
EWCMF ERA5 小時尺度數據 Python API Windows 多線程下載教程(.grib)
ERA5 hourly data on single levels from 1940 to present -- Python API Download
1. ERA5下載網址-注冊ECMWF賬號-登錄



注意:記得勾選權限,不然可能會導致 API request 連接不成功。
在ERA5網站中個人主頁“Your profile”-“Licences”-“Dataset licences”-“Licence to use Copernicus Products”權限打勾,即可。


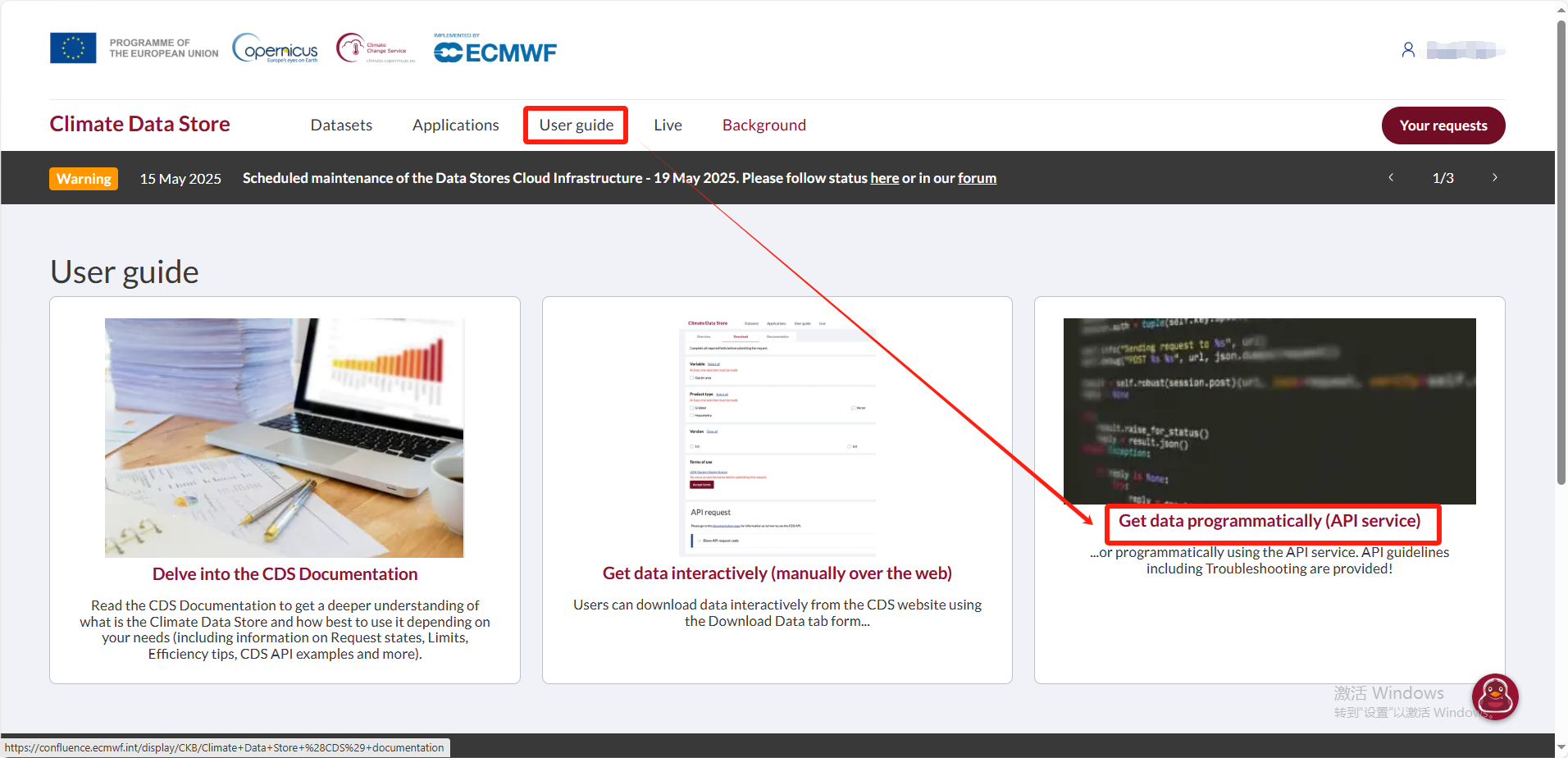
2. 找到密鑰
“User guide"-"Get data programmatically (API service)",點開下滑找到自己的“url”和“key”,復制保存代碼。
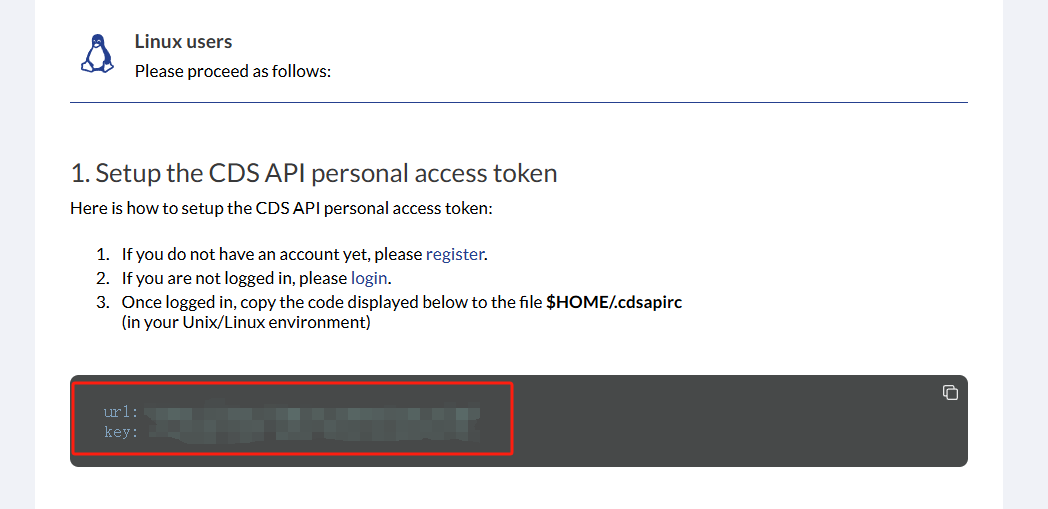
3. 配置 .cdsapirc文件
在 ‘C:\Users\用戶名’ 路徑下新建文本文檔,將步驟2中的兩行文字復制進新建的文本文檔,保存退出后,將文檔重命名為 .cdsapirc。

