【論文筆記】SegNet
【深度學習】總目錄
SegNet是Cambridge提出旨在解決自動駕駛或者智能機器人的圖像語義分割深度網絡,開放源碼,基于caffe框架。SegNet運用編碼-解碼結構和最大池化索引進行上采樣,最主要的貢獻是它在效率上的提升(內存和時間)。文章很長,消融實驗寫的很詳細,了解一下對以后改模型有所幫助。最后與DeepLab-LargeFOV和DeconvNet的對比實驗我沒有細看,這邊先不寫了。
原文地址:https://arxiv.org/abs/1511.00561
復現詳解:http://mi.eng.cam.ac.uk/projects/segnet/tutorial.html
1 Motivation
最近的一些方法嘗試直接采用用于類別預測的深度體系結構來進行像素級標記。結果雖然非常令人鼓舞,但結果看起來還是粗糙的。這主要是因為最大池化和子采樣降低了特征圖的分辨率。我們設計SegNet的動機來自于將低分辨率特征映射到輸入分辨率以實現像素級分類。這種映射必須產生對精確的邊界定位有用的特征。
道路場景理解需要對外觀(道路、建筑)、形狀(汽車、行人)進行建模,并理解不同類別(如道路和人行道)之間的空間關系(上下文)。在典型的道路場景中,大多數像素屬于道路、建筑等大類,因此網絡必須產生平滑的分割。引擎還必須能夠根據物體的形狀描繪物體,盡管它們的尺寸很小。因此,在提取的圖像表示中保留邊界信息是重要的。從計算角度來看,在推理過程中,網絡必須在內存和計算時間方面都有效。網絡需要有端到端訓練的能力,以便使用有效的權重更新技術(如隨機梯度)聯合優化網絡中的所有權重。
2 網絡結構
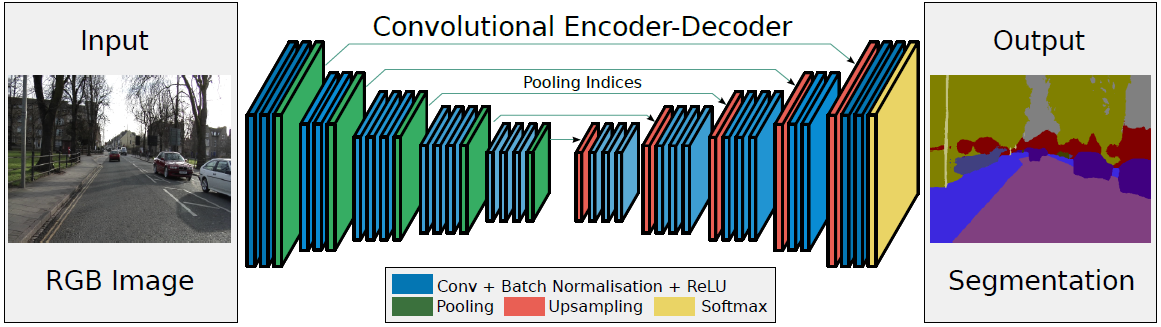
- 左邊是Encoder:卷積提取特征,通過pooling增大感受野,同時圖片變小。使用的是VGG16的前13層卷積網絡,去除全連接層可以保留更高分辨率的特征圖,并且能夠顯著地減小網絡的參數(134M->14.7M)
- 右邊是Decoder:Upsamping就是Pooling的逆過程,將圖片變成兩倍大小,再用index信息直接將數據放回對應位置,后面再接Conv訓練學習。
- 最后通過Softmax,得到每一個像素屬于某個類別的概率,最大概率所屬類別做為該像素的label,最終完成圖像像素級別的分類。
