
深入淺出了解生成模型-6:常用基座模型與 Adapters等解析
更加好的排版:https://www.big-yellow-j.top/posts/2025/07/06/DFBaseModel.html
基座擴散模型
主要介紹基于Unet以及基于Dit框架的基座擴散模型以及部分GAN和VAE模型,其中SD迭代版本挺多的(從1.2到3.5)因此本文主要重點介紹SD 1.5以及SDXL兩個基座模型,以及兩者之間的對比差異,除此之外還有許多閉源的擴散模型比如說Imagen、DALE等。對于Dit基座模型主要介紹:Hunyuan-DiT、FLUX.1等。對于各類模型評分網站(模型評分仁者見仁智者見智,特別是此類生成模型視覺圖像生成是一個很主觀的過程,同一張圖片不同人視覺感官都是不同的):https://lmarena.ai/leaderboard
SDv1.5 vs SDXL[1]
SDv1.5: https://huggingface.co/stable-diffusion-v1-5/stable-diffusion-v1-5
SDXL:https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0
兩者模型詳細的模型結構:SDv1.5--SDXL模型結構圖,其中具體模型參數的對比如下:
1、CLIP編碼器區別:
在SD1.5中選擇的是CLIP-ViT/L(得到的維度為:768)而在SDXL中選擇的是兩個CLIP文本編碼器:OpenCLIP-ViT/G(得到的維度為:1280)以及CLIP-ViT/L(得到維度為:768)在代碼中對于兩個文本通過編碼器處理之后SDXL直接通過cat方式拼接:prompt_embeds = torch.concat(prompt_embeds_list, dim=-1) 也就是說最后得到的維度為:[..,..,1280+768]。最后效果很明顯:SDXL對于文本的理解能力大于SD1.5
2、圖像輸出維度區別:
再SD1.5中的默認輸出是:512x512而再SDXL中的默認輸出是:1024x1024,如果希望將SD1.5生成的圖像處理為1024x1024可以直接通過超分算法來進行處理,除此之外在SDXL中還會使用一個refiner模型(和Unet的結構相似)來強化base模型(Unet)生成的效果。
3、SDXL論文中的技術細節:
- 1、圖像分辨率優化策略。
數據集中圖像的尺寸圖像利用率問題(選擇512x512舍棄256x256就會導致圖像大量被舍棄)如果通過超分辨率算法將圖像就行擴展會放大偽影,這些偽影可能會泄漏到最終的模型輸出中,例如,導致樣本模糊。(The second method, on the other hand, usually introduces upscaling artifacts which may leak into the final model outputs, causing, for example, blurry samples.)作者做法是:訓練階段直接將原始圖像的分辨率 \(c=(h_{org},w_{org})\)作為一個條件,通過傅里葉特征編碼而后加入到time embedding中,推理階段直接將分辨率作為一個條件就行嵌入,進而實現:當輸入低分辨率條件時,生成的圖像較模糊;在不斷增大分辨率條件時,生成的圖像質量不斷提升。

- 2、圖像裁剪優化策略
直接統一采樣裁剪坐標top和cleft(分別指定從左上角沿高度和寬度軸裁剪的像素數量的整數),并通過傅里葉特征嵌入將它們作為調節參數輸入模型,類似于上面描述的尺寸調節。第1,2點代碼中的處理方式為:
def _get_add_time_ids(
self, original_size, crops_coords_top_left, target_size, dtype, text_encoder_projection_dim=None
):
add_time_ids = list(original_size + crops_coords_top_left + target_size)
passed_add_embed_dim = (
self.unet.config.addition_time_embed_dim * len(add_time_ids) + text_encoder_projection_dim
)
expected_add_embed_dim = self.unet.add_embedding.linear_1.in_features
...
add_time_ids = torch.tensor([add_time_ids], dtype=dtype)
return add_time_ids
推薦閱讀:
1、SDv1.5-SDXL-SD3生成效果對比
Imagen
https://imagen.research.google/
https://deepmind.google/models/imagen/
非官方實現:https://github.com/lucidrains/imagen-pytorch
類似Github,通過3階段生成:https://github.com/deep-floyd/IF
Imagen[2]論文中主要提出:1、純文本語料庫上預訓練的通用大型語言模型(例如T5、CLIP、BERT等)在編碼圖像合成的文本方面非常有效:在Imagen中增加語言模型的大小比增加圖像擴散模型的大小更能提高樣本保真度和Imagetext對齊。

2、通過提高classifier-free guidance weight(\(\epsilon(z,c)=w\epsilon(z,c)+ (1-w)\epsilon(z)\) 也就是其中的參數 \(w\))可以提高image-text之間的對齊,但會損害圖像逼真度,產生高度飽和不自然的圖像(論文里面給出的分析是:每個時間步中預測和正式的x都會限定在 \([-1,1]\)這個范圍但是較大的 \(w\)可能導致超出這個范圍),論文里面做法就是提出 動態調整方法:在每個采樣步驟中,我們將s設置為 \(x_0^t\)中的某個百分位絕對像素值,如果s>1,則我們將 \(x_0^t\)閾值設置為范圍 \([-s,s]\),然后除以s。

3、和上面SD模型差異比較大的一點就是,在imagen中直接使用多階段生成策略,模型先生成64x64圖像再去通過超分辨率擴散模型去生成256x256以及1024x1024的圖像,在此過程中作者提到使用noise conditioning augmentation(NCA)策略(對輸入的文本編碼后再去添加隨機噪聲)

Dit

Dit[3]模型結構上,1、模型輸入,將輸入的image/latent切分為不同patch而后去對不同編碼后的patch上去添加位置編碼(直接使用的sin-cos位置編碼),2、時間步以及條件編碼,對于時間步t以及條件c的編碼而后將兩部分編碼后的內容進行相加,在TimestepEmbedder上處理方式是:直接通過正弦時間步嵌入方式而后將編碼后的內容通過兩層liner處理;在LabelEmbedder處理方式上就比較簡單直接通過nn.Embedding進行編碼處理。3、使用Adaptive layer norm(adaLN)block以及adaZero-Block(對有些參數初始化為0,就和lora中一樣初始化AB為0,為了保證后續模型訓練過程中的穩定)
在layernorm中一般歸一化處理方式為:\(\text{Norm}(x)=\gamma \frac{x-\mu}{\sqrt{\sigma^2+ \epsilon}}+\beta\) 其中有兩個參數 \(\gamma\) 和 \(\beta\) 是固定的可學習參數(比如說直接通過
nn.Parameter進行創建),在模型初始化時創建,并在訓練過程中通過梯度下降優化。但是在 adaLN中則是直接通過 \(\text{Norm}(x)=\gamma(c) \frac{x-\mu}{\sqrt{\sigma^2+ \epsilon}}+\beta(c)\) 通過輸入的條件c進行學習的
總結Dit訓練過程:首先將圖片通過VAE進行編碼,而后將編碼后的內容patch化然后輸入到Ditblock(就是通過一些Attention結構進行堆疊)中去預測模型的噪聲
Hunyuan-DiT
騰訊的Hunyuan-DiT[4]模型整體結構

整體框架不是很復雜,1、文本編碼上直接通過結合兩個編碼器:CLIP、T5;2、VAE則是直接使用的SD1.5的;3、引入2維的旋轉位置編碼;4、在Dit結構上(圖片VAE壓縮而后去切分成不同patch),使用的是堆疊的注意力模塊(在SD1.5中也是這種結構)self-attention+cross-attention(此部分輸入文本)。論文里面做了改進措施:1、借鑒之前處理,計算attention之前首先進行norm處理(也就是將norm拿到attention前面)。
簡短了解一下模型是如何做數據的:

