
從0到1自定義文字排版引擎:原理篇
這篇文章是從0到1自定義富文本渲染的原理篇之一,此外你還可能感興趣:
更多內容歡迎關注公眾號:非專業程序員Ping
- 一文讀懂字符與編碼
- 一文讀懂字符、字形、字體
- 一文讀懂字體文件
- 從0到1自定義文字排版引擎:原理篇
- 逆向分析CoreText中的字體級聯/Font Fallback機制
- 新手小白也能看懂的LLDB技巧/逆向技巧
- 深入理解iOS CoreText API
引言
前面我們講解了字符與編碼,知道了Character與Unicode的關系和區別,也介紹了字符(Character)、字形(Glyph)、字體的區別,并通過實際解析一個Font文件,真正了解到了Font文件中有什么;如果你對這些概念還熟悉,推薦先閱讀前面幾篇文章打好基礎。
作為程序員,日常和文本打交道肯定最多,不知道你是否深入想過這樣一個問題:
一段中英日等多國混排的文字,系統(排版引擎)是如何知道怎么排布每個文字的,特別是不同國家的語言排版規則不同,比如中文、英文是從左向右排列,阿拉伯文是從右向左排列的;阿拉伯文會有連字(ligature),中文沒有連字;更細節的,為了增強文本的可讀性和美觀性,系統一般還會將文字緊湊處理(kerning)、連字處理(ligature)等,排版引擎在其中到底做了哪些事情,每一步的基本原理又是怎么樣的,本文將帶你逐步揭開排版引擎的神秘面紗。
通過本文,或許你也能自定義一個文字排版引擎了。
一、文本預處理/Unicode歸一化
在字符與編碼一文中,我們知道同一個字符可能對應多個code point,比如????????對應U+1F468 + U+200D + U+1F469 + U+200D + U+1F467 ;甚至Unicode為了兼容歷史編碼,也允許一個字符有多種表示方法,比如é可以表示為:單一code point(U+00E9),組合code point(U+0065 + U+0301)。
