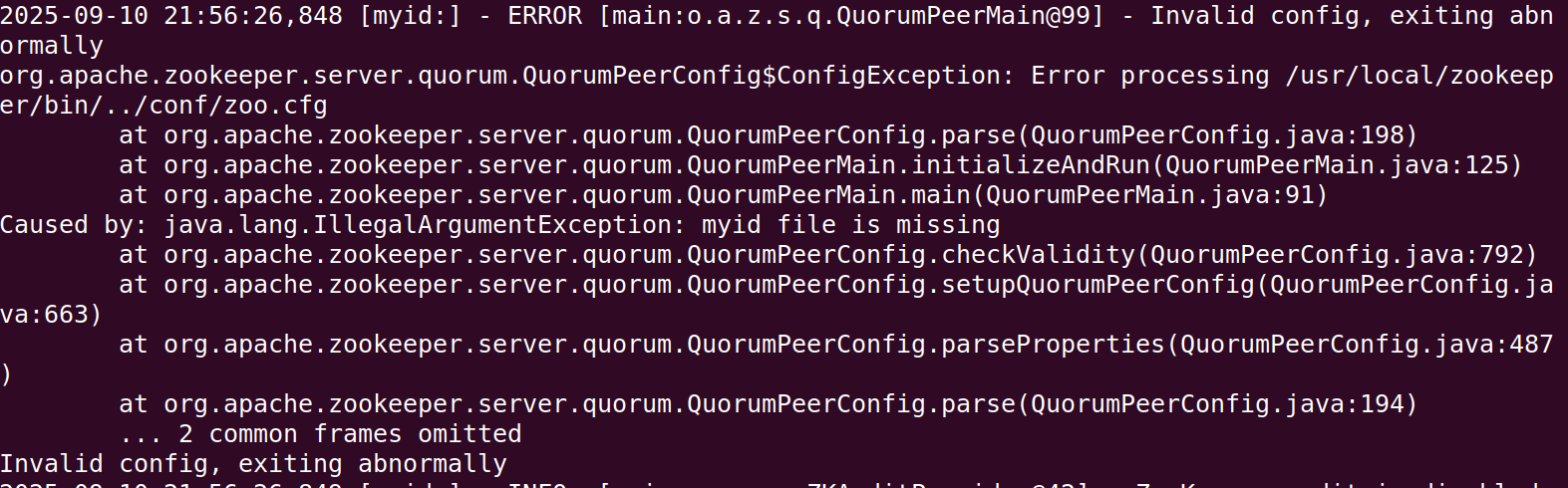
注1:配置文件時,注釋單獨一行寫,不能寫在參數后面,否則在解析時,會把注釋內容也識別為參數,導致報錯,日志內容如下

注2:配置文件時,
dataDir和dataLogDir的配置路徑,不要用環境變量來代替絕對路徑,例如dataDir=$ZOOKEEPER_HOME/data是錯誤的。 ZooKeeper 的配置文件(zoo.cfg)本身不支持解析環境變量(如$ZOOKEEPER_HOME),會把它當作普通字符串處理,導致無法正確識別路徑。導致報錯,日志內容如下
(6)壓縮文件,并發送到其他機器上
cd /usr/local
tar -zcvf ~/zookeeper.tar.gz ./zookeeper/
scp ~/zookeeper.tar.gz hadoop@slave01:/home/hadoop/
scp ~/zookeeper.tar.gz hadoop@slave02:/home/hadoop/
(7)在slave01和slave02進行解壓縮,并配置環境變量
sudo tar -zxvf ~/zookeeper.tar.gz -C /usr/local/
sudo vim ~/.bashrc
粘貼下面的環境變量
#Zookeeper
export ZOOKEEPER_HOME=/usr/local/zookeeper
export PATH=${ZOOKEEPER_HOME}/bin:$PATH
之后執行source ~/.bashrc 命令刷新環境變量,使配置生效。
(8)配置myid文件(所有機器上都要做,包括master、slave)
vim /usr/local/zookeeper/data/myid
myid填寫數字,就是zoo.cfg文件中填寫的主機名前的數字。只填一個數字就行。


(9)常用命令
zkServer.sh start //啟動zookeeper
zkServer.sh stop //停止zookeeper
zkServer.sh status //查看zookeeper運行狀態(至少啟動兩個節點再去查看,不然選舉失敗,狀態也是不正常)
zkServer.sh version //查看zookeeper版本
zkServer.sh restart //重啟zookeeper
zookeeper客戶端:
zkCli.sh //進入zookeeper客戶端
quit //退出客戶端
deleteall //刪除文件夾及其子文件夾(例:deleteall /hbase)
3.zookeeper啟動
在每個機器上都單獨輸入 zkServer.sh start ,來啟動zookeeper。
至少啟動兩個,然后輸入zkServer.sh status 查看啟動狀態。
注:Hmaster與leader不在同一機器上,是正常現象。實際生產環境中,甚至會刻意將 HMaster 和 ZooKeeper Leader 部署在不同機器。
- 避免 “單點故障放大”
如果二者在同一臺機器,一旦該機器宕機,會同時導致 HBase 失去主管理節點、ZooKeeper 集群失去 Leader(需重新選舉),雙重故障會大幅延長集群恢復時間;分開部署則只會影響單一組件,風險更可控。 - 減少資源競爭
HMaster 需處理 HBase 的 Region 分配、元數據更新等計算;ZooKeeper Leader 需處理大量分布式鎖請求(如 HBase 依賴 ZooKeeper 實現 Master 選舉、RegionServer 心跳)。二者分開部署可避免 CPU、內存、網絡資源的相互搶占,提升各自性能。 - 符合 “組件解耦” 設計
分布式架構的核心原則是 “組件解耦”,HBase 本身就是依賴 ZooKeeper 提供的分布式協調能力(而非依賴其物理節點),只要 HMaster 能通過網絡正常連接 ZooKeeper 集群(配置hbase.zookeeper.quorum指向 ZooKeeper 集群地址),就無需關心 ZooKeeper Leader 具體在哪臺機器。
示例如下
master節點

