
DolphinScheduler依賴機制、Open-Falcon告警推送與監控的優化實踐
一、背景
DolphinScheduler(海豚調度器)作為開源分布式調度系統,核心價值在于破解大數據場景下復雜任務的調度與流程編排難題,憑借可靠的任務調度、可視化工作流管理等能力,已成為生產環境的核心調度中樞——當前95%以上的大數據任務均通過其實現協調調度。而Open-Falcon作為專注大規模分布式系統的開源監控工具,二者形成"調度核心+監控中樞"的協同關系:前者承擔任務調度的核心職責,后者則作為其專屬告警對接系統,實現監控信息向釘釘群的精準推送。
然而原生機制中,DolphinScheduler的依賴判斷邏輯、告警推送效果及組件監控能力均存在優化空間——例如依賴判斷僅基于工作流級別可能導致資源浪費,原生告警存在關鍵信息淹沒、無優先級區分等問題,且缺乏組件不可用狀態的自動監控與自愈機制。
為此,本文聚焦某大數據團隊的實戰優化經驗,系統闡述該團隊的核心實踐:針對任務依賴機制的源碼級改造(新增節點級別判斷邏輯)、與Open-Falcon的告警對接升級(實現信息精簡、優先級分級與分群推送),以及組件監控體系的構建(含節點存活檢測與自愈能力)等。通過拆解技術實現邏輯與落地細節,為同類場景下的調度系統優化提供可復用的實踐參考。
二、DolphinScheduler改進實踐
2.1依賴機制修改
2.1.1 依賴信息介紹
DolphinScheduler不單單支持DAG簡單的前驅和后繼節點之間的依賴關系,同時還提供任務依賴節點,支持流程間的自定義任務依賴。
- 名詞解釋:
DAG:全稱 Directed Acyclic Graph,簡稱 DAG。工作流中的 Task 任務以有向無環圖的形式組裝起來,從入度為零的節點進行拓撲遍歷,直到無后繼節點為止。舉例如下圖:
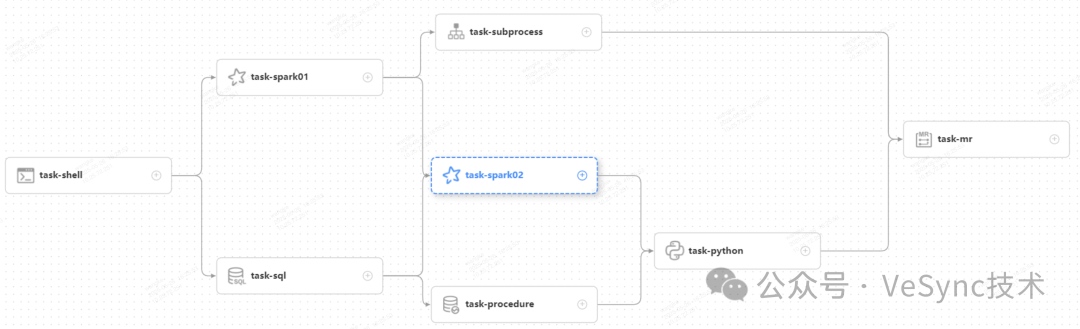
流程定義:通過拖拽任務節點并建立任務節點的關聯所形成的可視化DAG。
流程實例:流程實例是流程定義的實例化,可以通過手動啟動或定時調度生成。每運行一次流程定義,產生一個流程實例
任務實例:任務實例是流程定義中任務節點的實例化,標識著某個具體的任務。
任務類型:目前支持有 SHELL、SQL、SUB_PROCESS(子流程)、PROCEDURE、MR、SPARK、PYTHON、DEPENDENT(依賴),同時計劃支持動態插件擴展,注意:其中 SUB_PROCESS類型的任務需要關聯另外一個流程定義,被關聯的流程定義是可以單獨啟動執行的。
2.1.2 問題描述
DolphinScheduler的原生依賴機制是:從元數據庫t_ds_process_instance(流程實例表)根據依賴的時間周期(如圖示)在其范圍內根據工作流的結束時間倒序取第一條工作流實例進行判斷。
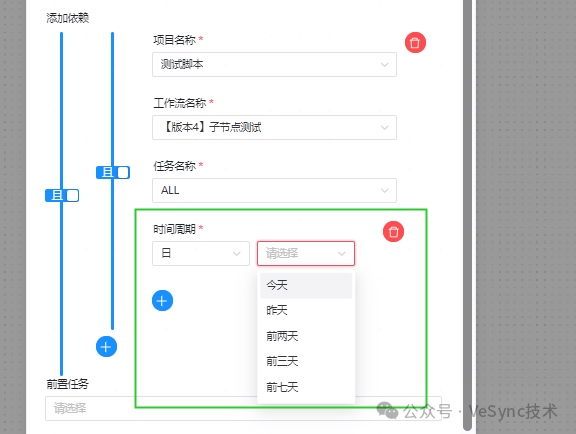
這就導致了一個問題:工作流中出現執行失敗的節點就需要將完整工作流進行修復,存在已經成功執行占用資源較大、執行時間較長的節點需要重新執行、在包含大量節點的工作流已經執行大半,受影響的只是少量的工作流要重新執行的情況。
但如果只執行失敗和未執行的節點,就會導致再失敗工作流中已經執行成功的節點在后續的依賴判斷中會被判失敗。
2.1.3 改進邏輯
我們對這一機制進行了優化改進。在獲取新工作流實例的位置增加部分邏輯:獲取依賴的節點code,從元數據庫t_ds_task_instance表根據依賴的時間周期在其范圍內根據工作流的結束時間倒序取第一條節點實例。
此改動既保證了原生邏輯中判斷會遵循工作流級(process)實例的完成順序,又增加節點級別(task)實例的判斷。
2.1.4 代碼修改
- dolphinscheduler-master/src/main/java/org/apache/dolphinscheduler/server/master/utils/DependentExecute.java添加代碼:
// 代碼121行
