
KT-pFL
相比于其他pFL,KT-pFL將聚合過程制定成個性化的群體知識遷移訓練算法,使每個客戶端都能在服務器端保持個性化的軟預測,以指導其他客戶端的本地訓練。
KT-pFL 通過使用知識系數矩陣對所有局部軟預測進行線性組合 來更新每個客戶的個性化軟預測,這可以自適應地加強擁有相似數據分布的客戶之間的協作。此外,為了量化每個客戶對他人個性化訓練的貢獻,知識系數矩陣被參數化,以便它可以與模型同時訓練。知識系數矩陣和模型參數在每一輪中都按照梯度下降方式交替更新。在不同設置(異構模型和數據分布)下對各種數據集 (EMNIST、Fashion_MNIST、CIFAR-10) 進行了廣泛的實驗。結果表明,所提出的框架是第一個通過參數化組知識遷移實現個性化模型訓練的聯邦學習范式,同時與最先進的算法相比實現了顯著的性能提升。
聯邦學習
可以在多個客戶端之間協作訓練共享的機器學習模型,而無需直接訪問私有數據。通過定期聚合客戶端的參數進行全局模型更新。(高精度和強泛化)
問題
用戶本地數據集中的異質性??采用個性化模型即個性化聯邦學習(pFL)。
KT-pFL
允許每個客戶端在服務器上維護個性化的軟預測,該預測可以通過使用知識系數矩陣的所有客戶端的局部軟預測的線性組合來更新。為了量化每個客戶對另一個客戶的個性化軟預測的貢獻,我們將知識系數矩陣參數化,以便它可以在每輪迭代中以交替的方式與模型同時訓練。
KT-pFL打破了同構模型限制壁壘,即每輪都需要傳輸整個參數集,其數據量遠大于軟預測,而且還通過使用參數化更新機制提高了訓練效率。
假設n個客戶端,每個客戶端只能接觸到自己的私有數據集
xi是第i個數據樣本,yi是xi對應的標簽

其中 Ln(w) 是第 n 個客戶端的本地損失函數,用于測量私有數據集Dn上的局部經驗風險, LCE 是交叉熵損失函數,用于測量預測值與真實值標簽之間的差異。
改進
設 s(wnx) 表示來自客戶端 n 的協作知識,x 表示來自所有客戶端都可以訪問的公共數據集 Dr 的數據樣本。定義客戶端 n 的個性化損失函數為
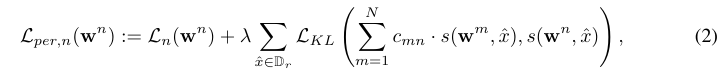
其中 入 > 0 是超參數,LKL 代表 Kullback-Leibler (KL) 發散函數,并添加到損失函數中,以將個性化知識從一位教師轉移到另一位教師。CMN 是知識系數,用于估計客戶 m 對 n 的貢獻。
KT-pFL框架
- 對私有數據進行本地訓練
- 3.各個客戶端輸出本地對公共數據的軟預測并發給服務器。
- 服務器通過本地軟預測和知識系數矩陣的線性組合計算每個客戶的個性化軟預測
- 每個客戶端下載個性化軟預測執行蒸餾階段
知識蒸餾的關鍵在于如何傳遞知識。傳統的訓練是使用真實標簽的hard targets,而知識蒸餾可能用到了教師模型輸出的soft targets,也就是概率分布
- 服務器更新知識系數矩陣
![]()
不同情況下,知識既可以指軟預測,也能指模型參數。

s(wn, x)可以認為是對客戶n的軟預測,用logits zn的softmax來計算,logits zn是客戶n模型上最后一個完全連接層的輸出,T是softmax函數的溫度超參數

其中 為所有權重的連接向量,dn表示模型參數wN的維數。1∈Rn2是元素都等于1的單位矩陣。(4)中的第二項是保證整個學習系統泛化能力的正則化項。如果沒有正則化項,數據分布完全不同的客戶端往往會設置較大的知識系數值(即等于1),在這種情況下,訓練過程中不會進行協作。ρ是一個大于0的正則化參數。
為所有權重的連接向量,dn表示模型參數wN的維數。1∈Rn2是元素都等于1的單位矩陣。(4)中的第二項是保證整個學習系統泛化能力的正則化項。如果沒有正則化項,數據分布完全不同的客戶端往往會設置較大的知識系數值(即等于1),在這種情況下,訓練過程中不會進行協作。ρ是一個大于0的正則化參數。
KT-pFL Algorithm
提出了一種局部模型參數和知識系數矩陣交替更新的KT-pFL算法。為了實現FL中的個性化知識轉移,我們根據相關的協作知識在本地訓練個性化模型。將(2)插入(4)中,我們可以設計一種交替優化方法來求解(4),即在每輪中輪流固定w或c,交替優化未固定的w或c,直到到達一個收斂點。
在每一輪通信中,我們首先固定c并局部優化(訓練)w幾個epoch。在這種情況下,w的更新既依賴于私有數據(即Dn上的LCE, n∈[1,···,n]),也依賴于公共數據(即Dr上的LKL),這些私有數據只能被對應的客戶端訪問,而公共數據(即Dr上的LKL)則可以被所有客戶端訪問。??


