
深度學習基礎理論————常見評價指標以及Loss Function
評價指標
準確率/精確率/召回率
| Positive (預測到的正例) | Negative (預測到的反例) | |
|---|---|---|
| True (預測結果為真) | TP | TN |
| False (預測結果為假) | FP | FN |
爭對正案例的計算:
1、準確率計算方式(ACC):\(Acc= \frac{TP+TN}{TP+TN+FP+FN}\)
2、精確率計算方式(Precision):\(\frac{TP}{TP+FP}\)
3、召回率計算方式(Recall):\(\frac{TP}{TP+FN}\)
4、F1計算方式:\(\frac{2\times Precision \times Recall}{Precision+ Recall}\)
| 指標 | 優點 | 缺點 |
|---|---|---|
| 準確率 | - 直觀且易理解 | - 在類別不平衡的情況下可能誤導模型評估 |
| 精確率 | - 衡量預測為正類的樣本中,實際為正類的比例;適用于避免假陽性 | - 可能忽視召回率,導致漏掉正類樣本(假陰性) |
| 召回率 | - 衡量模型對正類樣本的識別能力;適用于避免假陰性 | - 可能導致精確率較低,增加誤報(假陽性) |
| F1 分數 | - 平衡精確率和召回率,適用于不平衡的任務 | - 不能單獨反映精確率或召回率,可能不適用于需要單獨關注某一項的場景 |
BLEU
BLEU 采用一種N-gram的匹配規則,原理比較簡單,就是比較譯文和參考譯文之間n組詞的相似的一個占比
原文:今天天氣不錯
機器譯文:It is a nice day today
人工譯文:Today is a nice day
1-gram:

命中5個詞,那么計算得到匹配度為:\(5/6\)
3-gram:
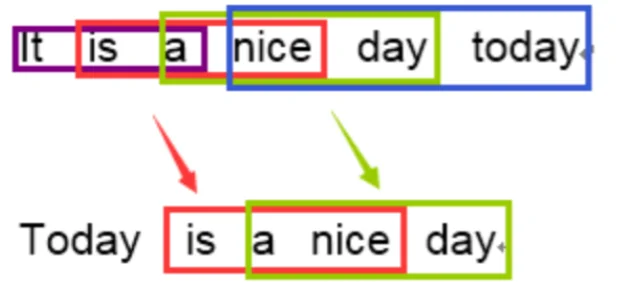
計算得到匹配度為:\(2/4\)
在通過結合召回率和懲罰因子之后得到BLEU計算公式為:
使用例子,直接使用第三方庫sacrebleu
import sacrebleu
hyps = ['我有一個帽衫', '大大的帽子']
refs = ['你好,我有一個帽衫', '帽子大大的']
bleu = sacrebleu.corpus_bleu(hyps, [refs], tokenize='zh')
print(float(bleu.score))
# 59.809989126151606
Loss Function
Cross-Entropy Loss(交叉熵損失)
交叉熵損失用于分類任務,它度量的是預測概率分布與真實標簽分布之間的差異。通常用于多分類問題。交叉熵損失公式(多分類)如下:
其中\(N\)為類別數量,\(y_i\)真實標簽數據,\(p_i\)模型預測概率。二分類交叉熵損失為:\(Loss=?[ylog(p)+(1?y)log(1?p)]\)
在pytorch中對于交叉熵損失函數主要參數:
- 1、label_smoothing (float, optional):通過平滑標簽的方式來避免模型過度自信,提高模型的泛化能力并緩解類別不平衡問題的技術。假設模型有 C 個類別,標簽為 y,真實標簽的平滑值為 ε,則:對于真實類別 y = 1,標簽值變為 1 - ε;對于其他類別 y ≠ 1,標簽值變為 ε / (C - 1)
- 2、ignore_index (int, optional):忽略某些特定的標簽,通常用于標記某些數據的特殊情況,如填充(padding)區域、無效標簽或其他不需要參與損失計算的標簽
- 3、reduction (str, optional):'none'、'mean' 和 'sum'分別表示對最后 不匯總、平均值、求和
- 4、weight:相當于在計算損失過程中給每一個標簽額外補充一個權重
對于交叉熵損失計算從代碼角度出發需要考慮的就是輸入數據格式:
InputShape:\((N,C)\) 或者 \((N,C,d_1,...,d_K)\)。Target:\((N)\) 或者 \((N,C,d_1,...,d_K)\) 其中 C代表類別,N代表batch_size。從數據格式上可以看出也就是保證N、C在同一維度即可
?值得注意的是,在pytorch的交叉熵損失里面已經計算了softmax/sigmoid,所以模型輸出如果用交叉熵損失函數就不需要用softmax/sigmoid處理
Mean Squared Error(均方誤差)
均方誤差損失用于回歸任務,度量預測值與真實值之間的差異。MSE 計算的是預測值和實際值的平方誤差的平均值。MSE 公式:
其中\(N\)為類別數量,\(y_i\)真實標簽數據,\(p_i\)模型預測概率。例子:比如說預測類別(假設為3),模型輸出之后通過sigmoid/softmax處理之后得到:
| 預測 | 真實 |
|---|---|
| 0.3 0.3 0.4 | 0 0 1 (A) |
| 0.3 0.4 0.3 | 0 1 0 (B) |
| 0.1 0.2 0.7 | 1 0 0 (C) |
均方誤差計算:\(\frac{(0.3-0)^2+(0.3-0)^2+(0.4-1)^2+...}{3}=0.81\)
交叉熵計算:\(\frac{-(0\times log0.3+ 0\times log0.3+ 1\times log0.4+ ...)}{3}=1.37\)