預處理就是保證字符串在進行排版/字形選擇(shaping)之前是穩定、唯一、可預測的,避免因為 Unicode 的多種表示方法導致排版不一致,比如避免é被分開成e和 ?排版渲染。
預處理一般步驟是:
- 編碼轉換:將字符統一成UTF-32編碼
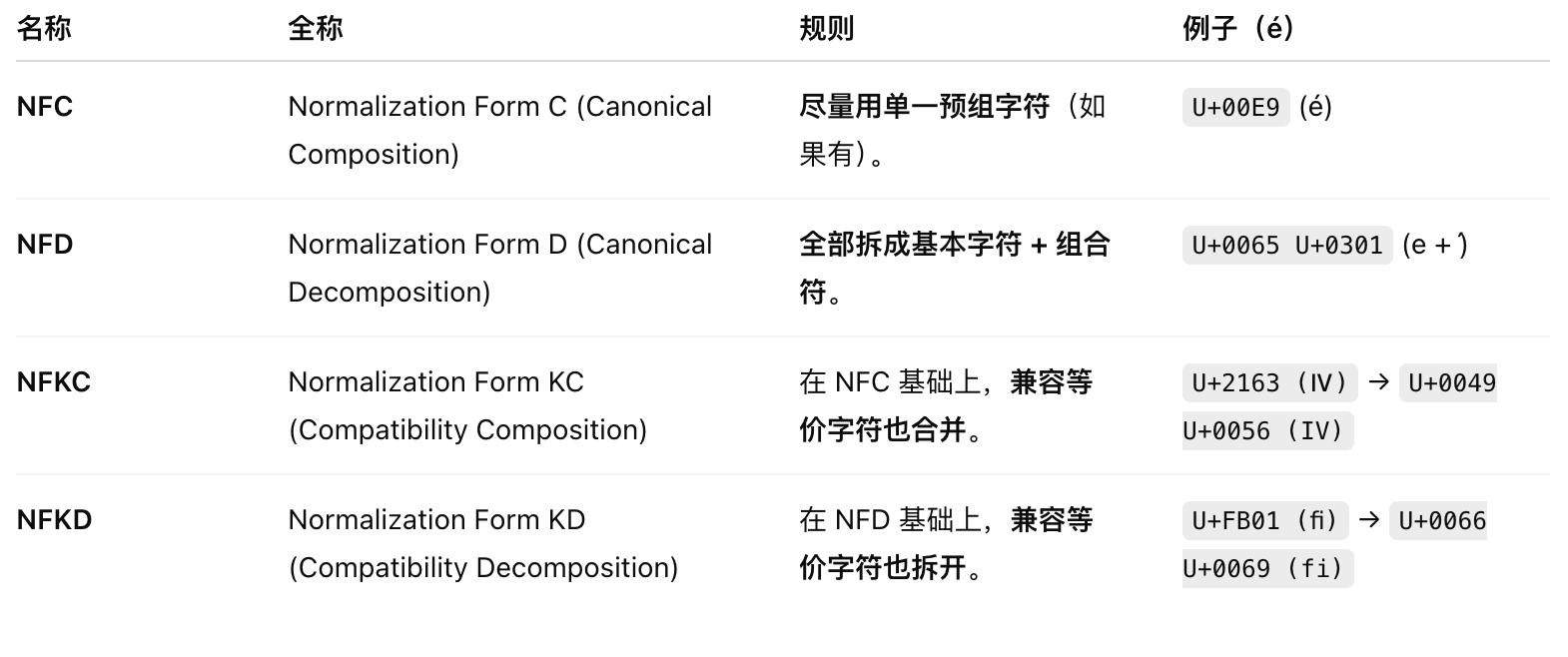
- 規范化(Normalization):NFC/NFD/NFKC/NFKD等,Web 標準和絕大多數現代系統都默認使用NFC
Q:NFC/NFD/NFKC/NFKD是什么
這些是Unicode標準里定義的幾種規范化形式,區別是:
二、分段
為什么要分段:不同國家、語言的排版規則不同,比如阿拉伯文有連字、中文沒有,阿拉伯文從右到左排,中文從左往右排,分段之后方便后續的字體選擇和shaping,比如HarfBuzz 這樣的 shaping 引擎一次只能處理一個 Script run
分段就是把字符串按 Unicode Script (Latin, Han, Hiragana, Katakana 等) 劃分成 run(分組)。
原理比較簡單,Unicode 為每個 code point 定義了一個 Script 屬性,遍歷字符串,按 Script 屬性連續分段即可。
比如對于Hello世界あい,從左往右掃描字符串,每遇到 Script 改變,就切分出一個 run,最后會被劃分成:
Hello" → Latin世界→ Hanあい→ Hiragana
特殊情況:
有些字符的 Script = Common(標點、數字、空格)或 Inherited(音調符號、聲調標記),這些字符分段時需要特殊處理,規則一般是:
- 如果是 Common → 繼承相鄰 run 的 Script(如果左右run都有Script,一般跟隨左邊;如果左邊沒有run,比如開頭就是空格,那就跟隨右邊;如果左右都沒有run,比如
!!!,那整體就是一個Common run)。 - 如果是 Inherited → 附著到前一個 base 字符的 Script。
比如:
世界! → "世界" (Han) + "!" (也歸 Han run)
é (e + 重音符) → 整體算 Latin
三、雙向文本處理(BiDi)
BiDi就是將字符從邏輯順序處理成視覺順序,計算機里字符串總是按邏輯順序存儲(用戶輸入順序),但在渲染時,不同語言有不同的書寫方向,比如中文、英文從左往右排列,阿拉伯文、希伯來文從右往左排列,如果一段文本中既有中文、英文,又有阿拉伯文、希伯來文,那還得處理混排時的順序,BiDi就是處理混排情況下文本的實際顯示順序的。
在后續的例子中,為了方便演示,我們假設以小寫字母作為LTR,以大寫字母作為RTL,比如:
abc ABC
abc:表示LTR(從左往右排)書寫方向
ABC:表示RTL(從右往左排)書寫方向
Unicode有一套完整的BiDi算法(細節可參考鏈接),在介紹原理之前需要先了解幾個基本概念:
1)字符類型(Character Types)
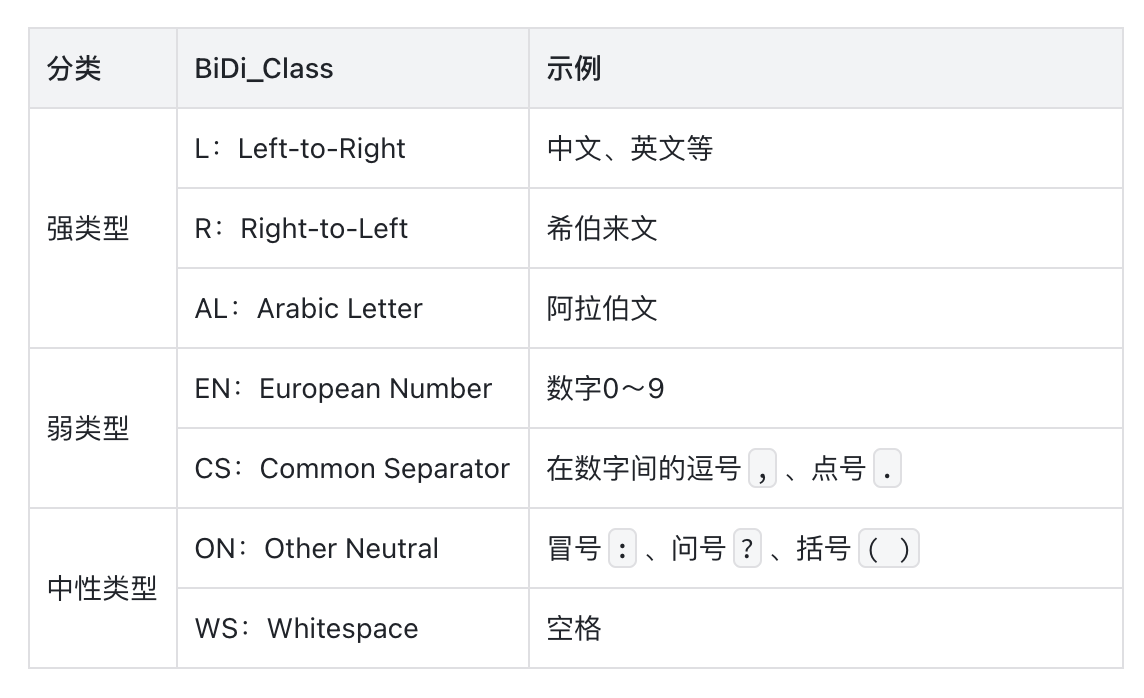
Unicode給每個code point定義了一個Bidi_Class的屬性(Unicode的方向屬性):
-
L= Left-to-Right(中文、英文...) -
R= Right-to-Left(希伯來文) -
AL= Arabic Letter(阿拉伯文) -
EN= European Number(歐洲數字) -
AN= Arabic Number(阿拉伯數字) -
ON= Other Neutral(標點符號) -
...
