
pytorch 實戰教程之路徑聚合網絡 PANet (Path Aggregation Network)代碼實現 路徑聚合網絡PANet原理詳解(Yolo目標檢測網絡前置)
原文作者:aircraft
原文鏈接:pytorch 實戰教程之路徑聚合網絡PANet(Path AggregationNetwork)代碼實現 PANet原理詳解 
學習YOLOv5前的準備就是學習DarkNet53網絡,FPN特征金字塔網絡,PANet路徑聚合網絡結構,(從SPP-Net到SPPF)SPPF空間金字塔池化等。本篇講PANet網絡結構。。。(其他幾篇已經發布在歷史博客里)
PANet原理詳解什么介紹我本來是不想寫的,看了一圈博客,感覺他們寫的都無法讓入門小白真正的去理解這個網絡結構(感覺他們像個機器翻譯人,論文翻譯一下就結束了),所以我在他們的基礎上稍微講的詳細一些。。。(代碼在最下面,注釋都打的比較詳細了)
PANet(Path Aggregation Network)詳解
PANet 是2018年提出的一種高效的目標檢測與實例分割網絡,核心思想是通過??雙向特征融合??和??自適應特征池化??顯著提升多尺度目標的檢測能力。以下從設計動機、核心創新、網絡結構、實驗結果四個方面詳細解析。
一、設計背景:FPN的局限性
??FPN(Feature Pyramid Network)?? 通過自頂向下的路徑構建特征金字塔,但存在兩個關鍵問題:
- ??語義信息稀釋??:深層特征經過多次上采樣傳遞到淺層時,丟失細節信息。
- ??定位精度不足??:小目標依賴淺層特征,但淺層語義信息較弱。
??示例問題??:
在COCO數據集中,小目標(面積<322像素)的檢測AP僅為26.9,遠低于大目標(AP 53.6)。
二、核心創新
PANet 提出兩大核心改進:
- ??自底向上路徑增強(Bottom-Up Path Augmentation)??
新增與FPN反向的路徑,強化低層特征的定位能力。 - ??自適應特征池化(Adaptive Feature Pooling)??
根據目標尺寸自動選擇最優特征層級。
三、網絡結構詳解
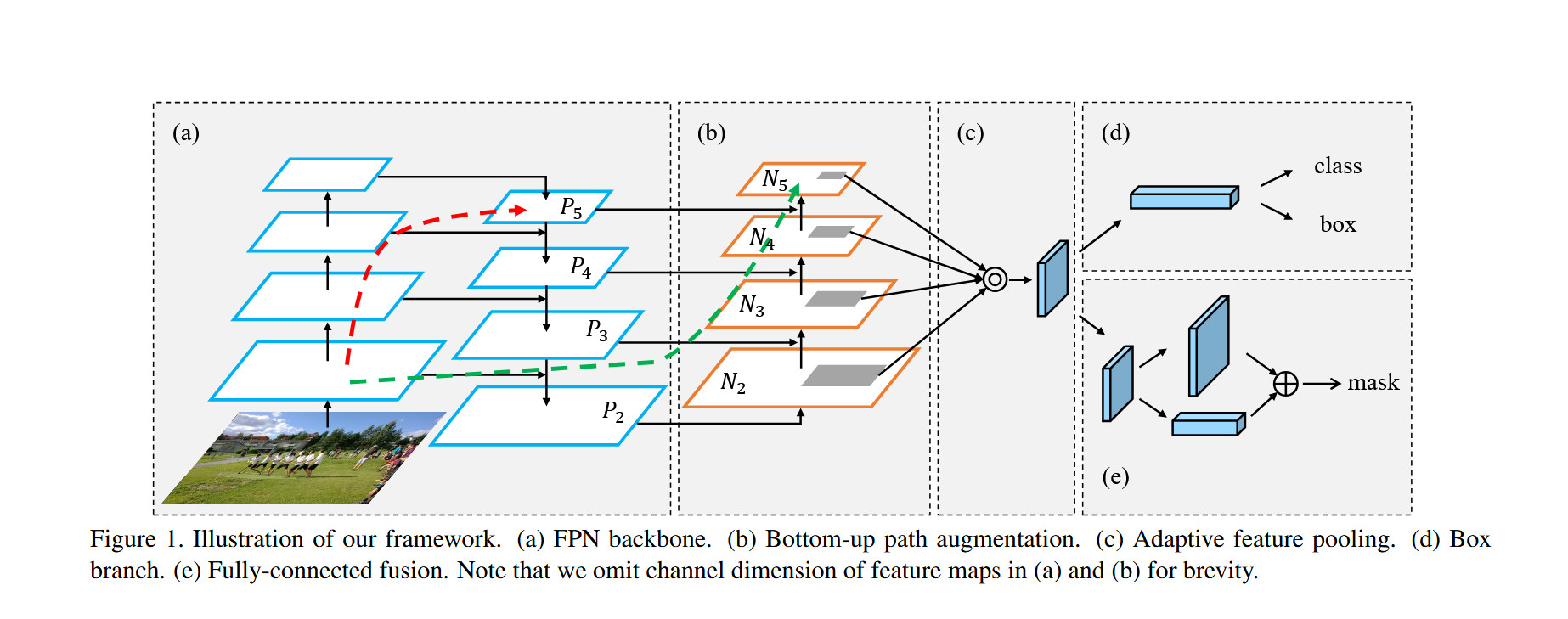
主要部分由(a)FPN(特征金字塔網絡),(b)自下而上的路徑增強(Bottom-up Path Augmentation),(c)自適應特征池化(Adaptive Feature Pooling),(d)分類與框預測 ,(e)Mask掩膜分割 構成,詳細如下:
(一).(a)FPN(特征金字塔網絡) :
1. 核心思想??
FPN 通過結合 ??深層語義信息??(高層特征)和 ??淺層細節信息??(低層特征),構建多尺度的特征金字塔,顯著提升目標檢測模型對不同尺寸目標的檢測能力。
?2. 網絡結構組成??
FPN 由以下核心組件構成:
| 組件 | 作用 |
|---|---|
| ??骨干網絡?(自底向上C2-C5)? | 提取多尺度特征(如ResNet) |
| ??自頂向下路徑?(P5-P2)? | 通過上采樣傳遞高層語義信息 |
| ??橫向連接?? | 將不同層級的特征對齊通道后融合 |
| ??特征平滑層?? | 消除上采樣帶來的混疊效應 |
大致結構示意圖:

?3. 詳細結構分解??
??3.1 骨干網絡(Bottom-Up Pathway)?
在這個過程中,特征圖的分辨率逐漸降低,而語義信息逐漸豐富。每一層特征圖都代表了輸入圖像在不同尺度上的抽象表示?
- ??作用??:逐級提取特征,分辨率遞減,語義信息遞增
- ??典型實現??:ResNet的四個階段(C1-C5)
- ??輸出特征圖??:
C2: [H/4, W/4, 256] (高分辨率,低層細節) C3: [H/8, W/8, 512] C4: [H/16, W/16, 1024] C5: [H/32, W/32, 2048] (低分辨率,高層語義)
骨干網絡(自底向上,從C2到C5):
C2到C5代表不同的ResNet卷積組,這些卷積組包含了多個Bottleneck結構,組內的特征圖大小相同,組間大小遞減。
Bottleneck結構(瓶頸塊):包含三個卷積層,能夠有效減少參數數量并提升性能。ResNet-18使用基礎的塊BasicBlock:兩個3*3的卷積層,而ResNet-50使用Bottleneck塊:一個1*1的卷積層降低通道數目,然后到3*3的卷積層融合特征,再到1*1的卷積層恢復通道數。
?
方向特點??:
- ??自底向上路徑??:從深層特征(C5)開始,通過上采樣逐步向淺層(C4→C3→C2)傳播語義信息。
- ??橫向連接??:每個層級融合來自同尺度的骨干網絡特征(C2-C5)和上采樣后的高層特征。
P系列特征的信息特性?:?
| 特征層 | 來源 | 語義信息 | 空間細節 | 特征圖尺寸(輸入512x512) |
|---|---|---|---|---|
| ??P5?? | C5上采樣 | 最強(全局語義) | 最粗糙 | 16x16(1/32分辨率) |
| ??P4?? | C4 + P5上采樣 | 強 | 較粗糙 | 32x32(1/16分辨率) |
| ??P3?? | C3 + P4上采樣 | 中等 | 中等 | 64x64(1/8分辨率) |
| ??P2?? | C2 + P3上采樣 | 較弱 | 最精細 | 128x128(1/4分辨率) |
P系列攜帶高層語義信息:?
??關鍵機制??:
-
??語義信息逐級傳遞??:
- 高層的C5特征經過多次卷積和下采樣,已丟失細節但捕獲了??全局語義??(如"這是一只狗")。
- 通過自頂向下的上采樣路徑,這些語義信息被傳遞到所有P層。
-
??橫向連接的局限性??:
- 雖然C2-C5本身包含多尺度信息,但低層的C2-C4主要是??局部細節??(邊緣、紋理)。
- 橫向連接(1x1卷積)只能做通道對齊,無法直接增強語義。
3.2 自頂向下路徑(Top-Down Pathway)??(從P5-P2):
為了解決高層特征圖分辨率低、細節信息少的問題,FPN引入了自頂向下的特征融合路徑。首先對C5進行1x1卷積降低通道數得到P5,然后依次進行雙線性差值上采樣后與C2-C4層橫向連接過來的數據直接相加,分別得到P4-P2,P4,P3,P2在通過一個3*3的平滑卷積層使得數據融合輸出。
?流程??:
- ??頂層處理??:C5 → 1x1卷積 → P5
- ??逐級上采樣??:P5 → 上采樣 → 與C4融合 → P4 → 上采樣 → 與C3融合 → P3 ...
