
昇騰服務(wù)器將BAAI/bge-large-zh-v1.5向量模型(bge模型)轉(zhuǎn)onnx轉(zhuǎn)om并部署
一、下載模型
使用huggingface-cli命令行下載
mkdir -p BAAI && ls BAAI|xargs huggingface-cli download BAAI/bge-large-zh-v1.5 --resume-download --local-dir-use-symlinks False --local-dir BAAI --exclude二、轉(zhuǎn)onnx
from transformers import AutoTokenizer, AutoModel
import torch
import numpy as np
import os
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('BAAI')
model = AutoModel.from_pretrained('BAAI')
model.eval()
def generate_random_data(shape, dtype, low=0, high=2):
if dtype in ["float32", "float16"]:
return np.random.random(shape).astype(dtype)
elif dtype in ["int32", "int64"]:
return np.random.uniform(low, high, shape).astype(dtype)
else:
raise NotImplementedError("Not supported format: {}".format(dtype))
input_data = (
torch.Tensor(generate_random_data([1, 256], "int64")).to(torch.int64),
torch.Tensor(generate_random_data([1, 256], "int64")).to(torch.int64),
torch.Tensor(generate_random_data([1, 256], "int64")).to(torch.int64)
)
input_names = ["input_ids", "attention_mask", "token_type_ids"]
output_names = ["out"]
torch.onnx.export(
model,
input_data,
os.path.join("BAAI", "bge-small-zh-v1.5.onnx"),
input_names=input_names,
output_names=output_names,
opset_version=11,
)三、onnx文件轉(zhuǎn)om文件
atc --model=./bge-small-zh-v1.5.onnx --framework=5 --output=./bge-small-zh-v1.5 --input_format=ND --log=debug --input_shape "input_ids:1,256;token_type_ids:1,256;attention_mask:1,256" --out_nodes "out" --soc_version=Ascend310P3注意:
--soc_version的310P3是你npu的型號(hào),使用npu-smi info查看

四、運(yùn)行om文件獲取文本向量
運(yùn)行代碼需要第五步安裝完依賴(lài)才可以運(yùn)行
import numpy as np
import os
import sys
from transformers import (
# BertAdapterModel,
AutoConfig,
AutoTokenizer)
# path = os.path.dirname(os.path.abspath(__file__))
# sys.path.append(os.path.join(path, "../embed/acllite"))
from ACLLite.python.acllite_resource import AclLiteResource
from ACLLite.python.acllite_model import AclLiteModel
# om文件路徑
model_path = 'bge-small-zh-v1.5.om'
def postprocess(output, attention_mask=None):
sentence_embeddings_np = output[0][:, 0]
sentence_embeddings_np = sentence_embeddings_np / np.linalg.norm(sentence_embeddings_np, ord=2, axis=1,
keepdims=True)
return sentence_embeddings_np
def preprocess(text, tokenizer):
# inputs = tokenizer(text, padding='max_length', max_length=512, return_tensors='pt')
inputs = tokenizer(text, padding='max_length', max_length=256, truncation=True, return_tensors='pt')
# inputs = tokenizer(text, padding=True, truncation=True, return_tensors='pt')
input_ids = inputs['input_ids'].detach().cpu().numpy()
attention_mask = inputs['attention_mask'].detach().cpu().numpy()
token_type_ids = inputs['token_type_ids'].detach().cpu().numpy()
inputs = [input_ids, attention_mask, token_type_ids]
return inputs, attention_mask
acl_resource = AclLiteResource()
acl_resource.init()
model = AclLiteModel(model_path)
# 模型文件路徑
tokenizer = AutoTokenizer.from_pretrained('bge-large-zh-v1.5')
def query(input):
inputs, attention_mask = preprocess(input.query, tokenizer)
outputs = model.execute(inputs)
outputs = postprocess(outputs, attention_mask)
return {"vecters": outputs.tolist()}
def cosine_similarity(embedding1, embedding2):
# 計(jì)算兩個(gè)向量的內(nèi)積
dot_product = np.dot(embedding1, embedding2)
# 計(jì)算兩個(gè)向量的模長(zhǎng)
norm1 = np.linalg.norm(embedding1)
norm2 = np.linalg.norm(embedding2)
# 計(jì)算余弦相似度
similarity = dot_product / (norm1 * norm2)
return similarity
if __name__ == '__main__':
text_1 = "我愛(ài)天安門(mén)"