這些方向屬性會有一個隱含的分類:
- 強類型:這類字符具有明確的方向性,如英文字母是從左往右(LTR),阿拉伯文是從右往左(RLT)
- 弱類型:這類字符方向性不明確,比如數字和一些符號(如出現在數字之間的符號
.、,等),比如阿拉伯數字123, - 中性類型:這類字符完全沒有方向性,如空格、標點符號(
.、,、?等),它們的方向完全由周圍的強類型字符決定
![在這里插入圖片描述]()
比如:
// 如下為計算機中存儲的邏輯順序
abc ABC
a(L) b(L) c(L) space(WS) A(R) B(R) C(R)
2)段落基本方向(Base Direction)
在沒有明確指定段落方向時,會采用默認規則來確定段落基本方向,即選擇段落中第一個強類型字符的方向作為段落基本方向,段落開頭的弱/中性字符會被忽略,直到遇到第一個強類型字符;如果整段都沒有強類型字符,則默認LTR。
比如:
// 如下為計算機中存儲的邏輯順序
// case-1
abc ABC
a(L) b(L) c(L) space(WS) A(R) A(R) C(R)
段落方向為LTR
// case-2
"123abc"
1(EN)2(EN)3(EN)a(L) b(L) c(L)
段落方向為LTR
// case-3
"123"
1(EN)2(EN)3(EN)
段落方向為默認LTR
段落基本方向主要有三個作用:
- 確定初始的嵌套等級(見下),如果基本方向為LTR,則嵌套等級從0開始;如果基本方向為RTL,則嵌套等級從1開始
- 決定中性字符的方向,如果中性字符左右都沒有強類型字符,那就會跟隨段落方向,比如
Hello !中!會跟隨段落方向LTR - 決定段落中文檔流方向,如果基本方向為LTR,文本將從容器左側開始向右排;如果基本方向為RTL,文本將從容器右側開始向左排
3)嵌套等級(Embedding Levels)
BiDi算法中用偶數等級(0, 2, 4...)代表LTR方向,奇數等級(1, 3, 5...)代表RTL方向;如前所述,段落基本方向決定了初始的嵌套等級(0級為LTR,1級為RTL),當文本中出現方向變化時,算法會相應地提升嵌套等級。
從段落初始等級開始,當遇到方向變化時,就提升一個等級;對于強類型字符等級比較容易確定,對于弱類型與中性類型字符則需要結合上下文來共同確定。
對于弱類型字符:比如AN/EN數字及其之間的標點符號,這些字符即使在 RTL 文本中也通常按 LTR 書寫。
對于中性字符:假設中性字符c左右字符(邏輯順序)分別為b、d,
-
如果b、d都為強類型字符,且
direction(b) = direction(d) = D,則direction(c) = D -
如果b是強類型字符,且
direction(b) = RTL,且d是AN或EN,則direction(c) = RTL -
如果b是AN或EN,且d是強類型字符,且
direction(d) = RTL,則direction(c) = RTL -
如果b是AN或EN,且d是AN或EN,則
direction(c) = RTL -
否則
direction(c) = direction(EL(c))(即其嵌套級別的方向,如果沒有控制符明確限制則為段落基本方向)
比如:
// 段落基本方向是LTR,初始等級0
邏輯順序:car means CAR.
嵌套等級:00000000001110
解釋:CAR為RTL,方向變化所以從0提升到1;中性字符.在段落首尾時遵循
// 段落基本方向是RTL,初始等級1
邏輯順序:CAR means car.
嵌套等級:11112222222221
解釋:第一個空格左右分別時RTL和LTR,會遵循段落方向;第二個空格左右都是LTR,被提升為LTR
Q:為什么需要2、3、4等更高等級的嵌套呢?
