
圖像擦除論文綜述-1:PixelHacker、PowerPanint等
更加好的排版:https://www.big-yellow-j.top/posts/2025/06/11/ImageEraser1.html
本文主要介紹幾篇圖像擦除論文模型:PixelHacker、PowerPanint等,并且實際測試模型的表現效果
PixelHacker
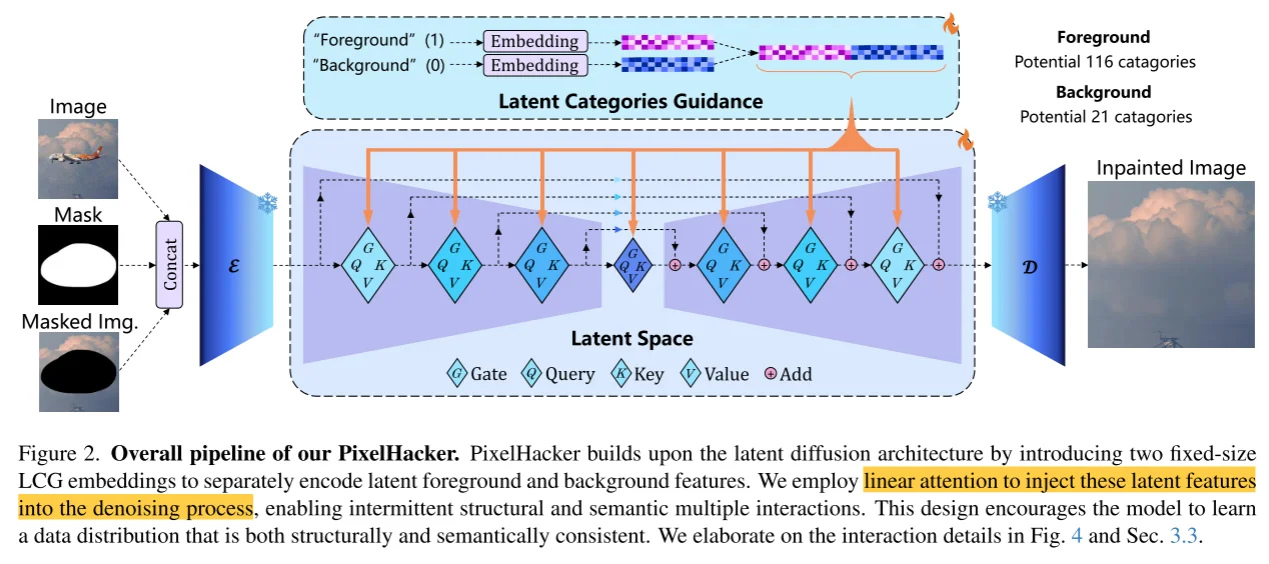
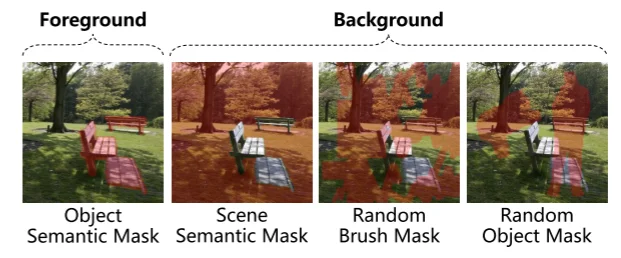
模型整體框架和Diffusion Model相似,輸入分為3部分:1、image;2、mask;3、mask image而后將這三部分進行拼接,然后通過VAE進行encoder,除此之外類似Diffusion Model中處理,將condition替換為mask內容(這部分作者分為兩類:1、foreground(116種類別);2、background(21種類別))作為condition(對于foreground直接通過編碼處理,對于background的3部分通過:\(M_{scene}+M_{rand}P_{rand}+M_{obj}P_{obj}\) 分別對于background的3部分)然后輸入到注意力計算中。
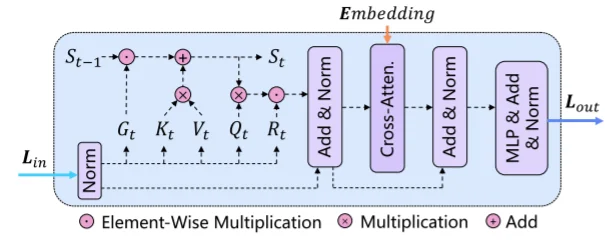
注意力計算過程,對于通過VAE編碼后的內容\(L_{in}\) 直接通過 \(LW\) 計算得到QKV,并且通過 2D遺忘矩陣 \(G_t\)計算過程為:
\(L_t\)計算過程:
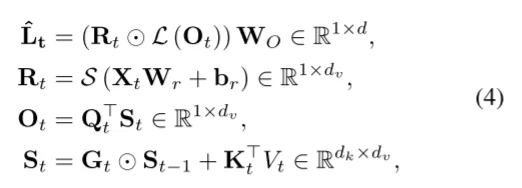
PixelHacker實際測試效果
| 圖像 | mask | 結果 | 問題 |
|---|---|---|---|
 |
 |
 |
背景文字細節丟失 |
 |
 |
 |
人物細節 |
|
 |
 |
生成錯誤 |
分析:只能生成較低分辨率圖像(512x512,Github),去除過程中對于復雜的圖像可能導致細節(背景中的文字、圖像任務)處理不好。
PowerPanint
A Task is Worth One Word: Learning with Task Prompts for High-Quality Versatile Image Inpainting
From: https://github.com/open-mmlab/PowerPaint
Modle:SD v1.5、CLIP

