NCCL論文閱讀
NCCL論文閱讀
前言
NCCL作為當(dāng)下最為主流的GPU通信庫,它的很多系統(tǒng)設(shè)計(jì)被后續(xù)工作(如DeepEP)采納,NCCL本身也已經(jīng)成為了行業(yè)內(nèi)的標(biāo)桿。作為一名網(wǎng)絡(luò)領(lǐng)域的研究人員,很有必要對(duì)NCCL的內(nèi)部原理進(jìn)行深入分析和研究。不過,本人嘗試過直接閱讀NCCL的源碼,確實(shí)很難以理解,尤其是難以讓人對(duì)整個(gè)NCCL的設(shè)計(jì)框架有一個(gè)完整的概念。好在今年7月份,Nvidia官方發(fā)表了一篇分析NCCL的論文,里面對(duì)NCCL的設(shè)計(jì)進(jìn)行了系統(tǒng)性介紹。基于避重就輕(?)的原則,我們今天就來一起讀一下NCCL的這篇論文,學(xué)習(xí)一下其中關(guān)鍵的設(shè)計(jì)要點(diǎn)。
注:
- NCCL的這篇論文寫的其實(shí)非常清晰而且簡(jiǎn)單,對(duì)于追求原汁原味的讀者,建議直接閱讀原文:Demystifying NCCL: An In-depth Analysis of GPU Communication Protocols and Algorithms。本文主要是對(duì)原文的摘抄+翻譯+個(gè)人理解。有些細(xì)節(jié)一些地方可能會(huì)參考NCCL的官方文檔。
- 本文盡量不涉及對(duì)NCCL底層代碼實(shí)現(xiàn)的探討,在部分地方可能會(huì)引用一些具體代碼。本文參考了nccl_KIDGINBROOK的博客-CSDN博客。
概述
NCCL API
-
作為一個(gè)集合通信庫,NCCL的通信操作發(fā)生在多個(gè)通信成員(communicator)之間。每個(gè)communicator對(duì)應(yīng)一個(gè)GPU。所有communicator需要先進(jìn)行初始化并指定其使用的GPU,才能進(jìn)行通信。
-
NCCL通信成員的初始化分為四種情況:
-
單進(jìn)程&單線程對(duì)應(yīng)多GPU
這種情況下,單進(jìn)程只需要使用
ncclCommInitAll就可以初始化所有的GPU,為每個(gè)GPU都創(chuàng)建一個(gè)communicator,如下面這個(gè)例子:ncclComm_t comms[4]; int devs[4] = { 0, 1, 2, 3 }; ncclCommInitAll(comms, 4, devs); -
多進(jìn)程/線程,每個(gè)進(jìn)程/線程對(duì)應(yīng)一個(gè)GPU
這種情況下,所有進(jìn)程/線程需要先確定一個(gè)全局唯一個(gè)UniqueId(通過其他方式進(jìn)行通信,比如MPI),然后分別調(diào)用
ncclCommInitRank來初始化各自的GPU。例子如下:ncclUniqueId id; if (myRank == 0) ncclGetUniqueId(&id); MPI_Bcast(&id, sizeof(id), MPI_BYTE, 0, MPI_COMM_WORLD); ncclComm_t comm; ncclCommInitRank(&comm, nRanks, id, myRank); -
多進(jìn)程/線程,每個(gè)進(jìn)程/線程對(duì)應(yīng)多個(gè)GPU
同樣地,可以把上面兩種情況結(jié)合一下。有多個(gè)進(jìn)程/線程,每個(gè)進(jìn)程/線程對(duì)應(yīng)多個(gè)communitor(GPU),例子如下。
for (int i=0; i<ngpus; i++) { cudaSetDevice(devs[i]); ncclCommInitRank(comms+i, ngpus*nRanks, id, myRank*ngpus+i); } -
單個(gè)GPU多個(gè)communicator
最后,也可以讓一個(gè)GPU對(duì)應(yīng)多個(gè)communicator。這些communicator應(yīng)屬于不同的通信組,對(duì)應(yīng)不同的UniqueId。
CUDACHECK(cudaSetDevice(localRank)); for (int i = 0; i < commNum; ++i) { if (myRank == 0) ncclGetUniqueId(&id); MPICHECK(MPI_Bcast((void *)&id, sizeof(id), MPI_BYTE, 0, MPI_COMM_WORLD)); NCCLCHECK(ncclCommInitRank(&blockingComms[i], nRanks, id, myRank)); }