- Unicode中有一些嵌套控制符,可以顯示提升嵌套等級,比如LRE(U+202A),RLE(U+202B)等
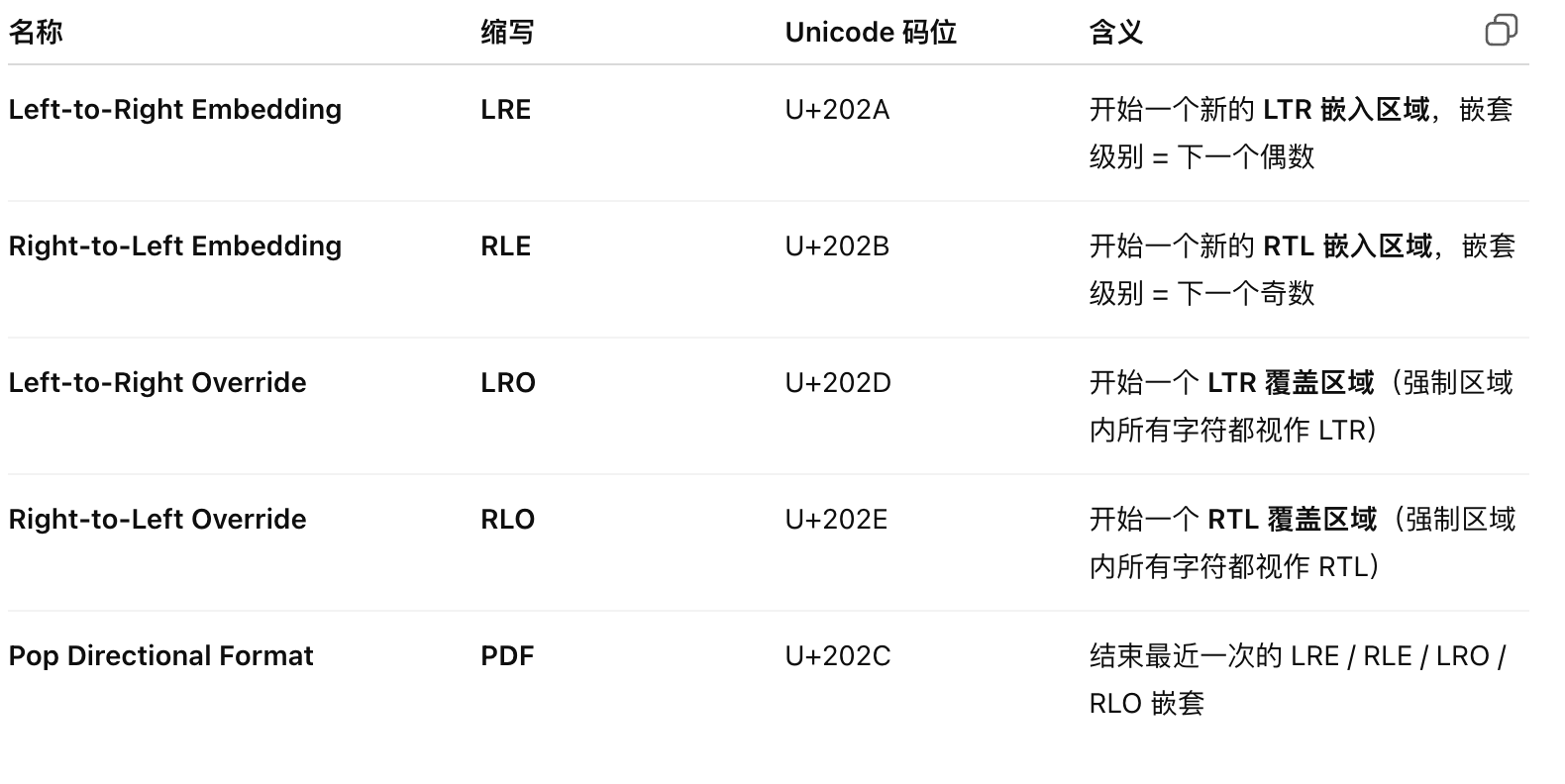
- BiDi算法會從最高嵌套等級逐級反轉字符,如果沒有多級嵌套,遇到復雜結構時(比如 RTL 內嵌 LTR,再內嵌數字),就無法只反轉某一層而保持其他層次穩定
理解上面概念后,我們來簡述BiDi算法的基本過程:
1)分段并確定段落基本方向
BiDi算法是針對段落生效的,拿到一篇文檔后,需要先將文檔拆分成段落,并為段落確定基本方向。
2)為每個字符分配嵌套等級
3)在奇數層做鏡像字符替換
在奇數級別(即 RTL 層級)中,對稱字符(如括號、尖括號、引號等)要“鏡像”替換。
例如在 RTL 層中,一個 “(” 應該顯示為 “)”,一個 “)” 應該顯示為 “(”。
4)阿拉伯連字處理
用一個新字符替換相鄰的阿拉伯字符,并確定每個阿拉伯字符的位置和形狀。
5)按嵌入級別反轉子串以生成視覺順序
對每行(line)分別處理(因為段落可能跨多行),假設最高嵌套等級為EL_h,最低奇數級別為EL_l,從EL_h遞減到EL_l,在每一級別就地反轉子串
遞歸處理完后,由高層級到低層級反轉嵌套子串,就能得到最終每行的視覺順序。
詳細邏輯可以參考:https://cs.uwaterloo.ca/~dberry/ATEP/Slides/UnicodeBiDiAlgorithm.pdf
下面以幾個例子說明:
// case-1
邏輯順序:car means CAR.