PixArt
華為諾亞方舟實驗室提出的 \(\text{PixArt}-\alpha\)模型整體框架如下:

相比較Dit模型論文里面主要進行的改進如下:
1、Cross-Attention layer,在DiT block中加入了一個多頭交叉注意力層,它位于自注意力層(上圖中的Multi-Head Self
-Attention)和前饋層(Pointwise Feedforward)之間,使模型能夠靈活地引入文本嵌入條件。此外,為了利用預訓練權重,將交叉注意力層中的輸出投影層初始化為零,作為恒等映射,保留了輸入以供后續層使用。
2、AdaLN-single,在Dit中的adaptive normalization layers(adaLN)中部分參數(27%)沒有起作用(在文生圖任務中)將其替換為adaLN-single
SD3、FLUX.1、FLUX1.1
FLUX模型商業不開源并且模型的綜合表現上一般而言flux會比較好(模型生成效果對比:??)
SD3的diffusers官方文檔:StableDiffusion3Pipeline
https://zhouyifan.net/2024/09/03/20240809-flux1/
SD3[5]、FLUX對于這幾組模型的前世今生不做介紹,主要了解其模型結構以及論文里面所涉及到到的一些知識點。首先介紹SD3模型在模型改進上[6]:1、改變訓練時噪聲采樣方法;2、將一維位置編碼改成二維位置編碼;3、提升 VAE 隱空間通道數(作者實驗發現最開始VAE會將模型下采樣8倍數并且處理通道為4的空間,也就是說 \(512 \times 512 \times 3 \rightarrow 64\times 64 \times 4\),不過在 SD3中將通道數由4改為16);4、對注意力 QK 做歸一化以確保高分辨率下訓練穩定。
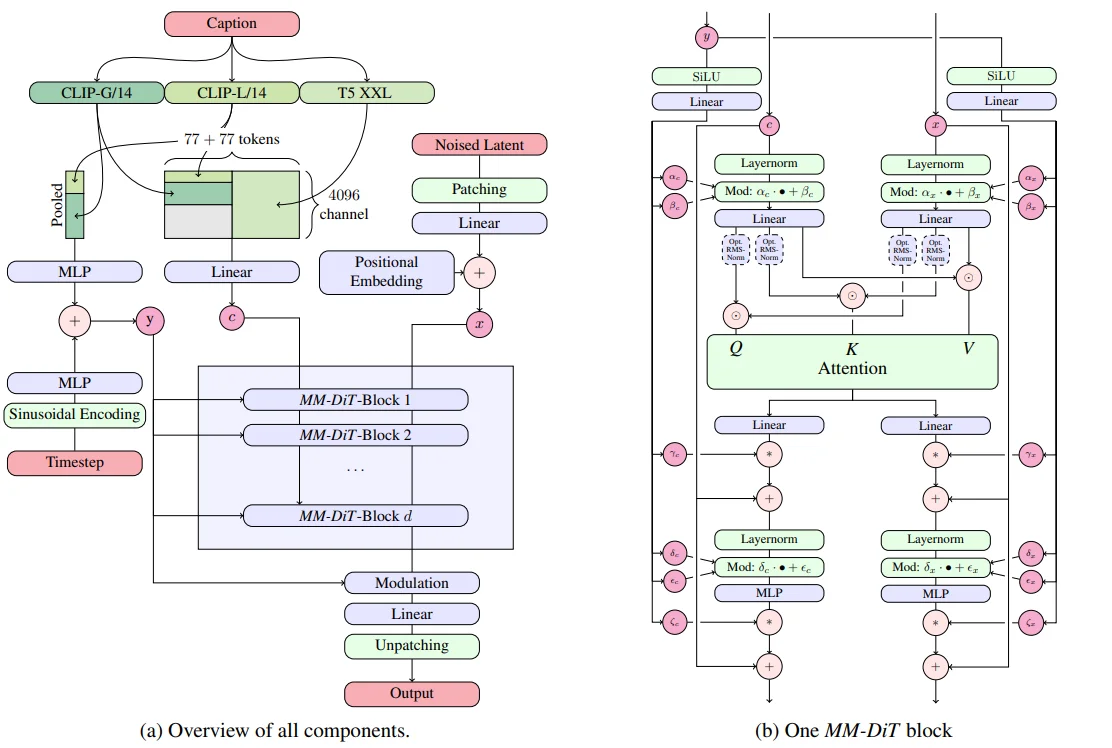
其中SD3模型的整體框架如上所述:
1、文本編碼器處理(代碼),在text encoder上SD3使用三個文本編碼器:clip-vit-large-patch14、 laion/CLIP-ViT-bigG-14-laion2B-39B-b160k 、 t5-v1_1-xxl ,對于這3個文本編碼器對于文本的處理過程為:就像SDXL中一樣首先3個編碼器分別都去對文本進行編碼,首先對于兩個CLIP的文本編碼處理過程為直接通過CLIP進行 prompt_embeds = text_encoder(text_input_ids.to(device)...) 而后去選擇 prompt_embeds.hidden_states[-(clip_skip + 2)](默認條件下 clip_skip=None也就是直接選擇倒數第二層)那么最后得到文本編碼的維度為:torch.Size([1, 77, 768]) torch.Size([1, 77, 1280]) 而T5的encoder就比較檢查直接通過encoder進行編碼,那么其編碼維度為:torch.Size([1, 256, 4096]),這樣一來就會得到3組的文編碼,對于CLIP的編碼結果直接通過clip_prompt_embeds=torch.cat([prompt_embed, prompt_2_embed], dim=-1) 即可,在將得到后的 clip_prompt_embeds結果再去和T5的編碼結果進行拼接之前會首先 clip_prompt_embeds=torch.nn.functional.pad(clip_prompt_embeds, (0, t5_prompt_embed.shape[-1] - clip_prompt_embeds.shape[-1])) 而后將T5的文本內容和 clip_prompt_embeds進行合并 prompt_embeds = torch.cat([clip_prompt_embeds, t5_prompt_embed], dim=-2)。由于使用T5模型導致模型的參數比較大進導致模型的顯存占用過大(2080Ti等GPU上輕量化的部署推理SD 3模型,可以只使用CLIP ViT-L + OpenCLIP ViT-bigG的特征,此時需要將T5-XXL的特征設置為zero(不加載)[7]),選擇不去使用T5模型會對模型對于文本的理解能力有所降低。

