生成式對抗網(wǎng)絡(luò)GAN
【 李宏毅機(jī)器學(xué)習(xí)】生成式對抗網(wǎng)絡(luò)GAN
在傳統(tǒng)的神經(jīng)網(wǎng)絡(luò)任務(wù)中,我們通常把一個網(wǎng)絡(luò)當(dāng)作一個函數(shù)f(x),給定輸入x,網(wǎng)絡(luò)就會輸出一個對應(yīng)的結(jié)果 y。比如圖像分類任務(wù)中,輸入是一張圖片,輸出是一個分類標(biāo)簽。這是一種 判別式模型(Discriminative Model),它學(xué)的是輸入和輸出之間的映射關(guān)系。但在生成式模型(Generative Model) 中,輸入會增加一個隨機(jī)分布中sample出來的z,網(wǎng)絡(luò)輸入x和z,輸出y是可以從中采樣的復(fù)雜分布。

網(wǎng)絡(luò)通常會采用兩種方式來處理x和z(1)拼接(Concatenate):直接把 兩個向量拼接在一起,變成一個更長的向量,輸入到神經(jīng)網(wǎng)絡(luò)中。(2)相加(Element-wise Add):如果x和 z維度相同,可以直接相加作為輸入。我們的目標(biāo)不再是“判斷”某個輸入屬于哪一類,而是希望模型能夠“生成”數(shù)據(jù)——比如生成看起來真實(shí)的圖片、音頻,甚至文本。換句話說,我們希望網(wǎng)絡(luò)本身就是一個“生成器”,可以從某種潛在的隨機(jī)性中創(chuàng)造出無限多樣的輸出。
1 GAN(Generative Adversarial Network)
1.1 GAN 的基本概念和工作原理
生成對抗網(wǎng)絡(luò)(GAN)是由 Ian Goodfellow 等人在 2014 年提出的一種生成式模型。與傳統(tǒng)的神經(jīng)網(wǎng)絡(luò)不同,GAN 由兩個相互競爭的網(wǎng)絡(luò)組成:生成器(Generator) 和 判別器(Discriminator)。
以生成二次元人臉為例:
生成器(Generator):把x拿掉,生成器只輸入隨機(jī)噪聲 z ,這種叫做unconditional generation。假設(shè)z是從normal distribution中sample出來的向量,這個向量一般是low-dim的向量,維度是自定義的,Generator輸入z后產(chǎn)生一個64x64x3的向量,整理后可以得到一張二次元人臉的圖像。

判別器(Discriminator):對應(yīng)的判別器輸入一張圖片(可能是來自真實(shí)數(shù)據(jù)集,也可能是來自生成器),輸出一個數(shù)字,數(shù)字越大表示輸入的圖像越像真實(shí)的二次元的人臉。

1.2 GAN 的訓(xùn)練機(jī)制
- 初始化生成器和判別器參數(shù)
- 在每個訓(xùn)練迭代中
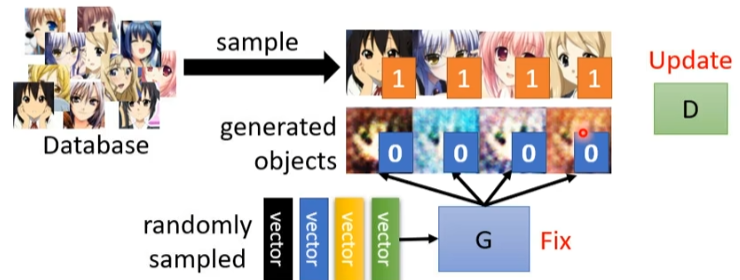
- 固定住生成器,更新判別器。具體的隨機(jī)采樣一些向量z,輸入到生成器,得到一些生成的圖像,然后從真實(shí)數(shù)據(jù)中采樣一些二次元人臉,訓(xùn)練判別器分別兩者之間的差異。比如用二分類器,或者邏輯回歸。
-
- 固定住判別器,更新生成器。具體的把兩個網(wǎng)絡(luò)接起來變成一個大網(wǎng)絡(luò),其中判別器的參數(shù)是固定的,訓(xùn)練生成器,使得分?jǐn)?shù)越大越好。