result = getDependTaskResult(dependentItem.getDepTaskCode(), processInstance, dateInterval); //函數getDependTaskResult 修改功能:在取最新的流程實例獲取對應任務實例依賴為空的情況下,增加單獨的任務實例獲取 private DependResult getDependTaskResult(long taskCode, ProcessInstance processInstance, DateInterval dateInterval) { DependResult result; TaskInstance taskInstance = null; List<TaskInstance> taskInstanceList = processService.findValidTaskListByProcessId(processInstance.getId()); for (TaskInstance task : taskInstanceList) { if (task.getTaskCode() == taskCode) { taskInstance = task; break; } } if (taskInstance == null) { // cannot find task in the process instance // maybe because process instance is running or failed. if (processInstance.getState().typeIsFinished()) { Integer processDefinitionId = processInstance.getId(); Date taskStartTime = dateInterval.getStartTime(); Date taskEndTime = dateInterval.getEndTime(); TaskInstance lastTaskInstance = processService.findLastRunningTaskByProcessDefinitionId(processDefinitionId, taskCode, taskStartTime, taskEndTime); if(lastTaskInstance == null) { return DependResult.FAILED; } if(lastTaskInstance.getState().typeIsFinished()){ result = getDependResultByState(lastTaskInstance.getState()); }else { result = DependResult.WAITING; } }else{ return DependResult.WAITING; } }else{ result = getDependResultByState(taskInstance.getState()); } return result; }
- dolphinscheduler-dao/src/main/resources/org/apache/dolphinscheduler/dao/mapper/TaskInstanceMapper.xml 添加代碼:
根據任務實例的開始時間倒序取最新一條數據:
<select id="findLastRunningTaskByProcessDefinitionId" resultType="org.apache.dolphinscheduler.dao.entity.TaskInstance">
select *
from t_ds_task_instance
<where>
task_code=#{taskCode}
<iftest="startTime!=null and endTime != null ">
and start_time <![CDATA[ >= ]]> #{startTime} and start_time <![CDATA[ <= ]]> #{endTime}
</if>
</where>
order by start_time desc limit 1
</select>
- dolphinscheduler-dao/src/main/java/org/apache/dolphinscheduler/dao/mapper/TaskInstanceMapper.java添加代碼:
TaskInstance findLastRunningTaskByProcessDefinitionId(@Param("processDefinitionId") Integer processDefinitionId,
@Param("states") int[] stateArray,
@Param("taskCode") long taskCode,
@Param("startTime") Date startTime,
