
吳恩達深度學習課程一:神經網絡和深度學習 第三周:淺層神經網絡(三)初始化
此分類用于記錄吳恩達深度學習課程的學習筆記。
課程相關信息鏈接如下:
- 原課程視頻鏈接:[雙語字幕]吳恩達深度學習deeplearning.ai
- github課程資料,含課件與筆記:吳恩達深度學習教學資料
- 課程配套練習(中英)與答案:吳恩達深度學習課后習題與答案
本篇為第一課第三周,3.11部分的筆記內容,同時也是本周理論部分的最后一篇。
經過第二周的基礎補充,本周內容的理解難度可以說有了很大的降低,主要是從邏輯回歸擴展到淺層神經網絡,講解相關內容,我們按部就班梳理課程內容即可,當然,依舊會盡可能地創造一個較為絲滑的理解過程。
上一篇通過展開講述激活函數的作用,并再次過了一遍淺層神經網絡的傳播過程,來說明淺層神經網絡如何提高擬合能力,本篇則補上最后一塊拼圖,同時也是本周理論部分的最后一篇。
在這周的例子里,我們設置神經網絡隱藏層的神經元為四個,輸出層的神經元再綜合四個神經元的輸出結果計算最終的輸出,那隱藏層神經元的數量增加后,又是如何發揮正向的作用呢?
我們知道每個神經元都有自己的參數,我們通過不斷訓練參數達到擬合效果,如何讓每個神經元都真的對擬合起到幫助作用,就是本篇的內容:隨機初始化
1. 什么是初始化
在訓練神經網絡之前,我們并不知道哪些參數(權重 \(W\) 和偏置 \(b\))是最好的,因此需要先給它們一個“起始值”,這個過程就叫做初始化。
這些初始值相當于我們在參數空間中的“出發點”,之后通過梯度下降不斷調整,逐步逼近損失函數的最小值。
簡單來說,就是賦初值。
2. 為什么要隨機初始化
在邏輯回歸中,我們并不強調初始化內容,這是因為整個網絡只有一層線性組合與其相關的參數,我們的所有操作都是在更新這一組參數,因此,把這組參數初始化成什么樣,并不算一個需要思考的地方,因為這組參數最終都會隨著更新讓損失達到最低點。