段落等級:0(第一個強字符為LTR,所以段落等級為0)
嵌套等級:00000000001110
反轉level 1: car means RAC.
// case-2
邏輯順序:[RLE]car MEANS CAR.[PDF]
段落等級:1(RLT開啟一個新的嵌套等級,嵌套等級提升到1,段落等級為1;PDF為表示嵌套終止)
嵌套等級: 22211111111111
反轉level 2:rac MEANS CAR.
反轉level 1~2:.RAC SNAEM car
// case-3
邏輯順序:he said "[RLE]car MEANS CAR[PDF]."
段落等級:0
嵌套等級:000000000 2221111111111 00
反轉level 2:he said "rac MEANS CAR."
反轉level 1~2:he said "RAC SNAEM car."
四、字體匹配與Fallback
字體匹配與Fallback是一個復雜的過程,我們后續的塑形與測量都依賴字體文件。
由于任何一個字體都不可能覆蓋 Unicode 的所有字符,比如:Times New Roman 渲染拉丁字母沒問題,但遇到中文 “你” 就會變成“豆腐塊”(小方塊:是操作系統在沒找到合適字體來顯示字符時,會兜底到占位符,比如?或?等);所以排版系統實際要做的就是:確保每個字符都有合適的字體來渲染,同時盡量保持風格一致。
每個字符都有對應的code point,在Font文件中有什么一文中,我們知道了字體文件中有各種各樣的表,其中cmap表存儲了code point與glyphID的映射,通過cmap表我們可以精確的查到該Font是否支持某個code point,但是僅通過cmap查詢是不夠的,主要有兩個原因:
- 操作系統一般安裝了成百上千種字體,如果對每個code point都去遍歷所有Font的cmap表,那開銷會非常大
- 不同Font支持的Unicode范圍是有交集的,一個code point可能匹配出多個Font,為了渲染風格的統一,我們期望相同Script的字符盡量用同一種Font
Q:相同Script的字符如果使用了不同的Font,會有什么問題
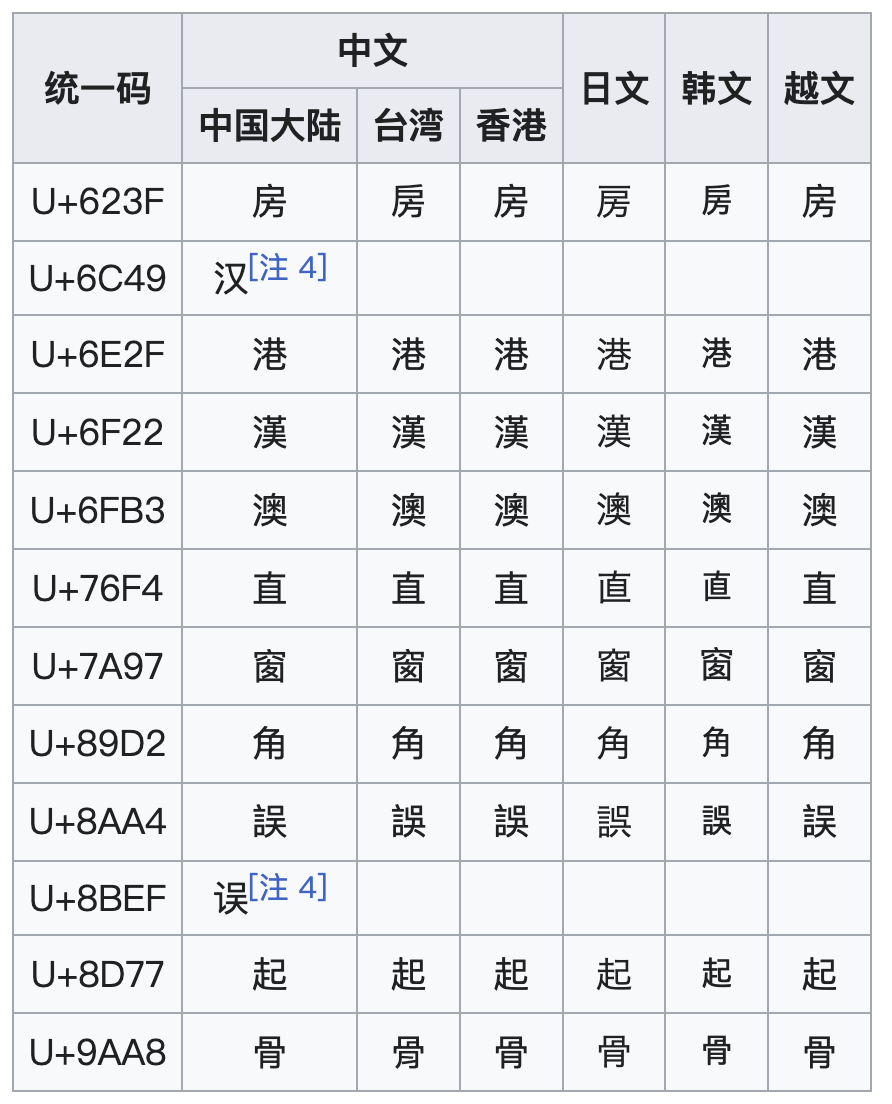