inputs_1, attention_mask = preprocess(text_1, tokenizer)
result_list_1 = model.execute(inputs_1)
embedding1 = postprocess(result_list_1)[0]
# 輸出向量
print("embedding1",embedding1)
# 余弦相似度
# print(cosine_similarity(embedding1, embedding2))接口形式:
import numpy as np
import os
from fastapi import FastAPI, Depends
from pydantic import BaseModel
from typing import List
from transformers import AutoTokenizer
from ACLLite.python.acllite_resource import AclLiteResource
from ACLLite.python.acllite_model import AclLiteModel
# om文件路徑
model_path = 'bge-small-zh-v1.5.om'
# 模型文件路徑
model_name = 'bge-large-zh-v1.5'
# 全局變量
acl_resource = None
model = None
app = FastAPI()
tokenizer_ = AutoTokenizer.from_pretrained(model_name)
class InputItem(BaseModel):
input: List[str]
model: str
class EmbeddingResponse(BaseModel):
object: str
embedding: List[float]
class EmbeddingsResponse(BaseModel):
data: List[EmbeddingResponse]
def postprocess(output, attention_mask=None):
sentence_embeddings_np = output[0][:, 0]
sentence_embeddings_np = sentence_embeddings_np / np.linalg.norm(sentence_embeddings_np, ord=2, axis=1, keepdims=True)
return sentence_embeddings_np
def preprocess(texts, tokenizer):
inputs = tokenizer(texts, padding='max_length', max_length=256, truncation=True, return_tensors='pt')
input_ids = inputs['input_ids'].detach().cpu().numpy()
attention_mask = inputs['attention_mask'].detach().cpu().numpy()
token_type_ids = inputs['token_type_ids'].detach().cpu().numpy()
return input_ids, attention_mask, token_type_ids
@app.post("/v1/embeddings", response_model=EmbeddingsResponse)
async def get_embeddings(input_data: InputItem):
texts = input_data.input
model_n = input_data.model
input_ids, attention_mask, token_type_ids = preprocess(texts, tokenizer_)
outputs = model.execute([input_ids, attention_mask, token_type_ids])
embeddings = postprocess(outputs, attention_mask)
response_data = []
for embedding in embeddings:
response_data.append({
"object": "embedding",
"embedding": embedding.tolist(),
})
return {"data": response_data}
@app.on_event("startup")
def startup_event():
global acl_resource, model
acl_resource = AclLiteResource()
acl_resource.init()
model = AclLiteModel(model_path)
def start_server():
import uvicorn
# om_baai_main是你腳本名字
uvicorn.run("om_baai_main:app", host=os.environ.get('EMBEDDING_HOST', '0.0.0.0'),
port=int(os.environ.get('EMBEDDING_PORT', 8000)), workers=int(os.environ.get('EMBEDDING_WORKERS', 1)))
if __name__ == "__main__":
start_server()接口調(diào)用方式:
curl --location --request POST 'http://192.168.21.30:8000/v1/embeddings' \
--header 'Content-Type: application/json' \
--data-raw '{
"input": [
"八一建軍節(jié)前夕,中共中央政治局就推進(jìn)現(xiàn)代邊海空防建設(shè)進(jìn)行第十六次集體學(xué)習(xí)。"
],
"model": "bge-large-zh-v1.5" # 隨便寫(xiě),沒(méi)做校驗(yàn)
}'五、安裝ACLLite依賴(lài)
from ACLLite.python.acllite_resource import AclLiteResource
from ACLLite.python.acllite_model import AclLiteModel
from ACLLite.python.acllite_model import AclLiteModel
需要安裝ACLLite,地址是:https://gitee.com/ascend/ACLLite
按照源碼編譯安裝
此過(guò)程可能提示安裝git和sudo:
# 安裝git
apt-get update
apt-get install -y git
# 安裝sudo
apt-get install sudo安裝以后運(yùn)行代碼,會(huì)提示ACLLite項(xiàng)目里找不到包,實(shí)際是導(dǎo)包路徑問(wèn)題,進(jìn)入項(xiàng)目找到對(duì)應(yīng)文件改一下路徑就可以
比如:
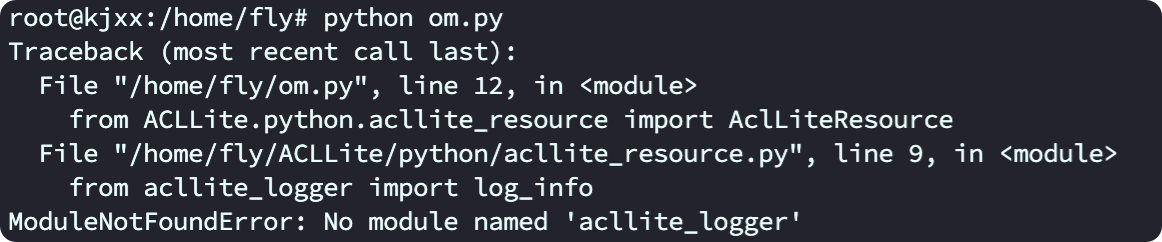
將from acllite_logger import log_info改成from ACLLite.python.acllite_logger import log_info
除此以外還要安裝一個(gè)Pillow:pip install Pillow==9.5.0

 浙公網(wǎng)安備 33010602011771號(hào)
浙公網(wǎng)安備 33010602011771號(hào)