模型整體結構和DF模型相同,輸入模型內容為:噪聲的潛在分布、mask圖像(\(x \bigodot (1-m)\))、mask;在論文中將condition替換為4部分組合(微調兩部分:\(P_{obj}\) 以及 \(P_{ctxt}\)):1、\(P_{obj}\)
1、增強上下文的模型感知:使用隨機mask訓練模型并對其進行優化以重建原始圖像可獲得最佳效果,通過使用\(P_{ctxt}\)(可學習的)讓模型學會如何根據圖像的上下文信息來填充缺失的部分,而不是依賴于文本描述,優化過程為:
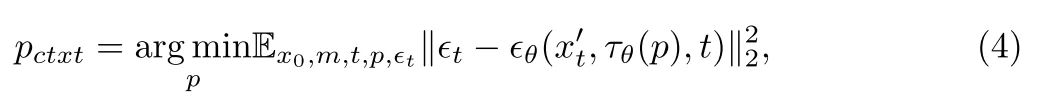
2、通過文本增強模型消除:通過使用\(P_{obj}\):訓練過程和上面公式相同,不過將識別得到的物體bbox作為圖像mask并且將 \(P_{obj}\)作為mask區域的文本描述,引導模型根據給定的文本描述生成對應的對象。
第1和第2點區別在于,第二點輸入有文本描述,而第一點就是可學習的文本
3、物品移除:使用移除過程中模型很容易進入一個“誤解”:模型是新生成一個內容貼在需要消除的內容位置而不是消除內容(比如下面結果),作者的做法是直接將上面兩個進行加權:
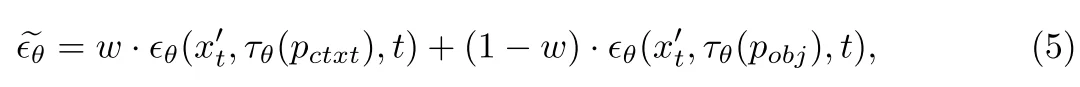
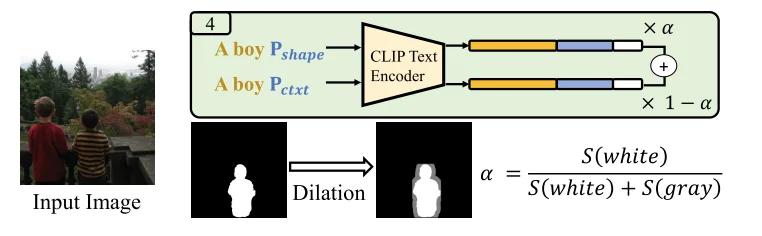
4、通過形狀增強模型消除:\(P_{shape}\):使用精確的對象分割mask和對象描述進行訓練,不過這樣會使得模型過擬合(輸入文本和選定的區域,可能模型只考慮選定區域內容生成),因此替換做法是:直接對精確識別得到內容通過 膨脹操作讓他沒那么精確,具體處理操作為:
于此同時參考上面過程還是進行加權組合
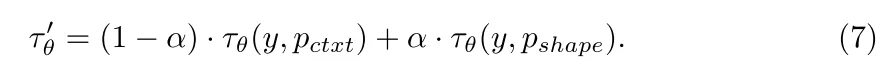
PowerPanint實際測試效果
只測試
Object removal inpainting,測試的權重:ppt-v1
| 圖像 | mask | 結果 | 測試 |
|---|---|---|---|
 |
 |
 |
部分移除 |
|
 |
 |
全部移除 |
 |
 |
 |
復雜布局全部移除 |
|
 |
 |
復雜布局細小內容移除 |
|
 |
 |
多目標內容移除 |
 |
 |
 |
多目標內容移除 |
總的來說:PowerPanint還是比較優秀的消除模型,總體移除效果“說得過去”(如果不去追求消除的細節,見下面圖像,比如說消除帶來的圖像被扭曲等)不過得到最后的圖像的尺寸會被修改(in:2250x1500 out:960x640,此部分沒有仔細去檢查源代碼是否可以取消或者自定義),除此之外,參考Github上提出的issue-1:圖像 resize 了,修改了分辨率,VAE 對人臉的重建有損失,如果mask沒有完全覆蓋掉人,留了一些邊緣,模型有bias容易重建生成出新的東西。issue-2:平均推理速度20s A100 GPU。