Unicode 為了節省碼點空間,將許多中、日、韓來源相同但字形有細微差異的漢字合并到了同一個碼點上,也就是所謂的中日韓統一表意文字(CJK Unified Ideographs);如下,同一個code point在不同語言下樣式不同,如果不處理Script,那可能會在一個日文段落里顯示出中文的“房”字形,這在專業排版上是不可接受的。另外,不同的Font格設計風格(字寬、基線、形態)也不同,如果一個段落里穿插不同的Font,那最終排版看起來也會很奇怪。
現代操作系統做字體匹配與Fallback的方式一般是:
1)通過前面的分段,將一段字符串按Script分成不同的run
2)檢查用戶指定的主字體是否支持
檢查用戶指定字體(主字體)的cmap是否支持對應字符(code point),如果支持則命中主字體,如果不支持則進入Fallback流程。
3)Fallback時按OS_2表中的ulUnicodeRange掩碼初步篩選支持的Unicode范圍
注意OS_2表只是一個大概范圍,并不代表完全支持該范圍的Unicode,如果要精確查詢是否支持還是要查cmap表。
4)通過GSUB/GPOS 表精確查找支持哪些Script
GSUB/GPOS中定義了ScriptList,明確聲明字體為哪些Script提供了shaping規則;排版引擎通過GSUB/GPOS表來處理復雜的排版規則,比如字形替換、連字、上下標對齊等,排版引擎會優先選擇明確支持對應Script的Font。
5)通過cmap表驗證支持的code point
如果匹配出多個Fallback字體,那系統可能會根據用戶設置的主字體風格,系統語言、字體優先級等來選擇最優的字體。
當然,操作系統中一般會對Script的Fallback字體表有緩存,上面的3、4步驟一般不用每次都做,Fallback表類似于:
{
"scripts": {
"hans": ["Microsoft YaHei", "SimSun", "Source Han Sans SC"],
"hant": ["Microsoft JhengHei", "Source Han Sans TC"],
"latn": ["Arial", "Times New Roman", "Verdana", "Microsoft YaHei", ...],
"kana": ["Meiryo", "Yu Gothic", "Source Han Sans JP"]
},
"families": {
"Arial": { "regular": "arial.ttf", "bold": "arialbd.ttf" },
...
