


CatDCGAN項目復現與對抗網絡初識
作者 CarpVexing 日期 100521 禁止轉載
引言
Gan對抗生成網絡,不管怎么說,這都算不上是一項新技術。奈何筆者長期所學落后于時代,總算在保研后一段時間能夠好好琢磨一下ML的內容。今天先記錄下復現CatDCGAN項目的操作流程,并將所參考的網址記錄在此處。
CatDCGAN項目基本信息
這是一個利用對抗網絡生成貓咪頭像的項目,非商業用途,更像是一個用于實踐對抗網絡應用的玩具類型項目。作者是simoninithomas,以下是他2018年在freecodecamp就此項目發表的文章:
(https://www.freecodecamp.org/news/how-ai-can-learn-to-generate-pictures-of-cats-ba692cb6eae4/)
項目的基本原理其實不難理解,兩個神經網絡分別作為Generater和Discriminator相互對抗和博弈,關于其具體損失函數、優化函數、訓練部分的細節可以從原文和代碼中了解,在此不表。最終實現的效果,是通過3個G左右的貓貓圖片訓練出一個模型,可以隨機生成貓貓頭圖像。__請注意,隨機生成貓貓頭僅僅意味著圖片中的貓貓頭被認定為貓,我們無法通過它的代碼實現對于貓貓特征的任何掌控。__這意味著他只實現了一個對抗生成網絡的基本功能,并無別的創新。
復現項目的準備工作
首先,下載項目源碼\數據集\現成的模型。源碼在ipynb中。
(https://github.com/simoninithomas/CatDCGAN)
(https://www.kaggle.com/crawford/cat-dataset)
(https://drive.google.com/drive/folders/1zdZZ91fjOUiOsIdAQKZkUTATXzqy7hiz?usp=sharing)
筆者認為,jupyter notebook難以在指定的conda虛擬python環境中運行。盡管網絡上有著各種解決方案,但是筆者均沒能成功解決此問題。為了方便,直接把代碼整體復制到py文件中,用指定內核運行并測試。
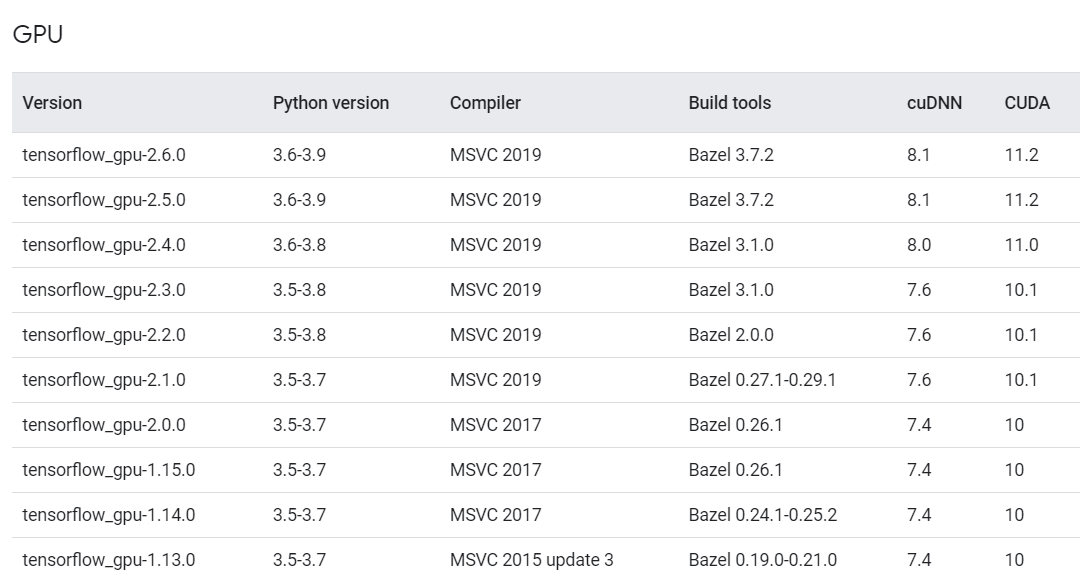
這個項目用的是TensorFlow1,所以需要相應配置一套TensorFlow環境,1或者2都可以。此過程需要非常小心地注意TensorFlow_gpu、python、CUDA、cudnn的版本對應關系。安裝環境細節可參考此文章:
(https://blog.csdn.net/weixin_43877139/article/details/100544065)
版本對應關系(windows環境下):
筆者用的是tensorflow_gpu-2.6.0/python3.8/cudnn8.1/cuda11.2組合。確保tensorflow能夠正常識別gpu之后就可以進行數據集和源代碼的修改了。
數據集預處理
按照作者說法,先要將貓臉不居中、損壞、裁剪嚴重、倒置、不像貓、被遮擋等情況的數據剔除。為此他準備了一段sh腳本,可是那是存在一些小問題的。我們可以先將下載好的數據集解壓到./并將文件夾命名為“cat_dataset”,然后將./cat_dataset/cats這個文件夾剪切出來到./。接下來下載“preprocess_cat_dataset.py”放到./,項目鏈接如下:
最后在./保存如下腳本,并在git bash中運行它。
mv cat_dataset/CAT_00/* cat_dataset
rmdir cat_dataset/CAT_00
mv cat_dataset/CAT_01/* cat_dataset
rmdir cat_dataset/CAT_01
mv cat_dataset/CAT_02/* cat_dataset
rmdir cat_dataset/CAT_02
mv cat_dataset/CAT_03/* cat_dataset
rmdir cat_dataset/CAT_03
mv cat_dataset/CAT_04/* cat_dataset
rmdir cat_dataset/CAT_04
mv cat_dataset/CAT_05/* cat_dataset
rmdir cat_dataset/CAT_05
mv cat_dataset/CAT_06/* cat_dataset
rmdir cat_dataset/CAT_06
## Error correction
rm cat_dataset/00000003_019.jpg.cat
mv 00000003_015.jpg.cat cat_dataset/00000003_015.jpg.cat
## Removing outliers
# Corrupted, drawings, badly cropped, inverted, impossible to tell it's a cat, blocked face
cd cat_dataset