SD3使用T5-XXL模型。這使得以少于24GB的VRAM在GPU上運行模型,即使使用FP16精度。因此如果需要使用就需要:1、將部分模型下放到CPU上;2、直接取消T5的使用(
StableDiffusion3Pipeline.from_pretrained("stabilityai/stable-diffusion-3-medium-diffusers",text_encoder_3=None,tokenizer_3=None,torch_dtype=torch.float16))。
文本編碼過程:1、CLIP編碼分別得到:[1, 77, 768]和[1, 77, 1280];2、T5編碼得到:[1, 256, 4096];3、CLIP文本編碼拼接:[1, 77, 2048]在去將其通過pad填充到和T5一致得到最后CLIP編碼器維度為:[1, 77, 4096];4、最后文本編碼維度:[1, 333, 4096]
2、Flow Matching模式(原理);
3、MM-Dit模型架構(代碼):觀察上面過程,擴散模型輸入無非就是3個內容:1、時間步(\(y\));2、加噪處理的圖像(\(x\));3、文本編碼(\(c\))。首先對于 時間步而言處理過程為:直接通過 Sin位置編碼然后去和CLIP(兩個合并的)進行組合即可對于另外兩個部分直接通過代碼進行理解:
def forward(
self,
hidden_states: torch.Tensor, # 加噪聲的圖片 (batch size, channel, height, width)
encoder_hidden_states: torch.Tensor = None, # 條件編碼比如說:文本prompt (batch size, sequence_len, embed_dims)
pooled_projections: torch.Tensor = None, # 池化后的條件編碼 (batch size, embed_dims)
timestep: torch.LongTensor = None, # 時間步編碼
block_controlnet_hidden_states: List = None,
joint_attention_kwargs: Optional[Dict[str, Any]] = None,
return_dict: bool = True,
skip_layers: Optional[List[int]] = None,
) -> Union[torch.Tensor, Transformer2DModelOutput]:
...
height, width = hidden_states.shape[-2:]
# Step-1
hidden_states = self.pos_embed(hidden_states) # 直接使用 2D的位置編碼
temb = self.time_text_embed(timestep, pooled_projections)
encoder_hidden_states = self.context_embedder(encoder_hidden_states) # 一層線性映射
...
# Step-2
for index_block, block in enumerate(self.transformer_blocks):
is_skip = True if skip_layers is not None and index_block in skip_layers else False
if torch.is_grad_enabled() and self.gradient_checkpointing and not is_skip:
...
elif not is_skip:
encoder_hidden_states, hidden_states = block(
hidden_states=hidden_states,
encoder_hidden_states=encoder_hidden_states,
temb=temb,
joint_attention_kwargs=joint_attention_kwargs,
)
...
# Step-3
hidden_states = self.norm_out(hidden_states, temb)
hidden_states = self.proj_out(hidden_states)
patch_size = self.config.patch_size
height = height // patch_size
width = width // patch_size
hidden_states = hidden_states.reshape(
shape=(hidden_states.shape[0], height, width, patch_size, patch_size, self.out_channels)
)
hidden_states = torch.einsum("nhwpqc->nchpwq", hidden_states)
output = hidden_states.reshape(
shape=(hidden_states.shape[0], self.out_channels, height * patch_size, width * patch_size)
)
...
if not return_dict:
return (output,)
return Transformer2DModelOutput(sample=output)
Step-1:首先去將圖像 \(x\)使用2D 正弦-余弦位置編碼進行處理,對于時間步直接sin位置編碼,對于條件(文本prompt等)直接通過一層線性編碼處理。
Step-2:然后就是直接去計算Attention:encoder_hidden_states, hidden_states = block(hidden_states=hidden_states,encoder_hidden_states=encoder_hidden_states,temb=temb,joint_attention_kwargs=joint_attention_kwargs,),對于這個block的設計過程為:
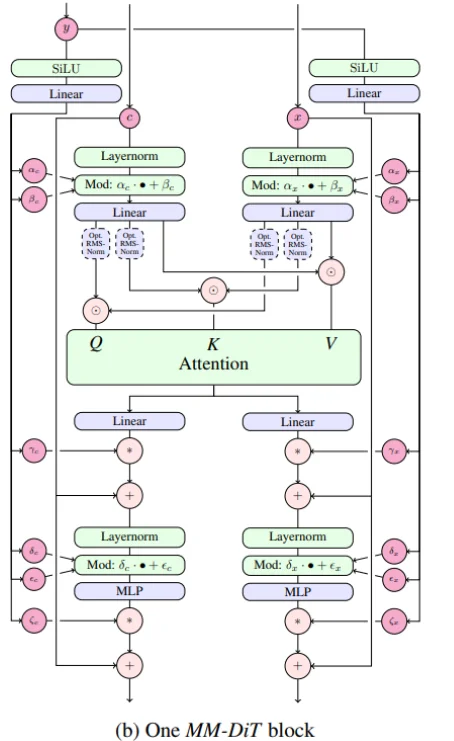
def forward(
self,
hidden_states: torch.FloatTensor,
encoder_hidden_states: torch.FloatTensor,
temb: torch.FloatTensor,