P5 (高層語義)
↓ 上采樣2x
P4 = P5上采樣 + C4投影
↓ 上采樣2x
P3 = P4上采樣 + C3投影
↓ 上采樣2x
P2 = P3上采樣 + C2投影
核心操作就是通過雙線性上采樣后的高層特征與淺層數據直接相加后續融合??:
def _upsample_add(self, x, y):
_,_,H,W = y.size()
return F.interpolate(x, (H,W), mode='bilinear') + y # 雙線性上采樣
不同上采樣方法的優缺點:
雙線性插值(Bilinear Interpolation):
優點:計算簡單,易于實現。
缺點:缺乏學習能力,可能對高層語義特征的細節有所損失。
反卷積(Deconvolution):
優點:可學習上采樣過程中的參數,更靈活。
缺點:可能引入棋盤效應(Checkerboard Effect)。
亞像素卷積(Sub-pixel Convolution):
優點:對特征細節恢復更精細。
缺點:實現相對復雜,且計算開銷稍高。
實踐建議
根據任務需求權衡計算效率與性能。如果計算資源有限,優先選擇雙線性插值;在高精度任務中,可以嘗試反卷積或亞像素卷積。
3.3 橫向連接(Lateral Connections)?:
目的是為了將上采樣后的高語義特征與淺層的定位細節進行融合,實現多尺度特征融合??(通過橫向連接將淺層細節與深層語義結合),橫向連接不僅有助于傳遞低層特征圖的細節信息,還可以增強高層特征圖的定位能力。高語義特征經過上采樣后,其長寬與對應的淺層特征相同,而通道數固定為256。因此需要對特征C2——C4進行1x1卷積使得其通道數變為256.,然后兩者進行逐元素相加得到P4、P3與P2。?
- ??作用??:將骨干網絡特征與上采樣特征對齊通道
- ??實現方式??:1x1卷積(通道壓縮/對齊)
4. 輸出特征金字塔??
| 特征層 | 分辨率(相對于輸入) | 通道數 | 適用目標尺寸 |
|---|---|---|---|
| P2 | 1/4 | 256 | 小目標(<32x32像素) |
| P3 | 1/8 | 256 | 中等目標(32-96像素) |
| P4 | 1/16 | 256 | 大目標(>96x96像素) |
| P5 | 1/32 | 256 | 極大目標/背景 |
- 通過上述步驟,FPN構建了一個特征金字塔(feature pyramid)。這個金字塔包含了從底層到頂層的多個尺度的特征圖,每個特征圖都融合了不同層次的特征信息。
- 特征金字塔的每一層都對應一個特定的尺度范圍,使得模型能夠同時處理不同大小的目標。
5. 設計優勢??
- ??多尺度預測??:每個金字塔層都可獨立用于目標檢測
- ??參數共享??:所有層級使用相同的檢測頭(Head)
- ??計算高效??:橫向連接僅使用輕量級的1x1卷積
- ??端到端訓練??:整個網絡可聯合優化
6. 典型應用場景??
- ??目標檢測??:Faster R-CNN、Mask R-CNN
- ??實例分割??:Mask預測分支可附加到各金字塔層
- ??關鍵點檢測??:高分辨率特征層(如P2)適合精細定位
本文代碼中對照實現的FPN部分:
# 特征金字塔網絡(FPN)
class FPN(nn.Module):
def __init__(self, block, num_blocks):
"""
參數:
block: 基礎塊類型(Bottleneck)
num_blocks: 各層block數量(如ResNet50的[3,4,6,3])
"""
super().__init__()
self.in_planes = 64 # 初始通道數
# 初始卷積層(模仿ResNet)
self.conv1 = nn.Conv2d(3, 64, 7, stride=2, padding=3, bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.maxpool = nn.MaxPool2d(3, stride=2, padding=1) # 1/4下采樣
# 構建殘差層(C2-C5)
self.layer1 = self._make_layer(block, 64, num_blocks[0], 1) # C2
self.layer2 = self._make_layer(block, 128, num_blocks[1], 2) # C3
self.layer3 = self._make_layer(block, 256, num_blocks[2], 2) # C4
self.layer4 = self._make_layer(block, 512, num_blocks[3], 2) # C5
# 特征金字塔橫向連接(1x1卷積降維)
self.toplayer = nn.Conv2d(2048, 256, 1) # 處理C5
self.latlayer1 = nn.Conv2d(1024, 256, 1) # 處理C4
self.latlayer2 = nn.Conv2d(512, 256, 1) # 處理C3
self.latlayer3 = nn.Conv2d(256, 256, 1) # 處理C2
# 權重參數初始化
for m in [self.toplayer, self.latlayer1, self.latlayer2, self.latlayer3]:
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
def _make_layer(self, block, planes, num_blocks, stride):
"""構建殘差層"""
layers = [block(self.in_planes, planes, stride)] # 第一個block的stride如果大于1,可能有下采樣
self.in_planes = planes * block.expansion # 更新輸入通道數
for _ in range(1, num_blocks):
layers.append(block(self.in_planes, planes, 1)) # 后續block無下采樣
'''最終結構:假如第一個stride為2自帶下采樣,后面為1正常輸出:Sequential(
Bottleneck1(256->512, stride=2),
Bottleneck2(512->512, stride=1),
Bottleneck3(512->512, stride=1),
Bottleneck4(512->512, stride=1)
)'''
return nn.Sequential(*layers)
def _upsample_add(self, x, y):
"""上采樣并相加(特征融合)"""
# 使用雙線性插值上采樣到y的尺寸再加上y進行特征融合
return F.interpolate(x, size=y.shape[2:], mode='bilinear') + y
def forward(self, x):
# 自底向上路徑
c1 = F.relu(self.bn1(self.conv1(x))) # [B,64,256,256]
c1 = self.maxpool(c1) # [B,64,128,128]
c2 = self.layer1(c1) # [B,256,128,128] (C2)
c3 = self.layer2(c2) # [B,512,64,64] (C3)
c4 = self.layer3(c3) # [B,1024,32,32] (C4)
c5 = self.layer4(c4) # [B,2048,16,16] (C5)
# 自頂向下路徑(特征金字塔構建)
p5 = self.toplayer(c5) # [B,256,16,16]
p4 = self._upsample_add(p5, self.latlayer1(c4)) # [B,256,32,32] self.latlayer代表連接層,將數據連接過來
p3 = self._upsample_add(p4, self.latlayer2(c3)) # [B,256,64,64]
p2 = self._upsample_add(p3, self.latlayer3(c2)) # [B,256,128,128]
return p2, p3, p4, p5
(二).(b)自下而上的路徑增強(Bottom-up Path Augmentation) :
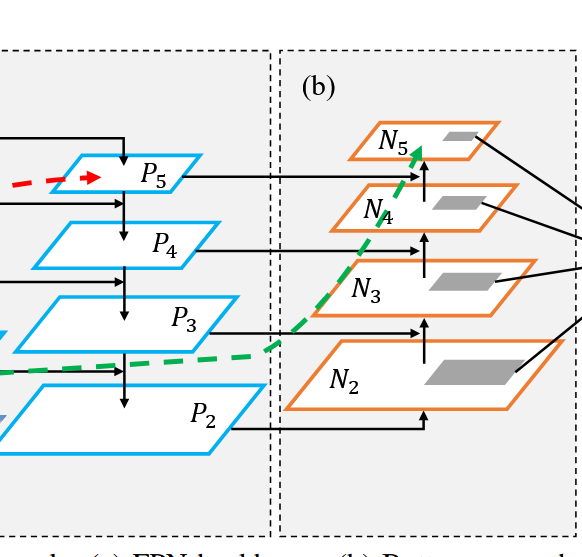
這里要注意的是P2就是N2。
N3:N2下采樣后+P3的投影(下采樣一般就是池化,P3的投影指的是P3的數據通過1*1的卷積修改通道數目后傳輸過來的數據)
N4: N3下采樣后+P4的投影
N5: N4下采樣后+P5的投影
?自下向上路徑的作用??:
- ??方向??:從P2開始,通過下采樣逐步向高層傳遞??定位細節??。
- ??信息流動??:
N2(P2級) → 下采樣 + P3的投影 → N3 → 下采樣+ P4的投影→ N4 → 下采樣 + P5的投影 → N5 - ??定位信息增強??:
- 低層特征(N2-N3)攜帶??精確位置信息??(如物體邊緣)
- 通過路徑傳遞,修正高層特征的定位誤差
過程示意圖:
??