rm 00000004_007.jpg 00000007_002.jpg 00000045_028.jpg 00000050_014.jpg 00000056_013.jpg 00000059_002.jpg 00000108_005.jpg 00000122_023.jpg 00000126_005.jpg 00000132_018.jpg 00000142_024.jpg 00000142_029.jpg 00000143_003.jpg 00000145_021.jpg 00000166_021.jpg 00000169_021.jpg 00000186_002.jpg 00000202_022.jpg 00000208_023.jpg 00000210_003.jpg 00000229_005.jpg 00000236_025.jpg 00000249_016.jpg 00000254_013.jpg 00000260_019.jpg 00000261_029.jpg 00000265_029.jpg 00000271_020.jpg 00000282_026.jpg 00000316_004.jpg 00000352_014.jpg 00000400_026.jpg 00000406_006.jpg 00000431_024.jpg 00000443_027.jpg 00000502_015.jpg 00000504_012.jpg 00000510_019.jpg 00000514_016.jpg 00000514_008.jpg 00000515_021.jpg 00000519_015.jpg 00000522_016.jpg 00000523_021.jpg 00000529_005.jpg 00000556_022.jpg 00000574_011.jpg 00000581_018.jpg 00000582_011.jpg 00000588_016.jpg 00000588_019.jpg 00000590_006.jpg 00000592_018.jpg 00000593_027.jpg 00000617_013.jpg 00000618_016.jpg 00000619_025.jpg 00000622_019.jpg 00000622_021.jpg 00000630_007.jpg 00000645_016.jpg 00000656_017.jpg 00000659_000.jpg 00000660_022.jpg 00000660_029.jpg 00000661_016.jpg 00000663_005.jpg 00000672_027.jpg 00000673_027.jpg 00000675_023.jpg 00000692_006.jpg 00000800_017.jpg 00000805_004.jpg 00000807_020.jpg 00000823_010.jpg 00000824_010.jpg 00000836_008.jpg 00000843_021.jpg 00000850_025.jpg 00000862_017.jpg 00000864_007.jpg 00000865_015.jpg 00000870_007.jpg 00000877_014.jpg 00000882_013.jpg 00000887_028.jpg 00000893_022.jpg 00000907_013.jpg 00000921_029.jpg 00000929_022.jpg 00000934_006.jpg 00000960_021.jpg 00000976_004.jpg 00000987_000.jpg 00000993_009.jpg 00001006_014.jpg 00001008_013.jpg 00001012_019.jpg 00001014_005.jpg 00001020_017.jpg 00001039_008.jpg 00001039_023.jpg 00001048_029.jpg 00001057_003.jpg 00001068_005.jpg 00001113_015.jpg 00001140_007.jpg 00001157_029.jpg 00001158_000.jpg 00001167_007.jpg 00001184_007.jpg 00001188_019.jpg 00001204_027.jpg 00001205_022.jpg 00001219_005.jpg 00001243_010.jpg 00001261_005.jpg 00001270_028.jpg 00001274_006.jpg 00001293_015.jpg 00001312_021.jpg 00001365_026.jpg 00001372_006.jpg 00001379_018.jpg 00001388_024.jpg 00001389_026.jpg 00001418_028.jpg 00001425_012.jpg 00001431_001.jpg 00001456_018.jpg 00001458_003.jpg 00001468_019.jpg 00001475_009.jpg 00001487_020.jpg
rm 00000004_007.jpg.cat 00000007_002.jpg.cat 00000045_028.jpg.cat 00000050_014.jpg.cat 00000056_013.jpg.cat 00000059_002.jpg.cat 00000108_005.jpg.cat 00000122_023.jpg.cat 00000126_005.jpg.cat 00000132_018.jpg.cat 00000142_024.jpg.cat 00000142_029.jpg.cat 00000143_003.jpg.cat 00000145_021.jpg.cat 00000166_021.jpg.cat 00000169_021.jpg.cat 00000186_002.jpg.cat 00000202_022.jpg.cat 00000208_023.jpg.cat 