joint_attention_kwargs: Optional[Dict[str, Any]] = None,
):
joint_attention_kwargs = joint_attention_kwargs or {}
# Aeetntion Step-1
if self.use_dual_attention:
norm_hidden_states, gate_msa, shift_mlp, scale_mlp, gate_mlp, norm_hidden_states2, gate_msa2 = self.norm1(
hidden_states, emb=temb
)
else:
...
if self.context_pre_only:
...
else:
norm_encoder_hidden_states, c_gate_msa, c_shift_mlp, c_scale_mlp, c_gate_mlp = self.norm1_context(
encoder_hidden_states, emb=temb
)
# Attention Step-2
attn_output, context_attn_output = self.attn(
hidden_states=norm_hidden_states,
encoder_hidden_states=norm_encoder_hidden_states,
**joint_attention_kwargs,
)
attn_output = gate_msa.unsqueeze(1) * attn_output
hidden_states = hidden_states + attn_output
...
norm_hidden_states = self.norm2(hidden_states)
norm_hidden_states = norm_hidden_states * (1 + scale_mlp[:, None]) + shift_mlp[:, None]
if self._chunk_size is not None:
...
else:
ff_output = self.ff(norm_hidden_states)
ff_output = gate_mlp.unsqueeze(1) * ff_output
hidden_states = hidden_states + ff_output
if self.context_pre_only:
...
return encoder_hidden_states, hidden_states
計算注意力過程中,首先 Attention Step-1:正則化處理(正如上面Dit中的一樣將條件拆分為幾個參數,觀察SD3圖中的MMDit設計,會將 加噪聲處理的圖片 和 條件編碼都去(處理方式相同)通過 “正則化”,在SD3中處理方式為,直接shift_msa, scale_msa, gate_msa, shift_mlp, scale_mlp, gate_mlp, shift_msa2, scale_msa2, gate_msa2 = emb.chunk(9, dim=1) 拆分之后去通過 LayerNorm處理之后得到 norm_hidden_states 而后在去計算 norm_hidden_states * (1 + scale_msa[:, None]) + shift_msa[:, None])然后后面處理過程就比較簡單和上面的流程圖是一樣的。
這樣一來一個MMDit block就會返回兩部分結果 encoder_hidden_states, hidden_states(區別Dit之間在于,MMDit是將image和text兩種模態之間的信息進行融合二Dit只是使用到imgae一種模態)
Step-3就比較簡單就是一些norm等處理。
總的來說MMDiT Block 的輸入主要有三部分:時間步嵌入 \(y\):通過一個 MLP 投影,得到一組參數,用于調節 Block 內的 LayerNorm / Attention / MLP(類似 FiLM conditioning)。圖像 token \(x\):由加噪圖像 latent patch embedding 得到,并加上 2D 正弦余弦位置編碼。文本 token \(c\):來自文本編碼器的輸出,一般帶有 1D 位置編碼。Block 內部機制:將 \(x\) 和 \(c\) 拼接在一起,作為 Transformer 的輸入序列。在自注意力層中,\(x\) token 能和 \(c\) token 交互,從而實現 跨模態融合。\(y\)(timestep embedding)通過投影提供額外的條件控制。
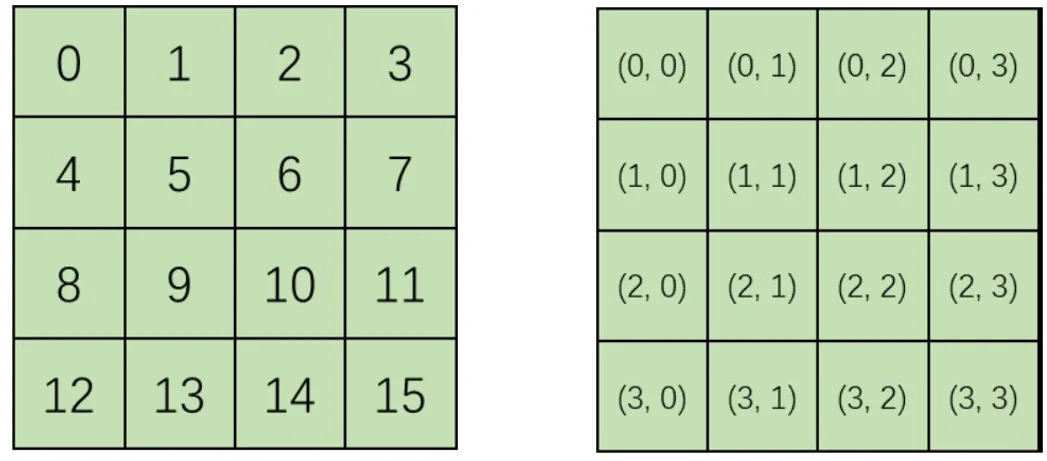
2D 正弦-余弦位置編碼
左側為一般的位置編碼方式,但是有一個缺點:生成的圖像的分辨率是無法修改的。比如對于上圖,假如采樣時輸入大小不是4x3,而是4x5,那么0號圖塊的下面就是5而不是4了,模型訓練時學習到的圖塊之間的位置關系全部亂套,因此就通過2D位置去代表每一塊的位置信息。
- FLUX模型而言其結構如下
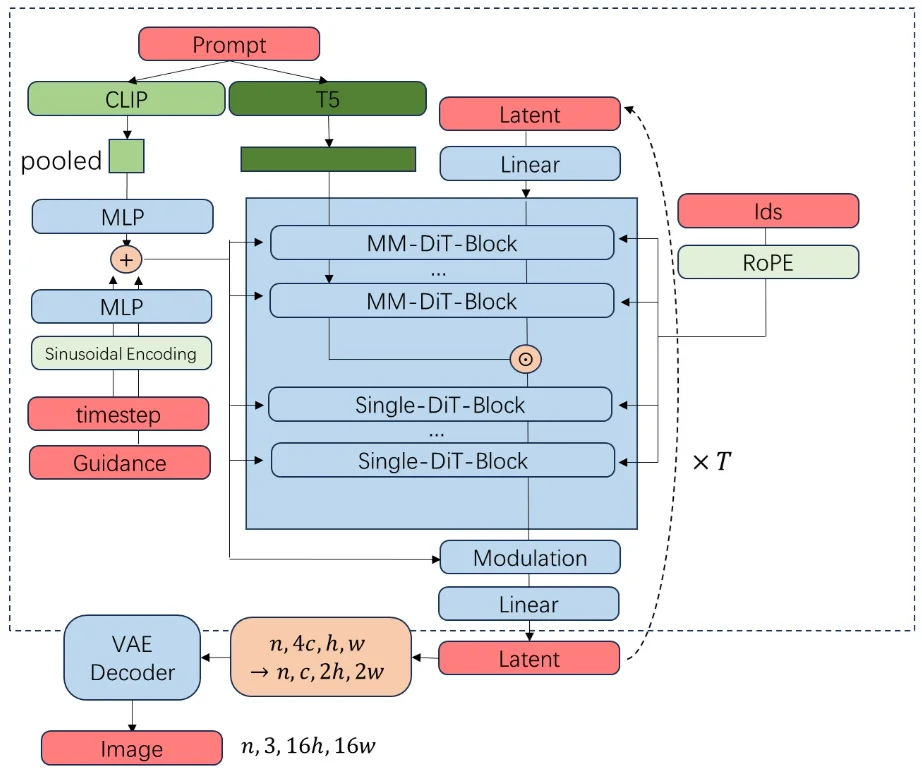
區別SD3模型在于,FLUX.1在文本編碼器選擇上只使用了2個編碼器(CLIPTextModel、T5EncoderModel)并且FLUX.1 VAE架構依然繼承了SD 3 VAE的8倍下采樣和輸入通道數(16)。在FLUX.1 VAE輸出Latent特征,并在Latent特征輸入擴散模型前,還進行了 _pack_latents操作,一下子將Latent特征通道數提高到64(16 -> 64),換句話說,FLUX.1系列的擴散模型部分輸入通道數為64,是SD 3的四倍。對于 _pack_latents做法是會將一個 \(2\times 2\)的像素去補充到通道中。
def _pack_latents(latents, batch_size, num_channels_latents, height, width):
latents = latents.view(batch_size, num_channels_latents, height // 2, 2, width // 2, 2)
latents = latents.permute(0, 2, 4, 1, 3, 5)
latents = latents.reshape(batch_size, (height // 2) * (width // 2), num_channels_latents * 4)
return latents