Improving Text-guided Object Inpainting with Semantic Pre-inpainting
From: https://github.com/Nnn-s/CATdiffusion.
沒有提供權重無法測試
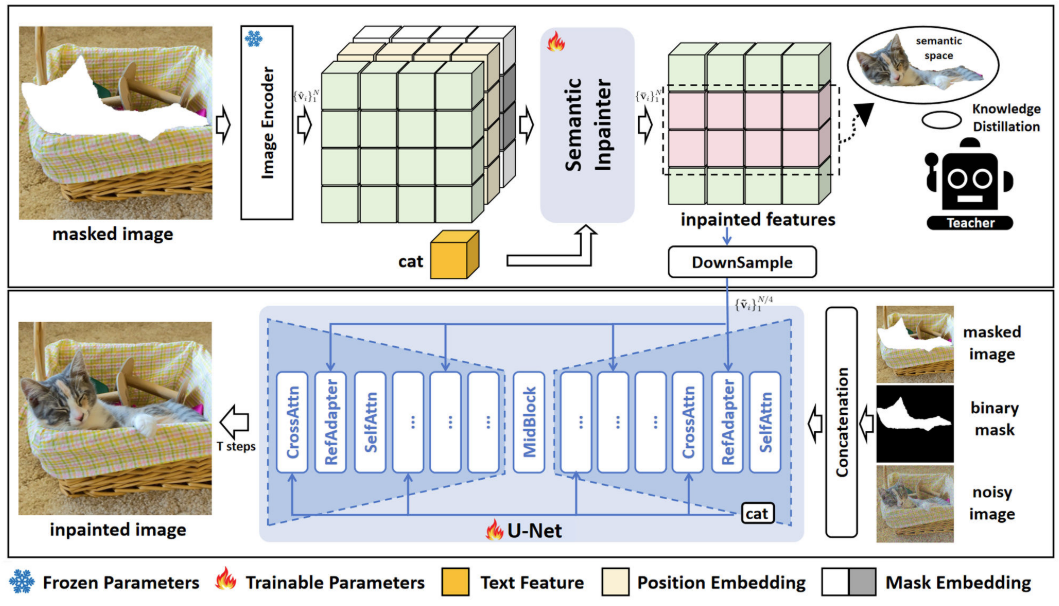
由于DDM生成過程中是不可控的,本文提出通過text來提高模型可控。相比較之前研究(直接將圖片通過VAE處理輸入DF中,并且將文本作為條件進行輸入),最開始得到的latent space和text feature之間存在“信息不對齊”。在該文中“提前”將text feature輸入到模型中。具體做法是:
- 首先通過CLIP來對齊特征信息
將image通過clip image encoder進行編碼得到特征而后通過SemInpainter:同時結合可學習的位置信息(PE)、可學習的mask圖像特征(ME)、文本特征,整個過程為:
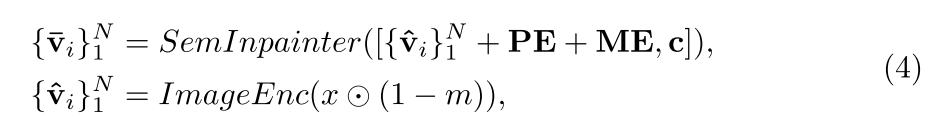
其中:SemInpainter(和CLIP的image encoder相似結構)根據視覺上下文和文本提示c的條件下,恢復CLIP空間中mask對象的ground-truth語義特征,說人話就是通過知識蒸餾方式來訓練這個模塊參數。對于兩部分特征最后通過下采樣方式得到最后特征:

- **reference adapter layer (RefAdapter) **

總結
簡單終結上面幾篇論文,基本出發思路都是基于Stable diffusion Moddel然后通過修改Condition方式:無論為是CLip編碼文本嵌入還是clip編碼圖像嵌入。不過值得留意幾個點:1、對于mask內容可以用“非規則”(類似對mask內容進行膨脹處理)的方式輸入到模型中來提高能力。2、在圖像擦除中容易出現幾個小問題:圖像替換問題(理論上是擦除圖像但是實際被其他圖像給“替換”)、圖像模糊問題(擦除圖像之后可能會在圖像上加一個“馬賽克”,擦除區域模糊)對于這兩類問題可以參考論文。
進一步閱讀: 1、https://arxiv.org/pdf/2504.00996;2、RAD: Region-Aware Diffusion Models for Image Inpainting

 浙公網安備 33010602011771號
浙公網安備 33010602011771號