00000210_003.jpg.cat 00000229_005.jpg.cat 00000236_025.jpg.cat 00000249_016.jpg.cat 00000254_013.jpg.cat 00000260_019.jpg.cat 00000261_029.jpg.cat 00000265_029.jpg.cat 00000271_020.jpg.cat 00000282_026.jpg.cat 00000316_004.jpg.cat 00000352_014.jpg.cat 00000400_026.jpg.cat 00000406_006.jpg.cat 00000431_024.jpg.cat 00000443_027.jpg.cat 00000502_015.jpg.cat 00000504_012.jpg.cat 00000510_019.jpg.cat 00000514_016.jpg.cat 00000514_008.jpg.cat 00000515_021.jpg.cat 00000519_015.jpg.cat 00000522_016.jpg.cat 00000523_021.jpg.cat 00000529_005.jpg.cat 00000556_022.jpg.cat 00000574_011.jpg.cat 00000581_018.jpg.cat 00000582_011.jpg.cat 00000588_016.jpg.cat 00000588_019.jpg.cat 00000590_006.jpg.cat 00000592_018.jpg.cat 00000593_027.jpg.cat 00000617_013.jpg.cat 00000618_016.jpg.cat 00000619_025.jpg.cat 00000622_019.jpg.cat 00000622_021.jpg.cat 00000630_007.jpg.cat 00000645_016.jpg.cat 00000656_017.jpg.cat 00000659_000.jpg.cat 00000660_022.jpg.cat 00000660_029.jpg.cat 00000661_016.jpg.cat 00000663_005.jpg.cat 00000672_027.jpg.cat 00000673_027.jpg.cat 00000675_023.jpg.cat 00000692_006.jpg.cat 00000800_017.jpg.cat 00000805_004.jpg.cat 00000807_020.jpg.cat 00000823_010.jpg.cat 00000824_010.jpg.cat 00000836_008.jpg.cat 00000843_021.jpg.cat 00000850_025.jpg.cat 00000862_017.jpg.cat 00000864_007.jpg.cat 00000865_015.jpg.cat 00000870_007.jpg.cat 00000877_014.jpg.cat 00000882_013.jpg.cat 00000887_028.jpg.cat 00000893_022.jpg.cat 00000907_013.jpg.cat 00000921_029.jpg.cat 00000929_022.jpg.cat 00000934_006.jpg.cat 00000960_021.jpg.cat 00000976_004.jpg.cat 00000987_000.jpg.cat 00000993_009.jpg.cat 00001006_014.jpg.cat 00001008_013.jpg.cat 00001012_019.jpg.cat 00001014_005.jpg.cat 00001020_017.jpg.cat 00001039_008.jpg.cat 00001039_023.jpg.cat 00001048_029.jpg.cat 00001057_003.jpg.cat 00001068_005.jpg.cat 00001113_015.jpg.cat 00001140_007.jpg.cat 00001157_029.jpg.cat 00001158_000.jpg.cat 00001167_007.jpg.cat 00001184_007.jpg.cat 00001188_019.jpg.cat 00001204_027.jpg.cat 00001205_022.jpg.cat 00001219_005.jpg.cat 00001243_010.jpg.cat 00001261_005.jpg.cat 00001270_028.jpg.cat 00001274_006.jpg.cat 00001293_015.jpg.cat 00001312_021.jpg.cat 00001365_026.jpg.cat 00001372_006.jpg.cat 00001379_018.jpg.cat 00001388_024.jpg.cat 00001389_026.jpg.cat 00001418_028.jpg.cat 00001425_012.jpg.cat 00001431_001.jpg.cat 00001456_018.jpg.cat 00001458_003.jpg.cat 00001468_019.jpg.cat 00001475_009.jpg.cat 00001487_020.jpg.cat
cd ..