GAN的訓(xùn)練目標(biāo)是通過對抗訓(xùn)練,生成器和判別器在博弈中不斷提高自己的能力:
- 生成器的目標(biāo):生成足夠真實(shí)的數(shù)據(jù),使得判別器無法區(qū)分它們是來自真實(shí)數(shù)據(jù)還是生成的假數(shù)據(jù)。
假設(shè)生成的數(shù)據(jù)分布為PG,真實(shí)數(shù)據(jù)分布為Pdata,生成器的目標(biāo)就是
![]()
Divergence是PG和Pdata之間的某種距離,距離越小兩個分布就越相近。盡管不知道PG和Pdata是什么樣的分布,但是可以從中sample。
- 判別器的目標(biāo):盡可能準(zhǔn)確地區(qū)分真實(shí)數(shù)據(jù)和生成數(shù)據(jù),減少自己的分類錯誤。
分別從PG和Pdata中sample,Discriminator要學(xué)會給PG和中sample到的樣本打1,給Pdata中sample到的樣本打0,要做的是一個二分類任務(wù)。判別器的總 BCE 損失(對所有樣本)為
![]()
損失是要最小化,等價于最大化目標(biāo)函數(shù)V:

這個maxV和JS divergence有關(guān),因此生成器的目標(biāo)就是
![]()
之前的訓(xùn)練步驟就是在解這個minmax問題,為什么訓(xùn)練步驟可以解這個函數(shù),見論文推導(dǎo)。設(shè)計(jì)不同的objective function解minmax問題,就對應(yīng)不同的divergence(參考)。
1.3 WGAN:基于 Wasserstein 距離的改進(jìn)方法
在大多數(shù)情況下,PG和Pdata之間是沒有重疊的,兩個都是高維空間的低維manifold,相當(dāng)于二維空間的兩條直線。即使兩個分布是有重疊的,但是sample的點(diǎn)不夠多,重疊的范圍也非常小。當(dāng)兩個分布沒有重疊時,JS divergence是存在問題的。 JS divergence是非度量的,不能為生成器提供一個明確的目標(biāo)方向來指導(dǎo)其優(yōu)化。比如下面的情況,PG和Pdata越來越接近,但是JS始終為log2,知道兩者重合才會變成0。

為了改善 GAN 的訓(xùn)練穩(wěn)定性,研究者提出了Wasserstein GAN(WGAN)。它的核心思想是:
替換原本的 JS 散度為 Wasserstein 距離(又叫 Earth Mover’s Distance)。
你可以把它理解為:把一堆土(生成的數(shù)據(jù)分布)搬到另一堆土堆(真實(shí)數(shù)據(jù)分布)需要花費(fèi)的最小“搬運(yùn)成本”。這是一種更光滑、梯度更穩(wěn)定的距離度量方式。

計(jì)算Wasserstein 距離就是解下面的公式

注意:
-
WGAN 中的判別器不再是“真假分類器”,而是一個 Critic,它的輸出是任意實(shí)數(shù),用于度量樣本的“真實(shí)性”得分。
-
為了滿足理論條件,Critic 的梯度需要是1-Lipschitz的。這個限制是讓Discriminator變得平滑,如果沒有這個限制,D會給生成的x負(fù)無窮,給真實(shí)的x正無窮,訓(xùn)練會無法收斂,max始終是無窮大。
??Q: 如何讓Discriminator變得比較平滑?
最早用權(quán)重裁剪,限制權(quán)重在-c到c之間,后續(xù)改進(jìn)為 WGAN-GP(加入梯度懲罰項(xiàng)),訓(xùn)練更穩(wěn)定,另一個常用、效果非常不錯的方式是:Spectral Normalization,歸一化權(quán)重的最大奇異值,不需要像 WGAN-GP 那樣計(jì)算復(fù)雜的梯度懲罰項(xiàng),也避免了 weight clipping 帶來的訓(xùn)練困難。
1.4 GAN 面臨的挑戰(zhàn)
盡管已經(jīng)有了如WGAN這樣的改進(jìn)方法,GAN在訓(xùn)練過程中仍然面臨諸多挑戰(zhàn)。這主要源于其對抗性訓(xùn)練機(jī)制的本質(zhì)特性:生成器(Generator)與判別器(Discriminator)在訓(xùn)練過程中是相互博弈、彼此促進(jìn)的關(guān)系。模型的優(yōu)化是一個動態(tài)博弈過程,如果其中一方(例如判別器)訓(xùn)練不足或性能不穩(wěn)定,就會導(dǎo)致另一方(如生成器)無法獲得有效的反饋信號,從而影響整體訓(xùn)練效果。這種相互依賴使得GAN的訓(xùn)練過程高度不穩(wěn)定,調(diào)試和收斂都較為困難。目前主流的生成模型,除了GAN,還有變分自編碼器(VAE),流模型(Flow-based Models)。GAN在圖像生成質(zhì)量上往往優(yōu)于VAE和Flow模型,但它的訓(xùn)練更不穩(wěn)定、可解釋性更弱。