@Param("endTime") Date endTime
);
- dolphinscheduler-service/src/main/java/org/apache/dolphinscheduler/service/process/ProcessService.java 添加代碼:
TaskInstance findLastRunningTaskByProcessDefinitionId(Integer processDefinitionId, long taskCode, Date startTime, Date endTime);
- dolphinscheduler-service/src/main/java/org/apache/dolphinscheduler/service/process/ProcessServiceImpl.java 添加代碼:
private final int[] stateArray = new int[]{ExecutionStatus.Pending.ordinal(),
ExecutionStatus.InProgress.ordinal(),
ExecutionStatus.Stopping.ordinal(),
ExecutionStatus.Failed.ordinal(),
ExecutionStatus.Stopped.ordinal(),
ExecutionStatus.CompletedWithViolations.ordinal(),
ExecutionStatus.Completed.ordinal()};
@Override
public TaskInstance findLastRunningTaskByProcessDefinitionId(Integer processDefinitionId, long taskCode, Date startTime, Date endTime) {
return taskInstanceMapper.findLastRunningTaskByProcessDefinitionId(processDefinitionId, stateArray, taskCode, startTime, endTime);
}
2.2 告警對接Open-Falcon
2.2.1 問題描述
DolphinScheduler原生的告警通知如下:
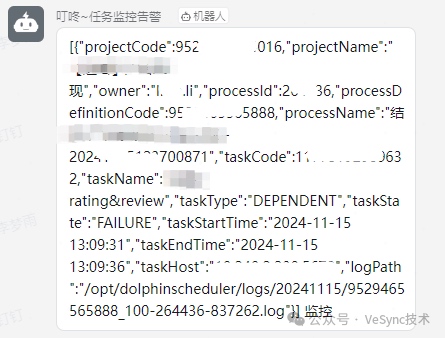
這樣的告警推送存在以下問題:
-
報警信息不清晰:上報較多無用信息(如code、owner、host及日志信息),導致關鍵信息淹沒
-
沒有告警優先級:所有工作流上報信息都一樣,某些需要立即關注的問題不能及時感知
-
沒有未恢復告警提示:告警信息較多的情況,容易遺漏修復
2.2.2 解決邏輯
確認原生告警邏輯的查詢條件: 每分鐘查詢元數據庫t_ds_process_instance表,匯總當前分鐘內執行結束的工作流信息,并標記對應狀態,將獲取數據上報open-falcon,實現告警信息自定義配置、告警等級設定、未恢復告警提示。
2.2.3 實現邏輯
確認只保留工作流級別的失敗通報,通過腳本實現:每分鐘獲取上一分鐘執行結束的工作流實例信息,獲取結束狀態向falcon上報組裝獲取的工作流相關信息、指定的告警等級等。
實現邏輯如下:
- 獲取監控時間段內的,工作流信息,獲取工作流的sql實現:
select pi.id, pd.name as process_name, pi.state
from (select id, state, process_definition_code from t_ds_process_instance where end_time >= '%s'
and end_time < '%s' and (command_param not like '%%parentProcessInstanceId%%' or command_param is null)) pi,
t_ds_process_definition pd
where pi.process_definition_code = pd.code
-
過濾不是結束狀態的工作流;
-
對執行結束的工作流進行狀態標記;
-
數據上報falcon、設置告警等級、告警過濾、實現告警分情況上報不同群
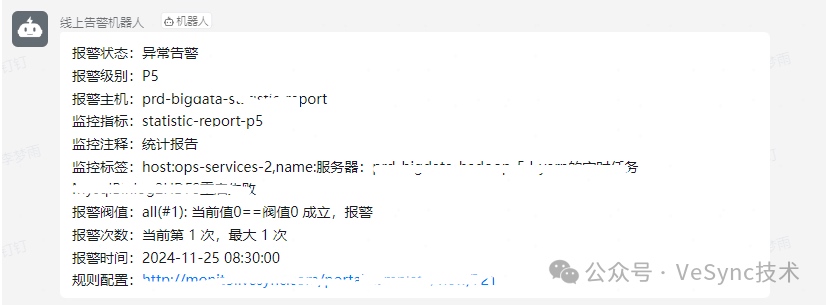
實現后告警信息如下圖:
三、DolphinScheduler的監控體系
3.1 節點狀態存活監控
3.1.1 什么問題?