## Preprocessing and putting in folders for different image sizes
mkdir cats_bigger_than_64x64
mkdir cats_bigger_than_128x128
python preprocess_cat_dataset.py
## Removing cat_dataset
rm -r cat_dataset
為了讓代碼正常運行,還需要在./中創建兩個空文件夾,筆者將它們命名為from_checkpoint_IMG和images。其實這種命名是非常不規范的,但是鑒于盡量與代碼表意相吻合,暫且就這樣命名。
代碼修改
1、首先,本項目用的是tf1,筆者裝的是tf2。簡單解決這個問題的方法是:
把
import tensorflow as tf
改為
import tensorflow.compat.v1 as tf
tf.disable_v2_behavior()
題外話,如何區分代碼用的是tf1還是2?如果出現X=tf.placeholder(“float”)這類語句,那就是tf1,它在tf2下會出現“module ‘tensorflow’ has no attribute ‘placeholder’”的報錯。
2、下面兩個變量,第一個代表是否需要對圖片進行尺寸的統一化處理,這部分內容只需要處理過一遍就行了,也就是說,第一次運行時改為True,之后一直改為False。第二個變量代表是否利用已經訓練好的模型,如果重新馴良,需要花費至少20小時的時間,所以我們如果不需要重新訓練的話,就寫True。
do_preprocess = False
from_checkpoint = False
模型保存的路徑是./models/。我們可以將準備工作時下載的模型包解壓到這個路徑下。
3、修改代碼錯誤。
if from_checkpoint == True:
saver.restore(sess, "./models/model.ckpt")
show_generator_output(sess, 4, input_z, data_shape[3], data_image_mode, image_path, True, False)
image_path未定義。我們給它加一句image_path = "./from_checkpoint_IMG/FCI.jpg"。這個路徑也就是上一環節的那個空文件夾。
return losses, samples
這兩個都是未定義。sample根本沒用上,直接刪了。losses本來是想創建一個數組,記錄損失函數隨著時間的變化,最后用圖表反應變化情況的,但是代碼里面沒這部分內容。因此可在train函數中,定義:
losses = []
...
if i % 10 == 0:
train_loss_d = d_loss.eval({input_z: batch_z, input_images: batch_images})
train_loss_g = g_loss.eval({input_z: batch_z})
losses.append((train_loss_d, train_loss_g))
...
這里其實還是有問題的。假如直接利用已有的模型進行生成,這個數組就是空的,最后會報個錯。但是直接利用模型本來就不需要分析損失函數的變化情況,所以它最后報不報錯都無所謂了,這個也就不需要再去在意。
最后的生成圖片在./from_checkpoint_IMG/中。

完整代碼展示
import os
# import tensorflow as tf
import tensorflow.compat.v1 as tf
tf.disable_v2_behavior()
import numpy as np
import helper
from glob import glob
import pickle as pkl
import scipy.misc
import time
import cv2
import matplotlib.pyplot as plt
#%matplotlib inline
#do_preprocess = False
#from_checkpoint = False
do_preprocess = False
from_checkpoint = True
data_dir = './cats_bigger_than_128x128' # Data
data_resized_dir = "./resized_data"# Resized data
if do_preprocess == True:
os.mkdir(data_resized_dir)
for each in os.listdir(data_dir):
image = cv2.imread(os.path.join(data_dir, each))
image = cv2.resize(image, (128, 128))
cv2.imwrite(os.path.join(data_resized_dir, each), image)
# This part was taken from Udacity Face generator project
def get_image(image_path, width, height, mode):
"""
Read image from image_path
:param image_path: Path of image
:param width: Width of image
:param height: Height of image
:param mode: Mode of image
:return: Image data
"""
image = Image.open(image_path)
return np.array(image.convert(mode))
def get_batch(image_files, width, height, mode):
data_batch = np.array(
[get_image(sample_file, width, height, mode) for sample_file in image_files]).astype(np.float32)
# Make sure the images are in 4 dimensions
if len(data_batch.shape) < 4:
data_batch = data_batch.reshape(data_batch.shape + (1,))
return data_batch
show_n_images = 25
mnist_images = helper.get_batch(glob(os.path.join(data_resized_dir, '*.jpg'))[:show_n_images], 64, 64, 'RGB')
plt.imshow(helper.images_square_grid(mnist_images, 'RGB'))
# Taken from Udacity face generator project
from distutils.version import LooseVersion
import warnings
# import tensorflow as tf
# Check TensorFlow Version
assert LooseVersion(tf.__version__) >= LooseVersion('1.0'), 'Please use TensorFlow version 1.0 or newer. You are using {}'.format(tf.__version__)
print('TensorFlow Version: {}'.format(tf.__version__))
# Check for a GPU
if not tf.test.gpu_device_name():
warnings.warn('No GPU found. Please use a GPU to train your neural network.')