??Q: 為什么GAN難用于文本生成?
答:因?yàn)槲谋臼?/strong>離散的,而GAN的訓(xùn)練依賴于梯度的反向傳播。在文本生成中,生成器通常輸出一個概率分布,再通過 argmax 或 采樣 選擇一個詞。這種“選詞”的過程是非可導(dǎo)的,梯度無法穿過這個離散選擇,從而導(dǎo)致生成器無法優(yōu)化。在多個值相等或者接近的時候,梯度無法確定往哪個方向優(yōu)化。比如在 argmax 選詞時,即便概率稍微改變,只要最大值沒變,輸出結(jié)果也不會變,因此梯度是 0 或未定義的,無法有效訓(xùn)練生成器。
??Q: 那CNN里也有max pooling,為什么沒問題?
答:CNN 中的 max pooling 雖然也是 max 操作,但它出現(xiàn)在網(wǎng)絡(luò)的中間層,反向傳播時我們可以將梯度傳給最大值的位置,其他位置設(shè)為 0(這叫次梯度 subgradient)。這種近似梯度在實(shí)踐中效果不錯,因此不會影響 CNN 的訓(xùn)練。
模式坍縮 (Mode Collapse)
Mode Collapse 是指生成器只學(xué)會生成真實(shí)數(shù)據(jù)中的一小部分模式,導(dǎo)致輸出缺乏多樣性。換句話說,雖然真實(shí)數(shù)據(jù)有很多種可能,但生成器反復(fù)生成的是同一種或幾種“看起來不錯”的樣本。例如:你訓(xùn)練 GAN 生成手寫數(shù)字,但生成器最終只會生成“數(shù)字 3”,而忽略了其他數(shù)字。這樣雖然圖片質(zhì)量可能還可以,但多樣性完全丟失。這是因?yàn)樯善髦粚W⒂凇膀_過判別器”的目標(biāo),而不是完整地復(fù)現(xiàn)數(shù)據(jù)分布。一旦找到某個容易成功的樣本類型,就會反復(fù)生成,從而陷入局部最優(yōu)。
模式遺漏(Mode Dropping)
Mode Dropping 指的是生成器完全忽略了真實(shí)數(shù)據(jù)中的某些模式,即使這些模式在訓(xùn)練數(shù)據(jù)中是存在的,生成器卻沒有學(xué)會去生成它們。假設(shè)你訓(xùn)練一個 GAN 模型用于生成真實(shí)人臉,訓(xùn)練數(shù)據(jù)中包含了不同年齡、性別、膚色、發(fā)型的人臉圖像。但訓(xùn)練后的生成器:只會生成某一膚色的面孔。盡管這些樣本在真實(shí)數(shù)據(jù)中是存在的,生成器卻忽略了這些“模式”。這就屬于典型的 Mode Dropping —— 生成結(jié)果看起來多樣,但其實(shí)缺失了某些重要的群體特征。
1.5 GAN評估指標(biāo)
GAN 在訓(xùn)練中容易出現(xiàn)模式坍縮(Mode Collapse)和模式遺漏(Mode Dropping)等問題,即生成器生成的樣本看起來質(zhì)量不錯,但實(shí)則重復(fù)或覆蓋不全。這時我們就需要一些定量評估指標(biāo)來判斷兩個關(guān)鍵問題:(1) 生成圖像質(zhì)量好不好?(2) 生成圖像夠不夠多樣?不像分類器有準(zhǔn)確率指標(biāo),GAN 的 Generator 沒有明確的評價指標(biāo),但有一些常用方法可以參考:
Inception Score(IS)
- 用一個預(yù)訓(xùn)練的分類器(如 Inception-v3)去分類生成的圖像
- 一張圖片丟到CNN去分類,結(jié)果分布越集中,quality越高
- 一堆圖片的平均分布,越平均diversity越大
- good quality,large diversity→large IS,說明生成樣本質(zhì)量越好、類別多樣。
在二次元人臉生成中,分類器的輸出可能都是人臉,diversity小,不適合這個場景。
Frechet Inception Distane(FID)
-
將生成圖像和真實(shí)圖像分別輸入一個預(yù)訓(xùn)練好的 CNN(通常是 Inception v3);
-
在網(wǎng)絡(luò)的某一層(通常是 softmax 前的一層)提取特征向量(即使輸入圖像都是人臉,這些向量也會有所不同,因?yàn)樗鼈儾蹲降氖歉邔拥恼Z義信息(比如臉的姿態(tài)、表情、風(fēng)格等)
-
假設(shè)這兩組特征向量分別服從一個多維高斯分布,F(xiàn)ID 會分別計(jì)算這兩組特征向量的 均值(μ) 和 協(xié)方差矩陣(Σ),然后用 Frechet 距離來衡量它們之間的差異
 如果 FID 值很小,說明生成的圖像和真實(shí)圖像非常接近,但這并不意味著生成器生成的樣本多樣化。生成器可能只是記住了真實(shí)數(shù)據(jù)的某些特征,導(dǎo)致它只能生成“很相似”的樣本,而失去了多樣性,比如學(xué)會了對真實(shí)圖像進(jìn)行翻轉(zhuǎn)。真實(shí)特征分布可能遠(yuǎn)非高斯,所以在做次元人臉生成中主要是用FID和人眼就去看。
如果 FID 值很小,說明生成的圖像和真實(shí)圖像非常接近,但這并不意味著生成器生成的樣本多樣化。生成器可能只是記住了真實(shí)數(shù)據(jù)的某些特征,導(dǎo)致它只能生成“很相似”的樣本,而失去了多樣性,比如學(xué)會了對真實(shí)圖像進(jìn)行翻轉(zhuǎn)。真實(shí)特征分布可能遠(yuǎn)非高斯,所以在做次元人臉生成中主要是用FID和人眼就去看。
2 Conditional GAN(條件生成對抗網(wǎng)絡(luò))
傳統(tǒng)GAN中,生成器是無條件的——它只接收隨機(jī)噪聲z作為輸入。而 Conditional GAN 則引入條件信息x,例如類別標(biāo)簽、文本描述、圖像等,引導(dǎo)生成器生成“符合條件”的樣本。
應(yīng)用: 文本生成圖像
需要收集一些圖片和對應(yīng)的標(biāo)注, 輸入x是一段文字red eyes,可以用rnn或者transformer encoder把它變成一段向量。期望輸入red eyes,generator就輸出一個紅眼睛的圖片,每次的輸出都是不一樣的紅眼睛,取決于sample到不一樣的z。