除去改變text的編碼器數量以及VAE的通道數量之外,FLUX.1還做了如下的改進:FLUX.1 沒有做 Classifier-Free Guidance (CFG)(對于CFG一般做法就是直接去將“VAE壓縮的圖像信息變量復制兩倍” torch.cat([latents] * 2),文本就是直接將negative_prompt的編碼補充到文本編碼中 torch.cat([negative_prompt_embeds, prompt_embeds], dim=0))而是把指引強度 guidance 當成了一個和時刻 t 一樣的約束信息,傳入去噪模型 transformer 中。在transformer模型結構設計中,SD3是直接對圖像做圖塊化,再設置2D位置編碼 PatchEmbed,在FLUX.1中使用的是FluxPosEmbed(旋轉位置編碼)
# SD3
self.pos_embed = PatchEmbed(height=sample_size,width=sample_size,patch_size=patch_size,in_channels=in_channels,)
embed_dim=self.inner_dim,pos_embed_max_size=pos_embed_max_size, # hard-code for now.)
# FLUX.1
self.pos_embed = FluxPosEmbed(theta=10000, axes_dim=axes_dims_rope)
VAE基座模型
對于VAE模型在之前的博客有介紹過具體的原理,這里主要就是介紹幾個常見的VAE架構模型(使用過程中其實很少會去修改VAE架構,一般都是直接用SD自己使用的)所以就簡單對比一下不同的VAE模型在圖片重構上的表,主要是使用此huggingface上的進行比較(比較的數值越小越好,就數值而言 CogView4-6B效果最佳),下面結果為隨便挑選的一個圖片進行測試結果:
| 模型名稱 | 數值 | 時間(s) |
|---|---|---|
| stable-diffusion-v1-4 | 2,059 | 0.5908 |
| eq-vae-ema | 1,659 | 0.0831 |
| eq-sdxl-vae | 1,200 | 0.0102 |
| sd-vae-ft-mse | 1,204 | 0.0101 |
| sdxl-vae | 929 | 0.0105 |
| playground-v2.5 | 925 | 0.0096 |
| stable-diffusion-3-medium | 24 | 0.1027 |
| FLUX.1 | 18 | 0.0412 |
| CogView4-6B | 0 | 0.1265 |
| FLUX.1-Kontext | 18 | 0.0098 |
GAN基座模型
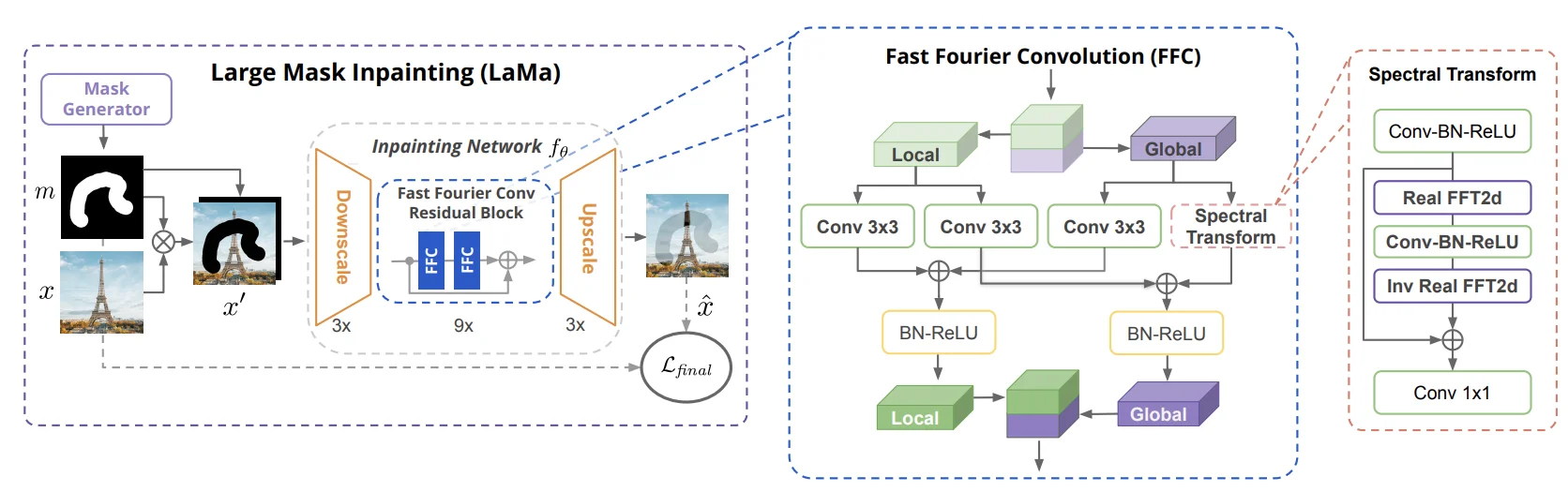
GAN模型個人在使用上用的不是特別多,因此主要介紹個人在實際使用過程中可能見到比較多的GAN模型。lama[8]模型、StyleGAN1-3模型
Qwen image
官方blog:https://qwenlm.github.io/zh/blog/qwen-image/
Qwen Image圖片編輯:https://huggingface.co/Qwen/Qwen-Image-Edit
Qwen Image:https://huggingface.co/Qwen/Qwen-Image
Qwen Image Lora微調8步生圖:https://huggingface.co/lightx2v/Qwen-Image-Lightning
Qwen Image圖片編輯int4量化版本:https://huggingface.co/nunchaku-tech/nunchaku-qwen-image,代碼
Qwen image[9]無論是多行文字、段落布局,還是中英文等不同語種,Qwen-Image都能以極高的保真度進行渲染,尤其在處理復雜的中文(logographic languages)方面,表現遠超現有模型(不過目前:2025.08.29模型全權重加載的話一般設備很難使用,不過又量化版本可以嘗試)模型整體結構:
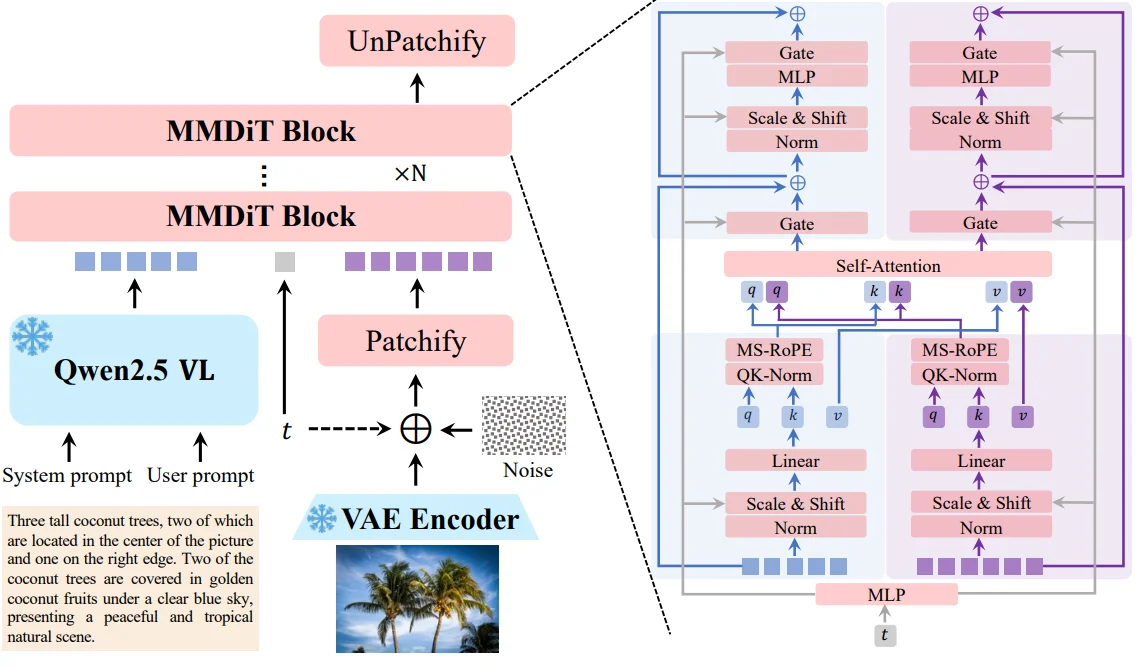
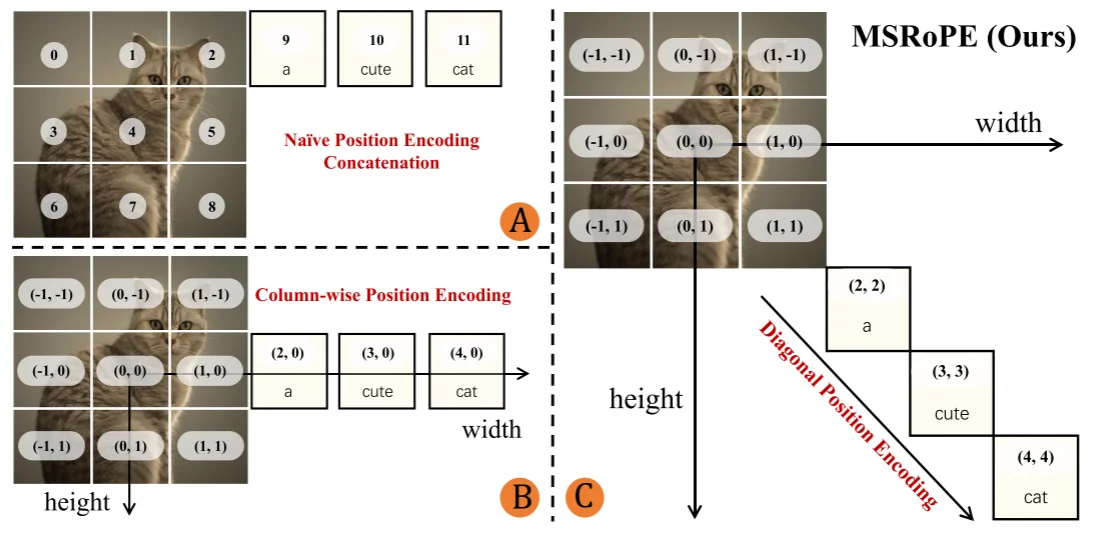
整體框架上還是MMDit結構和上面的SD3都是一致的,不過模型的改進在于:1、區別之前的都是使用CLIP模型去對齊圖片-文本之間信息,在Qwen Image中則是直接使用Qwen2.5-VL;2、對于VAE模型則是直接使用Wan-2.1-VAE(不過選擇凍結encoder部分只去訓練decoder部分);3、模型的結構還是使用MMDit結構,知識將位置編碼方式改為Multimodal Scalable RoPE (MSRoPE),位置編碼方式
大致框架了解之后細看他的數據是如何收集的以及后處理的:
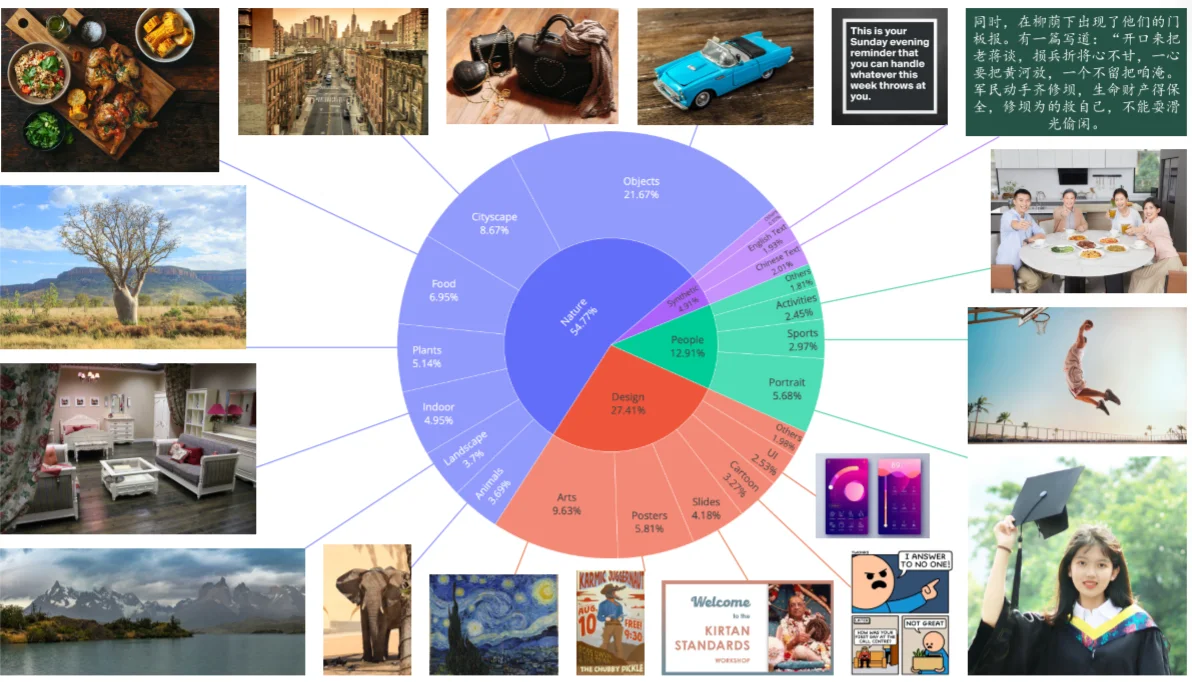
對于收集到數據之后,論文里面通過如下操作進行后處理:1、階段一過濾數據:模型預訓練是在256x256的圖片上進行訓練的,因此,過濾掉256x256以外的圖片還有一些低質量圖片等;2、階段二圖片質量強化:主要還是過濾一些低質量圖片如亮度紋理等;
不同模型參數對生成的影響
https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Features#stable-diffusion-20
- 參數
guidance_rescale對于生成的影響
引導擴散模型(如 Classifier-Free Guidance,CFG)中,用于調整文本條件對生成圖像的影響強度。它的核心作用是控制模型在生成過程中對文本提示的“服從程度”。公式上,CFG 調整預測噪聲的方式如下:
其中:1、\(\epsilon_{\text{cond}}\):基于文本條件預測的噪聲。2、\(\epsilon_{\text{uncond}}\):無條件(無文本提示)預測的噪聲。3、guidance_scale:決定條件噪聲相對于無條件噪聲的權重。得到最后測試結果如下(參數分別為[1.0, 3.0, 5.0, 7.5, 10.0, 15.0, 20.0],prompt = "A majestic lion standing on a mountain during golden hour, ultra-realistic, 8k", negative_prompt = "blurry, distorted, low quality"),容易發現數值越大文本對于圖像的影響也就越大。