else:
print('Default GPU Device: {}'.format(tf.test.gpu_device_name()))
def model_inputs(real_dim, z_dim):
"""
Create the model inputs
:param real_dim: tuple containing width, height and channels
:param z_dim: The dimension of Z
:return: Tuple of (tensor of real input images, tensor of z data, learning rate G, learning rate D)
"""
inputs_real = tf.placeholder(tf.float32, (None, *real_dim), name='inputs_real')
inputs_z = tf.placeholder(tf.float32, (None, z_dim), name="input_z")
learning_rate_G = tf.placeholder(tf.float32, name="learning_rate_G")
learning_rate_D = tf.placeholder(tf.float32, name="learning_rate_D")
# inputs_real = tf.compat.v1.placeholder(tf.float32, (None, *real_dim), name='inputs_real')
# inputs_z = tf.compat.v1.placeholder(tf.float32, (None, z_dim), name="input_z")
# learning_rate_G = tf.compat.v1.placeholder(tf.float32, name="learning_rate_G")
# learning_rate_D = tf.compat.v1.placeholder(tf.float32, name="learning_rate_D")
return inputs_real, inputs_z, learning_rate_G, learning_rate_D
def generator(z, output_channel_dim, is_train=True):
''' Build the generator network.
Arguments
---------
z : Input tensor for the generator
output_channel_dim : Shape of the generator output
n_units : Number of units in hidden layer
reuse : Reuse the variables with tf.variable_scope
alpha : leak parameter for leaky ReLU
Returns
-------
out:
'''
with tf.variable_scope("generator", reuse= not is_train):
# First FC layer --> 8x8x1024
fc1 = tf.layers.dense(z, 8*8*1024)
# Reshape it
fc1 = tf.reshape(fc1, (-1, 8, 8, 1024))
# Leaky ReLU
fc1 = tf.nn.leaky_relu(fc1, alpha=alpha)
# Transposed conv 1 --> BatchNorm --> LeakyReLU
# 8x8x1024 --> 16x16x512
trans_conv1 = tf.layers.conv2d_transpose(inputs = fc1,
filters = 512,
kernel_size = [5,5],
strides = [2,2],
padding = "SAME",
kernel_initializer=tf.truncated_normal_initializer(stddev=0.02),
name="trans_conv1")
batch_trans_conv1 = tf.layers.batch_normalization(inputs = trans_conv1, training=is_train, epsilon=1e-5, name="batch_trans_conv1")
trans_conv1_out = tf.nn.leaky_relu(batch_trans_conv1, alpha=alpha, name="trans_conv1_out")
# Transposed conv 2 --> BatchNorm --> LeakyReLU
# 16x16x512 --> 32x32x256
trans_conv2 = tf.layers.conv2d_transpose(inputs = trans_conv1_out,
filters = 256,
kernel_size = [5,5],
strides = [2,2],
padding = "SAME",
kernel_initializer=tf.truncated_normal_initializer(stddev=0.02),
name="trans_conv2")
batch_trans_conv2 = tf.layers.batch_normalization(inputs = trans_conv2, training=is_train, epsilon=1e-5, name="batch_trans_conv2")
trans_conv2_out = tf.nn.leaky_relu(batch_trans_conv2, alpha=alpha, name="trans_conv2_out")
# Transposed conv 3 --> BatchNorm --> LeakyReLU
# 32x32x256 --> 64x64x128
trans_conv3 = tf.layers.conv2d_transpose(inputs = trans_conv2_out,
filters = 128,
kernel_size = [5,5],
strides = [2,2],
padding = "SAME",
kernel_initializer=tf.truncated_normal_initializer(stddev=0.02),
name="trans_conv3")
batch_trans_conv3 = tf.layers.batch_normalization(inputs = trans_conv3, training=is_train, epsilon=1e-5, name="batch_trans_conv3")
trans_conv3_out = tf.nn.leaky_relu(batch_trans_conv3, alpha=alpha, name="trans_conv3_out")
# Transposed conv 4 --> BatchNorm --> LeakyReLU
# 64x64x128 --> 128x128x64
trans_conv4 = tf.layers.conv2d_transpose(inputs = trans_conv3_out,
filters = 64,
kernel_size = [5,5],
strides = [2,2],
padding = "SAME",
kernel_initializer=tf.truncated_normal_initializer(stddev=0.02),