??Q: 如何訓(xùn)練Conditional GAN?
如果像之前的GAN一樣,判別器只判斷圖像是否是真實(shí)的,生成器就不用在意輸入x,只要產(chǎn)生清晰的圖像就可以。在 Conditional GAN 中,我們的目標(biāo)不只是生成“看起來真實(shí)的圖像”,更重要的是:圖像還要和輸入的條件匹配。需要準(zhǔn)備文字和圖像成對的資料(positive),以及文字和機(jī)器產(chǎn)生出來的圖片(negative),還需要把文字和圖像亂配作為(negative)。

應(yīng)用: 圖像生成圖像 (image translation or pix2pix)
比如輸入黑白的圖片讓生成器著色,或者對圖像去霧。輸入一張圖片生成一張圖片,可以用supervised的方法,由于同樣的輸入可能對應(yīng)到不一樣的輸出,機(jī)器學(xué)到把所有的可能平均起來,所以產(chǎn)生的圖片會很模糊。如果用GAN的方法,再加入判別器,判別器輸入生成器生成的圖像和condition,然后輸出分?jǐn)?shù)。GAN方法產(chǎn)生的圖像比較清楚,但是可能會產(chǎn)生輸入沒有的東西,比如下面的房子左上角有奇怪的東西。當(dāng)GAN和supervised同時使用,效果會比較好,生成器在訓(xùn)練的時候一方面要騙過判別器,但又要使得產(chǎn)生的圖片和目標(biāo)越接近越好。