-
-
通信操作
NCCL支持多種集合通信操作(collective communication),包括
ncclAllReduce,ncclBroadcast,ncclReduce,ncclAllGather和ncclReduceScatter。NCCL還支持點(diǎn)對(duì)點(diǎn)的通信(Point-to-point communication)。至于這些操作的具體含義,以及其他的操作,這里不做贅述,詳見官方文檔。例子:
ncclAllReduce(sendbuff, recvbuff, count, datatype, op, comm, stream);上述指令會(huì)將該操作加入到操作流中,在這之后,可以通過
cudaStreamSynchronize指令來等待任務(wù)結(jié)束。 -
分組操作
NCCL支持將操作分組從而減少多次調(diào)用NCCL的開銷。具體做法是用
ncclGroupStart和ncclGroupEnd將多個(gè)操作包起來。在執(zhí)行ncclGroupStart之后,中間的通信操作會(huì)被阻塞住;直到ncclGroupEnd被調(diào)用時(shí),這些操作才會(huì)真正的被執(zhí)行。
多GPU管理
NCCL提供了3種調(diào)用GPU的方式,這三種方式各有優(yōu)劣:
-
每個(gè)進(jìn)程一個(gè)GPU
這種方式的優(yōu)點(diǎn)是隔離性,便于進(jìn)程管理。可以根據(jù)每個(gè)GPU對(duì)應(yīng)的NUMA節(jié)點(diǎn)來決定每個(gè)進(jìn)程被調(diào)度到哪個(gè)CPU上執(zhí)行。每個(gè)進(jìn)程有獨(dú)立的地址空間。
-
單進(jìn)程多線程,每個(gè)線程一個(gè)GPU
這種方式的優(yōu)點(diǎn)是便于進(jìn)程內(nèi)共享內(nèi)存,因?yàn)檫M(jìn)程內(nèi)的線程地址空間是相同的。這樣便于在多個(gè)GPU之間進(jìn)行直接內(nèi)存訪問,從而避免內(nèi)存拷貝的開銷。
-
單線程多個(gè)GPU
這種方式的有點(diǎn)是簡(jiǎn)單,便于開發(fā)和調(diào)試;缺點(diǎn)是單線程缺少并發(fā)性,可能影響效率。
數(shù)據(jù)傳輸
注:本段的介紹順序與NCCL原論文略有不同。本文希望盡可能從一個(gè)自頂向下的順序去講述整個(gè)通信過程。
通信通道
NCCL將通信路徑分為多個(gè)通道(channel)。每一個(gè)channel負(fù)責(zé)不相交的數(shù)據(jù)傳輸,使用獨(dú)立的硬件資源(包括GPU的流處理器SM和RDMA的QP)。多個(gè)channel的使用可以將傳輸任務(wù)平均的分配到多個(gè)硬件資源上,有助于提高系統(tǒng)的資源利用率。
對(duì)于小消息而言,使用多個(gè)channel可能導(dǎo)致每個(gè)channel傳輸?shù)南⑦^小,從而影響網(wǎng)絡(luò)的傳輸效率。因此對(duì)于小消息,NCCL會(huì)降低使用的channel數(shù)量。代碼詳見enqueue.cc。
在初始化communicator時(shí),NCCL會(huì)創(chuàng)建一些初始的channel結(jié)構(gòu)。在執(zhí)行集合通信操作時(shí),NCCL會(huì)根據(jù)操作算法、大小、網(wǎng)絡(luò)帶寬等信息自動(dòng)決定每個(gè)操作使用多少個(gè)channel。
對(duì)于ncclGroupStart和ncclGroupEnd之間的操作,NCCL會(huì)盡可能將操作分配到不同的channel上,從而提高操作間的并行性。
通信層
NCCL將通信分為節(jié)點(diǎn)內(nèi)通信(intra-node)和節(jié)點(diǎn)間通信(inter-node)兩種情況。每種情況有不同的傳輸策略。這些情況的特點(diǎn)如下圖所示:

節(jié)點(diǎn)內(nèi)通信

上圖展示了NCCL的節(jié)點(diǎn)內(nèi)通信策略。NCCL的節(jié)點(diǎn)內(nèi)通信主要使用了NVIDIA的GPUDirect Peer-to-Peer (P2P)技術(shù),允許GPU之間直接訪問內(nèi)存,無需CPU參與。
-