而現在,我們在隱藏層設置四個神經元,如果所有參數一開始都設為同一個值(例如全為 0),會出現一個非常嚴重的問題,我們看這樣一個過程:
- 每個隱藏層神經元收到的輸入一樣;
- 計算得到的中間結果也完全一樣;
- 反向傳播時梯度也一樣;
- 于是所有神經元更新后的參數依舊完全相同;
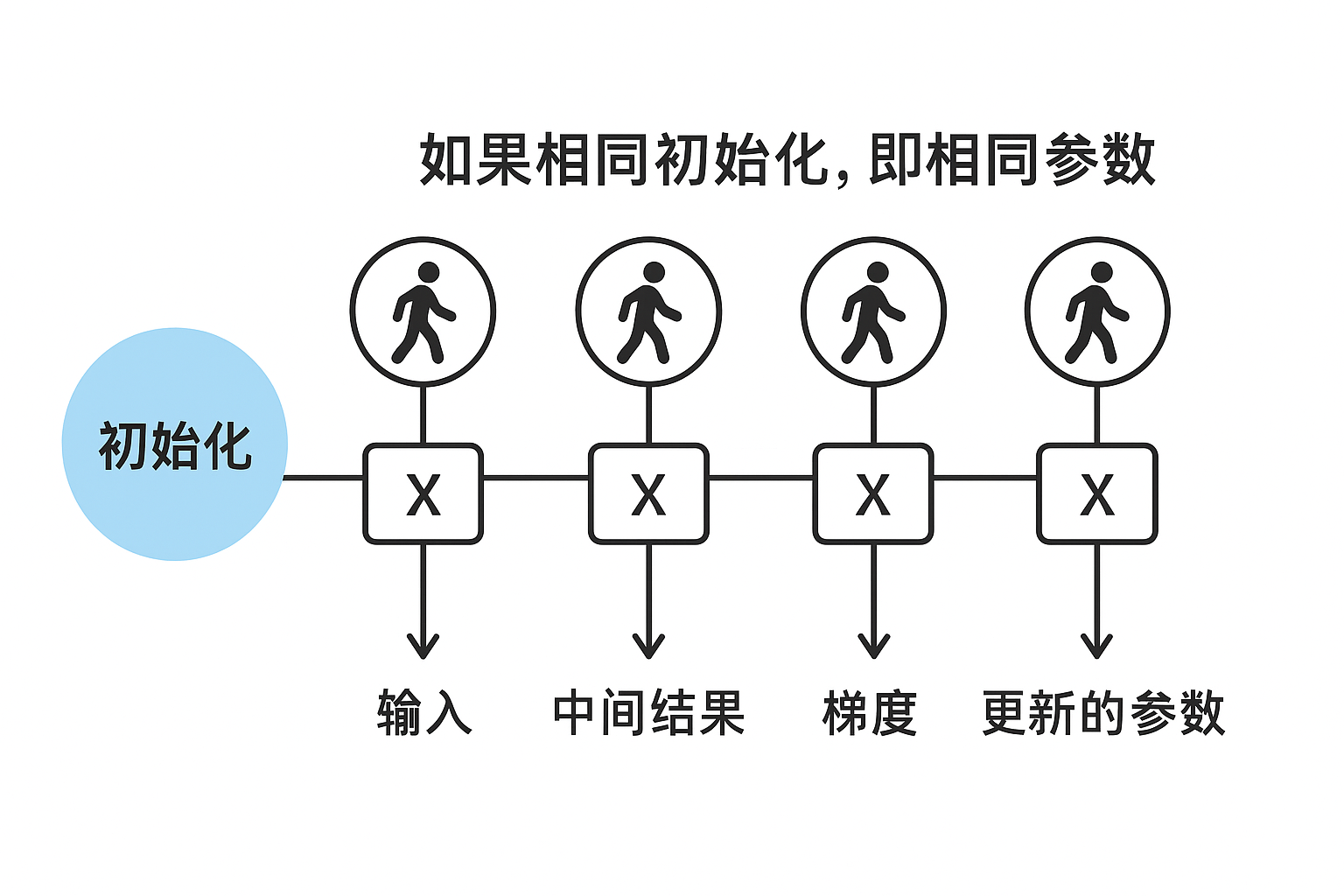
這樣訓練下去,即使我們設置了很多神經元,它們都在“做同樣的事情”,模型就退化成只有一個神經元的效果。用專業術語來說,這叫對稱性問題(Symmetry Problem)。
而解決辦法就是在初始化時給每個神經元賦予一個不同的隨機初始權重,打破對稱性,讓它們在訓練過程中各自朝不同方向學習。
3.損失的凸與非凸問題
我們說邏輯回歸不存在對稱性問題,還有另外一個關鍵原因:它的損失函數是凸函數。
在第二周第四部分我們講過,凸函數具有一個非常重要的特性:全局范圍內只有一個最低點(全局最小值)。
這意味著:無論參數從哪里初始化, 只要我們沿著梯度下降方向不斷更新參數,最終都會收斂到同一個最優點。
因此即使初始化相同,甚至初始化為 0,也不會導致模型陷入“學不動”或者“神經元行為完全一樣”的問題,如下圖所示:
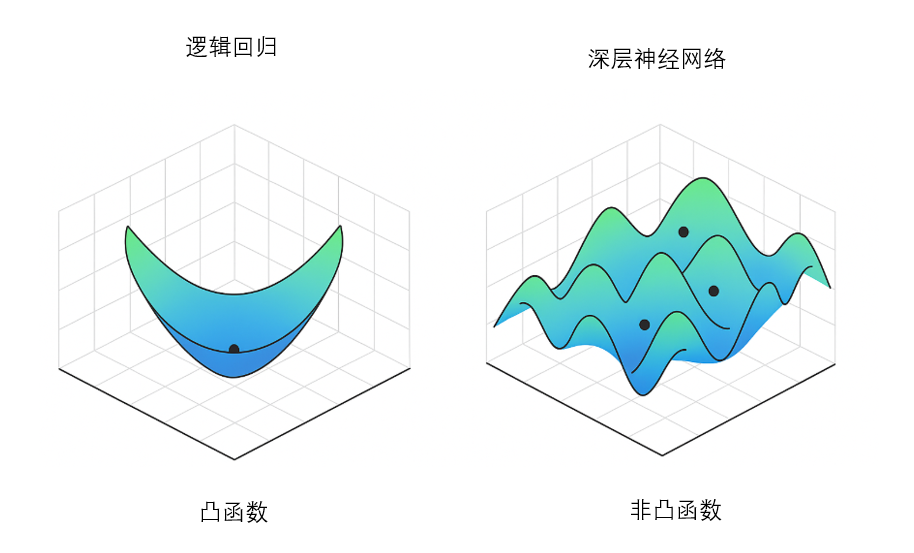
但當我們從邏輯回歸(單一線性變換)擴展為神經網絡(包含隱藏層、激活函數、多個權重矩陣)時,經過無數函數的相乘,損失函數就不再是一個光滑的碗形函數,而變成了一個復雜的山地地形。
有無數個山峰(局部最大值)、山谷(局部最小值)、鞍點(既不是峰也不是谷)。
此時,損失函數不是凸函數,而是非凸的。
因此,我們才需要隨機初始化不同的神經元,來不斷探索損失函數的最小值。
4.舉例類比隨機初始化的作用
我們依舊用山坡來舉例:
現在,我們派 4 個登山者去尋找一片山地的最低點(損失函數的最小值):