其中代碼具體操作如下,從代碼也很容易發現上面計算公式中的 uncond代表的就是我的negative_prompt,也就是說CFG做的就是negative_prompt對生成的影響:
if self.do_classifier_free_guidance:
prompt_embeds = torch.cat([negative_prompt_embeds, prompt_embeds], dim=0)
add_text_embeds = torch.cat([negative_pooled_prompt_embeds, add_text_embeds], dim=0)
add_neg_time_ids = add_neg_time_ids.repeat(batch_size * num_images_per_prompt, 1)
add_time_ids = torch.cat([add_neg_time_ids, add_time_ids], dim=0)
prompt_embeds = prompt_embeds.to(device)
Adapters
https://huggingface.co/docs/diffusers/tutorials/using_peft_for_inference
此類方法是在完備的 DF 權重基礎上,額外添加一個“插件”,保持原有權重不變。我只需修改這個插件,就可以讓模型生成不同風格的圖像。可以理解為在原始模型之外新增一個“生成條件”,通過修改這一條件即可靈活控制模型生成各種風格或滿足不同需求的圖像。
ControlNet
https://github.com/lllyasviel/ControlNet
建議直接閱讀:https://github.com/lllyasviel/ControlNet/discussions/categories/announcements 來了解更加多細節

ControlNet[10]的處理思路就很簡單,再左圖中模型的處理過程就是直接通過:\(y=f(x;\theta)\)來生成圖像,但是在ControlNet里面會 將我們最開始的網絡結構復制 然后通過在其前后引入一個 zero-convolution 層來“指導”( \(Z\) )模型的輸出也就是說將上面的生成過程變為:\(y=f(x;\theta)+Z(f(x+Z(c;\theta_{z_1});\theta);\theta_{Z_2})\)。通過凍結最初的模型的權重保持不變,保留了Stable Diffusion模型原本的能力;與此同時,使用額外數據對“可訓練”副本進行微調,學習我們想要添加的條件。因此在最后我們的SD模型中就是如下一個結構:

在論文里面作者給出一個實際的測試效果可以很容易理解里面條件c(條件 ??就是提供給模型的顯式結構引導信息,用于在生成過程中精確控制圖像的空間結構或布局,一般來說可以是草圖、分割圖等)到底是一個什么東西,比如說就是直接給出一個“線稿”然后模型來輸出圖像。

補充-1:為什么使用上面這種結構
在github上作者討論了為什么要使用上面這種結構而非直接使用mlp等(作者給出了很多測試圖像),最后總結就是:這種結構好
補充-2:使用0卷積層會不會導致模型無法優化問題?
不會,因為對于神經網絡結構大多都是:\(y=wx+b\)計算梯度過程中即使 \(w=0\)但是里面的 \(x≠0\)模型的參數還是可以被優化的
ControlNet代碼操作
Code: https://github.com/shangxiaaabb/ProjectCode/tree/main/code/Python/DFModelCode/training_controlnet
首先,簡單了解一個ControlNet數據集格式,一般來說數據主要是三部分組成:1、image(可以理解為生成的圖像);2、condiction_image(可以理解為輸入ControlNet里面的條件 \(c\));3、text。比如說以raulc0399/open_pose_controlnet為例

模型加載,一般來說擴散模型就只需要加載如下幾個:DDPMScheduler、AutoencoderKL(vae模型)、UNet2DConditionModel(不一定加載條件Unet模型),除此之外在ControlNet中還需要加載一個ControlNetModel。對于ControlNetModel中代碼大致結構為,代碼中通過self.controlnet_down_blocks來存儲ControlNet的下采樣模塊(初始化為0的卷積層)。self.down_blocks用來存儲ControlNet中復制的Unet的下采樣層。在forward中對于輸入的樣本(sample)首先通過 self.down_blocks逐層處理疊加到 down_block_res_samples中,而后就是直接將得到結果再去通過 self.controlnet_down_blocks每層進行處理,最后返回下采樣的每層結果以及中間層處理結果:down_block_res_samples,mid_block_res_sample
class ControlNetModel(ModelMixin, ConfigMixin, FromOriginalModelMixin):
@register_to_config
def __init__(...):
...
self.down_blocks = nn.ModuleList([])
self.controlnet_down_blocks = nn.ModuleList([])
# 封裝下采樣過程(對應上面模型右側結構)
controlnet_block = nn.Conv2d(output_channel, output_channel, kernel_size=1)
controlnet_block = zero_module(controlnet_block)
self.controlnet_down_blocks.append(controlnet_block)
for i, down_block_type in enumerate(down_block_types):
# down_block_types就是Unet里面下采樣的每一個模塊比如說:CrossAttnDownBlock2D
...
down_block = get_down_block(down_block_type) # 通過 get_down_block 獲取uet下采樣的模塊
self.down_blocks.append(down_block)
for _ in range(layers_per_block):
controlnet_block = nn.Conv2d(output_channel, output_channel, kernel_size=1)
controlnet_block = zero_module(controlnet_block)
self.controlnet_down_blocks.append(controlnet_block)
@classmethod
def from_unet(cls, unet,...):
...
# 通過cls實例化的類本身ControlNetModel
controlnet = cls(...)
if load_weights_from_unet:
# 將各類權重加載到 controlnet 中
controlnet.conv_in.load_state_dict(unet.conv_in.state_dict())
controlnet.time_proj.load_state_dict(unet.time_proj.state_dict())
...
return controlnet
def forward(...):
...
# 時間編碼
t_emb = self.time_proj(timesteps)
emb = self.time_embedding(t_emb, timestep_cond)
if self.class_embedding is not None:
...
class_emb = self.class_embedding(class_labels).to(dtype=self.dtype)
emb = emb + class_emb
# 對條件進行編碼
if self.config.addition_embed_type is not None:
if self.config.addition_embed_type == "text":
aug_emb = self.add_embedding(encoder_hidden_states)
elif self.config.addition_embed_type == "text_time":
time_ids = added_cond_kwargs.get("time_ids")
time_embeds = self.add_time_proj(time_ids.flatten())
time_embeds = time_embeds.reshape((text_embeds.shape[0], -1))
add_embeds = torch.concat([text_embeds, time_embeds], dim=-1)
add_embeds = add_embeds.to(emb.dtype)
aug_emb = self.add_embedding(add_embeds)
emb = emb + aug_emb if aug_emb is not None else emb
sample = self.conv_in(sample)
controlnet_cond = self.controlnet_cond_embedding(controlnet_cond)
sample = sample + controlnet_cond
# 下采樣處理
down_block_res_samples = (sample,)
for downsample_block in self.down_blocks:
if ...
...
else:
sample, res_samples = downsample_block(hidden_states=sample, temb=emb)
down_block_res_samples += res_samples
# 中間層處理
...
# 將輸出后的內容去和0卷積進行疊加
controlnet_down_block_res_samples = ()
for down_block_res_sample, controlnet_block in zip(down_block_res_samples, self.controlnet_down_blocks):
down_block_res_sample = controlnet_block(down_block_res_sample)
controlnet_down_block_res_samples = controlnet_down_block_res_samples + (down_block_res_sample,)
...
if not return_dict:
return (down_block_res_samples, mid_block_res_sample)
...
模型訓練,訓練過程和DF訓練差異不大。將圖像通過VAE處理、產生噪聲、時間步、將噪聲添加到(VAE處理之后的)圖像中,而后通過 controlnet得到每層下采樣的結果以及中間層結果:down_block_res_samples, mid_block_res_sample = controlnet(...)而后將這兩部分結果再去通過unet處理
model_pred = unet(
noisy_latents,
timesteps,
encoder_hidden_states=encoder_hidden_states,
down_block_additional_residuals=[
sample.to(dtype=weight_dtype) for sample in down_block_res_samples
],
mid_block_additional_residual=mid_block_res_sample.to(dtype=weight_dtype),
return_dict=False,
)[0]
后續就是計算loss等處理。模型驗證,直接就是使用StableDiffusionControlNetPipeline來處理了。最后隨機測試的部分例子(controlnet微調效果不是很好):

T2I-Adapter

T2I[11]的處理思路也比較簡單(T2I-Adap 4 ter Details里面其實就寫的很明白了),對于輸入的條件圖片(比如說邊緣圖像):512x512,首先通過 pixel unshuffle進行下采樣將圖像分辨率改為:64x64而后通過一層卷積+兩層殘差連接,輸出得到特征 \(F_c\)之后將其與對應的encoder結構進行相加:\(F_{enc}+ F_c\),當然T2I也支持多個條件(直接通過加權組合就行)
DreamBooth
https://huggingface.co/docs/diffusers/v0.34.0/using-diffusers/dreambooth
DreamBooth 針對的使用場景是,期望生成同一個主體的多張不同圖像, 就像照相館一樣,可以為同一個人或者物體照多張不同背景、不同姿態、不同服裝的照片(和ControlNet不同去添加模型結構,僅僅是在文本 Prompt)。在論文[12]里面主要出發點就是:1、解決language drif(語言偏離問題):指的是模型通過后訓練(微調等處理之后)模型喪失了對某些語義特征的感知,就比如說擴散模型里面,模型通過不斷微調可能就不知道“狗”是什么從而導致模型生成錯誤。2、高效的生成需要的對象,不會產生:生成錯誤、細節丟失問題,比如說下面圖像中的問題:

為了實現圖像的“高效遷移”,作者直接將圖像(比如說我們需要風格化的圖片)作為一個特殊的標記,也就是論文里面提到的 a [identifier] [class noun](其中class noun為類別比如所狗,identifier就是一個特殊的標記),在prompt中加入類別,通過利用預訓練模型中關于該類別物品的先驗知識,并將先驗知識與特殊標記符相關信息進行融合,這樣就可以在不同場景下生成不同姿勢的目標物體。就比如下面的 fine-tuning過程通過幾張圖片讓模型學習到 特殊的狗,然后再推理階段模型可以利用這個 特殊的狗去生成新的動作。換言之就是(以下面實際DreamBooth代碼為例):首先通過幾張 獅子狗 圖片讓模型知道 獅子狗張什么樣子,然后再去生成 獅子狗的不同的動作。