當(dāng)GPU之間通過NVLink互聯(lián)時(shí),NCCL實(shí)現(xiàn)基于NVLink的GPUDirect P2P通信。當(dāng)沒有NVLink時(shí),NCCL實(shí)現(xiàn)基于PCIe的GPUDirect P2P通信,這種方式依然要優(yōu)于基于CPU的
cudaMemcpy。 -
當(dāng)多個(gè)communicator屬于同一個(gè)進(jìn)程時(shí),NCCL額外支持一種
P2P_DIRECT的優(yōu)化。由于進(jìn)程內(nèi)的地址空間相同,GPU之間無需使用進(jìn)程間通信(IPC)的結(jié)構(gòu)。另外,GPU之間通信也無需經(jīng)過一個(gè)中間的緩沖(圖中的intermediate FIFO buffer),而是可以使用directSend和directRecv直接將數(shù)據(jù)從sendBuff傳輸?shù)?code>recvBuff。注意:GPUDirect P2P和
P2P_DIRECT這兩個(gè)名字有點(diǎn)像,但實(shí)際上是不同的東西。GPUDirect P2P是GPU的功能,核心在于繞過CPU;而P2P_DIRECT指直接訪問地址空間,從而實(shí)現(xiàn)零拷貝。P2P_DIRECT是基于GPUDirect P2P之上的。 -
當(dāng)GPU不支持GPUDirect P2P時(shí),NCCL還支持通過主機(jī)共享內(nèi)存(Shared Memory,SHM)的通信。在SHM模式下,一個(gè)GPU的控制進(jìn)程(CPU)負(fù)責(zé)將數(shù)據(jù)寫入到一塊共享的內(nèi)存區(qū)域,而另一個(gè)GPU的控制進(jìn)程負(fù)責(zé)從共享區(qū)域讀入數(shù)據(jù)。
-
最后,NCCL還支持使用網(wǎng)卡(NIC)進(jìn)行節(jié)點(diǎn)內(nèi)GPU之間的數(shù)據(jù)傳輸。這種方式可以更充分的利用PCIe帶寬,避免CPU成為瓶頸。前提是網(wǎng)卡支持GPUDirect RDMA。
節(jié)點(diǎn)間通信

上圖展示了NCCL的節(jié)點(diǎn)間通信。NCCL主要支持兩種節(jié)點(diǎn)間通信模式:使用TCP socker或者Infiniband (IB) verbs。
-
若網(wǎng)絡(luò)不支持RDMA,NCCL使用TCP socket通信。在這種模式下,intermediate buffer位于主機(jī)內(nèi)存中(CUDA pinned host memory)。發(fā)送端CPU將數(shù)據(jù)從GPU拷貝到主機(jī)上的buffer,再用socket發(fā)到接收端的buffer中。接收端收到數(shù)據(jù)后將其拷貝到GPU。使用主機(jī)內(nèi)存會(huì)導(dǎo)致PCIe開銷。發(fā)送端和接收端遵循一個(gè)rendezvous protocol,即它們需要先實(shí)現(xiàn)同步確定intermediate buffer中有足夠的空間,然后才會(huì)進(jìn)行實(shí)際的數(shù)據(jù)傳輸。
-
若網(wǎng)絡(luò)支持RDMA(Infiniband或RoCE),NCCL會(huì)使用IB進(jìn)行通信。與TCP socket相同的是,IB依然要使用intermediate buffer進(jìn)行數(shù)據(jù)傳輸,但buffer的位置取決于硬件因素。
若網(wǎng)卡無法直接訪問GPU內(nèi)存,則intermediate buffer位于主機(jī)內(nèi)存中。發(fā)送端GPU將數(shù)據(jù)拷貝到這塊內(nèi)存中,然后CPU的一個(gè)代理線程(proxy thread,每個(gè)rank一個(gè)proxy thread)發(fā)起RDMA write請(qǐng)求將數(shù)據(jù)發(fā)送到遠(yuǎn)端節(jié)點(diǎn)中。在接收端,代理線程將數(shù)據(jù)從主機(jī)內(nèi)存拷貝到GPU內(nèi)存中。
若網(wǎng)卡支持GPUDirect RDMA,則intermediate buffer位于GPU內(nèi)存中。網(wǎng)卡直接從GPU中讀寫數(shù)據(jù),從而避免了對(duì)主機(jī)內(nèi)存的訪問。
注:到目前為止,NCCL尚不支持GPU直接發(fā)起RDMA請(qǐng)求(GDA)。因此依然需要使用CPU代理線程發(fā)起RDMA請(qǐng)求。
-