name="trans_conv4")
batch_trans_conv4 = tf.layers.batch_normalization(inputs = trans_conv4, training=is_train, epsilon=1e-5, name="batch_trans_conv4")
trans_conv4_out = tf.nn.leaky_relu(batch_trans_conv4, alpha=alpha, name="trans_conv4_out")
# Transposed conv 5 --> tanh
# 128x128x64 --> 128x128x3
logits = tf.layers.conv2d_transpose(inputs = trans_conv4_out,
filters = 3,
kernel_size = [5,5],
strides = [1,1],
padding = "SAME",
kernel_initializer=tf.truncated_normal_initializer(stddev=0.02),
name="logits")
out = tf.tanh(logits, name="out")
return out
def discriminator(x, is_reuse=False, alpha = 0.2):
''' Build the discriminator network.
Arguments
---------
x : Input tensor for the discriminator
n_units: Number of units in hidden layer
reuse : Reuse the variables with tf.variable_scope
alpha : leak parameter for leaky ReLU
Returns
-------
out, logits:
'''
with tf.variable_scope("discriminator", reuse = is_reuse):
# Input layer 128*128*3 --> 64x64x64
# Conv --> BatchNorm --> LeakyReLU
conv1 = tf.layers.conv2d(inputs = x,
filters = 64,
kernel_size = [5,5],
strides = [2,2],
padding = "SAME",
kernel_initializer=tf.truncated_normal_initializer(stddev=0.02),
name='conv1')
batch_norm1 = tf.layers.batch_normalization(conv1,
training = True,
epsilon = 1e-5,
name = 'batch_norm1')
conv1_out = tf.nn.leaky_relu(batch_norm1, alpha=alpha, name="conv1_out")
# 64x64x64--> 32x32x128
# Conv --> BatchNorm --> LeakyReLU
conv2 = tf.layers.conv2d(inputs = conv1_out,
filters = 128,
kernel_size = [5, 5],
strides = [2, 2],
padding = "SAME",
kernel_initializer=tf.truncated_normal_initializer(stddev=0.02),
name='conv2')
batch_norm2 = tf.layers.batch_normalization(conv2,
training = True,
epsilon = 1e-5,
name = 'batch_norm2')
conv2_out = tf.nn.leaky_relu(batch_norm2, alpha=alpha, name="conv2_out")
# 32x32x128 --> 16x16x256
# Conv --> BatchNorm --> LeakyReLU
conv3 = tf.layers.conv2d(inputs = conv2_out,
filters = 256,
kernel_size = [5, 5],
strides = [2, 2],
padding = "SAME",
kernel_initializer=tf.truncated_normal_initializer(stddev=0.02),
name='conv3')
batch_norm3 = tf.layers.batch_normalization(conv3,
training = True,
epsilon = 1e-5,
name = 'batch_norm3')
conv3_out = tf.nn.leaky_relu(batch_norm3, alpha=alpha, name="conv3_out")
# 16x16x256 --> 16x16x512
# Conv --> BatchNorm --> LeakyReLU
conv4 = tf.layers.conv2d(inputs = conv3_out,
filters = 512,
kernel_size = [5, 5],
strides = [1, 1],
padding = "SAME",
kernel_initializer=tf.truncated_normal_initializer(stddev=0.02),
name='conv4')
batch_norm4 = tf.layers.batch_normalization(conv4,
training = True,
epsilon = 1e-5,
name = 'batch_norm4')
conv4_out = tf.nn.leaky_relu(batch_norm4, alpha=alpha, name="conv4_out")
# 16x16x512 --> 8x8x1024
# Conv --> BatchNorm --> LeakyReLU
conv5 = tf.layers.conv2d(inputs = conv4_out,
filters = 1024,
kernel_size = [5, 5],
strides = [2, 2],
padding = "SAME",
kernel_initializer=tf.truncated_normal_initializer(stddev=0.02),
name='conv5')
batch_norm5 = tf.layers.batch_normalization(conv5,
training = True,
epsilon = 1e-5,
name = 'batch_norm5')
conv5_out = tf.nn.leaky_relu(batch_norm5, alpha=alpha, name="conv5_out")
# Flatten it
flatten = tf.reshape(conv5_out, (-1, 8*8*1024))
# Logits
logits = tf.layers.dense(inputs = flatten,
units = 1,
activation = None)
out = tf.sigmoid(logits)
return out, logits
def model_loss(input_real, input_z, output_channel_dim, alpha):
"""