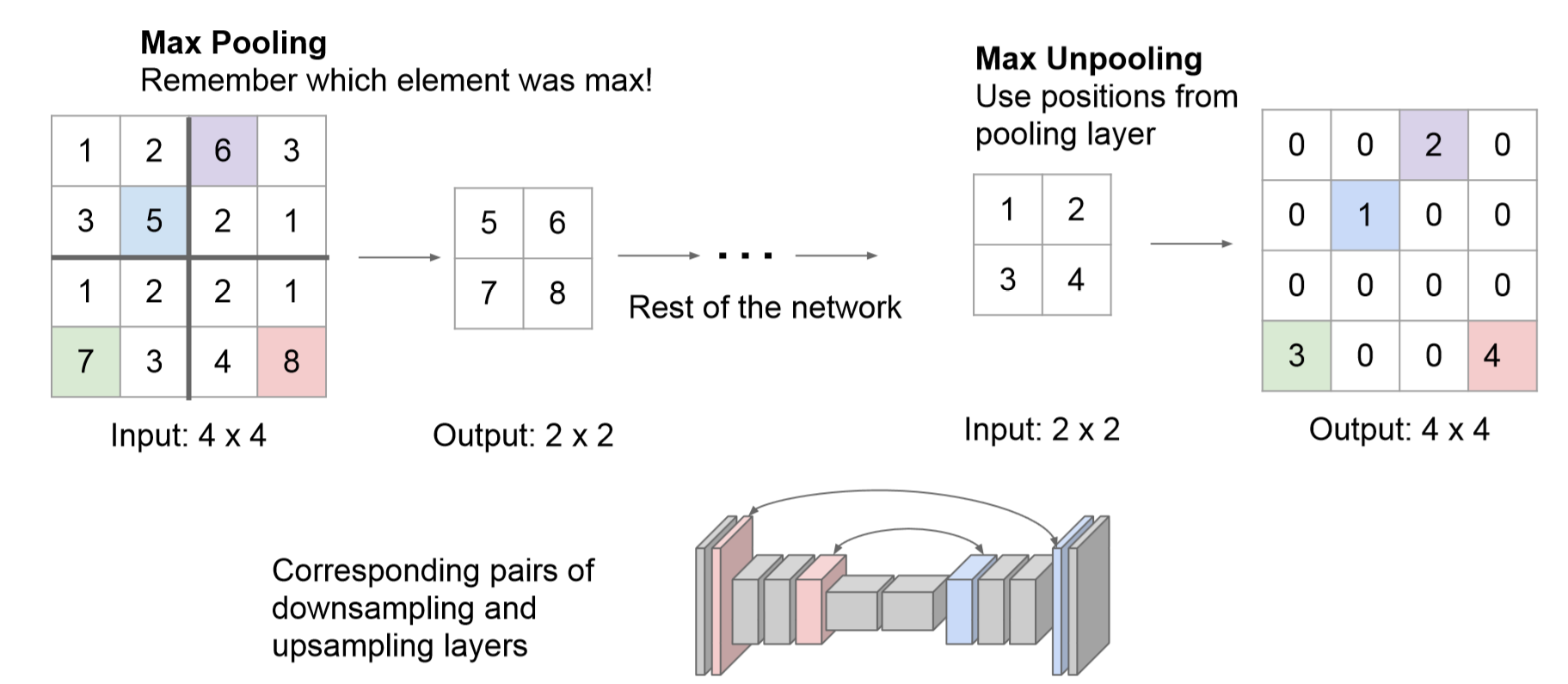
max-pooling indices(亮點)
在Encoder中,每次max-pooling,都會保存max權值在2x2filter中的相對位置;在Decoder中,根據保存的indices進行上采樣:首先對輸入的特征圖放大兩倍,然后把輸入特征圖的數據根據Encoder中pooling層的索引位置放入,其他位置為0。
利用池化索引來執行非線性上采樣的優點:(1)保留了部分重要的邊界信息,改善了網絡模型對于邊界的描述 (2)減少了FCN中因上采樣而需要訓練的參數 (3)能在極小修改的條件下與Encoder-Decoder網絡模型相結合。
3 實驗
3.1 評價指標
使用如下幾種指標(1)global accuracy(G)(2)class average accuracy(C) (3)mIoU:比類平均準確率更嚴格,因為它懲罰FP預測,然而mIoU并不是類別平衡cross-entropy損失函數的優化目標(其優化目標是準確率最大化)。這三種指標在語義分割評價指標中介紹過。還有對邊界描述的評價指標boundary F1-measure (BF):涉及計算邊界像素的F1指標。給定一個像素容錯距離,計算預測值和ground truth類別邊界之間的精確度和召回率。作者使用圖像對角線的0.75%作為容錯距離。與mIoU相比,BF的評判結果更符合人類對語義分割效果的判定。
3.2 Decoder Variants
很多語義分割網絡有相同的Encoder,僅在Decoder上有所不同。這邊選擇比較FCN和SegNet的解碼技術。
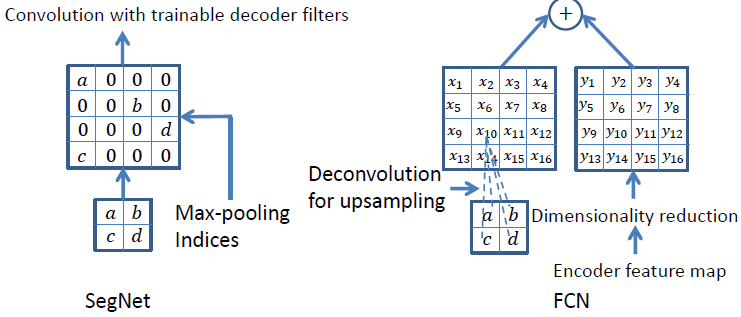
如上圖所示,SegNet使用最大池化索引來上采樣,后面再接Conv訓練學習。這個上采樣不需要訓練學習,只是占用了一些存儲空間。FCN使用轉置卷積進行上采樣,這一過程需要學習,然后將Encoder中對應的特征矩陣降維后相加。為了分析SegNet并將其性能與FCN進行比較,作者設計了以下幾種變種。
- SegNet-Basic:4 encoders + 4 decoders,使用池化索引,卷積后加Bn,不用bias和ReLu。在所有編碼器和解碼器層上選擇7×7的恒定內核大小以提供用于平滑標記的寬上下文。