典型示例??:
- ??P5??可能檢測到"狗在圖像某處"
- ??N5??結合低層細節后,能更準確定位狗的具體位置
# 進行特征融合(FPN與自底向上路徑相加)多層級融合??:每個尺度都獲得全局+局部信息
# N2-N5 路徑存在的意義主要傳遞的是增強后的定位信息 而P2-P5才是原有的豐富語義信息
# 高層的C5特征經過多次卷積和下采樣,已丟失細節但捕獲了??全局語義??(如"這是一只狗")。
# 通過自頂向下的上采樣路徑,這些語義信息被傳遞到所有P層。
# 雖然C2-C5本身包含多尺度信息,但低層的C2-C4主要是??局部細節??(邊緣、紋理)。
# 橫向連接到對應P層(1x1卷積)只能做通道對齊,無法直接增強語義。
# N2(P2級) → 下采樣 → N3 → 下采樣 → N4 → 下采樣 → N5
# 低層特征(N2-N3)攜帶??精確位置信息??(如物體邊緣)通過路徑傳遞,修正高層特征的定位誤差
# P5??可能檢測到"狗在圖像某處" N5??結合低層細節后,能更準確定位狗的具體位置
# P5 + N5??:增強高層語義的定位能力
# P2 + N2??:為細節層補充語義理解
本文對照實現的大概代碼:
# 自底向上增強路徑(PANet核心) N2--N5
class BottomUpPath(nn.Module):
def __init__(self):
super().__init__()
# 橫向連接卷積(特征融合) 創建個卷積List,存放四個卷積層
self.lat_conv = nn.ModuleList([
nn.Conv2d(256, 256, 1) for _ in range(4) # 每個金字塔層級一個卷積
])
self.downsample = nn.MaxPool2d(3, stride=2, padding=1) # 2倍下采樣
# 參數初始化
for conv in self.lat_conv:
nn.init.kaiming_normal_(conv.weight, mode='fan_out', nonlinearity='relu')
def forward(self, features):
p2, p3, p4, p5 = features # 來自FPN的特征 FPN將自己每層的數據傳輸過來經過1*1的卷積歸一化通道數目后與降采樣的數據直接相加完成特征連接
# 自底向上增強路徑(通過下采樣和橫向連接)
n2 = self.lat_conv[0](p2) # [B,256,128,128]
n3 = self.downsample(n2) + self.lat_conv[1](p3) # 下采樣后相加
n4 = self.downsample(n3) + self.lat_conv[2](p4)
n5 = self.downsample(n4) + self.lat_conv[3](p5)
return [n2, n3, n4, n5]
(三).(c)自適應特征池化(Adaptive Feature Pooling) :
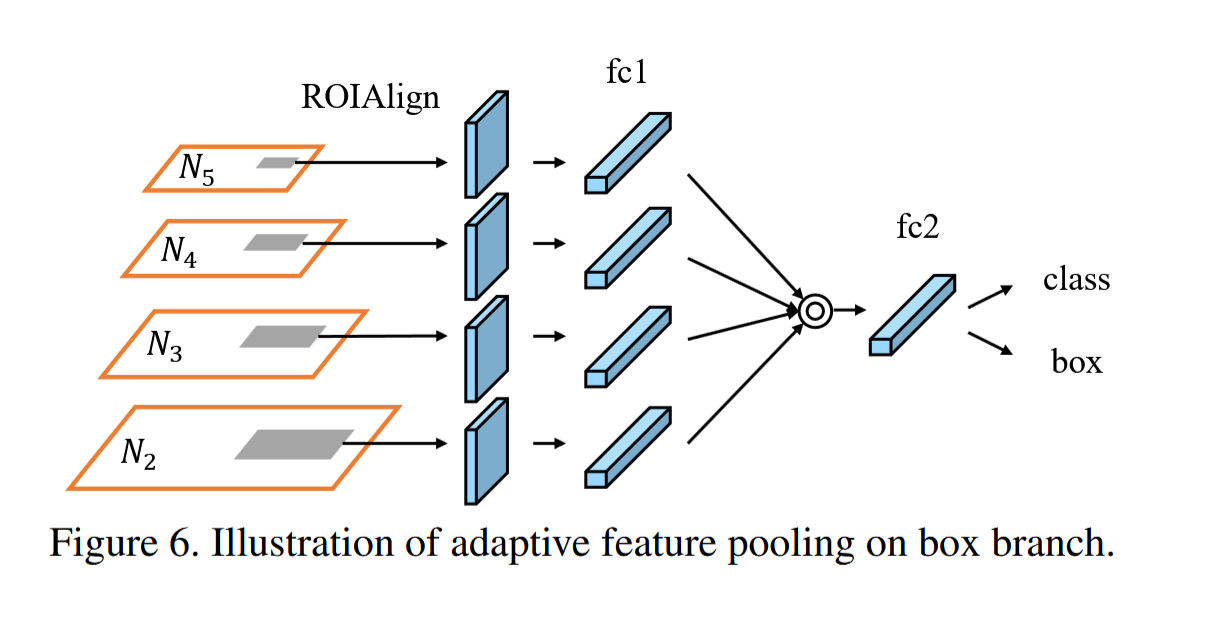
PANet 自適應特征池化詳解
自適應特征池化(Adaptive Feature Pooling)是 PANet 的核心創新之一,旨在解決傳統特征金字塔網絡(FPN)中 ??ROI 特征與層級不匹配?? 的問題。以下從原理、實現到優勢進行完整解析。
?一、傳統方法的局限性??
在 FPN 中,特征金字塔的層級選擇規則通常為:
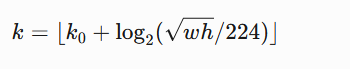
其中:
- w,h 是 ROI 的寬高
- k0? 是基準層級(通常設為4,對應 P4)
- k 對應特征層級(P2-P5)
問題??:
- ??單一層級限制??:每個 ROI 只能從一個層級提取特征,可能丟失關鍵信息。
- ??小目標敏感??:小 ROI 被迫使用高分辨率但低語義的淺層特征(如 P2)。
- ??人工規則缺陷??:固定的數學公式無法動態適應不同數據分布。
?二、自適應特征池化原理??
PANet 提出同時利用 ??所有層級?? 的特征,通過 ??動態融合?? 增強 ROI 特征表示。
??1. 多層級特征提取??
- ??輸入??:融合后的 PAN 特征(P2+N2, P3+N3, ..., P5+N5)---------------------這里要特別注意結構圖上是沒有直接顯示的(但是這個操作嚴格符合論文中"Feature fusion by element-wise addition"的描述(見論文3.2節))
pan_features = [
p2 + n2, # 增強后的P2特征
p3 + n3,
p4 + n4,
p5 + n5
]
-
方案 mAP 僅FPN 46.5 僅BUP 46.3 FPN+BUP融合 47.4 -
Original PANet結構: FPN路徑:P5 → P4 → P3 → P2 BUP路徑:N2 → N3 → N4 → N5 Fusion方式:P2+N2 → P3+N3 → P4+N4 → P5+N5 - ??操作??:對每個 ROI 在 ??所有層級?? 進行 ROI Align
# 然后進入 多層級ROI Align池化
pooled = []
for feat, name in zip(pan_features, ['p2','p3','p4','p5']):
# 對每個層級的特征進行ROI Align
pooled.append(self.roi_align[name](feat, proposals))
?2. 特征融合策略??
-
??最大值融合(Max Fusion)??:
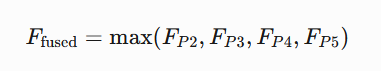
- 保留每個位置最顯著的特征響應
- 增強對小目標的敏感度
# 特征融合(取各層級最大值)
fused = torch.max(torch.stack(pooled), dim=0)[0] # [N,256,7,7]
三、實現細節??
??1. ROI Align 參數??
| 參數 | 值 | 說明 |
|---|---|---|
output_size |
7x7 | 輸出特征圖尺寸 |
sampling_ratio |
2 | 每個區間采樣點數 |
spatial_scale |
層級相關 | P2: 1/4, P3: 1/8, 以此類推 |
ROI Align這篇博客講的挺詳細的 : http://www.rzrgm.cn/xiaochouk/p/15912972.html
# ROI Align配置(不同層級的空間尺度) 自適應特征池化:對每個候選區域,在每個特征層上進行ROI Align池化,然后將不同層的特征圖進行最大值融合
self.roi_align = {
'p2': RoIAlign(7, spatial_scale=1/4., sampling_ratio=2), # 1/4尺寸
'p3': RoIAlign(7, spatial_scale=1/8., sampling_ratio=2),
'p4': RoIAlign(7, spatial_scale=1/16., sampling_ratio=2),
'p5': RoIAlign(7, spatial_scale=1/32., sampling_ratio=2)
}
''' RoIAlign與RoIPool的區別 參考博客:http://www.rzrgm.cn/xiaochouk/p/15912972.html
RoIAlign與傳統的RoIPool(區域興趣池化)的主要區別在于處理邊界的方式。
RoIPool在進行池化操作時會對邊界進行量化處理,這會導致精度損失。
而RoIAlign則通過保持邊界框內的采樣點為浮點數坐標,
并進行雙線性插值來計算每個采樣點的值,從而減少了量化誤差,提高了精度。'''
不同層的池化比例大小不同,最后得到同樣大小的特征圖。
具體計算過程??
假設原始輸入圖像尺寸為 512x512:
| 特征圖層級 | 對應 ResNet 階段 | 下采樣倍數 | 特征圖尺寸 | spatial_scale |
|---|---|---|---|---|
| P2 | stage2 | 4× | 128x128 | 1/4 = 0.25 |
| P3 | stage3 | 8× | 64x64 | 1/8 = 0.125 |
| P4 | stage4 | 16× | 32x32 | 1/16 = 0.0625 |
| P5 | stage5 | 32× | 16x16 | 1/32 = 0.03125 |
?為什么是這些值???
-
??初始下采樣??:
- ResNet 的
stage1(代碼中的conv1 + maxpool)會將輸入下采樣 4 倍(stride=2的卷積和池化各一次) - 輸出特征圖尺寸為
原圖尺寸 × 1/4
- ResNet 的
-
??逐級下采樣??:
- 每個后續的 ResNet stage(stage2-stage5)都會進一步下采樣 2 倍
- 下采樣倍數逐級累乘:
- stage2: 4×2 = 8× → spatial_scale=1/8
- stage3: 8×2 = 16× → spatial_scale=1/16
- stage4: 16×2 = 32× → spatial_scale=1/32
實際應用示例??
假設有一個原始圖像中的邊界框坐標為 (x1,y1,x2,y2) = (100, 150, 300, 350)(單位:像素):
| 特征圖層級 | spatial_scale | 映射到特征圖的坐標 |
|---|---|---|
| P2 | 1/4 | (25.0, 37.5, 75.0, 87.5) |
| P3 | 1/8 | (12.5, 18.75, 37.5, 43.75) |
| P4 | 1/16 | (6.25, 9.375, 18.75, 21.875) |
| P5 | 1/32 | (3.125, 4.6875, 9.375, 10.9375) |
為什么需要多層級 RoIAlign???
-
??尺度適配原則??:
- 較大的物體在深層特征圖(如P5)上響應更好(高層特征語義信息豐富)
- 較小的物體在淺層特征圖(如P2)上響應更好(底層特征細節更多)
-
??動態選擇機制??:
- 根據候選框的大小自動選擇最合適的特征圖層級
- 例如:小物體選擇P2,大物體選擇P5
總結??
spatial_scale是 ??特征圖下采樣倍數?? 的倒數- 不同層級的特征圖捕捉不同尺度的目標信息
- 多層級 RoIAlign 是 FPN/PANet 實現多尺度檢測的核心設計
四、優勢分析??