由于線上環境會因為各種資源占用出現宕機或接近宕機的狀態(機器可以正常進入,但不能進行組件正常執行,例:磁盤寫滿、網絡波動等),但DolphinScheduler本身沒有針對組件不可用狀態監控或恢復的機制功能。
如果正好在沒人使用DolphinScheduler執行手動任務或進行測試時,很難察覺組件的異常狀態,如果在周末出現問題時,則會影響大量的任務運行,需要花費較長時間進行修復。
因此,實現節點狀態存活監控旨在:
- 實現組件的狀態監控,并嘗試自愈;
- 快速上報組件內自愈失敗的異常節點,減少對線上任務的執行影響。
3.1.2 功能描述
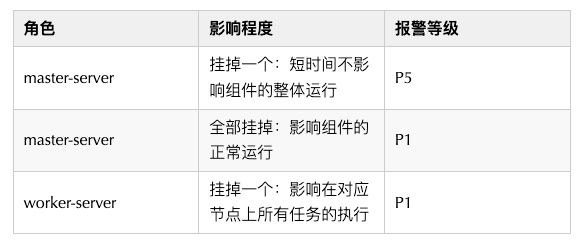
腳本監控DolphinScheduler的worker-server、master-server存活狀態,發現狀態異常時先進行重新啟動,再次監控狀態還是異常時,進行告警,因為不同節點在組件中的角色不同,因此對告警等級進行了下圖的設定:
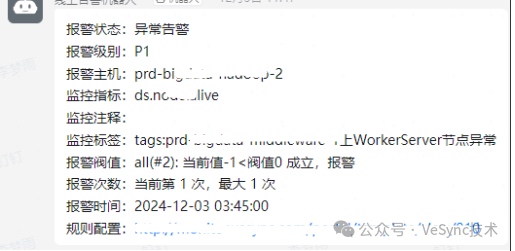
效果示例:
3.2 工作流定時狀態上線監控
3.2.1 什么問題?
由于線上定時任務的調度基本都在DolphinScheduler上執行,每天會有較多的上線操作,會對線上工作流進行下線修改操作,如果上線過程遺漏掉定時上線或者工作流上線,就會造成任務漏跑,嚴重的會影響其他的正常定時調度的工作流。
因此,工作流定時狀態上線監控旨在:每天夜里在凌晨任務高峰段開始前確認線上正式工作流的上線狀態、定時狀態。
3.2.2 功能描述
從DolphinScheduler元數據庫查詢,所有有上線定時設置的工作流,再逐一進行遞歸驗證工作流的上線狀態和定時上線狀態,以及子工作流的上線狀態,未上線時進行上報。
3.2.3 實現邏輯
- 從元數據庫獲取由定時設置且工作流名稱未包含‘修復’、‘測試’等關鍵詞的工作流信息;
- 遍歷上述獲取工作流,對其定時狀態進行判斷,如果未上線:則進行告警通知;
- 如果2中工作流定時上線,則遍歷工作流內節點信息,獲取所有的子節點類型節點,對子節點指向的工作流進行工作流上線狀態的判斷;正常則進行本步驟繼續遞歸子工作流節點直至工作流內沒有子工作流類型的節點為止;否則,就進行告警通知。
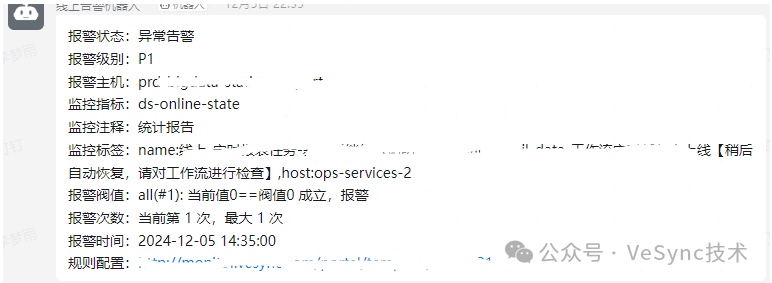
實現效果:
3.3 DolphinScheduler長時間執行工作流監控
3.3.1 什么問題?