4. 準備Python運行環境
在 cmd 或 Vscode 或 Pycharm 中安裝 cdsapi 庫(必要):
pip3 install cdsapi # for Python 3 或嘗試 pip3 install --user cdsapi # for Python 3
其他庫可根據代碼自行添加。
5. 自選指標得到 API request

6. 并行下載
將得到的API request 代碼帶入如下并行下載腳本(下載變量、保存路徑、時間等需要自行修改)
import os import time import datetime from queue import Queue from threading import Thread, Lock import cdsapi import logging from tqdm import tqdm # 配置參數(按需更改) VARS = ['total_precipitation'] BASE_DIR = "F:/O/Data/era5/" MIN_FILE_SIZE = 10 * 1024 * 1024 # 10MB MAX_RETRIES = 5 REQUEST_TIMEOUT = 600 # 10分鐘超時 MAX_WORKERS = 2 # 降低并發數以符合CDS API限制 # 配置日志 logging.basicConfig( level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s', handlers=[ logging.FileHandler('era5_download.log'), logging.StreamHandler() ] ) # 文件鎖避免并發寫入沖突 file_lock = Lock() def ensure_dir(var): """確保目錄存在""" path = os.path.join(BASE_DIR, var) os.makedirs(path, exist_ok=True) return path def download_one_file(var, riqi): """帶重試機制的安全下載函數""" filename = os.path.join(ensure_dir(var), f"era5.{var}.{riqi}.grib") # 檢查文件是否已完整存在 if os.path.exists(filename) and os.path.getsize(filename) >= MIN_FILE_SIZE: logging.info(f"File exists: {filename}") return True for attempt in range(MAX_RETRIES): try: # 創建臨時文件 temp_file = f"{filename}.tmp" c = cdsapi.Client(timeout=REQUEST_TIMEOUT) # 按需更改 c.retrieve( 'reanalysis-era5-single-levels', { 'product_type': 'reanalysis', 'variable': var, 'year': riqi[0:4], 'month': riqi[-2:], "day": [ "01", "02", "03", "04", "05", "06", "07", "08", "09", "10", "11", "12", "13", "14", "15", "16", "17", "18", "19", "20", "21", "22", "23", "24", "25", "26", "27", "28", "29", "30", "31" ], 'time': [ f"{h:02d}:00" for h in range(24) ], "format": "grib" }, temp_file ) # 驗證文件完整性 if os.path.getsize(temp_file) >= MIN_FILE_SIZE: with file_lock: os.replace(temp_file, filename) logging.info(f"Download