一個(gè)communicator對(duì)每個(gè)遠(yuǎn)端節(jié)點(diǎn)和遠(yuǎn)端網(wǎng)卡建立多個(gè)channel(就是上文里的那個(gè)channel,默認(rèn)為``p2pnChannels`=2個(gè),詳見paths.cc),負(fù)責(zé)這個(gè)與這個(gè)遠(yuǎn)端網(wǎng)卡對(duì)應(yīng)的所有GPU進(jìn)行通信,每個(gè)channel維護(hù)獨(dú)立的QP。在創(chuàng)建任務(wù)時(shí),數(shù)據(jù)被分塊給不同的channel,一起被放入proxy的任務(wù)列表中。在執(zhí)行任務(wù)時(shí),proxy輪訓(xùn)這些來自不同channel的任務(wù)。這種多channel的連接可以提升多QP的并發(fā)性,提高網(wǎng)絡(luò)利用率。
-
在一個(gè)channel中,一個(gè)communicator對(duì)每個(gè)遠(yuǎn)端的rank(GPU)都建立兩個(gè)RDMA RC QP。
-
一個(gè)正向的QP負(fù)責(zé)發(fā)送數(shù)據(jù)。proxy會(huì)發(fā)起一個(gè)或多個(gè)RDMA_WRITE請(qǐng)求將數(shù)據(jù)寫入到對(duì)端。對(duì)于每一塊(對(duì)應(yīng)后文的chunk)數(shù)據(jù)的最后一個(gè)請(qǐng)求,proxy發(fā)送RDMA_WRITE_WITH_IMM用于通知發(fā)送結(jié)束。詳見ncclIbIsend。
-
一個(gè)反向的QP用于接受“clear-to-send”(CTS)消息。該消息攜帶遠(yuǎn)端的buffer地址、rkey、以及fifo隊(duì)尾指針等信息,用于告知發(fā)送端:遠(yuǎn)端可以接受數(shù)據(jù)了。
具體地,在RDMA建鏈時(shí),發(fā)送端會(huì)將本地的一個(gè)fifo隊(duì)列的內(nèi)存地址告知接收端。接收端在post recv之后,用RDMA_WRITE向發(fā)送端的fifo數(shù)組中用寫入CTS消息。詳見ncclIbPostFifo。
兩個(gè)QP有助于將控制消息和數(shù)據(jù)消息隔離開,降低控制消息的head-of-line延遲。
-
-
特別地,在GPUDirect RDMA下,每次接收端recv接收數(shù)據(jù)時(shí),都需要執(zhí)行一下flush操作。這是因?yàn)楫?dāng)網(wǎng)卡產(chǎn)生CQE到CPU時(shí),數(shù)據(jù)不一定已經(jīng)寫入到GPU。具體地,在CPU輪訓(xùn)CQ,收到之前所有post recv的CQE后(調(diào)用ncclIbTest),會(huì)向一個(gè)特殊的本地loopback QP發(fā)起一個(gè)RDMA_READ請(qǐng)求(調(diào)用ncclIbFlush)。這個(gè)READ請(qǐng)求的完成標(biāo)志著之前所有的PCIe WRITE都已經(jīng)完成,這樣就保證了數(shù)據(jù)已經(jīng)到達(dá)GPU。詳見recvProxyProgress。
-
-
雖然論文中沒有提及,但現(xiàn)版本的NCCL是支持零拷貝(zero-copy)的。即不使用intermediate buffer,直接將數(shù)據(jù)寫入到遠(yuǎn)端GPU的output buffer中。詳見User Buffer Registration。
底層通信協(xié)議
NCCL支持三種通信協(xié)議:Simple, LL (low latency)和LL128。下表展示了三者各自的特點(diǎn)。

-
Simple
Simple協(xié)議適用于大消息,用于最大化帶寬利用率。上文提到的數(shù)據(jù)切塊,flush就是針對(duì)simple協(xié)議的。
-
LL
LL適用于小消息,用于優(yōu)化延遲而非帶寬利用率。LL的每個(gè)消息是一個(gè)8-byte的RDMA ATOMIC,包含4-byte的數(shù)據(jù)和4-byte的flag。LL的intermediate buffer必須位于主機(jī)內(nèi)存,CPU輪訓(xùn)flag從而得知數(shù)據(jù)是否傳輸完成。(因?yàn)镃PU輪訓(xùn)GPU內(nèi)存非常慢,所以用主機(jī)內(nèi)存。)
-
LL128