3 CycleGAN:無監(jiān)督圖像到圖像的轉(zhuǎn)換
在之前的unconditional generation中,輸入是一個簡單分布,輸出是一個復(fù)雜分布,現(xiàn)在稍微轉(zhuǎn)換下,輸入是x domain圖片的分布,輸出是y domain圖片的分布。假設(shè)我們將真實(shí)人臉轉(zhuǎn)換為二次元人臉,像之前訓(xùn)練GAN一樣,從x domain中sample一張圖片,輸入到Generator,再用學(xué)過ydomain的discriminator去給圖像打分,這是有問題的。Generator會無視輸入的圖片,只產(chǎn)生一張像y domain的二次元圖片就可以,這個圖片和輸入的真實(shí)人臉沒有。如何強(qiáng)化輸入和輸出的關(guān)系呢?之前的conditional gan也講過類似的問題,但是現(xiàn)在沒有成對的數(shù)據(jù)去訓(xùn)練discriminator學(xué)習(xí)輸入和輸出的關(guān)系。


4 作業(yè)HW6
鏈接給出了PDF和code:李宏毅2021&2022機(jī)器學(xué)習(xí)。
代碼:


import random import torch import numpy as np import os import glob import torch.nn as nn import torch.nn.functional as F import torchvision import torchvision.transforms as transforms from torch import optim from torch.autograd import Variable from torch.utils.data import Dataset, DataLoader import matplotlib.pyplot as plt from tqdm import tqdm def same_seeds(seed): # Python built-in random module random.seed(seed) # Numpy np.random.seed(seed) # Torch torch.manual_seed(seed) if torch.cuda.is_available(): torch.cuda.manual_seed(seed) torch.cuda.manual_seed_all(seed) torch.backends.cudnn.benchmark = False torch.backends.cudnn.deterministic = True same_seeds(2021) class CrypkoDataset(Dataset): def __init__(self, fnames, transform): self.transform = transform self.fnames = fnames self.num_samples = len(self.fnames) def __getitem__(self, idx): fname = self.fnames[idx] # 1. Load the image img = torchvision.io.read_image(fname) # 2. Resize and normalize the images using torchvision. img = self.transform(img) return img def __len__(self): return self.num_samples def get_dataset(root): fnames = glob.glob(os.path.join(root, '*')) # 1. Resize the image to (64, 64) # 2. Linearly map [0, 1] to [-1, 1] compose = [ transforms.ToPILImage(), transforms.Resize((64, 64)), transforms.ToTensor(), transforms.Normalize(mean=(0.5, 0.5, 0.5), std=(0.5, 0.5, 0.5)), ] transform = transforms.Compose(compose) dataset = CrypkoDataset(fnames, transform) return dataset def weights_init(m): classname = m.__class__.__name__ if classname.find('Conv') != -1: m.weight.data.normal_(0.0, 0.02) elif classname.find('BatchNorm') != -1: m.weight.data.normal_(1.0, 0.02) m.bias.data.fill_(0) class Generator(nn.Module): """ Input shape: (N, in_dim) Output shape: (N, 3, 64, 64) """ def __init__(self, in_dim, dim=64): super(Generator, self).__init__() def dconv_bn_relu(in_dim, out_dim): return nn.Sequential( nn.ConvTranspose2d(in_dim, out_dim, 5, 2, padding=2, output_padding=1, bias=False), nn.BatchNorm2d(out_dim), nn.ReLU() ) self.l1 = nn.Sequential( nn.Linear(in_dim, dim * 8 * 4 * 4, bias=False), nn.BatchNorm1d(dim * 8 * 4 * 4), nn.ReLU() ) self.l2_5 = nn.Sequential( dconv_bn_relu(dim * 8, dim * 4), dconv_bn_relu(dim * 4, dim * 2), dconv_bn_relu(dim * 2, dim), nn.ConvTranspose2d(dim, 3, 5, 2, padding=2, output_padding=1), nn.Tanh() ) self.apply(weights_init) def forward(self, x): y = self.l1(x) y = y.view(y.size(0), -1, 4, 4) y = self.l2_5(y) return y class Discriminator(nn.Module): """ Input shape: (N, 3, 64, 64) Output shape: (N, ) """ def __init__(self, in_dim, dim=64, use_sigmoid=True): super(Discriminator, self).