succeeded: {filename}") return True else: os.remove(temp_file) raise ValueError("Downloaded file is too small") except Exception as e: logging.warning(f"Attempt {attempt + 1} failed for {filename}: {str(e)[:200]}") time.sleep(2 ** attempt) # 指數退避 if os.path.exists(temp_file): os.remove(temp_file) logging.error(f"Max retries exceeded for {filename}") return False class DownloadWorker(Thread): def __init__(self, queue): Thread.__init__(self) self.queue = queue def run(self): while True: var, riqi = self.queue.get() try: download_one_file(var, riqi) except Exception as e: logging.error(f"Error processing {var} {riqi}: {str(e)[:200]}") finally: self.queue.task_done() def generate_dates(start_date, end_date): """生成日期序列""" dates = [] d = start_date delta = datetime.timedelta(days=1) while d <= end_date: dates.append(d.strftime("%Y%m")) d += delta return sorted(list(set(dates))) # 去重并排序 def main(): start_time = time.time() # 日期范圍 start_date = datetime.date(2024, 1, 1) end_date = datetime.date(2024, 12, 31) date_list = generate_dates(start_date, end_date) # 創建任務隊列 queue = Queue() # 填充隊列 for var in VARS: for riqi in date_list: queue.put((var, riqi)) # 創建工作線程 for _ in range(MAX_WORKERS): worker = DownloadWorker(queue) worker.daemon = True worker.start() # 進度監控 with tqdm(total=len(VARS)*len(date_list), desc="Download Progress") as pbar: while not queue.empty(): pbar.n = len(VARS)*len(date_list) - queue.qsize() pbar.refresh() time.sleep(1) queue.join() logging.info(f"Total time: {(time.time() - start_time)/60:.1f} minutes") if __name__ == '__main__': main()
下載請求進程可以在官網上看到
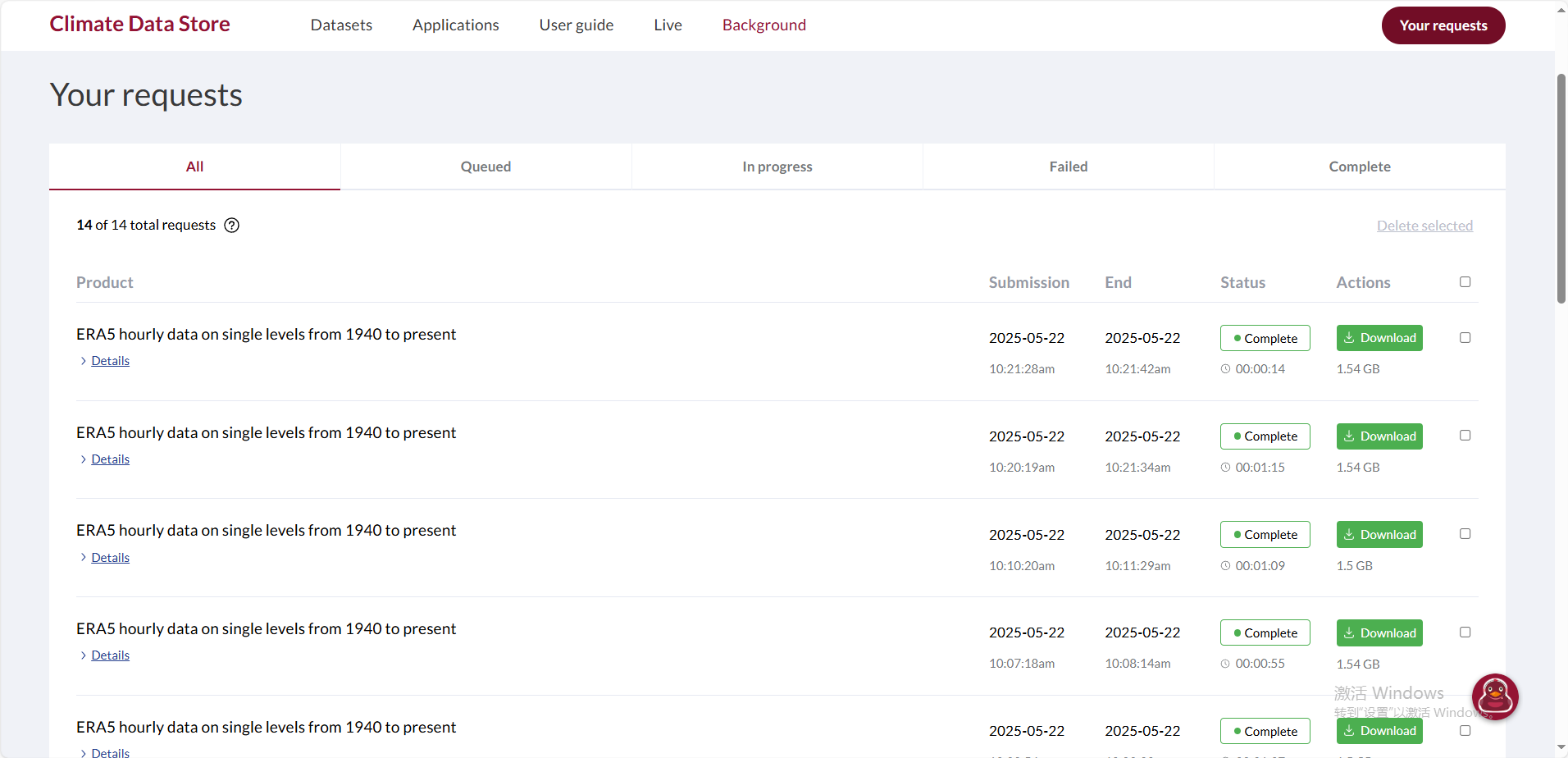
注意: 如果代碼報錯,沒有在官網上看到下載請求進程,則可能是 .cdsapirc文件內容有問題,可以嘗試將“url"和"key"冒號后的空格刪除,即可。
7. 下載成功界面(部分)

另外,nc文件下載同理,但是nc文件會更大,且下載時間會更長。

 浙公網安備 33010602011771號
浙公網安備 33010602011771號