LL128在帶寬利用率和延遲之間進(jìn)行了trade-off。LL128發(fā)送128-byte的RDMA WRITE,包括120-byte的數(shù)據(jù)和8-byte的flag,使得帶寬利用率約為95%。在發(fā)送數(shù)據(jù)時(shí),LL128依舊仿照Simple對(duì)一整塊的數(shù)據(jù)進(jìn)行發(fā)送。
LL128在NVLink上表現(xiàn)良好。不過LL128依賴于傳輸設(shè)備支持128-byte的原子寫,可能不適用于某些PCIe設(shè)備。
集合通信算法
集合通信算法是NCCL的核心。NCCL將每個(gè)集合通信算法拆分為若干個(gè)底層的通信原語,并分配到多個(gè)并行的channel上。算法的選擇取決于網(wǎng)絡(luò)拓?fù)洌╮ing或者tree)。
算法和協(xié)議支持
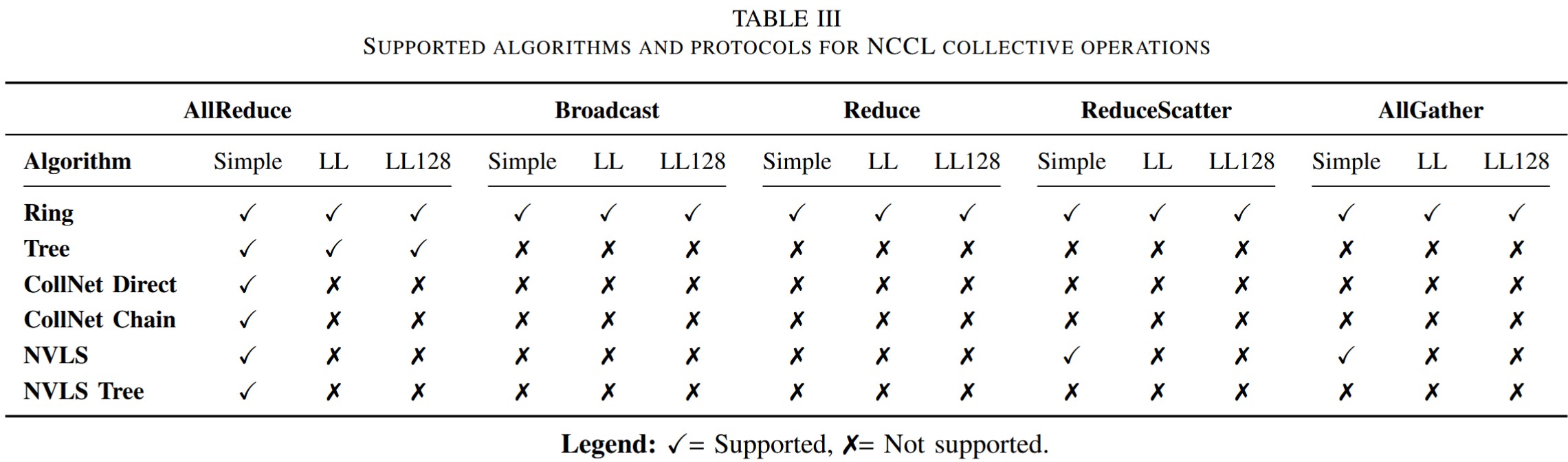
上圖展示了NCCL的不同算法和協(xié)議之間的支持關(guān)系。其中CollNet需要網(wǎng)絡(luò)交換機(jī)支持在網(wǎng)計(jì)算(如NVIDIA SHARP),NVLS需要NVLink Switch(NVSwitch)。本文不涉及CollNet和NVLS的具體實(shí)現(xiàn)。
通信原語
NCCL將上層的通信算法拆分為底層的通信原語(primitives)。常見的原語包括send, recv, recvReduceSend, recvCopySend, recvReduceCopySend,以及它們的direct版本(對(duì)應(yīng)前文提到的P2P_DIRECT)。這些原語的意義跟它們的名字相同。例如,recvReduceCopySend表示GPU先從上一個(gè)遠(yuǎn)端GPU接受數(shù)據(jù),將數(shù)據(jù)與本地的數(shù)據(jù)進(jìn)行reduce,再將結(jié)果拷貝到輸出buffer中,最后發(fā)送給下一個(gè)遠(yuǎn)端GPU。
迭代執(zhí)行模型
NCCL對(duì)數(shù)據(jù)進(jìn)行不同層次的分塊,用于不同粒度的并行。
-
NCCL將數(shù)據(jù)切分為若干連續(xù)的段,分配給不同的channel,不同channel并行處理數(shù)據(jù)。
-
每一個(gè)channel有一個(gè)固定大小的buffer。若一個(gè)channel的數(shù)據(jù)長(zhǎng)度超過了它的buffer大小,則將數(shù)據(jù)切分為多個(gè)外層循環(huán)(outer loop iteration),每個(gè)iteration處理一個(gè)buffer的數(shù)據(jù)。channel迭代執(zhí)行每個(gè)iteration。
-
channel的buffer被分為多個(gè)slot(通常為
NCCL_STEP=8個(gè))。在每個(gè)iteration中,數(shù)據(jù)被切分為多干個(gè)chunk,每個(gè)chunk對(duì)應(yīng)buffer的一個(gè)slot(chunk循環(huán)使用這些slot)。每個(gè)slot/chunk獨(dú)立的執(zhí)行原語的不同階段(比如recv+reduce+send)。多個(gè)chunk的好處是可以保證通信始終處于繁忙狀態(tài),提升通信帶寬的利用率。 -
NCCL的最基本數(shù)據(jù)單元成為element。對(duì)于不含計(jì)算的操作(如
ncclAllGather和ncclBroadcast),每個(gè)element是一個(gè)byte。對(duì)于含計(jì)算的操作(如ncclAllReduce,ncclReduceScatter,ncclReduce),每個(gè)element是一個(gè)用戶指定的數(shù)據(jù)類型(如float)。
下圖展示了NCCL中的數(shù)據(jù)切分方案。

執(zhí)行模型對(duì)應(yīng)GPU架構(gòu)
接下來,我們看一下上面的執(zhí)行模型是如何與GPU架構(gòu)對(duì)應(yīng)的。
-
Grid和Block結(jié)構(gòu)
一個(gè)NCCL kernel在啟動(dòng)時(shí)的grid維度為
(nChannels, 1, 1),即每個(gè)CUDA block對(duì)應(yīng)一個(gè)channel。在每個(gè)block內(nèi)部,NCCL使用動(dòng)態(tài)數(shù)量的threads。這個(gè)數(shù)量由NCCL自動(dòng)調(diào)節(jié)。 -
channel與block ID的關(guān)系