- SegNet-Basic-SingleChannelDecoder:解碼器的卷積用的單通道,顯著減少了可訓練參數的數量和推理時間。
- SegNet-Basic-EncoderAddition:池化索引后接卷積 + 逐元素add
- FCN-Basic:將encoder中的特征圖利用1x1的卷積進行維度縮減至K通道(k為類別數)然后作為decoder的輸入。decoder中上采樣使用8x8大小的轉置卷積,上采樣后的特征矩陣也是K通道。兩者逐元素相加。上采樣核使用雙線性插值權進行初始化。
- FCN-Basic-NoAddition:不使用特征矩陣的逐元素add(也就是沒有跳躍連接),只學習上采樣核。FCN解碼器模型要求在推理過程中存儲編碼器特征圖。例如,以180×240分辨率以32位浮點精度存儲FCN Basic第一層的64個特征圖需要11MB。這可以通過對11個特征圖進行降維來縮小,這需要大約1.9MB的存儲空間。另一方面,SegNet對池索引的存儲成本幾乎可以忽略不計(如果每2×2個池窗口使用2位存儲,則為0.17MB)。
- FCN Basic NoDimReduction:更占用內存的FCN,沒有針對編碼器特征圖執行維度縮減。這意味著與FCN-Basic不同,最終編碼器特征圖在傳遞到解碼器網絡之前不會壓縮到K個通道。因此,每個解碼器末端的通道數與相應的編碼器相同(即64)。
- Bilinear-Interpolation:使用固定雙線性插值權重的上采樣,不需要學習。
3.3 訓練
- CamVid道路場景數據集,由367個訓練圖像和233個測試RGB圖像(白天和黃昏場景)組成,分辨率為360×480,分割11個類別
- 隨機梯度下降(SGD),lr = 0.1,momentum = 0.9
- 在每個epochs之前,訓練集被打亂,然后按順序挑選mini-batch(12幅圖像),從而確保每個圖像在一個epochs中只使用一次
- 選擇在驗證數據集上性能最高的模型
- 交叉熵損失 + median frequency balancing,當訓練集中每個類的像素數量有很大變化時(例如道路、天空和建筑物像素主導CamVid數據集),則需要根據真實類別對損失進行不同的加權。