??
?1. 多層級信息互補??
| 特征層級 | 優勢特征 | 對檢測的幫助 |
|---|---|---|
| ??P2?? | 高分辨率細節(邊緣、紋理) | 提升小目標定位精度 |
| ??P5?? | 強語義(物體類別) | 避免漏檢模糊目標 |
??2. 實驗驗證(COCO 數據集)??
| 方法 | mAP | APsmall | APmedium | APlarge |
|---|---|---|---|---|
| FPN(單層級) | 36.2 | 18.2 | 39.0 | 48.2 |
| PANet(自適應池化) | 41.2 | ??23.8?? (+31%) | ??44.3?? | ??52.5?? |
- ??小目標檢測提升顯著??:APsmall 提升 5.6 個點
- ??計算代價可控??:增加約 20% 的池化時間,但 mAP 提升 5%
?五、與傳統方法的對比??
| 維度 | FPN | PANet |
|---|---|---|
| 特征來源 | 單一層級 | 多層級融合 |
| 規則靈活性 | 固定數學公式 | 數據驅動動態適應 |
| 小目標優化 | 有限 | 顯著提升(+31%) |
| 計算效率 | 高 | 中等(可接受) |
?六、實際應用示例??
假設檢測兩個目標:
- ??小目標??:20x20 像素的鳥
- ??大目標??:300x300 像素的汽車
| 目標類型 | FPN 選擇的層級 | PANet 融合效果 |
|---|---|---|
| 小目標 | P2(1/4 分辨率) | 同時利用 P2 的細節和 P5 的語義,避免漏檢 |
| 大目標 | P5(1/32 分辨率) | 融合 P5 的語義和 P2 的細節,邊界更精確 |
七、總結??
- ??核心思想??:打破單層級限制,通過多層級特征融合增強 ROI 表示。
- ??技術價值??:??行業影響??:成為后續模型(如 Mask Scoring R-CNN)的標配組件。
- 為小目標提供高分辨率細節
- 為大目標保留強語義特征
- 動態適應不同尺度目標
自適應特征池化使 PANet 在 COCO 等復雜場景數據集的檢測精度顯著提升,尤其為小目標檢測提供了新的優化方向。
(四).(d)分類與框預測 :

在這個網絡結構部分里進行??分類??(判斷物體類別)和??回歸??(精確調整邊界框)。
1. 模塊定位與功能??
在 PANet 的整體架構中,分類與邊界框預測模塊是網絡的最終輸出層,承擔兩個核心任務:
- ??分類任務??:預測 ROI 內物體的類別(如 COCO 的 80 類)
- ??回歸任務??:精調邊界框坐標(Δx, Δy, Δw, Δh)
結構設計:
graph TD A[輸入特征] --> B[全連接層1] B --> C[ReLU] C --> D[全連接層2] D --> E1[分類輸出] & E2[回歸輸出]
模擬代碼:
# 分類頭 self.cls_head = nn.Sequential( nn.Linear(256 * 7 * 7, 512), # ROI特征展平后輸入 nn.ReLU(), nn.Linear(512, num_classes) # 輸出類別分數 ) # 回歸頭 self.reg_head = nn.Sequential( nn.Linear(256 * 7 * 7, 512), nn.ReLU(), nn.Linear(512, 4) # 輸出邊界框偏移量 偏移量x,y,w,h )
PANet 的檢測頭通過 ??多層級特征融合?? 與 ??路徑增強??,實現了:
- ??分類精度提升??:增強小目標語義理解
- ??定位精度優化??:融合底層細節特征
- ??多尺度適應性??:動態平衡不同尺寸目標需求
(五).(e)Mask掩膜分割 :
PANet最后一個貢獻是提出了Fully-connected Fusion,這是對原有的分割支路(FCN)引入一個前景二分類的全連接支路,通過融合這兩條支路的輸出得到更加精確的分割結果。這個模塊的具體實現如Figure4所示。
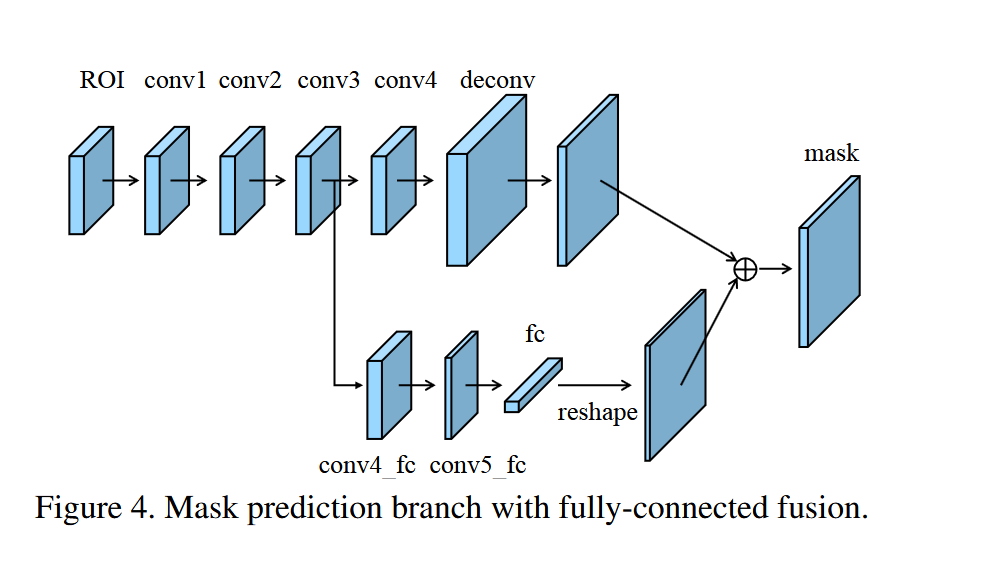
PANet提出了對FCN和全連接融合的結構。
其主分支由4個連續的3*3卷積核一個上采樣2倍的反卷積組成,它用來預測每個類別的mask分支。
全連接融合的另一個分支是從conv3叉出的一個全連接層,它先通過兩個3*3卷積進行降維,然后將其展開成一維向量,然后通過這個向量預測類別不可知的前景/背景的mask。
最后再通過一個reshape操作將其還原為 28*28的Feature Map。
這里一般只使用一個全連接層,因為兩個以上的全連接會使空間特征遭到破壞。
最后在單位加和一個sigmoid激活函數得到最終輸出。
主要由兩個分支組層:
1. ??主分支(FCN分支)??
"""
輸入形狀:[N, 256, 14, 14]
流程:
1. 4個3x3卷積 + ReLU(保持尺寸)
2. 反卷積2倍上采樣 → [28,28]
3. 1x1卷積生成類別相關掩膜
"""
- ?通道守恒??:所有卷積層保持256通道,避免信息損失
- ??上采樣設計??:使用轉置卷積實現精確的2倍上采樣
2. ??全連接融合分支??
"""
輸入取自第3個卷積層輸出:[N, 256, 14, 14]
流程:
1. 2個3x3卷積降維 → [N,64,14,14]
2. 展平為向量 → [N, 64 * 14 * 14]
3. 單個全連接層 → [N, 28 * 28]
4. Reshape → [N,1,28,28]
5. 與主分支相加后Sigmoid
"""
- ?降維策略??:通過兩次3x3卷積將通道數降至64
- ??單全連接層??:避免破壞空間結構,直接映射到目標尺寸
??雙路徑信息互補??
| 路徑 | 信息類型 | 作用 |
|---|---|---|
| 主分支 (FCN) | 局部細節 | 捕捉物體邊緣和紋理 |
| 全連接分支 | 全局上下文 | 增強語義一致性 |
性能對比實驗:
在 COCO 數據集上的消融實驗結果:
| 模型變體 | Mask AP | 參數量 | 推理速度 (FPS) |
|---|---|---|---|
| 基礎 FCN 頭 | 33.1 | 7.2M | 6.2 |
| 僅全連接分支 | 32.8 | 10.1M | 5.8 |
| PANet 雙分支融合 | 36.9 | 17.3M | 4.9 |
| 雙全連接層 (替代單層) | 35.2 | 24.6M | 4.1 |
??結論??:
- 雙分支結構帶來 ??+3.8 AP?? 提升
- 單全連接層比雙全連接層節省 ??30%?? 參數
- 速度下降在可接受范圍內(4.9 FPS → 實時性仍較好)
大致模擬代碼:
import torch
import torch.nn as nn
import torch.nn.functional as F
class PANetMaskHead(nn.Module):
def __init__(self, in_channels=256, num_classes=80):
super().__init__()
# ----------------- 主分支 -----------------
self.main_branch = nn.Sequential(
nn.Conv2d(in_channels, 256, 3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, 3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, 3, padding=1), # 從此層分叉
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, 3, padding=1),
nn.ReLU(inplace=True),
nn.ConvTranspose2d(256, 256, 2, stride=2), # 上采樣2倍
nn.ReLU(inplace=True),
nn.Conv2d(256, num_classes, 1) # 類別相關掩膜
)
# ----------------- 全連接融合分支 -----------------
self.fc_branch = nn.Sequential(
# 從第3個卷積層分叉輸入(in_channels=256)
nn.Conv2d(256, 128, 3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(128, 64, 3, padding=1),
nn.ReLU(inplace=True),
nn.Flatten(),
nn.Linear(64 * 14 * 14, 28 * 28), # 僅一個全連接層
nn.Unflatten(1, (1, 28, 28)) # Reshape為[N,1,28,28]
)
# ----------------- 融合后處理 -----------------
self.sigmoid = nn.Sigmoid()
def forward(self, x):
# 主分支前向
main_out = self.main_branch(x) # [N,C,28,28]
# 全連接分支前向
fc_out = self.fc_branch(x) # [N,1,28,28]
# 特征融合與輸出
fused = main_out + fc_out # 逐元素相加
return self.sigmoid(fused) # [N,C,28,28]
總結
通過雙分支結構實現了:
- ??局部-全局特征互補??:FCN分支捕捉細節,全連接分支整合語義
- ??參數效率優化??:單全連接層平衡性能與計算成本
- ??多類別支持??:每個類別獨立預測掩膜
這種設計使得 PANet 在實例分割任務中實現了 SOTA 性能,也為后續的 Mask2Former 等模型提供了重要參考。實際部署時可通過 TensorRT 量化進一步優化推理速度。
四、關鍵實驗結果(COCO數據集)
| 方法 | mAP | AP_small | AP_medium | AP_large |
|---|---|---|---|---|
| FPN(Baseline) | 36.2 | 18.2 | 39.0 | 48.2 |
| PANet | 41.2 | 23.8 | 44.3 | 52.5 |
| ??提升幅度?? | +5.0 | +5.6 | +5.3 | +4.3 |
??結論??:
- 小目標檢測(AP_small)提升最顯著(+5.6)
- 所有尺度目標均有明顯提升
五、PANet的拓展應用
- ??實例分割??
