
吳恩達深度學習課程二: 改善深層神經網絡 第一周:深度學習的實踐(三)dropout正則化
此分類用于記錄吳恩達深度學習課程的學習筆記。
課程相關信息鏈接如下:
- 原課程視頻鏈接:[雙語字幕]吳恩達深度學習deeplearning.ai
- github課程資料,含課件與筆記:吳恩達深度學習教學資料
- 課程配套練習(中英)與答案:吳恩達深度學習課后習題與答案
本周為第二課的第一周內容,就像課題名稱一樣,本周更偏向于深度學習實踐中出現的問題和概念,在有了第一課的機器學習和數學基礎后,可以說,在理解上對本周的內容不會存在什么難度。
當然,我也會對一些新出現的概念補充一些基礎內容來幫助理解,在有之前基礎的情況下,按部就班即可對本周內容有較好的掌握。
本篇繼續上篇的內容,介紹dropout 正則化。
1. dropout 正則化
1.1 原理介紹
Dropout(隨機失活)是一種在訓練過程中隨機“丟棄”部分神經元的正則化方法。
它的核心思想是:在每次訓練迭代時,隨機讓一部分神經元暫時不參與前向傳播和反向傳播,從而防止網絡過度依賴某些特定節點。
通俗地講,就是在每次迭代時,會隨機出現“修路”情況來關閉一些神經元,避免模型“太喜歡某條常走的彎路”,嘗試多條路徑,從而增強泛化能力,就像這樣:
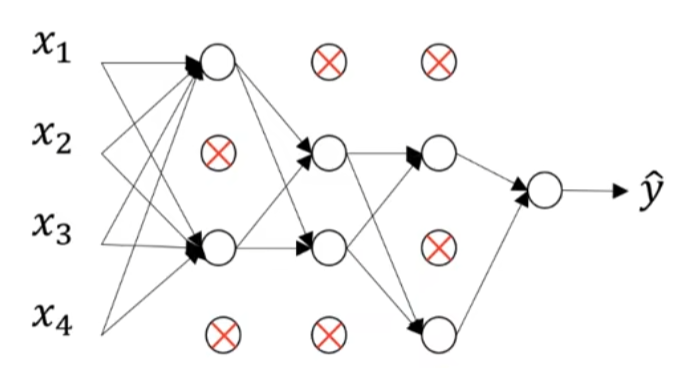
在數學上,設一個隱藏層的輸出為 \(A^{[l]}\),那么 Dropout 的過程可表示為:
其中:
- \(D^{[l]}\) 是一個與 \(A^{[l]}\) 形狀相同的隨機掩碼矩陣;
- \(keep_{prob}\) 是保留神經元的概率;
- 除以 \(keep_{prob}\) 是為了保持整體激活期望一致(防止數值偏移)。
別慌,這幾個公式堆在一起看起來確實挺嚇人,我們同樣展開一些需要理解的內容:
(1)什么叫隨機掩碼矩陣?
“隨機掩碼矩陣”其實就是一張決定誰能“上場”的隨機名單表。
在每一輪訓練中,rand(A.shape) 會生成一個介于 0~1 的隨機矩陣,如果某個位置的隨機數小于 \(keep_{prob}\) ,那對應的神經元就被“保留”,否則就被“屏蔽”。
用一個實例來說明:假設我們有一個隱藏層輸出:
現在,我們設置保留概率 \(keep_{prob} = 0.5\),然后隨機生成:
于是更新后的輸出就是:
這就表示——在這一輪訓練中,第 2 和第 4 個神經元被“臨時關閉”。
它們既不會參與當前的前向傳播,也不會計算梯度更新。
換句話說,每一輪上場的神經元陣容都不同, 有時候 1、3 上,有時候 2、4 上,像在打輪換賽。
(2)保持整體激活期望一致是什么意思?
由于每次訓練時有一部分神經元被“關掉”,如果不做任何處理,剩下神經元的輸出總量就會變小。
這會導致模型的數值分布發生偏移,訓練和測試階段的行為不一致。
這句話是什么意思?什么叫偏移?怎么就不一致了? 我們來詳細解釋一下:
在訓練階段,我們啟用 Dropout——每一輪隨機關閉一部分神經元;
而在測試階段,我們不再丟棄神經元,希望所有連接都參與計算。
因此,如果不做“除以 \(keep_{prob}\)”的調整,訓練時網絡看到的激活值較小,而測試時所有神經元都激活,信號強度會突然變大。
打個比方,這就相當于:
模型在訓練時習慣了“音量 50%”,但一到測試就被拉成“音量 100%”, 結果預測結果可能大幅波動,這就是所謂的分布偏移(distribution shift)
即同樣的輸入數據,在訓練和測試時,網絡的激活分布不一樣,表現出不同的“行為模式”。
而調整的目的就是:讓訓練時的信號強度和測試時一致,這樣模型在上場時才不會突然音量上升而不適應。
我們繼續用上面的例子:
原來的激活平均值為:
Dropout 之后(關掉一半神經元):
平均值直接變小很多,這會讓網絡誤以為“信號整體變弱”,從而影響學習。
所以我們把輸出除以保留概率:
這時平均值恢復到:
雖然不完全相等,但數量級一致,期望保持平衡。
換成人話就是: 雖然有一半神經元請假了,但留下來的要多干一倍活,這樣團隊輸出不變。(難繃)
(3)為什么這么“隨機”的機制能起作用?
