
吳恩達深度學習課程二: 改善深層神經網絡 第一周:深度學習的實踐(四)其他緩解過擬合的方法
此分類用于記錄吳恩達深度學習課程的學習筆記。
課程相關信息鏈接如下:
- 原課程視頻鏈接:[雙語字幕]吳恩達深度學習deeplearning.ai
- github課程資料,含課件與筆記:吳恩達深度學習教學資料
- 課程配套練習(中英)與答案:吳恩達深度學習課后習題與答案
本篇為第二課第一周,1.8的內容。
本周為第二課的第一周內容,就像課題名稱一樣,本周更偏向于深度學習實踐中出現的問題和概念,在有了第一課的機器學習和數學基礎后,可以說,在理解上對本周的內容不會存在什么難度。
當然,我也會對一些新出現的概念補充一些基礎內容來幫助理解,在有之前基礎的情況下,按部就班即可對本周內容有較好的掌握。
本篇繼續上篇的內容,在完成正則化部分后,再補充一些課程里提到的其他緩解過擬合的方法。
1.數據增強
之前提到解決過擬合最好的方法就是增加數據量,但受限于各個方面有時獲取新數據并不容易。
因此,就出現了數據增強,數據增強并不是引入新數據,而是以一些方式增強現有數據,到達“豐富數據集”的效果。
什么方式?看一眼就明白了:
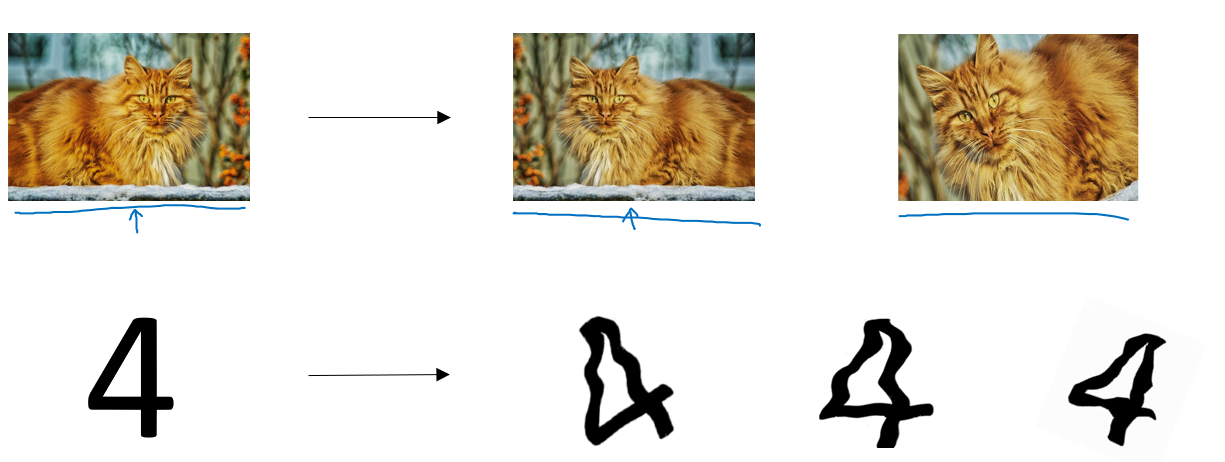
我們可以對圖像進行翻轉、裁剪、旋轉、模糊、亮度變化等處理。雖然這些樣本并沒有提供全新的信息,但它們能讓模型學習到更廣泛的特征變化。
這樣的操作看起來有些取巧,但也確實能做到一些查漏補缺,配合正則化有時能實現不錯的效果。
簡單舉個例子:上圖里的貓,我們對其處理后并不能提供太多新信息,從高維上講,模型依舊擬合的是橘貓的模樣,但是反轉,裁剪后,我們可以改變貓頭的位置,在圖中的比例。或者在模糊后訓練模型的“視力”。模型可以學會識別“同一類目標在不同條件下的表現”,起到豐富低維特征的作用。
要強調一點的是,課程中提到,數據增強也可以被稱為一種正則化方法。
2.早停(early stopping)
我們再回顧一下過擬合,在訓練神經網絡時,我們常常會遇到這樣一種現象:
模型在訓練集上的損失不斷下降,但在驗證集上的性能卻在某個時刻開始變差——也就是說,模型開始記住訓練數據的噪聲,出現了過擬合。
“早停”正是針對這一問題的一種簡單而有效的策略。
早停的核心思想是:當模型在驗證集上的表現不再提升時,就提前停止訓練,而不是一味追求訓練損失的最小化。
換句話說,我們不讓模型在訓練集上“學得太好”,而是在它剛開始出現過擬合的拐點提前終止,讓模型保持在一個“泛化性能最好”的狀態。
通常的做法是:
- 在每一輪(epoch)訓練后,計算模型在驗證集上的損失;
- 如果驗證集損失在連續若干輪(稱為耐心值 patience)中沒有顯著改善,就停止訓練;
- 最后保留驗證集效果最好的那一輪的模型參數。
如圖所示:
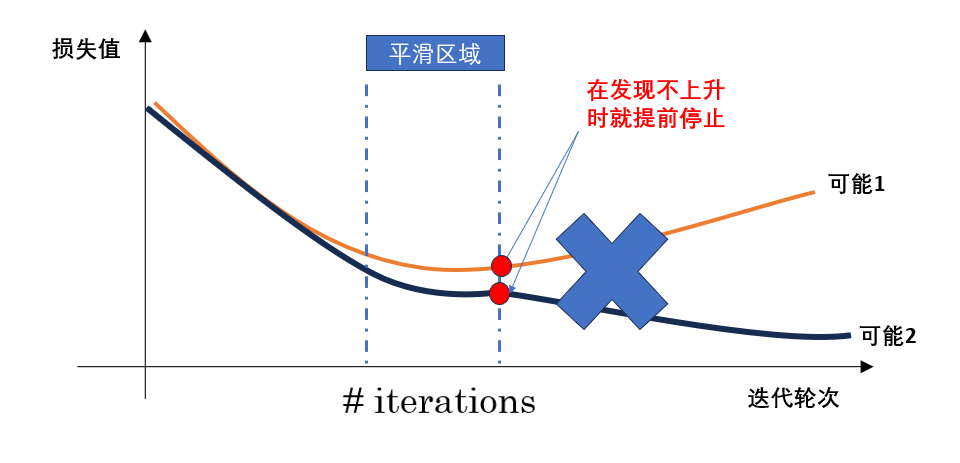
總的來說,早停的優點在于它能在驗證集性能開始下降前及時停止訓練,從而有效防止過擬合,并節省訓練時間;實現起來也十分簡單。
但它也有不足——如果停止得太早或驗證集波動較大,模型可能還沒學到足夠的特征就被迫中斷,導致欠擬合;同時,早停依賴驗證集的表現,可能帶來一定的不穩定性。
本篇內容不多,加上前兩篇,這部分內容總結了一些幫助緩解過擬合的方法,涉及到一些新的概念,因此花費了一些篇幅來幫助理解,之后的內容在理解上的難度就沒有這部分高了,進度也會快一些。

 浙公網安備 33010602011771號
浙公網安備 33010602011771號