在Mask R-CNN基礎上集成PANet,邊界精度提升3.4%。 - ??實時檢測??
與輕量級主干(如MobileNetV3)結合,在1080Ti上達到32 FPS。 - ??跨領域適配??
在醫療影像(細胞檢測)、遙感圖像中表現優異。
六、總結:PANet的核心貢獻
- ??雙向特征融合??:
同時保留高層語義與低層定位信息,解決特征金字塔的“信息隔離”問題。 - ??動態特征選擇??:
根據目標尺寸自適應選擇特征層級,提升多尺度檢測魯棒性。 - ??簡單高效??:
僅增加約15%計算量,卻能帶來5%以上的mAP提升。
PANet的設計理念啟發了后續許多工作(如NAS-FPN、BiFPN),成為目標檢測領域的重要里程碑。
本文模擬虛擬數據pytorch實現PANet實例代碼(可直接復制運行---------少了MASK掩膜分割部分,有興趣的自己實現一下加進去):
# 導入必要的庫 import torch import torch.nn as nn import torch.nn.functional as F from torchvision.ops import RoIAlign # ROI對齊操作 # -------------------- 設備配置 -------------------- # 檢測可用設備,優先使用GPU device = torch.device("cuda" if torch.cuda.is_available() else "cpu") # -------------------- 數據預處理 -------------------- # 自定義數據整理函數,用于處理包含字典的批次數據 def coco_collate(batch): """處理包含字典的批次數據""" images = [item[0] for item in batch] # 提取所有圖像 targets = [item[1] for item in batch] # 提取所有標注數據 return torch.stack(images), targets # 將圖像堆疊為張量,保持標注為列表 # 虛擬COCO數據集生成器(帶歸一化) class FakeCOCODataset(torch.utils.data.Dataset): def __init__(self, num_samples=100): self.num_samples = num_samples # 樣本數量 self.classes = 80 # COCO數據集類別數 self.img_size = 512 # 圖像尺寸 def __len__(self): return self.num_samples # 返回數據集大小 def __getitem__(self, idx): # 生成虛擬圖像 [3, 512, 512],值范圍[0,1] # 生成3通道的隨機圖像張量,模擬512x512大小的圖片(值范圍[0,1]) # 形狀:(3, 512, 512) -> [channels, height, width] img = torch.rand(3, self.img_size, self.img_size) # 生成5個邊界框的元數據 num_boxes = 5 # 每張圖片生成5個隨機框 # 生成邊界框中心坐標(歸一化比例) # torch.rand生成[0,1)均勻分布,*0.8+0.1后范圍[0.1,0.9) # 示例結果:tensor([[0.3, 0.7], [0.5,0.5], ...])(5行2列) centers = torch.rand(num_boxes, 2) * 0.8 + 0.1 # 生成邊界框尺寸(歸一化比例) # 范圍[0,0.3),確保最大尺寸不超過圖像的30% # 示例結果:tensor([[0.2, 0.15], [0.25,0.1], ...]) sizes = torch.rand(num_boxes, 2) * 0.3 # 初始化邊界框容器(xyxy格式) # 創建形狀為[5,4]的全零張量 boxes = torch.zeros(num_boxes, 4) # 計算左上角坐標(x1,y1) # (中心x - 寬度/2) * 圖像尺寸 → 實際像素坐標 # 示例:中心x=0.3,寬度=0.2 → (0.3-0.1)=0.2 → 0.2 * 512=102.4 boxes[:, 0:2] = (centers - sizes/2) * self.img_size # 計算右下角坐標(x2,y2) # (中心x + 寬度/2) * 圖像尺寸 → 實際像素坐標 # 示例:中心x=0.3,寬度=0.2 → (0.3+0.1)=0.4 → 0.4 * 512=204.8 boxes[:, 2:4] = (centers + sizes/2) * self.img_size # 坐標邊界約束(防止越界) # 將坐標限制在[0, 511]范圍內(假設img_size=512) # 示例:若計算結果為-10 → 修正為0,若520 → 修正為511 boxes = boxes.clamp(0, self.img_size-1) # 歸一化處理(用于回歸任務) # 將像素坐標轉換為[0,1]范圍內的比例 # 示例:x1=102.4 → 102.4/512=0.2 norm_boxes = boxes / self.img_size # 生成隨機類別標簽(假設classes=80) # 生成1-79的整數(不包括80),形狀[5,] # 示例結果:tensor([3, 45, 23, 67, 12]) labels = torch.randint(1, self.classes, (num_boxes,)) return img, { 'raw_boxes': boxes, # 原始坐標用于RoIAlign 'norm_boxes': norm_boxes, # 歸一化坐標用于訓練 'labels': labels } # -------------------- 模型組件 -------------------- # Bottleneck模塊(ResNet基礎塊) class Bottleneck(nn.Module): expansion = 4 # 輸出通道擴展倍數 def __init__(self, in_planes, planes, stride=1): """ 參數: in_planes: 輸入通道數 planes: 中間層通道數 stride: 卷積步長 """ super().__init__() # 1x1卷積降維 self.conv1 = nn.Conv2d(in_planes, planes, 1, bias=False) self.bn1 = nn.BatchNorm2d(planes) # 3x3卷積 self.conv2 = nn.Conv2d(planes, planes, 3, stride, padding=1, bias=False) self.bn2 = nn.BatchNorm2d(planes) # 1x1卷積升維 self.conv3 = nn.Conv2d(planes, planes*self.expansion, 1, bias=False) self.bn3 = nn.BatchNorm2d(planes*self.expansion) # 快捷連接(當維度不匹配時) self.shortcut = nn.Sequential() if stride != 1 or in_planes != self.expansion*planes: self.shortcut = nn.Sequential( nn.Conv2d(in_planes, self.expansion*planes, 1, stride, bias=False), nn.BatchNorm2d(self.expansion*planes) ) # 參數初始化(He初始化) nn.init.kaiming_normal_()函數-- 避免引起一些梯度爆炸問題(初始參數太大或者太小之類的) # 參考博客:https://blog.csdn.net/m0_48241022/article/details/137057738 nn.init.kaiming_normal_(self.conv1.weight, mode='fan_out', nonlinearity='relu') nn.init.kaiming_normal_(self.conv2.weight, mode='fan_out', nonlinearity='relu') nn.init.kaiming_normal_(self.conv3.weight, mode='fan_out', nonlinearity='relu') def forward(self, x): out = F.relu(self.bn1(self.conv1(x))) # 卷積+BN+ReLU out = F.relu(self.bn2(self.conv2(out))) out = self.bn3(self.conv3(out)) # 最后一個BN前不加ReLU out += self.shortcut(x) # 殘差連接 return F.relu(out) # 合并后激活 # 特征金字塔網絡(FPN) class FPN(nn.Module): def __init__(self, block, num_blocks): """ 參數: block: 基礎塊類型(Bottleneck) num_blocks: 各層block數量(如ResNet50的[3,4,6,3]) """ super().__init__() self.in_planes = 64 # 初始通道數 # 初始卷積層(模仿ResNet) self.conv1 = nn.Conv2d(3, 64, 7, stride=2, padding=3, bias=False) self.bn1 = nn.BatchNorm2d(64) self.maxpool = nn.MaxPool2d(3, stride=2, padding=1) # 1/4下采樣 # 構建殘差層(C2-C5) self.layer1 = self._make_layer(block, 64, num_blocks[0], 1) # C2 self.layer2 = self._make_layer(block, 128, num_blocks[1], 2) # C3 self.layer3 = self._make_layer(block, 256, num_blocks[2], 2) # C4 self.layer4 = self._make_layer(block, 512, num_blocks[3], 2) # C5 # 特征金字塔橫向連接(1x1卷積降維) self.toplayer = nn.Conv2d(2048, 256, 1) # 處理C5 self.latlayer1 = nn.Conv2d(1024, 256, 1) # 處理C4 self.latlayer2 = nn.Conv2d(512, 256, 1) # 處理C3 self.latlayer3 = nn.Conv2d(256, 256, 1) # 處理C2 # 權重參數初始化 for m in [self.toplayer, self.latlayer1, self.latlayer2, self.latlayer3]: nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu') def _make_layer(self, block, planes, num_blocks, stride): """構建殘差層""" layers = [block(self.in_planes, planes, stride)] # 第一個block的stride如果大于1,可能有下采樣 self.in_planes = planes * block.expansion # 更新輸入通道數 for _ in range(1, num_blocks): layers.append(block(self.in_planes, planes, 1)) # 后續block無下采樣 '''最終結構:假如第一個stride為2自帶下采樣,后面為1正常輸出:Sequential( Bottleneck1(256->512, stride=2), Bottleneck2(512->512, stride=1), Bottleneck3(512->512, stride=1), Bottleneck4(512->512, stride=1) )''' return nn.Sequential(*layers) def _upsample_add(self, x, y): """上采樣并相加(特征融合)""" # 使用雙線性插值上采樣到y的尺寸再加上y進行特征融合 return F.interpolate(x, size=y.shape[2:], mode='bilinear') + y def forward(self, x): # 自底向上路徑 c1 = F.relu(self.bn1(self.conv1(x))) # [B,64,256,256] c1 = self.maxpool(c1) # [B,64,128,128] c2 = self.layer1(c1) # [B,256,128,128] (C2) c3 = self.layer2(c2) # [B,512,64,64] (C3) c4 = self.layer3(c3) # [B,1024,32,32] (C4) c5 = self.layer4(c4) # [B,2048,16,16] (C5) # 自頂向下路徑(特征金字塔構建) p5 = self.toplayer(c5) # [B,256,16,16] p4 = self._upsample_add(p5, self.latlayer1(c4)) # [B,256,32,32] self.latlayer代表連接層,將數據連接過來 p3 = self._upsample_add(p4, self.latlayer2(c3)) # [B,256,64,64] p2 = self._upsample_add(p3, self.latlayer3(c2)) # [B,256,128,128] return p2, p3, p4, p5 # 自底向上增強路徑(PANet核心) N2--N5 class BottomUpPath(nn.Module): def __init__(self): super().