在啟動(dòng)kernel時(shí),NCCL會(huì)對(duì)每個(gè)kernel傳入一個(gè)
channelMask,代表這個(gè)kernel使用的所有channel編號(hào)。一個(gè)blockIdx.x的block對(duì)應(yīng)的channel編號(hào)就是channelMask中第blockIdx.x個(gè)為1的位。 -
warp組織
NCCL為每個(gè)warp分配不同的工作。前兩個(gè)warp負(fù)責(zé)初始化:warp 0負(fù)責(zé)加載communicator metadata到GPU共享內(nèi)存,而warp 1負(fù)責(zé)加載每個(gè)channel負(fù)責(zé)的數(shù)據(jù)。其余的warp負(fù)責(zé)真正的計(jì)算和通信任務(wù)。
不同集合通信操作的warp分工不同。例如,對(duì)于端到端通信,warp被分為send和receive兩個(gè)階段,它們的數(shù)量會(huì)根據(jù)實(shí)際傳輸?shù)臄?shù)據(jù)進(jìn)行動(dòng)態(tài)調(diào)節(jié)。
-
基于slot的流水線模型
前面提到,每個(gè)channel包含
NCCL_STEPS個(gè)slot,形成流水線結(jié)構(gòu)。一個(gè)warp中的threads會(huì)輪流使用這些slot進(jìn)行數(shù)據(jù)傳輸。每個(gè)slot包含一個(gè)fifo結(jié)構(gòu),標(biāo)記著當(dāng)前slot的運(yùn)行狀態(tài),包括當(dāng)前的數(shù)據(jù)指針等。不同的slot可以同時(shí)位于流水線的不同階段:正在計(jì)算,等待傳輸,正在傳輸,傳輸完成等。 -
thread級(jí)別數(shù)據(jù)搬運(yùn)
在最細(xì)的粒度,NCCL將數(shù)據(jù)分配給每個(gè)warp內(nèi)的不同threads。一個(gè)warp中的threads同時(shí)處理不同的數(shù)據(jù)element。例如,一個(gè)warp中的thread同時(shí)處理一連串相同的操作(send, reduce, copy),只不過處理不同的data element或者內(nèi)存地址。這符合GPU的SIMT架構(gòu)。
-
多個(gè)并發(fā)的流水線
NCCL的多個(gè)channel并行運(yùn)行在多個(gè)SM上,每個(gè)channel內(nèi)的slot運(yùn)行在原語的不同階段上,每個(gè)warp負(fù)責(zé)執(zhí)行不同階段的通信計(jì)算任務(wù)。這種多層次的流水線可以最大化帶寬利用率。
集合通信算法分析
在了解了NCCL的執(zhí)行模型后,我們可以來看NCCL的集合通信算法了。我們會(huì)分析每個(gè)上層的通信算法是如何被拆分為底層原語,并運(yùn)行在上面的執(zhí)行模型上的。
前面提到,NCCL的任務(wù)分為多個(gè)iteration。根據(jù)不同的iteration能否流水線執(zhí)行,NCCL的算法可以分為兩種:流水線(pipelined)和非流水線(non-pipelined)。
-
非流水線算法
在非流水線算法中,每個(gè)GPU需要完全執(zhí)行一個(gè)iteration中的所有操作后才能開始執(zhí)行下一個(gè)iteration。非流水線算法包括Ring AllReduce, Ring AllGather和Ring ReduceScatter。在下面的分析中,用\(k\)表示參與集合通信的GPU數(shù)量。在Ring拓?fù)渲校@\(k\)個(gè)GPU形成一個(gè)環(huán)形結(jié)構(gòu)。
-
Ring AllReduce

NCCL的Ring AllReduce對(duì)所有\(k\)個(gè)GPU上的數(shù)據(jù)進(jìn)行聚合,并將完整的結(jié)果交給所有GPU。上圖展示了Ring AllReduce的大致流程,包括一個(gè)類似ReduceScatter的過程和一個(gè)類似AllGather的過程。在每個(gè)iteration中,Ring AllReduce的流程包含\(2k-1\)?步(step),如下圖所示。

在第0步,所有GPU發(fā)送自己的一塊數(shù)據(jù)