隨機丟棄神經元,會讓網絡在每次訓練中都看到一個不同的子網絡。
于是整個訓練過程,就像在同時訓練一大群共享參數的小網絡。
最終,當我們在測試時把所有神經元都打開,網絡的行為就相當于這些小網絡預測結果的集成平均。
因此,Dropout 能顯著提升模型的穩健性,減少過擬合。
就像一個團隊經過無數次不同組合的演練, 最終每個人都能獨當一面,不再依賴特定搭檔。
總之,dropout正則化就是每次訓練都會讓網絡“瘦身”,但每次瘦的部分不同。
這樣,網絡學到的不是一條固定通路,而是多條冗余且穩健的特征路徑。
1.2 “人話版總結”
可以把神經網絡想成一張復雜的城市路網,每條“路”就是一條神經元之間的連接。
在沒有正則化時,模型總喜歡走幾條特別順暢的“老路”,久而久之就太依賴這些路線了。
一旦測試階段路況稍有不同(數據分布變化),模型就會懵,因為它從來沒學會走別的路。
而 Dropout 做的事,就是在每次訓練時——
隨機封幾條路去維修,讓模型被迫換條路走。
久而久之,模型就能適應多種交通方案,學會多條“通往目的地”的路徑。
等到測試階段,所有道路都重新開放,模型就像整個城市的交通系統都訓練有素:
不管哪條路通,都能通向正確的結果。
這也就是 Dropout 提升模型泛化能力的根本原因。
| 類型 | 內容 | 形象比喻 |
|---|---|---|
| 優點 | 1. 有效防止過擬合,讓模型不過度依賴特定神經元。2. 提高模型的魯棒性(穩健性),相當于訓練了多個“子網絡”的集成效果。3. 在一定程度上還能起到特征選擇作用,讓網絡更“均衡”地使用不同特征。 | 修路讓模型學會多條路線,不怕某條主路堵車。 |
| 缺點 | 1. 訓練時間變長(因為每次激活模式不同,收斂更慢)。2. 不適合用于推理階段,測試時必須關閉 Dropout。3. 如果 \(keep_{prob}\) 過低,會導致模型學習信號太弱,出現欠擬合。 | 修太多路,車都走不動了;修太少路,又起不到練兵效果。 |
2. 應用正則化和調節學習率的關系?
在上一篇的結尾,我們提出了這樣一個問題:應用正則化和直接調節學習率有什么不同呢?
詳細點說:
既然正則化最終是要影響參數的大小,那我是不是調一調學習率也能達到類似的效果?
要回答這個問題,我們先分別看看二者到底在干什么。
2.1 學習率:決定“走多快”
學習率 \(\alpha\) 是梯度下降中最直觀的參數。
它控制著模型在參數空間中更新的步伐大小:
- 學習率太大:模型可能“邁太大步”,直接越過最優點,甚至震蕩發散。
- 學習率太小:模型每次只挪一點點,訓練速度慢到令人發瘋。
通俗地講:學習率決定你“往山谷底走的步子多大”。
太大了會一腳踩空;太小了磨到天荒地老。
2.2 正則化:決定“走哪條路”
正則化并不是控制你“走得快不快”,而是在梯度更新時施加一種施加一種特定的影響力。
以 L2 正則化為例,參數更新公式是:
可以看出:
- \(\frac{\lambda}{m}W\) 這一項,會在每次更新時把權重往 0 拉一點;
- 它的目的不是減慢步伐,而是修正方向——讓參數不至于“長歪”。
Dropout也是同理, 就像在訓練道路上隨機設置一些坑洞,讓車手學會繞過,而不是死死踩同一條路,它并不減慢你的油門(學習率依然決定速度),而是防止模型走到“捷徑陷阱”,學得太偏。
通俗地說:學習率是油門,正則化是方向盤。
學習率太大,車容易沖出路,沒有正則化,車會偏離中心線。
這里我用GPT畫了一張圖,或許能幫助記憶:

2.3 總結
| 對比項 | 學習率調節 | 正則化(L2 / Dropout) |
|---|---|---|
| 目的 | 控制參數更新的速度 | 控制參數更新的方向與幅度,使其不過大,或防止過擬合 |
| 影響階段 | 優化器(梯度下降) | 損失函數(多加一項懲罰)或訓練策略(Dropout) |
| 公式體現 | \(W := W - \alpha dW\) | \(W := W - \alpha (dW + \frac{\lambda}{m}W)\) 或隨機丟掉部分神經元 |
| 形象比喻 | 決定“走多快” | 決定“往哪走”,Dropout 讓車手學會繞開陷阱 |
| 錯誤調節后果 | 步子太大,震蕩不收斂;太小,訓練緩慢 | 懲罰太強,模型太簡單(欠擬合);太弱,模型太復雜(過擬合);Dropout 太大,模型收斂慢 |
| 交互影響 | 學習率越大,懲罰效果越顯著;兩者需協調 | 一般配合調節,防止權重過大或收斂太慢 |
總之,學習率與正則化是互補的,而不是替代關系。
一個決定“快慢”,一個決定“方向和穩健性”;
只有搭配得當,模型才能又快又穩地收斂到合理的最優點。
對正則化的介紹暫時就到此為止,下一篇會簡要介紹一些其他幫助緩解過擬合的方法,說實話,有些方法甚至會給我們一種“耍小聰明”的感覺。

 浙公網安備 33010602011771號
浙公網安備 33010602011771號