
吳恩達深度學習課程一:神經網絡和深度學習 第一周:深度學習簡介
此分類用于記錄吳恩達深度學習課程的學習筆記。
課程相關信息鏈接如下:
- 原課程視頻鏈接:[雙語字幕]吳恩達深度學習deeplearning.ai
- github課程資料,含課件與筆記:吳恩達深度學習教學資料
- 課程配套練習(中英)與答案:吳恩達深度學習課后習題與答案
1.課程內容
第一周的內容較為簡單,并不涉及具體實操,其地位相當于教材中的緒論部分,簡單介紹了神經網絡(Neural Network,NN)和深度學習(Deep Learning,DL)相關的基本概念,優勢與課程計劃等內容。
因此,總結本章內容時會省去課程介紹部分,并添加相當一部分的基礎知識以便理解。
1.1 什么是神經網絡?
課程中并未照本宣科地給出神經網絡的定義,而是通過預測房價的例子來理解神經網絡。
這里先給出網絡中對神經網絡的一種闡述:
神經網絡是受生物神經系統啟發而設計的計算模型,旨在模擬人腦的工作方式,用于解決復雜的模式識別和學習問題。它由多個節點(也叫神經元)構成,這些節點按照不同的層級(輸入層、隱藏層、輸出層)組織,通過加權連接相互連接。神經網絡的核心思想是通過訓練過程調整這些連接的權重,以最小化預測輸出與實際結果之間的誤差,從而使模型能夠在新數據上進行準確的預測和分類。
我們抓住重點,即神經網絡由神經元組成,要了解什么是神經網絡,先要了解什么是神經元。
同樣先給出神經元的一種闡述:
神經元是神經網絡的基本計算單元,接收輸入信號,加權求和后添加偏置,再通過激活函數輸出結果。
我們通過課程中里的例子來進行說明:
現在,我們有一個數據集,包含房屋面積和房屋價格兩類數據。我們希望通過這兩類數據尋找規律,即通過房屋面積預測房屋價格。

如圖中左側所示,此即為一個最簡單的神經網絡,它由一個輸出層神經元節點,一個隱藏層神經元節點和一個輸出層神經元節點組成。
課程中的基礎介紹較為簡略,我們先行補充一下輸入層,隱藏層,輸出層的概念。
- 輸入層的神經元接收外部數據(此時為房屋面積),并將這些數據傳遞到網絡的下一層。每個輸入神經元代表輸入數據的一個特征,輸入層節點數量由特征數量決定。
- 隱藏層的神經元負責數據處理和特征抽取。隱藏層位于輸入層和輸出層之間,通常有多個隱藏層,這些層主要用于學習數據中的復雜模式。每個隱藏層的神經元通過權重連接接收來自輸入層或前一隱藏層的輸出信號,并對這些信號進行加權求和。在加權求和后,神經元會通過激活函數進行非線性變換,決定該神經元的輸出。這個輸出將傳遞到下一層(可能是另一層隱藏層或輸出層)
- 輸出層的神經元負責生成最終的結果(此時為房屋價格),如分類標簽或回歸值。輸出層的神經元通常代表模型的預測結果。
需要注意的一點是,在課程中,吳恩達老師稱此網絡為“單神經元網絡”,這里的單神經元是指隱藏層的神經元個數,實際上,輸入輸出層的節點也是可以被稱為神經元,只是這些節點不涉及權重等參數的計算,我們理解即可。
在了解神經元后,緊接著我們就產生了下一步問題,像這樣把幾個神經元連接起來就可以預測價格了嗎?神經網絡到底是怎么工作的呢?
神經網絡的關鍵在于隱藏層的設置,我們的數據通過輸入層進入隱藏層,而隱藏層的神經元工作如展開篇幅過長,我們在此只闡述隱藏層神經元最基本的功能:對隨機初始化權重的輸入進行加權求和,本質上是一種線性變換,這個過程我們是不可見的,也就是所謂的“隱藏”。
但結合題目,又產生了新的問題:我們不難想到,房屋面積和房屋價格都不可能為負數,因此,本題的擬合函數一定是一個非線性函數,如下圖所示:

那隱藏層又如何處理數據的非線性關系呢?
這里便可以引入之前的概念里多次出現的激活函數了。
激活函數 是一種數學函數,它的輸入是神經元的加權和(即輸入信號和權重的乘積之和),輸出是經過函數變換的結果。激活函數的主要作用是通過非線性變換引入網絡的非線性特性,使神經網絡能夠表示和處理復雜的模式。
個人理解來說,激活函數就是對輸出引入非線性的變換,提供了處理復雜能力的關系。我們在之后會再詳細展開。
目前已有的激活函數多種多樣,最簡潔且實用的便是適用本題的線性修正單元(Rectified Linear Unit,ReLU)激活函數,其公式為:
因此,在隱藏層添加激活函數后,即可處理房屋面積和房屋價格都不可能為負數的情況。
在此之后,最終的輸出會和答案進行對比計算誤差并以此更新輸入的權重,如此反復,最終達成良好的,可以處理復雜問題的擬合效果,這便是神經網絡的簡要工作原理,涉及的其他過程會在之后的課程中再詳細展開。
單神經網絡如此工作,多神經網絡同樣如此,我們再對房屋價格問題進行簡單的擴展,擴大神經網絡的規模,如下圖所示:
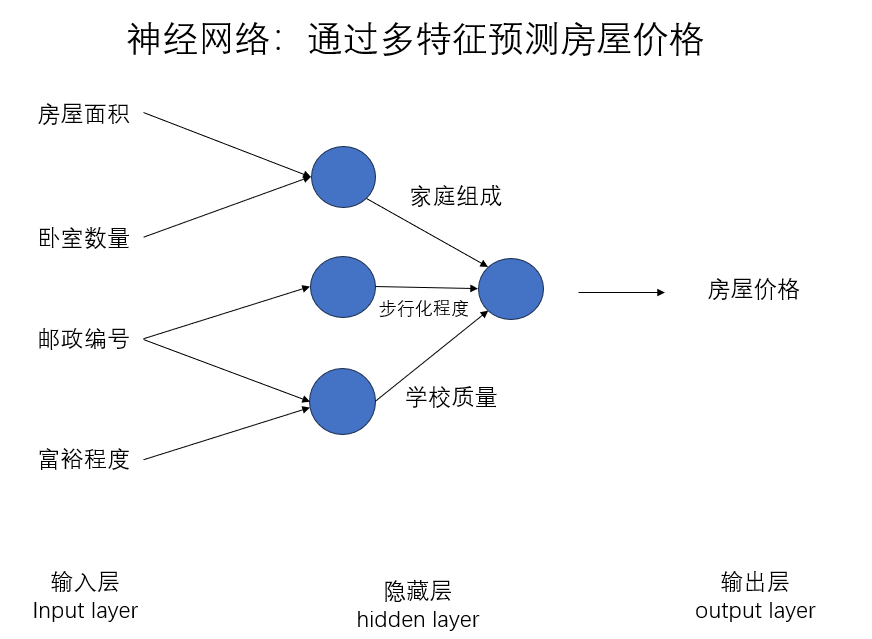
可以發現,我們增加了輸入的特征數量的同時也增加了一層新的隱藏層,實際上,隱藏層層數的增加是對特征的進一步抽象,就如圖中所示,我們可以從房屋面積和臥室數量推斷家庭組成,從郵政編號和富裕程度推斷學校質量,多數情況下,這將更有利于我們的擬合效果。
但要說明的是,這張圖的連接關系只是便于理解,實際上,我們更常用下面這樣的連接:

可以看到,我們的每個輸入特征都對和下一層的隱藏神經元進行了全連接,隱藏層間同樣如此,由神經網絡自身完成特征的進一步提取,我們只需設置好輸入,參數,中間的過程即可完全由神經網絡自己完成。
總之,在擁有足夠數據量的監督學習情況下, 神經網絡非常擅長數據的擬合。
1.2神經網絡的發展和應用領域都有什么?
神經網絡的主要應用和其創造的經濟價值都基于機器學習中的監督學習。
監督學習(Supervised Learning)是機器學習中的一種學習方式,在這種學習過程中,算法從一組輸入數據和對應的正確輸出(標簽)中學習,目的是通過建立一個映射關系,從而預測新的、未見過的數據的標簽。具體來說,監督學習的目標是根據已知的訓練數據,學會一個函數模型,該模型能夠將輸入映射到正確的輸出。
通俗來講,把模型比作學生,訓練比作考試,監督學習就是學生可以在考試-對答案-考試的重復中不斷提高自己的成績。
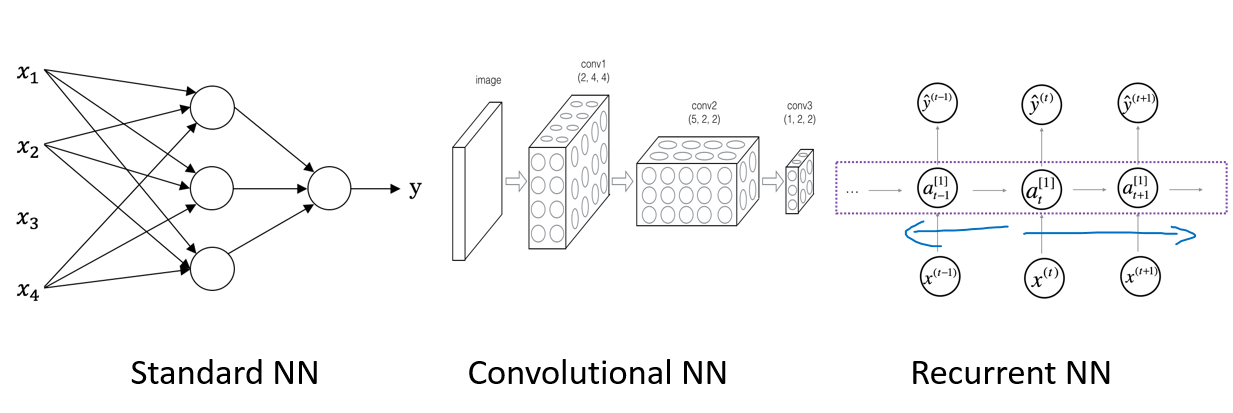
在監督學習的基礎上,神經網絡又發展出常用于處理圖像數據的卷積神經網絡(Convolutional Neural Network, CNN)和處理序列數據的循環神經網絡(Recurrent Neural Network, RNN)
二者都有自己適用的應用領域,舉例如下:
- NN:房地產,廣告點擊
- CNN:圖片分類,標記
- RNN:音頻處理,語言反應
- 面對無人駕駛等復雜問題,則常需要復雜的混合神經網絡
1.3什么是結構化數據和非結構化數據?
- 結構化數據是指高度組織化且以預定義的數據模型進行存儲的數據。這些數據通常可以在表格中表示,并且每個數據項(如行和列)都有明確的定義。
- 非結構化數據是指沒有預定格式或數據模型的數據。這類數據沒有固定的組織形式,通常無法被傳統的數據庫直接存儲和查詢。它包括各種文本、圖像、音頻、視頻等類型的數據。
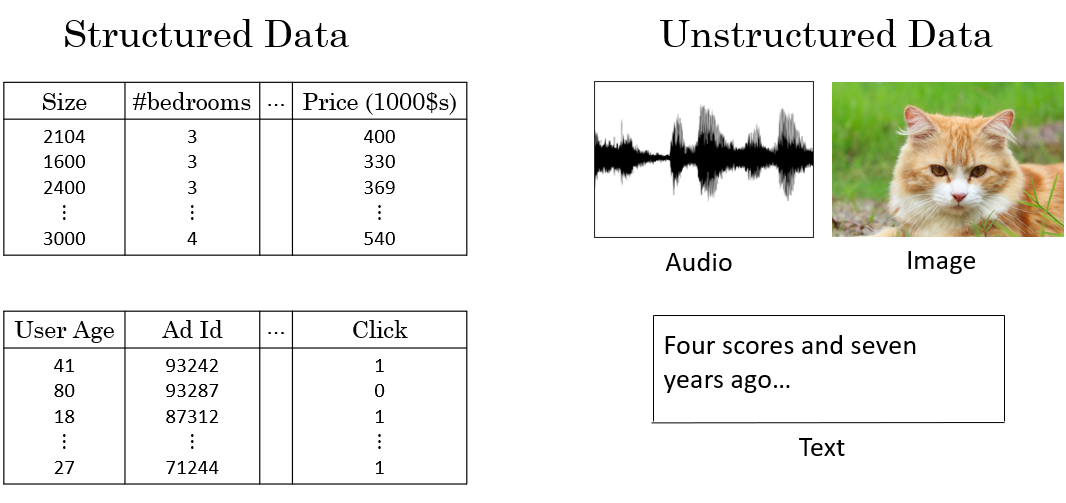
得益于深度學習和神經網絡的發展,計算機相比幾年前,能更好地處理和應用非結構化數據,也同樣創造了巨大的經濟價值。
1.4深度學習為什么會興起?
- 傳統的機器學習算法隨著數據量的進一步增加進入瓶頸期,而相比之下,規模反而推動了深度學習的發展,一個大型的神經網絡在海量數據的支持下表現極佳。
- 在數據量較小的情況下,各類算法的優劣并不明顯,更取決于組件和算法的涉及,但當數據量到達一定量級,神經網絡便會穩定占據優勢。
- 算法方面的創新也進一步推動了代碼運行速度,讓思考,實驗,修改的周期更短。

2.課后習題
習題鏈接:【中英】【吳恩達課后測驗】Course 1 - 神經網絡和深度學習 - 第一周測驗
本部分習題均為選擇,無編程習題,熟悉相關概念即可。

 浙公網安備 33010602011771號
浙公網安備 33010602011771號