
基于Qlearning強化學習的Cart-Pole推車桿平衡控制系統matlab仿真
1.算法仿真效果
matlab2022a仿真結果如下(完整代碼運行后無水印):

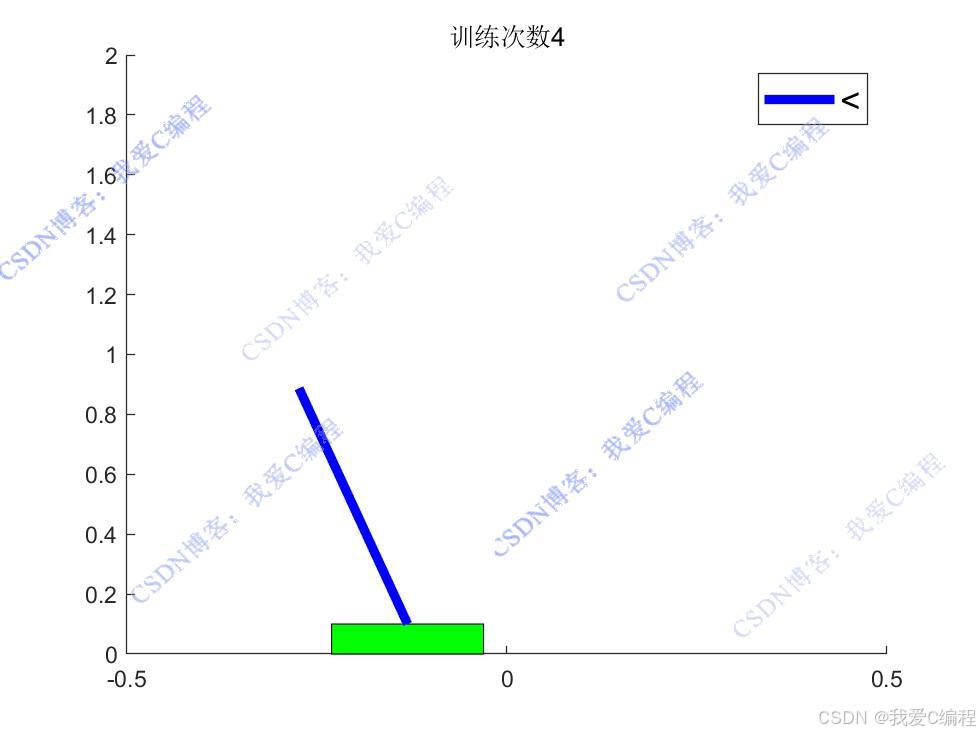
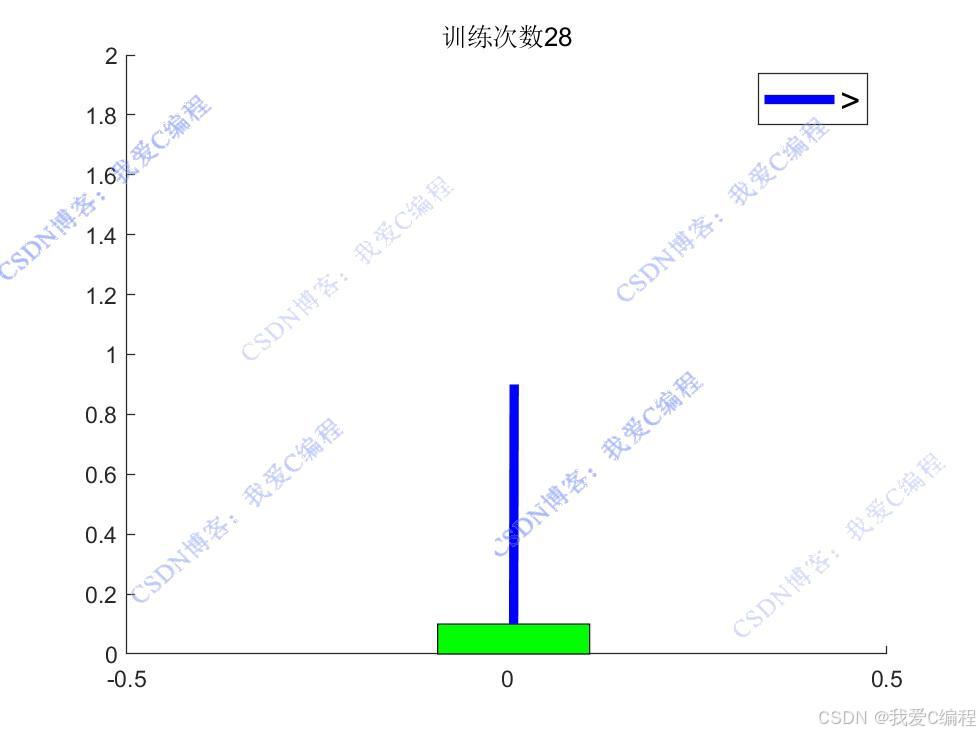

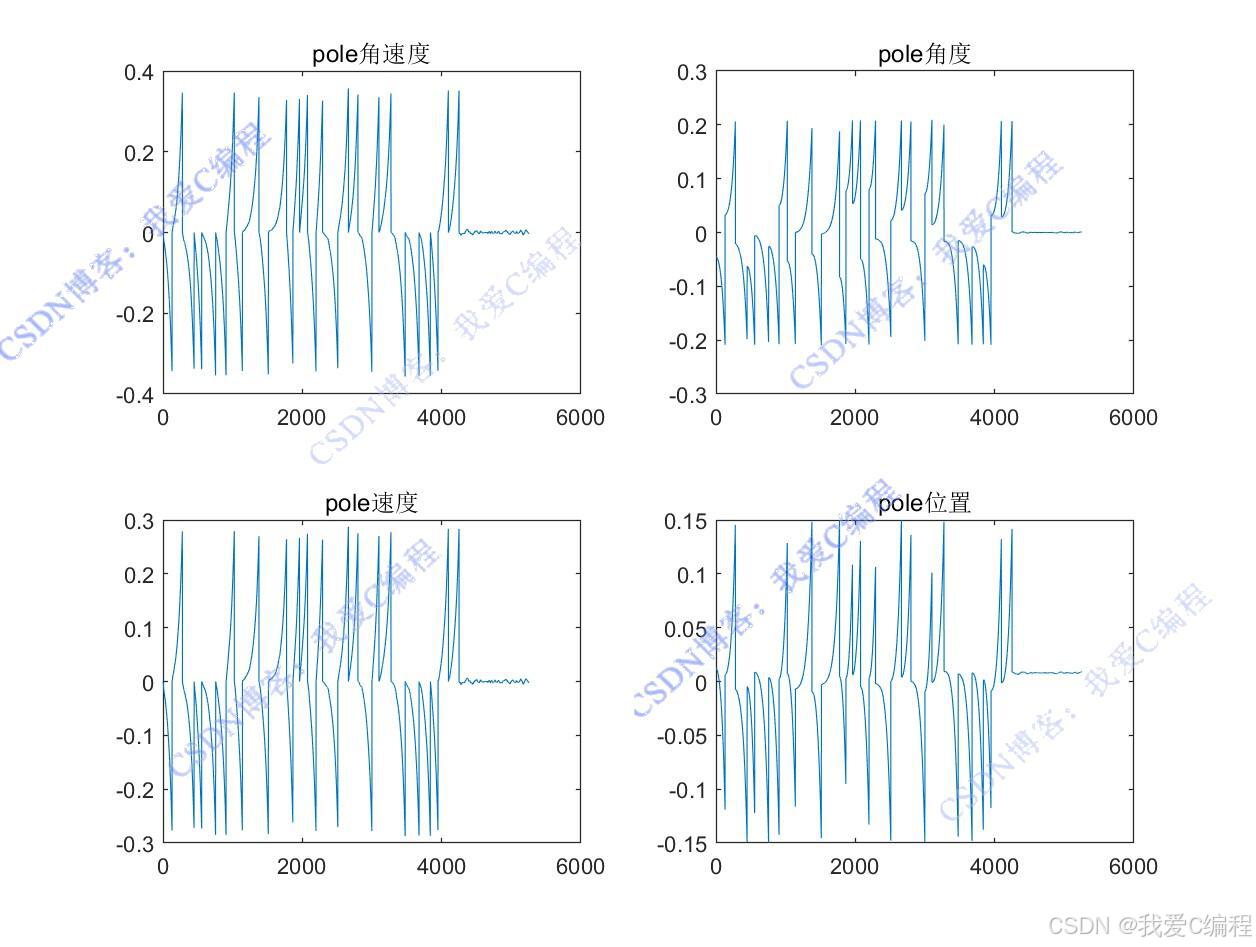
通過不斷與環境交互并更新Q值函數,智能體能夠逐漸學習到在不同狀態下的最優動作,從而實現桿的平衡控制。
仿真操作步驟可參考程序配套的操作視頻。
2.算法涉及理論知識概要
強化學習作為一種強大的機器學習范式,為解決這類復雜的控制問題提供了有效的途徑。其中,Q-learning算法因其簡單性和通用性,在Cart-Pole推車桿平衡控制系統中得到了廣泛應用。本文將深入探討基于Q-learning強化學習的Cart-Pole推車桿平衡控制系統的原理。
Cart-Pole物理模型
Cart-Pole系統由一個可在水平軌道上移動的推車和一根通過鉸鏈連接在推車上的桿組成。假設推車的質量為

這些方程描述了系統狀態隨時間的變化規律,是理解和控制Cart-Pole系統的基礎。
Cart-Pole推車桿平衡控制系統的目標是設計一個控制器,通過施加合適的力F,使桿在盡可能長的時間內保持垂直平衡狀態(即 θ≈0),同時確保推車不超出軌道邊界。在實際應用中,這一問題的解決方案可以推廣到機器人平衡控制、火箭姿態調整等領域。