目前,線上大多數的工作流執行不會超過4個小時,但存在:1、特殊工作流長時間執行;2、異常工作流執行:長時間請求等待、依賴卡住等情況。
開發DolphinScheduler長時間執行工作流監控,旨在:提醒當前線上存在超長時間執行工作流,方便異常情況的停止并及時修復;也方便特殊工作流的分析優化。
3.3.2 功能描述
上報當前執行時長超過4小時(基本是執行異常事件)的工作流名稱。
3.3.3 代碼實現
- 獲取超長時間執行的工作流信息,實現sql如下:
select pjname, pname, stat from
(select process_definition_code, TIMESTAMPDIFF(minute , start_time,now()) stat from t_ds_process_instance where state = 1) instance
join
(select project.name pjname, process.name pname, process.code
from t_ds_project project join t_ds_process_definition process on process.project_code = project.code
whereprocess.name not like '%測試%'
and process.name not like '%修復%') def
on def.code = instance.process_definition_code
wherestat > 240
-
判斷是不是指定端特殊工作流(為這類工作流設置單獨的告警時長);
-
超出設置閾值,則進行上報。
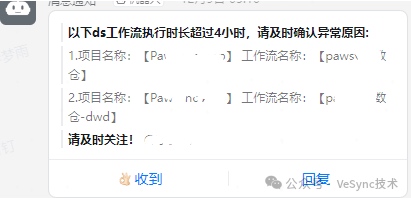
實現效果:
3.4 Shell節點未添加重試監控
3.4.1 什么問題?
由于DolphinScheduler上的執行任務受集群機器的狀態影響、關聯組件(比如:zookeeper、MySQL等)的影響、網絡影響,不能保證任務節點在定時調度時,一次就一定能執行成功,所以需要進行重試次數的設置。
本監控實現對當日新增的節點未添加重試進行上報提醒。
3.4.2 功能描述
上報當前shell類型節點未增加重試的工作流信息。
3.4.3 代碼實現
從元數據庫獲取當日新增的、類型為‘SHELL’的、未被禁止的、所屬工作流已上線的、失敗重試次數為0的節點信息,sql實現如下:
select project.name pjname, process.name pname, task.name tname
from t_ds_task_definition task
join t_ds_project project on task.project_code = project.code
left join t_ds_process_definition process on locate(task.code, process.locations) > 0
where process.release_state = 1 and task.task_type in ('SHELL', 'SQL')
and task.fail_retry_times = 0 and process.release_state = 1 and task.flag = 1
and (task.update_time >= '{}' or task.create_time >= '{}')
對獲取的信息進行匯總上報。
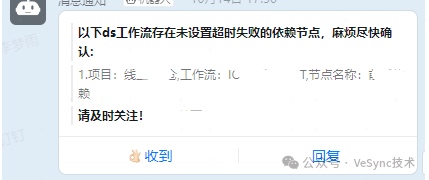
3.5 依賴節點未設置超時失敗監控
3.5.1 什么問題?