| 情況 | 結果 |
|---|---|
| 所有人從同一個山頂出發(全零初始化) | 大家看到的坡度一樣,朝同一個方向走,走的路徑重疊,只等于一個人找路,效率極低。 |
| 每個人從不同位置出發(隨機初始化) | 各自看到的坡度不一樣,探索方向不同,更可能有人找到更低的谷底(更優解)。 |
因此,隨機初始化就是給每個神經元一個不同的出發點,讓它們探索不同的優化空間。
5. 權重的隨機初始化
在神經網絡中,隱藏層的每個神經元都擁有屬于自己的權重參數 \(W\) 和偏置 \(b\)。
如果我們把所有權重都初始化為相同的值,就會造成一個嚴重的問題:對稱性永遠無法被打破,所有神經元的行為完全一樣,網絡就失去了“多神經元協作學習”的意義。
因此,我們需要為每一個權重賦予一個隨機的初始值,這就叫做權重隨機初始化。
它并不是讓權重變得“亂七八糟”,而是把它們設定在一個很小且隨機的范圍內,例如:
這樣,就可以打破對稱性,實現多個隱藏神經元探索多個不同方向的效果。
而對于權重的隨機初始化,也有一些科學的初始化算法,我們遇到再說。
6. 偏置的初始化
與權重不同,偏置 \(b\) 一般不需要隨機初始化,而是直接初始化為 0 或一個很小的常數。
這是因為偏置項不會造成之前提到的“對稱性問題”,它作為一個常數,只是簡單地把激活函數的輸入整體向左或向右平移,不會影響神經元之間是否相同。
因此,在權重已經隨機初始化實現了打亂效果后,我們便不會把過多的算法性能浪費在偏置上。
總結
這便是本周課程的最后一部分內容,相比第二周需要較多的基礎補充,本周其實只是實現了從邏輯回歸到淺層神經網絡的擴展,了解了神經網絡規模增加是如何幫助擬合的。
下一篇的內容便是本周的課后習題和代碼實踐,我們用實操來感受一下帶隱藏層的神經網絡相比邏輯回歸帶來的性能提升。

 浙公網安備 33010602011771號
浙公網安備 33010602011771號