Q-learning強化學習
強化學習是一種通過智能體(Agent)與環境(Environment)進行交互,以最大化累積獎勵(Reward)為目標的機器學習方法。在Cart-Pole系統中,智能體就是負責控制推車運動的控制器,環境則是Cart-Pole系統本身。
Q值函數的更新規則為:
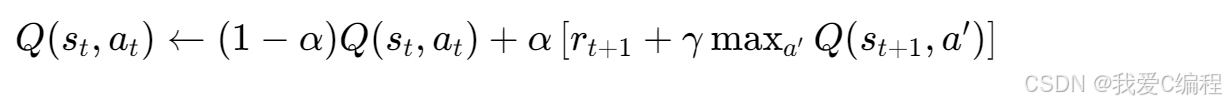
控制每次更新的步長。學習率越大,新的經驗對Q值的影響越大;學習率越小,Q值的更新越依賴于之前的估計。
在訓練完成后,使用訓練好的Q表進行測試。在測試過程中,智能體采用貪心策略(即 ?=0)選擇動作,觀察Cart-Pole系統在不同初始狀態下的平衡控制效果。可以通過計算系統保持平衡的平均時間、成功平衡的次數等指標來評估控制器的性能。
3.MATLAB核心程序
.............................................................
% 繪制新的狀態
figure(1);
% 計算桿的兩個端點的 x 坐標
X = [Pos_car, Pos_car+Lens*sin(Ang_car)];
% 計算桿的兩個端點的 y 坐標
Y = [0.1, 0.1+Lens*cos(Ang_car)];
% 繪制小車,用綠色矩形表示
obj=rectangle('Position',[Pos_car-0.1,0,0.2,0.1],'facecolor','g');
hold on