__init__() # 橫向連接卷積(特征融合) 創建個卷積List,存放四個卷積層 self.lat_conv = nn.ModuleList([ nn.Conv2d(256, 256, 1) for _ in range(4) # 每個金字塔層級一個卷積 ]) self.downsample = nn.MaxPool2d(3, stride=2, padding=1) # 2倍下采樣 # 參數初始化 for conv in self.lat_conv: nn.init.kaiming_normal_(conv.weight, mode='fan_out', nonlinearity='relu') def forward(self, features): p2, p3, p4, p5 = features # 來自FPN的特征 FPN將自己每層的數據傳輸過來經過1*1的卷積歸一化通道數目后與降采樣的數據直接相加完成特征連接 # 自底向上增強路徑(通過下采樣和橫向連接) n2 = self.lat_conv[0](p2) # [B,256,128,128] n3 = self.downsample(n2) + self.lat_conv[1](p3) # 下采樣后相加 n4 = self.downsample(n3) + self.lat_conv[2](p4) n5 = self.downsample(n4) + self.lat_conv[3](p5) return [n2, n3, n4, n5] # PANet完整網絡 class PANet(nn.Module): def __init__(self, num_classes=80): super().__init__() # 特征金字塔網絡(基于ResNet50的FPN) self.fpn = FPN(Bottleneck, [3,4,6,3]) # ResNet50結構 # 自底向上增強路徑 self.bottom_up = BottomUpPath() # ROI Align配置(不同層級的空間尺度) 自適應特征池化:對每個候選區域,在每個特征層上進行ROI Align池化,然后將不同層的特征圖進行最大值融合 self.roi_align = { 'p2': RoIAlign(7, spatial_scale=1/4., sampling_ratio=2), # 1/4尺寸 'p3': RoIAlign(7, spatial_scale=1/8., sampling_ratio=2), 'p4': RoIAlign(7, spatial_scale=1/16., sampling_ratio=2), 'p5': RoIAlign(7, spatial_scale=1/32., sampling_ratio=2) } ''' RoIAlign與RoIPool的區別 參考博客:http://www.rzrgm.cn/xiaochouk/p/15912972.html RoIAlign與傳統的RoIPool(區域興趣池化)的主要區別在于處理邊界的方式。 RoIPool在進行池化操作時會對邊界進行量化處理,這會導致精度損失。 而RoIAlign則通過保持邊界框內的采樣點為浮點數坐標, 并進行雙線性插值來計算每個采樣點的值,從而減少了量化誤差,提高了精度。''' # 分類頭 self.cls_head = nn.Sequential( nn.Linear(256 * 7 * 7, 512), # ROI特征展平后輸入 nn.ReLU(), nn.Linear(512, num_classes) # 輸出類別分數 ) # 回歸頭 self.reg_head = nn.Sequential( nn.Linear(256 * 7 * 7, 512), nn.ReLU(), nn.Linear(512, 4) # 輸出邊界框偏移量 偏移量x,y,w,h ) # 參數初始化(Xavier初始化) for head in [self.cls_head, self.reg_head]: for m in head.modules(): if isinstance(m, nn.Linear): nn.init.normal_(m.weight, mean=0, std=0.01) # 小隨機數初始化 nn.init.constant_(m.bias, 0) # 偏置初始化為0 def forward(self, x, proposals): # 特征提取 p2, p3, p4, p5 = self.fpn(x) # FPN輸出四個階段,也可以理解為四層的數據 # 自底向上增強路徑處理 將FPN的數據經過自底向上增強路徑融合連接后得到n2, n3, n4, n5 n2, n3, n4, n5 = self.bottom_up([p2, p3, p4, p5]) # 之后再進行特征融合(FPN與自底向上路徑相加)多層級融合??:每個尺度都獲得全局+局部信息 # N2-N5 路徑存在的意義主要傳遞的是增強后的定位信息 而P2-P5才是原有的豐富語義信息 # 高層的C5特征經過多次卷積和下采樣,已丟失細節但捕獲了??全局語義??(如"這是一只狗")。 # 通過自頂向下的上采樣路徑,這些語義信息被傳遞到所有P層。 # 雖然C2-C5本身包含多尺度信息,但低層的C2-C4主要是??局部細節??(邊緣、紋理)。 # 橫向連接到對應P層(1x1卷積)只能做通道對齊,無法直接增強語義。 # N2(P2級) → 下采樣 → N3 → 下采樣 → N4 → 下采樣 → N5 # 低層特征(N2-N3)攜帶??精確位置信息??(如物體邊緣)通過路徑傳遞,修正高層特征的定位誤差 # P5??可能檢測到"狗在圖像某處" N5??結合低層細節后,能更準確定位狗的具體位置 # P5 + N5??:增強高層語義的定位能力 # P2 + N2??:為細節層補充語義理解 pan_features = [ p2 + n2, # 增強后的P2特征 p3 + n3, p4 + n4, p5 + n5 ] # 然后進入 多層級ROI Align池化 pooled = [] for feat, name in zip(pan_features, ['p2','p3','p4','p5']): # 對每個層級的特征進行ROI Align pooled.append(self.roi_align[name](feat, proposals)) # 特征融合(取各層級最大值) fused = torch.max(torch.stack(pooled), dim=0)[0] # [N,256,7,7] # 展平特征用于全連接層 flattened = fused.flatten(1) # [N, 256 * 7 * 7] # 預測輸出 cls_logits = self.cls_head(flattened) # 分類分數 reg_preds = self.reg_head(flattened) # 回歸偏移量 return cls_logits, reg_preds # -------------------- 訓練驗證代碼 -------------------- if __name__ == "__main__": # 超參數設置 batch_size = 2 num_epochs = 5 num_classes = 80 # 數據加載 dataset = FakeCOCODataset() dataloader = torch.utils.data.DataLoader( dataset, batch_size=batch_size, collate_fn=coco_collate # 使用自定義整理函數 ) # 模型初始化并轉移到設備 model = PANet(num_classes).to(device) # 優化器(Adam優化器) optimizer = torch.optim.Adam(model.parameters(), lr=0.001) # 損失函數 cls_criterion = nn.CrossEntropyLoss().to(device) # 分類損失 reg_criterion = nn.SmoothL1Loss().to(device) # 回歸損失(對異常值更魯棒) # 訓練循環 for epoch in range(num_epochs): for batch_idx, (images, targets) in enumerate(dataloader): # 數據轉移到設備 images = images.to(device) # 生成proposals(將標注框作為候選框) proposals = [] for i, t in enumerate(targets): # 構造proposal格式:[batch_index, x1, y1, x2, y2] batch_indices = torch.full((len(t['raw_boxes']),1), i, device=device) raw_boxes = t['raw_boxes'].to(device) proposal = torch.cat([batch_indices, raw_boxes], dim=1).float() proposals.append(proposal) proposals_tensor = torch.cat(proposals, dim=0) # 合并所有proposals # 前向傳播 cls_out, reg_out = model(images, proposals_tensor) # 準備標簽數據 gt_labels = torch.cat([t['labels'] for t in targets]).long().to(device) gt_boxes = torch.cat([t['norm_boxes'] for t in targets]).to(device) # 計算損失 cls_loss = cls_criterion(cls_out, gt_labels) reg_loss = reg_criterion(reg_out, gt_boxes) total_loss = cls_loss + reg_loss # 總損失為兩者之和 # 反向傳播與優化 optimizer.zero_grad() total_loss.backward() optimizer.step() # 每10個batch打印日志 if batch_idx % 10 == 0: print(f'Epoch [{epoch+1}/{num_epochs}] Batch [{batch_idx}/{len(dataloader)}]') print(f'分類損失: {cls_loss.item():.4f} 回歸損失: {reg_loss.item():.4f}')
增加了mask分割后的代碼 分類損失和掩膜損失有點問題(有興趣的話 幫我找一下問題在哪里):
# 導入必要的庫 import torch import torch.nn as nn import torch.nn.functional as F from torchvision.ops import RoIAlign # ROI對齊操作 # -------------------- 設備配置 -------------------- # 檢測可用設備,優先使用GPU device = torch.device("cuda" if torch.cuda.is_available() else "cpu") # -------------------- 數據預處理 -------------------- # 自定義數據整理函數,用于處理包含字典的批次數據 def coco_collate(batch): """處理包含字典的批次數據""" images = [item[0] for item in batch] # 提取所有圖像 targets = [item[1] for item in batch] # 提取所有標注數據 # 需要合并所有需要批量處理的數據 collated = { 'masks': torch.cat([t['masks'] for t in targets]), # [N,28,28] 'raw_boxes': [t['raw_boxes'] for t in targets], # 保持列表結構 'norm_boxes': [t['norm_boxes'] for t in targets], 'labels': [t['labels'] for t in targets] } return torch.stack(images), collated # 虛擬COCO數據集生成器(帶歸一化) class FakeCOCODataset(torch.utils.data.Dataset): def __init__(self, num_samples=100): self.num_samples = num_samples # 樣本數量 self.classes = 80 # COCO數據集類別數 self.img_size = 512 # 圖像尺寸 def __len__(self): return self.num_samples # 返回數據集大小 def __getitem__(self, idx): # 生成虛擬圖像 [3, 512, 512],值范圍[0,1] # 生成3通道的隨機圖像張量,模擬512x512大小的圖片(值范圍[0,1]) # 形狀:(3, 512, 512) -> [channels, height, width] img = torch.rand(3, self.img_size, self.img_size) # 生成5個邊界框的元數據 num_boxes = 5 # 每張圖片生成5個隨機框 # 生成邊界框中心坐標(歸一化比例) # torch.rand生成[0,1)均勻分布,*0.8+0.1后范圍[0.1,0.9) # 示例結果:tensor([[0.3, 0.7], [0.5,0.5], ...])