median frequency balancing:
(1)計算整個訓練集中各個類別出現的頻率: fc = 訓練集中被標記為c的像素數/訓練集中所有圖片的總像素數 c=1,...,k
(2)選出集合[f1,...fk]中的中位數fmedian
(3)為每個類別的loss分配權重wc = fmedian / fc c=1,...,k
3.4 分析
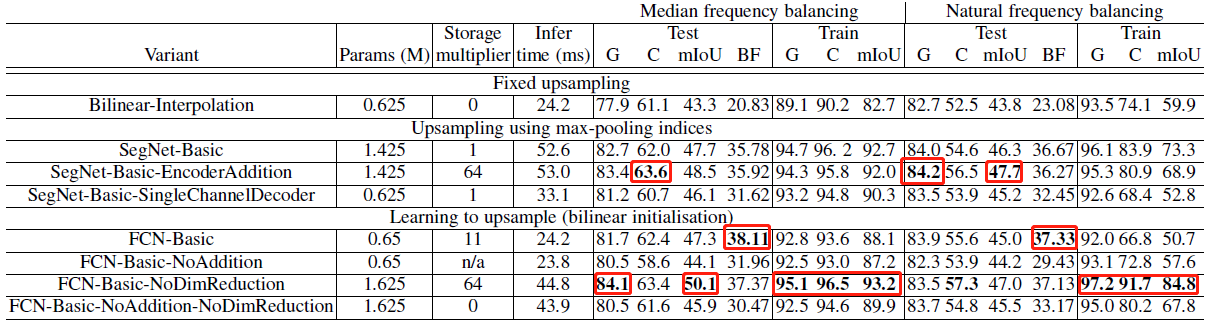
在各網絡已訓練至均收斂的條件下,各變體的評價結果如上表所示。結果表明:
- (1) Decoder需要訓練,使用雙線性插值作為Decoder的效果最差。
- (2) SegNet-Basic和FCN-Basic性能相近,但后者由于保存各層的feature map消耗更多內存。
- (3) FCN-Basic-NoAddition的性能差于結構最相近的SegNet-Basic,表明Encoder中信息的重要性。
- (4) 不對Encoder的輸出進行壓縮,能帶來性能的提升,但在保存feature map時會增大內存消耗。
- (5) 與FCN-Basic-NoAddition和FCN-Basic-NoAddition-NoDimReduction相比,SegNet-Basic-SingleChannelDecoder雖然丟失了部分信息,但仍保留了部分Encoder中的信息,因此性能優于前兩者。
- (6) 在不限制內存和推斷時間的條件下,FCN-Basic-NoDimReduction和SegNet-EncoderAddition達到了最優的性能,FCN-Basic-NoDimReduction的BF1最高,表明存儲空間和準確率之間存在著權衡。
作者總結了如下要點:
- 將encoder的特征圖全部存儲時,性能最好。 尤其是對于邊緣的分割
- 當限制存儲時,可以使用適當的decoder(例如SegNet類型)來存儲和使用encoder產生的特征圖(維數降低,max-pooling indices)的壓縮形式來提高性能。
- 更大的decoder提高了網絡的性能
3. SegNet算法詳解

 浙公網安備 33010602011771號
浙公網安備 33010602011771號