Get the loss for the discriminator and generator
:param input_real: Images from the real dataset
:param input_z: Z input
:param out_channel_dim: The number of channels in the output image
:return: A tuple of (discriminator loss, generator loss)
"""
# Generator network here
g_model = generator(input_z, output_channel_dim)
# g_model is the generator output
# Discriminator network here
d_model_real, d_logits_real = discriminator(input_real, alpha=alpha)
d_model_fake, d_logits_fake = discriminator(g_model,is_reuse=True, alpha=alpha)
# Calculate losses
d_loss_real = tf.reduce_mean(
tf.nn.sigmoid_cross_entropy_with_logits(logits=d_logits_real,
labels=tf.ones_like(d_model_real)))
d_loss_fake = tf.reduce_mean(
tf.nn.sigmoid_cross_entropy_with_logits(logits=d_logits_fake,
labels=tf.zeros_like(d_model_fake)))
d_loss = d_loss_real + d_loss_fake
g_loss = tf.reduce_mean(
tf.nn.sigmoid_cross_entropy_with_logits(logits=d_logits_fake,
labels=tf.ones_like(d_model_fake)))
return d_loss, g_loss
def model_optimizers(d_loss, g_loss, lr_D, lr_G, beta1):
"""
Get optimization operations
:param d_loss: Discriminator loss Tensor
:param g_loss: Generator loss Tensor
:param learning_rate: Learning Rate Placeholder
:param beta1: The exponential decay rate for the 1st moment in the optimizer
:return: A tuple of (discriminator training operation, generator training operation)
"""
# Get the trainable_variables, split into G and D parts
t_vars = tf.trainable_variables()
g_vars = [var for var in t_vars if var.name.startswith("generator")]
d_vars = [var for var in t_vars if var.name.startswith("discriminator")]
update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS)
# Generator update
gen_updates = [op for op in update_ops if op.name.startswith('generator')]
# Optimizers
with tf.control_dependencies(gen_updates):
d_train_opt = tf.train.AdamOptimizer(learning_rate=lr_D, beta1=beta1).minimize(d_loss, var_list=d_vars)
g_train_opt = tf.train.AdamOptimizer(learning_rate=lr_G, beta1=beta1).minimize(g_loss, var_list=g_vars)
return d_train_opt, g_train_opt
def show_generator_output(sess, n_images, input_z, out_channel_dim, image_mode, image_path, save, show):
"""
Show example output for the generator
:param sess: TensorFlow session
:param n_images: Number of Images to display
:param input_z: Input Z Tensor
:param out_channel_dim: The number of channels in the output image
:param image_mode: The mode to use for images ("RGB" or "L")
:param image_path: Path to save the image
"""
cmap = None if image_mode == 'RGB' else 'gray'
z_dim = input_z.get_shape().as_list()[-1]
example_z = np.random.uniform(-1, 1, size=[n_images, z_dim])
samples = sess.run(
generator(input_z, out_channel_dim, False),
feed_dict={input_z: example_z})
images_grid = helper.images_square_grid(samples, image_mode)
if save == True:
# Save image
images_grid.save(image_path, 'JPEG')
if show == True:
plt.imshow(images_grid, cmap=cmap)
plt.show()
def train(epoch_count, batch_size, z_dim, learning_rate_D, learning_rate_G, beta1, get_batches, data_shape, data_image_mode, alpha):
"""
Train the GAN
:param epoch_count: Number of epochs
:param batch_size: Batch Size
:param z_dim: Z dimension
:param learning_rate: Learning Rate
:param beta1: The exponential decay rate for the 1st moment in the optimizer
:param get_batches: Function to get batches
:param data_shape: Shape of the data
:param data_image_mode: The image mode to use for images ("RGB" or "L")