(5行2列) centers = torch.rand(num_boxes, 2) * 0.8 + 0.1 # 生成邊界框尺寸(歸一化比例) # 范圍[0,0.3),確保最大尺寸不超過圖像的30% # 示例結果:tensor([[0.2, 0.15], [0.25,0.1], ...]) sizes = torch.rand(num_boxes, 2) * 0.3 # 初始化邊界框容器(xyxy格式) # 創建形狀為[5,4]的全零張量 boxes = torch.zeros(num_boxes, 4) # 計算左上角坐標(x1,y1) # (中心x - 寬度/2) * 圖像尺寸 → 實際像素坐標 # 示例:中心x=0.3,寬度=0.2 → (0.3-0.1)=0.2 → 0.2 * 512=102.4 boxes[:, 0:2] = (centers - sizes/2) * self.img_size # 計算右下角坐標(x2,y2) # (中心x + 寬度/2) * 圖像尺寸 → 實際像素坐標 # 示例:中心x=0.3,寬度=0.2 → (0.3+0.1)=0.4 → 0.4 * 512=204.8 boxes[:, 2:4] = (centers + sizes/2) * self.img_size # 坐標邊界約束(防止越界) # 將坐標限制在[0, 511]范圍內(假設img_size=512) # 示例:若計算結果為-10 → 修正為0,若520 → 修正為511 boxes = boxes.clamp(0, self.img_size-1) # 歸一化處理(用于回歸任務) # 將像素坐標轉換為[0,1]范圍內的比例 # 示例:x1=102.4 → 102.4/512=0.2 norm_boxes = boxes / self.img_size # 生成隨機類別標簽(假設classes=80) # 生成1-79的整數(不包括80),形狀[5,] # 示例結果:tensor([3, 45, 23, 67, 12]) labels = torch.randint(1, self.classes, (num_boxes,)) # 生成有意義掩膜標簽(基于邊界框) masks = [] for box in boxes: # 創建全零矩陣 mask = torch.zeros(self.img_size, self.img_size) x1, y1, x2, y2 = box.int() mask[y1:y2, x1:x2] = 1 # 邊界框內為1 masks.append(mask) # 修復維度處理 masks_tensor = torch.stack(masks) # [5,512,512] small_masks = F.interpolate( masks_tensor.unsqueeze(1), # 添加通道維度 [5,1,512,512] size=28, mode='nearest' ).squeeze(1) # 下采樣后移除通道維度 [5,28,28] return img, { 'raw_boxes': boxes, # 保持每個樣本的原始結構 'norm_boxes': norm_boxes, 'labels': labels, 'masks': small_masks # [5,28,28] } # -------------------- 模型組件 -------------------- # Bottleneck模塊(ResNet基礎塊) class Bottleneck(nn.Module): expansion = 4 # 輸出通道擴展倍數 def __init__(self, in_planes, planes, stride=1): """ 參數: in_planes: 輸入通道數 planes: 中間層通道數 stride: 卷積步長 """ super().__init__() # 1x1卷積降維 self.conv1 = nn.Conv2d(in_planes, planes, 1, bias=False) self.bn1 = nn.BatchNorm2d(planes) # 3x3卷積 self.conv2 = nn.Conv2d(planes, planes, 3, stride, padding=1, bias=False) self.bn2 = nn.BatchNorm2d(planes) # 1x1卷積升維 self.conv3 = nn.Conv2d(planes, planes*self.expansion, 1, bias=False) self.bn3 = nn.BatchNorm2d(planes*self.expansion) # 快捷連接(當維度不匹配時) self.shortcut = nn.Sequential() if stride != 1 or in_planes != self.expansion*planes: self.shortcut = nn.Sequential( nn.Conv2d(in_planes, self.expansion*planes, 1, stride, bias=False), nn.BatchNorm2d(self.expansion*planes) ) # 參數初始化(He初始化) nn.init.kaiming_normal_()函數-- 避免引起一些梯度爆炸問題(初始參數太大或者太小之類的) # 參考博客:https://blog.csdn.net/m0_48241022/article/details/137057738 nn.init.kaiming_normal_(self.conv1.weight, mode='fan_out', nonlinearity='relu') nn.init.kaiming_normal_(self.conv2.weight, mode='fan_out', nonlinearity='relu') nn.init.kaiming_normal_(self.conv3.weight, mode='fan_out', nonlinearity='relu') def forward(self, x): out = F.relu(self.bn1(self.conv1(x))) # 卷積+BN+ReLU out = F.relu(self.bn2(self.conv2(out))) out = self.bn3(self.conv3(out)) # 最后一個BN前不加ReLU out += self.shortcut(x) # 殘差連接 return F.relu(out) # 合并后激活 # 特征金字塔網絡(FPN) class FPN(nn.Module): def __init__(self, block, num_blocks): """ 參數: block: 基礎塊類型(Bottleneck) num_blocks: 各層block數量(如ResNet50的[3,4,6,3]) """ super().__init__() self.in_planes = 64 # 初始通道數 # 初始卷積層(模仿ResNet) self.conv1 = nn.Conv2d(3, 64, 7, stride=2, padding=3, bias=False) self.bn1 = nn.BatchNorm2d(64) self.maxpool = nn.MaxPool2d(3, stride=2, padding=1) # 1/4下采樣 # 構建殘差層(C2-C5) self.layer1 = self._make_layer(block, 64, num_blocks[0], 1) # C2 self.layer2 = self._make_layer(block, 128, num_blocks[1], 2) # C3 self.layer3 = self._make_layer(block, 256, num_blocks[2], 2) # C4 self.layer4 = self._make_layer(block, 512, num_blocks[3], 2) # C5 # 特征金字塔橫向連接(1x1卷積降維) self.toplayer = nn.Conv2d(2048, 256, 1) # 處理C5 self.latlayer1 = nn.Conv2d(1024, 256, 1) # 處理C4 self.latlayer2 = nn.Conv2d(512, 256, 1) # 處理C3 self.latlayer3 = nn.Conv2d(256, 256, 1) # 處理C2 # 權重參數初始化 for m in [self.toplayer, self.latlayer1, self.latlayer2, self.latlayer3]: nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu') def _make_layer(self, block, planes, num_blocks, stride): """構建殘差層""" layers = [block(self.in_planes, planes, stride)] # 第一個block的stride如果大于1,可能有下采樣 self.in_planes = planes * block.expansion # 更新輸入通道數 for _ in range(1, num_blocks): layers.append(block(self.in_planes, planes, 1)) # 后續block無下采樣 '''最終結構:假如第一個stride為2自帶下采樣,后面為1正常輸出:Sequential( Bottleneck1(256->512, stride=2), Bottleneck2(512->512, stride=1), Bottleneck3(512->512, stride=1), Bottleneck4(512->512, stride=1) )''' return nn.Sequential(*layers) def _upsample_add(self, x, y): """上采樣并相加(特征融合)""" # 使用雙線性插值上采樣到y的尺寸再加上y進行特征融合 return F.interpolate(x, size=y.shape[2:], mode='bilinear') + y def forward(self, x): # 自底向上路徑 c1 = F.relu(self.bn1(self.conv1(x))) # [B,64,256,256] c1 = self.maxpool(c1) # [B,64,128,128] c2 = self.layer1(c1) # [B,256,128,128] (C2) c3 = self.layer2(c2) # [B,512,64,64] (C3) c4 = self.layer3(c3) # [B,1024,32,32] (C4) c5 = self.layer4(c4) # [B,2048,16,16] (C5) # 自頂向下路徑(特征金字塔構建) p5 = self.toplayer(c5) # [B,256,16,16] p4 = self._upsample_add(p5, self.latlayer1(c4)) # [B,256,32,32] self.latlayer代表連接層,將數據連接過來 p3 = self._upsample_add(p4, self.latlayer2(c3)) # [B,256,64,64] p2 = self._upsample_add(p3, self.latlayer3(c2)) # [B,256,128,128] return p2, p3, p4, p5 # 自底向上增強路徑(PANet核心) N2--N5 class BottomUpPath(nn.Module): def __init__(self): super().__init__() # 橫向連接卷積(特征融合) 創建個卷積List,存放四個卷積層 self.lat_conv = nn.ModuleList([ nn.Conv2d(256, 256, 1) for _ in range(4) # 每個金字塔層級一個卷積 ]) self.downsample = nn.MaxPool2d(3, stride=2, padding=1) # 2倍下采樣 # 參數初始化 for conv in self.lat_conv: nn.init.kaiming_normal_(conv.weight, mode='fan_out', nonlinearity='relu') def forward(self, features): p2, p3, p4, p5 = features # 來自FPN的特征 FPN將自己每層的數據傳輸過來經過1 * 1的卷積歸一化通道數目后與降采樣的數據直接相加完成特征連接 # 自底向上增強路徑(通過下采樣和橫向連接) n2 = self.lat_conv[0](p2) # [B,256,128,128] n3 = self.downsample(n2) + self.lat_conv[1](p3) # 下采樣后相加 n4 = self.downsample(n3) + self.lat_conv[2](p4) n5 = self.downsample(n4) + self.lat_conv[3](p5) return [n2, n3, n4, n5] # ?? 