slave01節點

slave02節點

4.zookeeper是什么?為什么要用它?為什么不用Hbase自帶的?
(1)ZooKeeper 是一款開源的分布式協調服務,核心作用是幫分布式系統(由多個獨立服務組成的系統)解決配置同步、節點管理、分布式鎖等協調問題,讓系統運行更穩定、有序。
(2)
- 分布式數據庫 HBase 用它管理集群節點 ——ZooKeeper 實時監控 HBase 的主節點(Master)和從節點(RegionServer)狀態,若主節點故障,能快速從備用節點中選新主節點,避免數據庫服務中斷;
- 電商秒殺場景中,多個服務同時搶庫存易超賣,此時用 ZooKeeper 實現 “分布式鎖”—— 同一時間只允許一個服務操作庫存,確保庫存數據準確。
可以類似于:學校運動會的總調度員”:
學校運動會有多個項目(對應分布式系統里的多個服務),每個項目需要知道比賽時間、場地安排(對應服務需要的配置信息),還要避免不同項目搶同一跑道(對應服務搶同一資源),且得實時掌握每個項目是否正常進行(對應監控服務節點狀態)。
這時總調度員(ZooKeeper)的作用就是:提前把統一的賽程表(配置)發給所有項目組,協調好各項目的場地使用(分布式鎖),一旦某個項目出問題(比如裁判缺席),立刻通知替補人員頂上(節點故障切換),確保整個運動會(分布式系統)不混亂、不中斷。
(3)HBase 自帶 ZooKeeper與獨立zookeeper的區別
簡單來說就是單獨的zookeeper更加靈活、高效、安全
| 對比維度 | HBase 自帶 ZooKeeper | 單獨的 ZooKeeper |
|---|---|---|
| 部署與維護成本 | 低:無需單獨下載部署,依賴 HBase 腳本啟動 / 停止,配置簡化(僅需在 HBase 配置文件中指定 ZooKeeper 參數)。 | 高:需單獨下載、配置(如zoo.cfg)、啟動,需獨立監控和運維,新增組件學習成本。 |
| 獨立性與生命周期 | 弱綁定:ZooKeeper 隨 HBase 啟動而啟動、隨 HBase 停止而停止,無法單獨重啟或升級;HBase 故障可能直接影響 ZooKeeper。 | 完全獨立:ZooKeeper 可單獨啟動、停止、升級,生命周期與 HBase 無關;HBase 重啟 / 故障不影響 ZooKeeper 運行。 |
| 擴展性 | 有限:僅支持單機模式或小規模偽集群(默認不支持 ZooKeeper 集群,需手動修改配置但兼容性差),無法滿足大規模集群需求。 | 靈活:支持單機、偽集群、完全分布式集群(3 + 節點,滿足高可用),可根據業務規模擴容 ZooKeeper 節點。 |
| 穩定性與可靠性 | 較低:ZooKeeper 與 HBase 共享資源(CPU、內存、磁盤),HBase 高負載時可能導致 ZooKeeper 響應緩慢;無獨立監控,故障排查困難。 | 較高:資源隔離(獨立服務器 / 容器),避免 HBase 負載影響;可單獨配置監控(如 Zabbix、Prometheus),故障定位更高效。 |
| 多組件兼容性 | 差:僅為 HBase 服務,無法被其他分布式組件(如 Kafka、Spark)復用,導致集群中存在多個 “孤立” ZooKeeper 實例,資源浪費且管理復雜。 | 好:可作為 “全局協調服務”,為 HBase、Hadoop、Kafka 等多個組件提供統一協調,減少資源冗余,簡化集群管理。 |
| 版本與升級靈活性 | 低:ZooKeeper 版本與 HBase 綁定(如 HBase 2.5.0 默認自帶 ZooKeeper 3.5.9),升級 ZooKeeper 需先升級 HBase,無法單獨適配高版本 ZooKeeper 的新特性(如動態配置)。 | 高:ZooKeeper 版本可獨立選擇(需與 HBase 兼容,如 HBase 2.x 支持 ZooKeeper 3.4.x/3.5.x),可單獨升級 ZooKeeper,無需依賴 HBase 版本迭代。 |
| 適用場景 | 小規模測試、開發環境、單機偽集群(追求快速搭建,無需高可用)。 | 生產環境、大規模 HBase 集群、多組件協同的分布式集群(需高可用、穩定性和擴展性)。 |

 浙公網安備 33010602011771號
浙公網安備 33010602011771號