Focal Loss
Focal Loss主要用于處理樣本失衡問題(樣本里面標簽不平衡問題,比如說分類任務標簽大部分是類別A只有少部分是標簽B),其原理也很簡單可以直接在原交叉熵基礎上補充一個 因子即可。
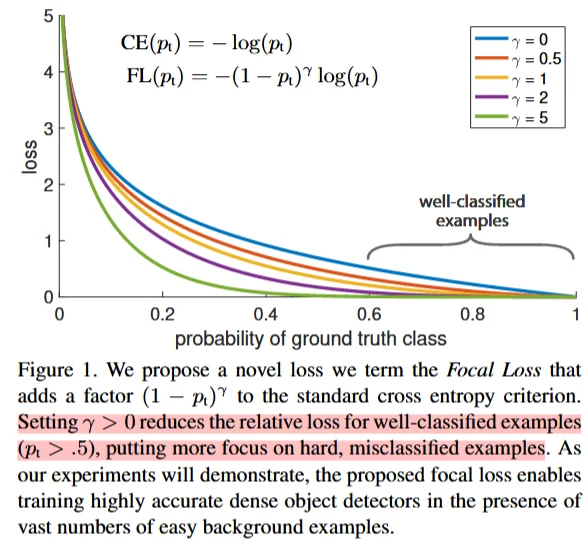
\(\gamma\):調節因子,用于控制對易分類樣本的懲罰程度。它是一個非負實數,通常設置為大于 0 的值。當\(\gamma\)>0 時,隨著\(p_t\)的增加,\((1-p_t)^{\gamma}\)的值會迅速減小,從而降低易分類樣本的損失值。這樣可以使得模型更加關注那些難以分類的樣本。(換言之,如果樣本里面大部分都是A那么計算得到 \(p_t\)也就會越大,那么可以增加 \(\gamma\)值來減小這部分值對于損失值的影響)
\(\alpha\): 平衡因子,用于調整正類和負類之間的權重。它是一個可調參數,通常設置為\(\alpha\)對于正類和 1?\(\alpha\)對于負類。當數據集中正負樣本數量不均衡時,可以通過調整\(\alpha\)來平衡兩類樣本的貢獻。例如,在一個正負樣本比例為 1:9 的數據集中,可以將\(\alpha\)設置為 0.9,以增加正類樣本的權重(一般而言對于這個參數直接使用我的標簽權重即可)
import torch
import torch.nn as nn
import torch.nn.functional as F
class FocalLoss(nn.Module):
"""Focal Loss implementation."""
def __init__(self, gamma=1.5, alpha=0.25):
super().__init__()
self.gamma = gamma
self.alpha = alpha
def forward(self, pred, label, mask_labels=None):
"""Calculates focal loss with optional mask_labels."""
loss = F.binary_cross_entropy_with_logits(pred, label, reduction='none')
pred_prob = pred.sigmoid()
p_t = label * pred_prob + (1 - label) * (1 - pred_prob)
loss *= (1.0 - p_t) ** self.gamma
if self.alpha > 0:
loss *= label * self.alpha + (1 - label) * (1 - self.alpha)
if mask_labels is not None:
loss *= mask_labels.float()
return loss.sum() / mask_labels.sum()
return loss.mean()
if __name__ == '__main__':
h, w = 500, 500
labels_parent = torch.randint(0, 2, (h, w), dtype=torch.float32)
tmp_labels = torch.zeros(1000, 1000)
tmp_labels[:h, :w] = labels_parent
tmp_labels_mask = torch.zeros(1000, 1000)
tmp_labels_mask[:h, :w] = 1
pred = torch.randn(1, 1000, 1000)
focal_loss = FocalLoss()
loss = focal_loss(pred, tmp_labels.unsqueeze(0), tmp_labels_mask)
print(loss)
對于 FocalLoss另外一個改進為:CB Loss用于改進樣本分布不均衡問題:
L1 loss
L1 loss:算預測值與真實值之間的絕對差值來衡量模型的預測誤差,公式為:
Huber Loss
Huber Loss用于回歸任務的損失函數,它結合了均方誤差(MSE)和絕對誤差(MAE)的優點,可以減少對異常值(outliers)的敏感性,同時保持較好的梯度性質
參考
1、https://pytorch.org/docs/stable/generated/torch.nn.CrossEntropyLoss.html
2、https://pytorch.org/docs/stable/generated/torch.nn.L1Loss.html#torch.nn.L1Loss
3、Focal Loss for Dense Object Detection
4、https://blog.csdn.net/zhang2010hao/article/details/84559971
5、https://openaccess.thecvf.com/content_CVPR_2019/papers/Cui_Class-Balanced_Loss_Based_on_Effective_Number_of_Samples_CVPR_2019_paper.pdf

 浙公網安備 33010602011771號
浙公網安備 33010602011771號