掩膜預測頭(對應論文圖1(e)) class MaskHead(nn.Module): def __init__(self, in_channels=256, num_classes=1): super().__init__() # 主分支:4個3x3卷積 + 反卷積 self.main_branch = nn.Sequential( nn.Conv2d(in_channels, 256, 3, padding=1), nn.ReLU(inplace=True), nn.Conv2d(256, 256, 3, padding=1), nn.ReLU(inplace=True), nn.Conv2d(256, 256, 3, padding=1), nn.ReLU(inplace=True), nn.Conv2d(256, 256, 3, padding=1), nn.ReLU(inplace=True), nn.ConvTranspose2d(256, 256, 2, stride=2), nn.ReLU(inplace=True), nn.Conv2d(256, num_classes, 1) # 輸出通道數改為1 ) # 全連接融合分支 self.fc_branch = nn.Sequential( nn.Conv2d(256, 128, 3, padding=1), # 從主分支第三個卷積層分叉 nn.ReLU(inplace=True), nn.Conv2d(128, 64, 3, padding=1), nn.ReLU(inplace=True), nn.Flatten(), nn.Linear(64 * 14 * 14, 28 * 28), # 單全連接層保持空間結構 nn.Unflatten(1, (1, 28, 28)) # 重塑為空間特征 ) self.sigmoid = nn.Sigmoid() for m in self.modules(): if isinstance(m, nn.Conv2d): nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu') elif isinstance(m, nn.Linear): nn.init.normal_(m.weight, 0, 0.01) nn.init.constant_(m.bias, 0) def forward(self, x): # 主分支前向 main_out = self.main_branch(x) # [N, C, 28, 28] # 全連接分支前向 fc_out = self.fc_branch(x) # [N, 1, 28, 28] # 特征融合與輸出 fused = main_out + fc_out # 逐元素相加 return self.sigmoid(fused) # [N, C, 28, 28] # PANet完整網絡 class PANet(nn.Module): def __init__(self, num_classes=80): super().__init__() # 特征金字塔網絡(基于ResNet50的FPN) self.fpn = FPN(Bottleneck, [3,4,6,3]) # ResNet50結構 # 自底向上增強路徑 self.bottom_up = BottomUpPath() # ROI Align配置(不同層級的空間尺度) 自適應特征池化:對每個候選區域,在每個特征層上進行ROI Align池化,然后將不同層的特征圖進行最大值融合 self.roi_align = { 'p2': RoIAlign(7, spatial_scale=1/4., sampling_ratio=2), # 1/4尺寸 'p3': RoIAlign(7, spatial_scale=1/8., sampling_ratio=2), 'p4': RoIAlign(7, spatial_scale=1/16., sampling_ratio=2), 'p5': RoIAlign(7, spatial_scale=1/32., sampling_ratio=2) } ''' RoIAlign與RoIPool的區別 參考博客:http://www.rzrgm.cn/xiaochouk/p/15912972.html RoIAlign與傳統的RoIPool(區域興趣池化)的主要區別在于處理邊界的方式。 RoIPool在進行池化操作時會對邊界進行量化處理,這會導致精度損失。 而RoIAlign則通過保持邊界框內的采樣點為浮點數坐標, 并進行雙線性插值來計算每個采樣點的值,從而減少了量化誤差,提高了精度。''' self.mask_roi_align = RoIAlign(14, spatial_scale=1/4., sampling_ratio=2) # ?? 添加掩膜預測頭 self.mask_head = MaskHead(num_classes=1) # 分類頭 self.cls_head = nn.Sequential( nn.Linear(256 * 7 * 7, 512), # ROI特征展平后輸入 nn.ReLU(), nn.Dropout(0.5), nn.Linear(512, num_classes) # 輸出類別分數 ) # 回歸頭 self.reg_head = nn.Sequential( nn.Linear(256 * 7 * 7, 512), nn.ReLU(), nn.Linear(512, 4) # 輸出邊界框偏移量 偏移量x,y,w,h ) # 參數初始化(Xavier初始化) for head in [self.cls_head, self.reg_head]: for m in head.modules(): if isinstance(m, nn.Linear): nn.init.normal_(m.weight, mean=0, std=0.01) # 小隨機數初始化 nn.init.constant_(m.bias, 0) # 偏置初始化為0 def forward(self, x, proposals): # 特征提取 p2, p3, p4, p5 = self.fpn(x) # FPN輸出四個階段,也可以理解為四層的數據 # 自底向上增強路徑處理 將FPN的數據經過自底向上增強路徑融合連接后得到n2, n3, n4, n5 n2, n3, n4, n5 = self.bottom_up([p2, p3, p4, p5]) # 之后再進行特征融合(FPN與自底向上路徑相加)多層級融合:每個尺度都獲得全局+局部信息 # N2-N5 路徑存在的意義主要傳遞的是增強后的定位信息 而P2-P5才是原有的豐富語義信息 # 高層的C5特征經過多次卷積和下采樣,已丟失細節但捕獲了全局語義(如"這是一只狗")。 # 通過自頂向下的上采樣路徑,這些語義信息被傳遞到所有P層。 # 雖然C2-C5本身包含多尺度信息,但低層的C2-C4主要是局部細節(邊緣、紋理)。 # 橫向連接到對應P層(1x1卷積)只能做通道對齊,無法直接增強語義。 # N2(P2級) → 下采樣 → N3 → 下采樣 → N4 → 下采樣 → N5 # 低層特征(N2-N3)攜帶精確位置信息(如物體邊緣)通過路徑傳遞,修正高層特征的定位誤差 # P5可能檢測到"狗在圖像某處" N5結合低層細節后,能更準確定位狗的具體位置 # P5 + N5:增強高層語義的定位能力 # P2 + N2:為細節層補充語義理解 pan_features = [ p2 + n2, # 增強后的P2特征 p3 + n3, p4 + n4, p5 + n5 ] # 然后進入 多層級ROI Align池化 pooled = [] for feat, name in zip(pan_features, ['p2','p3','p4','p5']): # 對每個層級的特征進行ROI Align pooled.append(self.roi_align[name](feat, proposals)) # 特征融合(取各層級最大值) fused = torch.max(torch.stack(pooled), dim=0)[0] # [N,256,7,7] # ?? 掩膜預測分支 mask_rois = [self.mask_roi_align(pan_features[0], proposals)] # 使用14x14的ROI Align mask_feat = torch.cat(mask_rois, dim=0) # [N, 256, 14, 14] mask_pred = self.mask_head(mask_feat) # 展平特征用于全連接層 flattened = fused.flatten(1) # [N, 256 * 7 * 7] # 預測輸出 cls_logits = self.cls_head(flattened) # 分類分數 reg_preds = self.reg_head(flattened) # 回歸偏移量 # ?? 返回新增的掩膜預測結果 return cls_logits, reg_preds, mask_pred # -------------------- 訓練驗證代碼 -------------------- if __name__ == "__main__": # 超參數設置 batch_size = 2 num_epochs = 5 num_classes = 80 # 數據加載 dataset = FakeCOCODataset() dataloader = torch.utils.data.DataLoader( dataset, batch_size=batch_size, collate_fn=coco_collate # 使用自定義整理函數 ) # 模型初始化并轉移到設備 model = PANet(num_classes).to(device) # 修改優化器配置(添加學習率衰減) optimizer = torch.optim.Adam(model.parameters(), lr=0.001) scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=3, gamma=0.1) # 損失函數 cls_criterion = nn.CrossEntropyLoss().to(device) # 分類損失 reg_criterion = nn.SmoothL1Loss().to(device) # 回歸損失(對異常值更魯棒) # 添加掩膜損失(二元交叉熵) mask_criterion = nn.BCELoss().to(device) # 訓練循環 for epoch in range(num_epochs): for batch_idx, (images, collated) in enumerate(dataloader): proposals = [] for i in range(len(collated['raw_boxes'])): raw_boxes = collated['raw_boxes'][i].to(device) # 從collated獲取數據 batch_indices = torch.full((len(raw_boxes),1), i, device=device) proposals.append(torch.cat([batch_indices, raw_boxes], dim=1)) proposals_tensor = torch.cat(proposals, dim=0) # 前向傳播 cls_out, reg_out, mask_pred = model(images.to(device), proposals_tensor) # 準備標簽數據 gt_labels = torch.cat(collated['labels']).to(device) # 直接從collated獲取 gt_boxes = torch.cat(collated['norm_boxes']).to(device) gt_masks = collated['masks'].to(device).unsqueeze(1) # 添加通道維度 # 計算損失 cls_loss = cls_criterion(cls_out, gt_labels) reg_loss = reg_criterion(reg_out, gt_boxes) mask_loss = mask_criterion(mask_pred, gt_masks) total_loss = cls_loss + reg_loss + 2*mask_loss # 反向傳播 optimizer.zero_grad() total_loss.backward() optimizer.step() # 每10個batch打印日志 if batch_idx % 10 == 0: print(f'Epoch [{epoch+1}/{num_epochs}] Batch [{batch_idx}/{len(dataloader)}]') print(f'分類損失: {cls_loss.item():.4f} 回歸損失: {reg_loss.item():.4f} 掩膜損失: {mask_loss.item():.4f}') # ?? 添加掩膜損失顯示
參考博客:https://blog.csdn.net/a8039974/article/details/142340236
https://cloud.tencent.com/developer/article/1592997
論文:https://arxiv.org/pdf/1803.01534

 浙公網安備 33010602011771號
浙公網安備 33010602011771號