send給自己的下一個(gè)鄰。在接下來的\(k-2\)步,所有GPU執(zhí)行recvReduceSend,從上一個(gè)鄰居接受數(shù)據(jù),與本地的數(shù)據(jù)進(jìn)行聚合,并將結(jié)果發(fā)給下一個(gè)鄰居。在第\(k-1\)步,所有GPU使用recvReduceCopySend收到一塊數(shù)據(jù),與本地?cái)?shù)據(jù)聚合,這樣就得到了最終的一塊數(shù)據(jù)結(jié)果,然后將該結(jié)果拷貝到output buffer中,最后把這塊數(shù)據(jù)發(fā)給下一個(gè)鄰居。在接下來\(k-2\)?步,所有GPU使用recvCopySend從上一個(gè)鄰居獲取一塊聚合好的結(jié)果,拷貝到output buffer中,并將其發(fā)給下一個(gè)鄰居。在最后一步,每個(gè)GPU只需要進(jìn)行recv收到最后一塊結(jié)果。 -
Ring AllGather

NCCL的Ring AllGather使\(k\)個(gè)GPU都獲得它們?nèi)康臄?shù)據(jù)。其流程分為\(k\)步。在第0步,所有GPU先將自己的數(shù)據(jù)拷貝到output buffer中,并發(fā)送給下一個(gè)鄰居。若是in-place操作,則無需進(jìn)行拷貝。在接下來\(k-2\)步,每個(gè)GPU用
recvCopySend從上一個(gè)鄰居接受數(shù)據(jù),拷貝到output buffer中,并發(fā)送給下一個(gè)鄰居;在最后一步,每個(gè)GPU用recv接收最后一塊數(shù)據(jù)。 -
Ring ReduceScatter
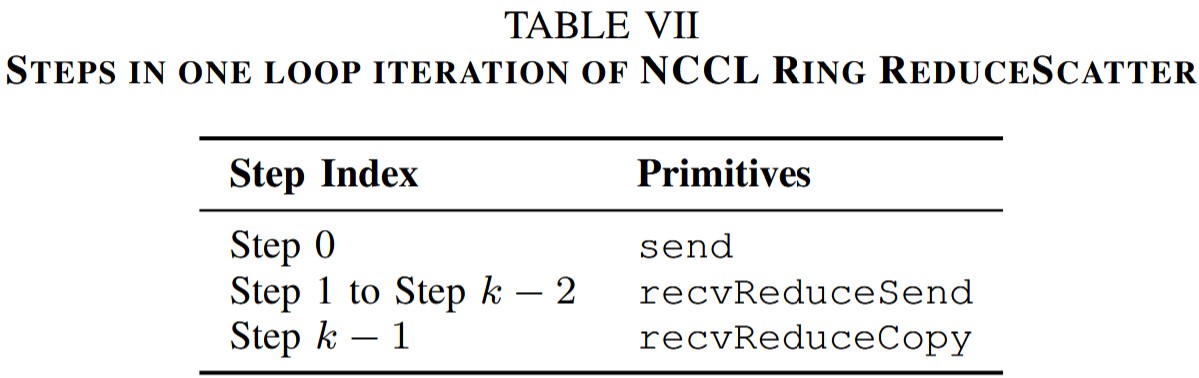
在Ring ReduceScatter開始之前,所有GPU的send buffer包含\(k\)塊獨(dú)立的數(shù)據(jù)。ReduceScatter對(duì)這些數(shù)據(jù)進(jìn)行聚合,并將結(jié)果分發(fā)給不同GPU。其流程分為\(k\)步。在第0步,所有GPU發(fā)送一塊本地?cái)?shù)據(jù)給下一個(gè)鄰居。在接下來\(k-2\)步,所有GPU用
recvReduceSend從上一個(gè)鄰居接受數(shù)據(jù),與本地?cái)?shù)據(jù)進(jìn)行聚合,并發(fā)給下一個(gè)鄰居;在最后一步,所有GPU用recvReduceCopy從上一個(gè)鄰居接受數(shù)據(jù),與本地?cái)?shù)據(jù)進(jìn)行聚合,并拷貝到output buffer。
特別注意,雖然Ring AllReduce的流程大致上和Ring ReduceScatter+Ring AllGather很像,但它們內(nèi)部并不相同。一方面,Ring AllReduce將其中的原語進(jìn)行了合并,可以實(shí)現(xiàn)更好的流水線。另一方面,Ring AllReduce和Ring ReduceScatter與Ring AllGather內(nèi)部的數(shù)據(jù)排布并不相同。以上面的Fig.4為例。在Ring AllReduce中,若數(shù)據(jù)被劃分為若干個(gè)連續(xù)的段,分配給不同的channel。假設(shè)Ring ReduceScatter也采用同樣的排布,則在右上角的ReduceScatter結(jié)果中,每個(gè)channel都是圖中的排布情況。這與ReduceScatter的語義不符:在ReduceScatter中,第\(i\)個(gè)GPU應(yīng)該得到全局的第\(i\)塊數(shù)據(jù),而不是每一個(gè)channel內(nèi)部的第\(i\)塊數(shù)據(jù)。不過,我還沒弄清楚NCCL的Ring ReduceScatter是如何保證數(shù)據(jù)排布的正確性的。這個(gè)留待以后探究,如果有知道的讀著歡迎與我討論。
-
-
流水線算法
在流水線算法中,不同iteration中的steps可以同時(shí)進(jìn)行。流水線算法包含Tree AllReduce, Ring Broadcast和Ring Reduce。
-
Tree AllReduce

上圖左下角展示了一個(gè)4個(gè)節(jié)點(diǎn)的tree拓?fù)洹P枰⒁獾氖沁@里的分支只存在于節(jié)點(diǎn)之間。節(jié)點(diǎn)內(nèi)的GPU是形成一條鏈的結(jié)構(gòu)。Tree AllReduce的每個(gè)iteration大致分為兩個(gè)階段:Reduce和Broadcast。
