From "LLM" to "Agent"(從大語言模型到智能體)
比爾·蓋茨近期發表了一篇博客,其中談到Agents將會是LLM的未來方向。LLM是一個Decoder,是Agent的大腦。LLM和Agent的區別,正如GPT-4和ChatGPT的區別。
1 Intro
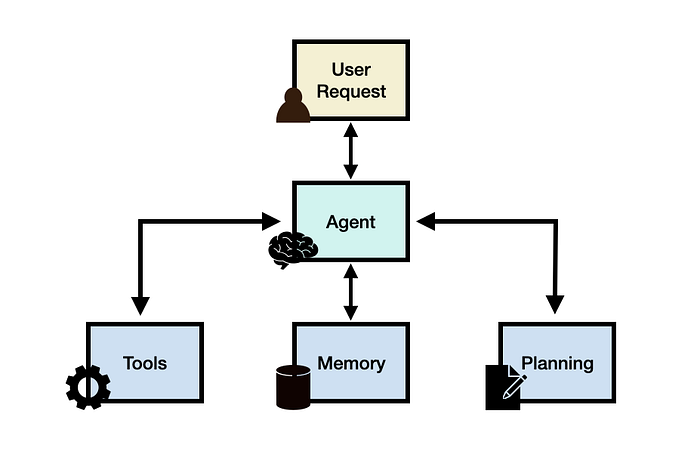
如圖所示:
- Agents具有運用“Tools”的能力,可以調用外部api或沙盤來執行代碼;
- Agents具有多種“Memory”的能力,短期記憶指的是當前token內的上下文窗口,長期記憶指的是LLM的權重參數;
- Agents具有可以“Planning”的能力,能夠自主進行子任務分解和自我反省。
2 Tool Usage
能夠使用工具是人類與其他生物在很多方面的區別。我們創造、修改和利用外部物體來擴展我們的身體和認知能力。同樣,為大語言模型配備外部工具可以顯著擴展其功能。
在AI Agents設置中,工具對應于一組工具集合,這些工具集合使LLM Agents能夠與外部環境(如谷歌搜索、代碼解釋器、數學引擎等)進行交互。工具也可以是某種形式的數據庫、知識庫和外部模型。當Agents與外部工具交互時,它通過工作流執行任務,這些工作流幫助Agents獲得觀察結果或必要的上下文,以完成給定的子任務并最終完成完整的任務。
3 Memories
《普通心理學》書中將人的記憶區分為三種:感覺記憶(瞬時記憶)、工作記憶(短期記憶)、長時記憶(長期記憶)。
對于Agents來說,感覺記憶就是Embedding后的嵌入向量;工作記憶則是經過Transformer注意力機制捕捉后的隱狀態序列;長時記憶則通常指大語言模型的權重參數。
除了內部記憶,Agents可以使用外部記憶如RAG機制。
4 Planning Strategy
Agents的規劃能力是當前的最大挑戰。

如圖所示,有很多這樣的論文,即思想鏈,思想樹,思想算法(也稱思想圖)。這些方法都在原本的LLM Decoder上強調分步推理的提示工程和微調。提示工程幫助引導模型,模型具體的推理過程是自己分析得出的。
4.1 自我反省
上述規劃模塊不涉及任何反饋,這使得很難實現長期規劃,特別是解決復雜任務所必需的。為了應對這一挑戰,我們可以創建一個過程,以迭代地反映和改進基于過去的行動和觀察的執行計劃。目標是糾正和改進過去的錯誤,這有助于提高最終結果的質量。
和人類一樣,Agents需要策略從錯誤中汲取教訓。
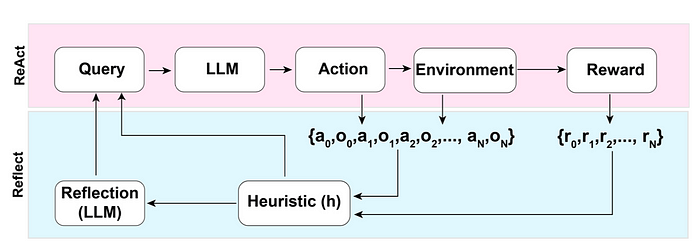
ReAct
ReAct結合了推理和行動,旨在使LLM能夠通過在一系列步驟(重復N次)之間交錯來解決復雜的任務:Thought,Action和Observation。


Reflexion
這是一個基于ReAct改進,為智能體提供動態記憶和自我反思能力以提高推理能力的框架。反射有一個標準的強化學習設置,其中獎勵模型提供一個簡單的二元獎勵,操作空間遵循ReAct中的設置,其中特定于任務的操作空間用語言增強,以支持復雜的推理步驟。
Chain of Hindsight(CoH)
模型被要求通過查看自己過去的工作來改進自己,進行評分,并附上關于下次如何做得更好的筆記。該模型通過使用其自身嘗試和反饋的歷史,嘗試產生一個將獲得更好評級的新輸出來進行實踐。
Algorithm Distillation(AD)
AD算法蒸餾將類似的想法應用于機器人或代理學習任務。代理回顧它在過去幾次嘗試中的表現,并試圖找出改進的算法模式。然后,它預測下一步應該比之前的動作更好,學習變得更好的算法策略。
參考博文https://luxiangdong.com/2024/04/28/agents2/。

 浙公網安備 33010602011771號
浙公網安備 33010602011771號