}
}
我們后續也會逆向探究下CoreText中的字體級聯(Fallback)機制,更細節的這里不再展開。
Q:像????????這種由多個code point組成的字符,是怎么匹配Font的
像????????這種由多個code point組成的字符(如下),一般稱之為Grapheme Cluster(字素簇):
?? (U+1F468, MAN)
+ U+200D (ZWJ, Zero Width Joiner)
+ ?? (U+1F469, WOMAN)
+ U+200D (ZWJ, Zero Width Joiner)
+ ?? (U+1F467, GIRL)
Unicode Emoji 標準里規定了哪些序列可以組合成單個 emoji(如 ????????、???????? 等),排版引擎會根據Emoji data(來自Unicode數據表)來判斷這是不是一個合法的ZWJ Sequence,識別成功會將其視為一個不可分割的單元,在匹配字體時會做如下處理:
1)用組合序列的第一個非ZWJ code point 去查找字體
ZWJ:Zero Width Joiner,零寬度連接符,它的作用就像“膠水”,告訴排版引擎兩側字符不可分割。
對于????????來說,就是用 U+1F468 (??),去查找字體,查找和Fallback過程同上。一般而言會匹配到系統內置的彩色表情符號字體:macOS/iOS上一般是Apple Color Emoji,Windows上是Segoe UI Emoji,Android上一般是Noto Color Emoji
2)用匹配的字體進行字形替換
這一步其實發生在下面的塑性階段,在查到的字體表中通過 GSUB表把多個 code point 映射成一個彩色的glyph,也就是字形替換。
如果這一步沒找到合法的可替換字形,那就Fallback到單獨顯示?? ?? ??
五、字形選擇與Shaping
這一步的目標是將抽象的字符轉換成具體的glyphIDs和布局信息,以供下一步排版使用;輸入是一段單一 Script、單一字體的文本 run和上面匹配出的字體,輸出是一個字形序列,包括glyphIDs、x_advance、y_advance、x_offset、y_offset等。
大致分為兩步:
1)code point映射到glyphID
每個code point會通過字體的cmap表映射成一個glyphID。
2)文本塑形:應用GSUB、GPOS規則
Shaping引擎會讀取字體文件中的GSUB表,進行字形替換,比如連字,emoji替換等;讀取GPOS表,調整字形的位置,比如上下標位置、字間距(kerning)、阿拉伯文的連寫等。
六、測量與排版
這一步的目標是將字形序列按自定義布局規則排版到二維坐標系下,簡單講就是確定每個glyph的位置、大小信息,以供下一步繪制使用。
大致分為兩步:
1)獲取字形的metrics
從字體文件的hhea/OS_2表中讀取出每個glyph的ascent、descent等信息,用于確定baseline、lineHeight等信息。
2)自定義布局確定每個glyph位置
從上面得到的baseline、lineHeight等信息,以及第六步得到的advance寬度(glyph前進量)等,可以計算出每個glyph的寬高、對齊基線,這樣我們就能像前端一樣自定義文檔流布局(Inline、Inline-Block、Block)來精確的排版每個glyph的位置。
七、渲染上屏
經過上面的塑形、排版過程,我們已經能得到按顯示順序排列且帶有精確位置的glyph序列,繪制階段就是將這些抽象的glyph序列上屏顯示出來。
這一步一般有軟光柵、硬光柵等多種選型,在macOS/iOS上,可以通過CoreText來繪制字形序列,比如:CTFontDrawGlyphs;本文主要講解排版引擎流程,渲染部分不再展開,后續有時間再單獨開篇研究。
總結
至此,我們自定義文字排版引擎的原理篇告一段落;相信通過以上講解,我們對文字排版的流程有了一個大致了解,下一步我們將結合ICU、HarfBuzz等來實戰實現一個小型的自定義文字排版引擎。
更多精彩內容,歡迎關注??公眾號:非專業程序員Ping
posted on 2025-10-22 23:48 非專業程序員Ping 閱讀(160) 評論(2) 收藏 舉報


 浙公網安備 33010602011771號
浙公網安備 33010602011771號