"""
samples, losses = [], []
# Create our input placeholders
input_images, input_z, lr_G, lr_D = model_inputs(data_shape[1:], z_dim)
# Losses
d_loss, g_loss = model_loss(input_images, input_z, data_shape[3], alpha)
# Optimizers
d_opt, g_opt = model_optimizers(d_loss, g_loss, lr_D, lr_G, beta1)
i = 0
version = "firstTrain"
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
# Saver
saver = tf.train.Saver()
num_epoch = 0
if from_checkpoint == True:
saver.restore(sess, "./models/model.ckpt")
image_path = "./from_checkpoint_IMG/FCI.jpg"
show_generator_output(sess, 4, input_z, data_shape[3], data_image_mode, image_path, True, False)
else:
for epoch_i in range(epoch_count):
num_epoch += 1
if num_epoch % 5 == 0:
# Save model every 5 epochs
#if not os.path.exists("models/" + version):
# os.makedirs("models/" + version)
save_path = saver.save(sess, "./models/model.ckpt")
print("Model saved")
for batch_images in get_batches(batch_size):
# Random noise
batch_z = np.random.uniform(-1, 1, size=(batch_size, z_dim))
i += 1
# Run optimizers
_ = sess.run(d_opt, feed_dict={input_images: batch_images, input_z: batch_z, lr_D: learning_rate_D})
_ = sess.run(g_opt, feed_dict={input_images: batch_images, input_z: batch_z, lr_G: learning_rate_G})
if i % 10 == 0:
train_loss_d = d_loss.eval({input_z: batch_z, input_images: batch_images})
train_loss_g = g_loss.eval({input_z: batch_z})
# Save losses to view after training
losses.append((train_loss_d, train_loss_g))
# Save it
image_name = str(i) + ".jpg"
image_path = "./images/" + image_name
show_generator_output(sess, 4, input_z, data_shape[3], data_image_mode, image_path, True, False)
# Print every 5 epochs (for stability overwize the jupyter notebook will bug)
if i % 1500 == 0:
image_name = str(i) + ".jpg"
image_path = "./images/" + image_name
print("Epoch {}/{}...".format(epoch_i+1, epochs),
"Discriminator Loss: {:.4f}...".format(train_loss_d),
"Generator Loss: {:.4f}".format(train_loss_g))
show_generator_output(sess, 4, input_z, data_shape[3], data_image_mode, image_path, False, True)
# return losses, samples
return losses
# Size input image for discriminator
real_size = (128,128,3)
# Size of latent vector to generator
z_dim = 100
learning_rate_D = .00005 # Thanks to Alexia Jolicoeur Martineau https://ajolicoeur.wordpress.com/cats/
learning_rate_G = 2e-4 # Thanks to Alexia Jolicoeur Martineau https://ajolicoeur.wordpress.com/cats/
batch_size = 64
epochs = 215
alpha = 0.2
beta1 = 0.5
# Create the network
#model = DGAN(real_size, z_size, learning_rate, alpha, beta1)
# Load the data and train the network here
dataset = helper.Dataset(glob(os.path.join(data_resized_dir, '*.jpg')))
# with tf.Graph().as_default():
# losses, samples = train(epochs, batch_size, z_dim, learning_rate_D, learning_rate_G, beta1, dataset.get_batches,
# dataset.shape, dataset.image_mode, alpha)
with tf.Graph().as_default():
losses = train(epochs, batch_size, z_dim, learning_rate_D, learning_rate_G, beta1, dataset.get_batches,
dataset.shape, dataset.image_mode, alpha)
fig, ax = plt.subplots()
losses = np.array(losses)
plt.plot(losses.T[0], label='Discriminator', alpha=0.5)
plt.plot(losses.T[1], label='Generator', alpha=0.5)
plt.title("Training Losses")
plt.legend()
plt.show()
后記
項目本身沒有什么亮點,但是挺好玩的。由于本科畢設需要用到此類技術,接下來筆者會考慮更多接觸pytorch應用和理論知識的學習。另外,需要仔細思考在此基礎上如何開發出更新穎、更具實用價值的功能,不然就顯得太單調了。

 浙公網安備 33010602011771號
浙公網安備 33010602011771號