在論文里面作者設計如下的Class-specific Prior Preservation Loss(參考stackexchange)[13]:
上面損失函數中后面一部分就是我們的先驗損失,比如說\(c_{pr}\)就是對 "a dog"進行編碼然后計算生成損失。在代碼中:
if args.with_prior_preservation:
model_pred, model_pred_prior = torch.chunk(model_pred, 2, dim=0)
target, target_prior = torch.chunk(target, 2, dim=0)
# Compute instance loss
loss = F.mse_loss(model_pred.float(), target.float(), reduction="mean")
# Compute prior loss
prior_loss = F.mse_loss(model_pred_prior.float(), target_prior.float(), reduction="mean")
# Add the prior loss to the instance loss.
loss = loss + args.prior_loss_weight * prior_loss
else:
loss = F.mse_loss(model_pred.float(), target.float(), reduction="mean")
DreamBooth代碼操作
代碼:https://github.com/shangxiaaabb/ProjectCode/tree/main/code/Python/DFModelCode/training_dreambooth_lora/
權重:https://www.modelscope.cn/models/bigyellowjie/SDXL-DreamBooth-LOL/files
在介紹DreamBooth代碼之前,簡單回顧DreamBooth原理,我希望我的模型去學習一種畫風那么我就需要準備樣本圖片(如3-5張圖片)這幾張圖片就是專門的模型需要學習的,但是為了防止模型過擬合(模型只學習了我的圖片內容,但是對一些細節丟掉了,比如說我提供的5張油畫,模型就學會了我的油畫畫風但是為了防止模型對更加多的油畫細節忘記了,那么我就準備num_epochs * num_samples 張油畫類型圖片然后通過計算 Class-specific Prior Preservation Loss)需要準備 類型圖片來計算Class-specific Prior Preservation Loss。代碼處理(SDXL+Lora):
DreamBooth中數據處理過程:結合上面描述我需要準備兩部分數據集(如果需要計算Class-specific Prior Preservation Loss)分別為:instance_data_dir(與之對應的instance_prompt)以及 class_data_dir(與之對應的 class_prompt)而后需要做的就是將兩部分數據組合起來構成:
batch = {
"pixel_values": pixel_values,
"prompts": prompts,
"original_sizes": original_sizes,
"crop_top_lefts": crop_top_lefts,
}
模型訓練過程首先是lora處理模型:在基于transformer里面的模型很容易使用lora,比如說下面代碼使用lora包裹模型并且對模型權重進行保存:
from peft import LoraConfig
def get_lora_config(rank, dropout, use_dora, target_modules):
'''lora config'''
base_config = {
"r": rank,
"lora_alpha": rank,
"lora_dropout": dropout,
"init_lora_weights": "gaussian",
"target_modules": target_modules,
}
return LoraConfig(**base_config)
# 包裹lora模型權重
unet_target_modules = ["to_k", "to_q", "to_v", "to_out.0"]
unet_lora_config = get_lora_config(
rank= config.rank,
dropout= config.lora_dropout,
use_dora= config.use_dora,
target_modules= unet_target_modules,
)
unet.add_adapter(unet_lora_config)
一般的話考慮SD模型權重都比較大,而且我們使用lora微調模型沒必要對所有的模型權重進行存儲,那么一般都會定義一個hook來告訴模型那些參數需要保存、加載,這樣一來使用 accelerator.save_state(save_path) 就會先去使用 hook處理參數然后進行保存。:
def save_model_hook(models, weights, output_dir):
if accelerator.is_main_process:
unet_lora_layers_to_save = None
for model in models:
if isinstance(model, type(unwrap_model(unet))):
unet_lora_layers_to_save = convert_state_dict_to_diffusers(get_peft_model_state_dict(model))
...
weights.pop() # 去掉不需要保存的參數
StableDiffusionXLPipeline.save_lora_weights(
output_dir,
unet_lora_layers= unet_lora_layers_to_save,
...
)
def load_model_hook(models, input_dir):
unet_ = None
while len(models) > 0:
model = models.pop()
if isinstance(model, type(unwrap_model(unet))):
unet_ = model
lora_state_dict, network_alphas = StableDiffusionLoraLoaderMixin.lora_state_dict(input_dir)
unet_state_dict = {f"{k.replace('unet.', '')}": v for k, v in lora_state_dict.items() if k.startswith("unet.")}
unet_state_dict = convert_unet_state_dict_to_peft(unet_state_dict)
incompatible_keys = set_peft_model_state_dict(unet_, unet_state_dict, adapter_name="default")
...
accelerator.register_save_state_pre_hook(save_model_hook)
accelerator.register_load_state_pre_hook(load_model_hook)
其次模型訓練:就是常規的模型訓練(直接在樣本圖片:instance_data_dir以及樣本的prompt:instance_prompt上進行微調)然后計算loss即可,如果涉及到Class-specific Prior Preservation Loss(除了上面兩個組合還需要:class_data_dir以及 class_prompt)那么處理過程為(以SDXL為例),不過需要事先了解的是在計算這個loss之前會將兩個數據集以及prompt都組合到一起成為一個數據集(instance-image-prompt 以及 class-image-prompt之間是匹配的):
# 樣本內容編碼
instance_prompt_hidden_states, instance_pooled_prompt_embeds = compute_text_embeddings(config.instance_prompt, text_encoders, tokenizers)
# 類型圖片內容編碼
if config.with_prior_preservation:
class_prompt_hidden_states, class_pooled_prompt_embeds = compute_text_embeddings(config.class_prompt, text_encoders, tokenizers)
...
prompt_embeds = instance_prompt_hidden_states
unet_add_text_embeds = instance_pooled_prompt_embeds
if not config.with_prior_preservation:
prompt_embeds = torch.cat([prompt_embeds, class_prompt_hidden_states], dim=0)
unet_add_text_embeds = torch.cat([unet_add_text_embeds, class_pooled_prompt_embeds], dim=0)
...
model_pred = unet(...)
if config.with_prior_preservation:
model_pred, model_pred_prior = torch.chunk(model_pred, 2, dim=0)
target, target_prior = torch.chunk(target, 2, dim=0)
...
prior_loss = F.mse_loss(model_pred_prior.float(), target_prior.float(), reduction="mean")
...
loss = F.mse_loss(model_pred.float(), target.float(), reduction="mean")
...
loss = loss + config.prior_loss_weight * prior_loss
accelerator.backward(loss)
在這個里面之所以用 chunk是因為如果計算Class-specific Prior Preservation Loss里面的文本prompt是由兩部分拼接構成的torch.cat([prompt_embeds, class_prompt_hidden_states], dim=0)那么可以直接通過chunk來分離出兩部分(這個過程和使用參數guidance_rescale很相似)
最后測試的結果為(prompt: "A photo of Rengar the Pridestalker in a bucket",模型代碼以及權重下載):

總結
對于不同的擴散(基座)模型(SD1.5、SDXL、Imagen)等大部分都是采用Unet結構,當然也有采用Dit的,這兩個模型(SD1.5、SDXL)之間的差異主要在于后者會多一個clip編碼器再文本語義上比前者更加有優勢。對于adapter而言,可以直接理解為再SD的基礎上去使用“風格插件”,這個插件不去對SD模型進行訓練(從而實現對參數的減小),對于ControNet就是直接對Unet的下采樣所有的模塊(前后)都加一個zero-conv而后將結果再去嵌入到下采用中,而T2I-Adapter則是去對條件進行編碼而后嵌入到SD模型(上采用模塊)中。對于deramboth就是直接通過給定的樣本圖片去生“微調”模型,而后通過設計的Class-specific Prior Preservation Loss來確保所生成的樣本特里不會發生過擬合。

 浙公網安備 33010602011771號
浙公網安備 33010602011771號