對于服務器:
把初始w0和c0給客戶端,在每輪通信中:讓每個客戶端并行算wn t+1,就是自己的wn,更新知識系數矩陣c并把c t+1告訴所有客戶端。
對于客戶端:
客戶端n收到服務器發的wn t和cn,每個本地epoch都進行小批量訓練并上傳。對于每個蒸餾步驟小批量訓練再對公共數據更新參數。
local training: 通過應用梯度下降步驟對每個客戶端的私有數據進行訓練。
式中,ξn為局部訓練中使用的小批數據Dn。η1為學習率。

distillation:蒸餾:將知識從個性化軟預測轉移到基于公共數據集的每個本地客戶端;
式中,ξr為公共數據的小批量Dr, η2為學習率。c?m = [cm1, cm2,···,cmN]為客戶m的知識系數向量,可在c的第m行找到。注意,這一階段需要所有的協作知識和知識系數矩陣來獲得個性化軟預測,這些知識和知識系數矩陣可在服務器中收集。

update c:在本地更新了幾個epoch之后,我們轉向固定w并在服務器中更新c。
η3是更新c的學習率。
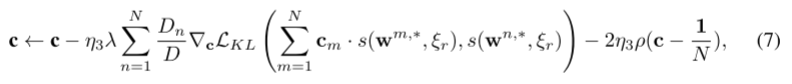
算法1演示了提出的KT-pFL算法,其背后的思想如圖1所示。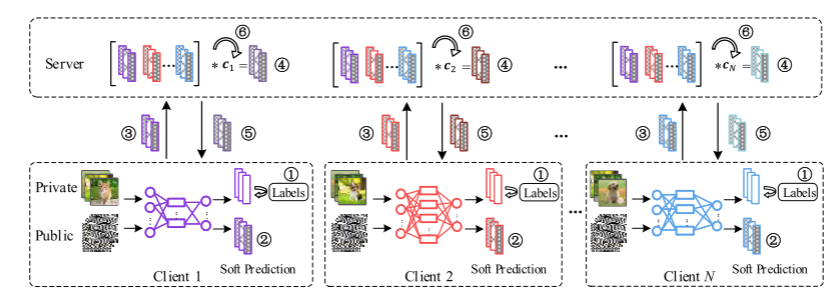
在每一輪通信訓練中,客戶端使用本地SGD基于私有數據訓練多個epoch,然后將協作知識(例如對公共數據的軟預測)發送給服務器。服務器接收到來自各個客戶端的協作知識后,根據知識系數矩陣對其進行聚合,形成個性化的軟預測。然后,服務器將個性化的軟預測發送回每個客戶端,以執行本地蒸餾。然后,客戶端在公共數據集2上迭代多個步驟。然后,在服務器端更新知識系數矩陣,同時確定模型參數w。
Evaluation
Task and Datasets
在三個不同的圖像分類任務:EMNIST[35]、Fashion_MNIST[36]和CIFAR-10[37]上評估了提出的訓練框架。對于每個數據集,應用兩種不同的Non-IId數據設置:1)每個客戶端只包含兩類樣本;2)每個客戶端包含所有類別的樣本,而每個類別的樣本數量與不同客戶端不同。所有的數據集被隨機分割,訓練和測試的比例分別為75%和25%。每個客戶機上的測試數據與其訓練數據具有相同的分布。對于所有方法,我們記錄了所有局部模型的平均測試精度進行評估
Model Structure
實驗采用了LeNet[38]、AlexNet[39]、ResNet-18[40]和ShuffleNetV2[41]四種不同的輕量級模型結構。我們的pFL系統有20個客戶端,它們被分配到4個不同的模型結構中,即每個模型5個客戶端。
Baseline
我們將KT-pFL的性能與基于非個性化蒸餾的方法(FedMD [13], FedDF[16])和基于個性化蒸餾的方法(pFedDF3)以及其他簡單版本的KT-pFL (Sim-pFL和TopK-pFL)進行了比較。

 浙公網安備 33010602011771號
浙公網安備 33010602011771號