__init__() def conv_bn_lrelu(in_dim, out_dim): return nn.Sequential( nn.Conv2d(in_dim, out_dim, 5, 2, 2), nn.BatchNorm2d(out_dim), nn.LeakyReLU(0.2), ) """ Medium: Remove the last sigmoid layer for WGAN. """ layers = [ nn.Conv2d(in_dim, dim, 5, 2, 2), nn.LeakyReLU(0.2), conv_bn_lrelu(dim, dim * 2), conv_bn_lrelu(dim * 2, dim * 4), conv_bn_lrelu(dim * 4, dim * 8), nn.Conv2d(dim * 8, 1, 4), ] if use_sigmoid: layers.append(nn.Sigmoid()) self.ls = nn.Sequential(*layers) self.apply(weights_init) def forward(self, x): y = self.ls(x) y = y.view(-1) return y def train(baseline="Simple", show_img=True): # Training hyperparameters batch_size = 64 z_sample = Variable(torch.randn(100, z_dim)).cuda() lr = 1e-4 if baseline == "Simple": n_epoch = 50 # 50 n_critic = 1 # 訓(xùn)練 1 次判別器,再訓(xùn)練 1 次生成器 elif baseline == "Medium": """ Medium: WGAN, 50 epoch, n_critic=5, clip_value=0.01 """ n_epoch = 50 n_critic = 5 # 先訓(xùn)練 5 次判別器,再訓(xùn)練 1 次生成器 clip_value = 0.01 # Model G = Generator(in_dim=z_dim).cuda() if baseline == "Simple": D = Discriminator(3).cuda() elif baseline == "Medium": D = Discriminator(3, use_sigmoid=False).cuda() G.train() D.train() # Loss criterion = nn.BCELoss() # Optimizer if baseline == "Simple": opt_D = torch.optim.Adam(D.parameters(), lr=lr, betas=(0.5, 0.999)) opt_G = torch.optim.Adam(G.parameters(), lr=lr, betas=(0.5, 0.999)) elif baseline == "Medium": """ Medium: Use RMSprop for WGAN. """ opt_D = torch.optim.RMSprop(D.parameters(), lr=lr) opt_G = torch.optim.RMSprop(G.parameters(), lr=lr) # DataLoader dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True, num_workers=2) steps = 0 for e, epoch in enumerate(range(n_epoch)): progress_bar = tqdm(dataloader) for i, data in enumerate(progress_bar): imgs = data imgs = imgs.cuda() bs = imgs.size(0) # ============================================ # Train D # ============================================ z = Variable(torch.randn(bs, z_dim)).cuda() r_imgs = Variable(imgs).cuda() f_imgs = G(z) if baseline == "Simple": # Label r_label = torch.ones((bs)).cuda() f_label = torch.zeros((bs)).cuda() # Model forwarding r_logit = D(r_imgs.detach()) f_logit = D(f_imgs.detach()) # Compute the loss for the discriminator. r_loss = criterion(r_logit, r_label) f_loss = criterion(f_logit, f_label) loss_D = (r_loss + f_loss) / 2 elif baseline == "Medium": # WGAN Loss loss_D = -torch.mean(D(r_imgs)) + torch.mean(D(f_imgs)) # Model backwarding D.zero_grad() loss_D.backward() # Update the discriminator. opt_D.step() if baseline == "Medium": """ Medium: Clip weights of discriminator. """ for p in D.parameters(): p.data.clamp_(-clip_value, clip_value) # ============================================ # Train G # ============================================ if steps % n_critic == 0: # Generate some fake images. z = Variable(torch.randn(bs, z_dim)).cuda() f_imgs = G(z) # Model forwarding f_logit = D(f_imgs) if baseline == "Simple": # Compute the loss for the generator. loss_G = criterion(f_logit, r_label) elif baseline == "Medium": # WGAN Loss loss_G = -torch.mean(D(f_imgs)) # Model backwarding G.zero_grad() loss_G.backward() # Update