由于DolphinScheduler對依賴信息的判斷在沒有對應實例的情況下,會進行等待然后判斷,一直循環。那么不設置超時失敗就會導致工作流在依賴執行異常的情況下(例如:未執行、或長時間執行不出來),就會一直進行判斷,這同樣可能造成大量工作流不能執行要花費較多時間進行修復,且要在修復前手動進行停止。本監控旨在解決依賴節點超時時長相關的監控,旨在保證依賴時長始終控制在合理且有效的范圍內
3.5.2 功能描述
上報未設置超時失敗的依賴類型節點、設置的不是超時失敗的依賴節點、以及依賴節點執行時長接近設置時長的節點
3.5.3 代碼實現
- 先獲取每日執行的、依賴節點類型的任務實例,關聯任務節點定義表,如果未設置超時、設置的不是超時失敗,則進行上報;
- 獲取近七天內執行的、依賴節點類型的任務且依賴執行時長超過1分鐘的實例信息,統計依賴執行總時長/依賴執行次數的平均執行時長,平均執行時長接近設置時長的80%,則進行上報;
- 獲取當日執行的、依賴執行時長超過設置時長90%,進行上報。
實現效果:
四、效率工具
4.1 工作流的依賴情況查詢
4.1.1 什么問題?
因為DolphinScheduler中工作流之間會有較多的依賴關系,因此在對工作流的拓撲進行調整、定時進行修改時,要先確認對他有依賴的下游工作流有哪些,需要逐一確認,調整對其是否有影響,是否需要隨之改動。
4.1.1 功能描述
查詢當前環境所有依賴你指定的工作流的工作流信息。
4.1.2 代碼實現
- 根據輸入的項目名稱、工作流名稱獲取對應的id;
- 在任務定義表中獲取依賴類型節點的信息中包含1中查詢到的id信息的任務節點id;
- 將2中獲取的id關聯工作流定義表、項目表,獲取其所在的項目和工作流。實現效果:
指定項目和工作流名稱:
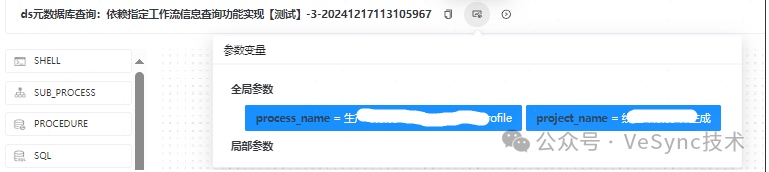
查詢結果:

4.2 工作流信息快捷查詢
4.2.1 功能描述
在DolphinScheduler元數據庫中工作流(process)和節點(task)都是通過project_code和項目進行關聯的,因此,查詢對應節點和工作流信息時,要經過較多處理,故進行一個基礎sql實現項目、工作流和節點的信息關聯,這樣在實際應用中只需要進行簡單其他篩選條件的添加。
4.2.2 代碼實現
select project.name pjname, process.name pname, task.name tname
from t_ds_task_definition task
join t_ds_project project on task.project_code = project.code
left join t_ds_process_definition process on locate(task.code, process.locations) > 0
這樣在實際應用中,只需要增加where條件和需要的字段就可以獲取所有需要的信息
舉例:獲取所有‘SQL’類型節點的信息:
select project.name pjname, process.name pname, task.name tname
from t_ds_task_definition task
join t_ds_project project on task.project_code = project.code
left join t_ds_process_definition process on locate(task.code, process.locations) > 0
where task.task_type = 'SQL'
五、展望
在本文介紹的大數據團隊對DolphinScheduler的優化實踐、監控體系和效率工具基礎上,為保證任務的穩定運行同時優化項目的調度、保障資源分配合理且充足,我們將會繼續通過智能編排算法進行以下方面優化:
結合歷史調度實例、集群資源空閑狀態、追溯依賴關系輸出合適的修改建議;
元數據導入dataHub,方便溯源工作流之間的真實的依賴關系,在腳本中自動進行遞歸改動,對改動信息進行輸出。
參考文檔:

 浙公網安備 33010602011771號
浙公網安備 33010602011771號