在NCCL的一種基于Tree的實(shí)現(xiàn)方案中,這兩個(gè)階段可以同時(shí)進(jìn)行。具體而言,NCCL將SM分為兩組,一組負(fù)責(zé)從葉子到根的Reduce,另一組負(fù)責(zé)從根到葉子的Broadcast。由于Reduce相比Broadcast更復(fù)雜一些,所以可以給Reduce階段分配更多的threads。

首先,所有葉子GPU將自己的數(shù)據(jù)
send給父節(jié)點(diǎn)。中間的GPU用recvReduceSend從子節(jié)點(diǎn)接收數(shù)據(jù),與本地?cái)?shù)據(jù)進(jìn)行reduce,并發(fā)給父節(jié)點(diǎn)。根GPU用recvReduceCopySend得到最終結(jié)果,并發(fā)給子節(jié)點(diǎn)。然后中間GPU用recvCopySend接收結(jié)果并發(fā)給自己的子節(jié)點(diǎn)。葉子GPU用recv接收結(jié)果。在上述Tree AllReduce算法中,由于Reduce和Broadcast階段可以流水線執(zhí)行,每個(gè)節(jié)點(diǎn)的收發(fā)帶寬都可以充分利用。但對(duì)于一般的Tree Reduce或者Tree Broadcast而言,Tree的拓?fù)鋾?huì)導(dǎo)致葉子節(jié)點(diǎn)只有發(fā)送或者接受的流量,導(dǎo)致帶寬浪費(fèi)。為了解決這個(gè)問題,NCCL采用了double binary tree (DBT)的拓?fù)洹H缦聢D所示:

在普通binary tree基礎(chǔ)上,DBT創(chuàng)建了第二棵樹。若節(jié)點(diǎn)數(shù)目為奇數(shù),則第二棵樹可以通過將第一棵樹向左移動(dòng)一位得到。若節(jié)點(diǎn)數(shù)目為偶數(shù),則第二棵樹可以是第一棵樹的鏡像。在DBT中,沒有一個(gè)節(jié)點(diǎn)在兩棵樹中都是非葉子節(jié)點(diǎn),至多一個(gè)節(jié)點(diǎn)在兩棵樹中都是葉子節(jié)點(diǎn)。
以基于DBT的Broadcast算法為例。NCCL將數(shù)據(jù)分為兩部分,交給不同的樹,對(duì)應(yīng)不同的channel,每個(gè)channel處理其中的一棵樹。在每一時(shí)刻,中間節(jié)點(diǎn)把數(shù)據(jù)用
recvCopySend從父節(jié)點(diǎn)接收數(shù)據(jù)并下發(fā)給子節(jié)點(diǎn)。圖中的紅色表示當(dāng)前時(shí)刻正在發(fā)生數(shù)據(jù)傳輸?shù)穆窂健?/p> -
Ring Broadcast

NCCL的Ring Broadcast以一個(gè)鏈的形狀對(duì)數(shù)據(jù)進(jìn)行廣播。根節(jié)點(diǎn)用
send(對(duì)于in-place操作)或者copySend發(fā)送數(shù)據(jù),中間節(jié)點(diǎn)用recvCopySend進(jìn)行傳遞,最后的節(jié)點(diǎn)用recv接收數(shù)據(jù)。 -
Ring Reduce
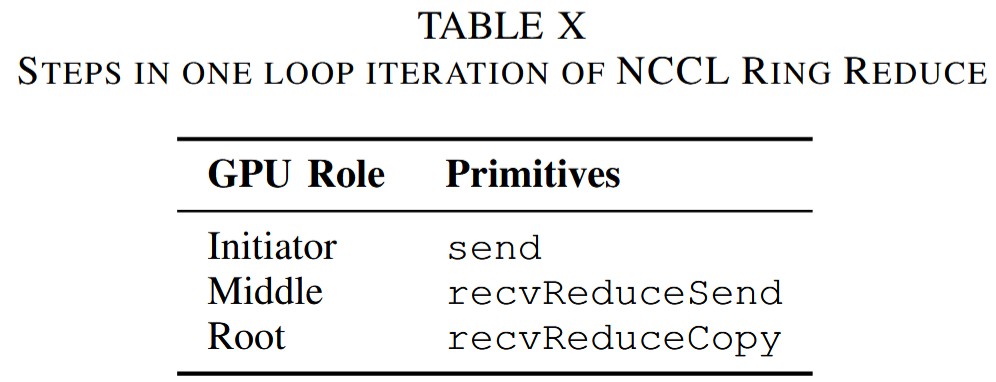
NCCL的Ring Reduce與Broadcast基本相反,以一個(gè)鏈的形狀將數(shù)據(jù)聚合到根節(jié)點(diǎn)。
-
總結(jié)
本文從一個(gè)比較上層的角度分析了NCCL的整體設(shè)計(jì),包括其API、傳輸層協(xié)議、對(duì)GPU架構(gòu)的利用、以及簡(jiǎn)略的通信算法。其中的很多設(shè)計(jì)都是被后續(xù)工作所使用的。比如DeepEP也沿用了其channel的結(jié)構(gòu),以及GPU內(nèi)部warp的分工等。當(dāng)然,NCCL的有些設(shè)計(jì)也被后人詬病,比如proxy的使用可能導(dǎo)致CPU成為瓶頸,未來可能會(huì)被GDA技術(shù)取代。本文也有很多細(xì)節(jié)部分沒有提及,比如NCCL如何識(shí)別并構(gòu)建網(wǎng)絡(luò)拓?fù)洌约皃rimitive內(nèi)部如何實(shí)現(xiàn)等等。總的來說,本文很好的展示了如何設(shè)計(jì)一個(gè)GPU通信庫以充分利用GPU資源。這對(duì)于未來基于NCCL進(jìn)行開發(fā)或者設(shè)計(jì)新的通信庫還是很有借鑒意義的。
| 歡迎來原網(wǎng)站坐坐! >原文鏈接<

 浙公網(wǎng)安備 33010602011771號(hào)
浙公網(wǎng)安備 33010602011771號(hào)