the generator. opt_G.step() steps += 1 # Set the info of the progress bar # Note that the value of the GAN loss is not directly related to # the quality of the generated images. progress_bar.set_postfix({ 'Loss_D': round(loss_D.item(), 4), 'Loss_G': round(loss_G.item(), 4), 'Epoch': e + 1, 'Step': steps, }) G.eval() f_imgs_sample = (G(z_sample).data + 1) / 2.0 filename = os.path.join(log_dir, f'Epoch_{epoch + 1:03d}.jpg') torchvision.utils.save_image(f_imgs_sample, filename, nrow=10) print(f' | Save some samples to {filename}.') # Show generated images in the jupyter notebook. if show_img: grid_img = torchvision.utils.make_grid(f_imgs_sample.cpu(), nrow=10) plt.figure(figsize=(10, 10)) plt.imshow(grid_img.permute(1, 2, 0)) plt.show() G.train() if (e + 1) % 5 == 0 or e == 0: # Save the checkpoints. torch.save(G.state_dict(), os.path.join(ckpt_dir, 'G.pth')) torch.save(D.state_dict(), os.path.join(ckpt_dir, 'D.pth')) def inference(): G = Generator(z_dim) G.load_state_dict(torch.load(os.path.join(ckpt_dir, 'G.pth'))) G.eval() G.cuda() # Generate 1000 images and make a grid to save them. n_output = 1000 z_sample = Variable(torch.randn(n_output, z_dim)).cuda() imgs_sample = (G(z_sample).data + 1) / 2.0 log_dir = os.path.join('logs') filename = os.path.join(log_dir, 'result.jpg') torchvision.utils.save_image(imgs_sample, filename, nrow=10) # Show 30 of the images. grid_img = torchvision.utils.make_grid(imgs_sample[:30].cpu(), nrow=10) plt.figure(figsize=(10, 10)) plt.imshow(grid_img.permute(1, 2, 0)) plt.show() if __name__ == '__main__': dataset = get_dataset('faces') # 注意,這些數(shù)值的范圍是 [-1, 1],所以顯示比較暗 # images = [dataset[i] for i in range(16)] # grid_img = torchvision.utils.make_grid(images, nrow=4) # plt.figure(figsize=(10, 10)) # plt.imshow(grid_img.permute(1, 2, 0)) # plt.show() # 我們需要將它們轉(zhuǎn)換到有效的范圍 [0, 1],才能正確顯示。 # images = [(dataset[i] + 1) / 2 for i in range(16)] # grid_img = torchvision.utils.make_grid(images, nrow=4) # plt.figure(figsize=(10, 10)) # plt.imshow(grid_img.permute(1, 2, 0)) # plt.show() z_dim = 100 log_dir = os.path.join('logs') ckpt_dir = os.path.join('checkpoints') os.makedirs(log_dir, exist_ok=True) os.makedirs(ckpt_dir, exist_ok=True) train(baseline="Medium", show_img=False) inference()
兩個指標(biāo):
-
FID(Frechet Inception Distance):衡量生成圖片和真實(shí)圖片的差異,越低越好。
-
AFD(Attribute FID Distance):衡量生成圖像屬性的多樣性或質(zhì)量,越高越好。
| 項(xiàng)目 | 評分標(biāo)準(zhǔn) | 分?jǐn)?shù) |
|---|---|---|
| ? 代碼部分 Code | 提交完整、可運(yùn)行的代碼 | 4 分 |
| ? 簡單基準(zhǔn) Simple | FID ≤ 30000 且 AFD ≥ 0.00 | 2 分 |
| ? 中等基準(zhǔn) Medium | FID ≤ 11800 且 AFD ≥ 0.43 | 2 分 |
| ? 強(qiáng)基準(zhǔn) Strong | FID ≤ 9300 且 AFD ≥ 0.53 | 1 分 |
| ? 最強(qiáng)基準(zhǔn) Boss | FID ≤ 8200 且 AFD ≥ 0.68 | 1 分 |
| ?? 額外加分 Bonus | 擊敗 Boss 基準(zhǔn) + 提交 < 100 字的英文 PDF 報(bào)告 | 0.5 分 |
- 從判別器中移除最后的 sigmoid 層。
- 計(jì)算損失時不取對數(shù)(log)。
- 將判別器的權(quán)重裁剪到一個常數(shù)范圍內(nèi)。
- 使用 RMSProp 或 SGD 作為優(yōu)化器。
用Spectral Normalization GAN (SNGAN)可以達(dá)到strong分?jǐn)?shù),主要是在判別器的每一層的權(quán)重進(jìn)行譜歸一化(Spectral Normalization)。


訓(xùn)練50epoch結(jié)果


訓(xùn)練50epoch結(jié)果


 浙公網(wǎng)安備 33010602011771號
浙公網(wǎng)安備 33010602011771號