% 繪制桿,用藍色粗線表示
obj2=plot(X,Y,'b','LineWidth',4);
hold on
% 設置坐標軸范圍
axis([-0.5 0.5 0 2]);
% 根據外力方向顯示圖例
if F > 0
legend('>','FontSize', 15);
else
legend('<','FontSize', 15);
end
% 更新圖形窗口的標題,顯示訓練次數和最大成功次數
title(strcat('訓練次數',num2str(iters)));
hold off
% 繪制平均 Q 值隨訓練次數的變化曲線
figure
plot(Q_save);
% 設置 x 軸標簽
xlabel('訓練次數');
% 設置 y 軸標簽
ylabel('Q value收斂值');
% 繪制子圖
figure
% 繪制第一個子圖,顯示桿的角速度隨訓練次數的變化
subplot(221);
plot(Vang_car_save);
% 設置子圖標題
title('pole角速度');
% 繪制第二個子圖,顯示桿的角度隨訓練次數的變化
subplot(222);
plot(Ang_car_save);
% 設置子圖標題
title('pole角度');
% 繪制第三個子圖,顯示小車的速度隨訓練次數的變化
subplot(223);
plot(V_car_save);
% 設置子圖標題
title('pole速度');
% 繪制第四個子圖,顯示小車的位置隨訓練次數的變化
subplot(224);
plot(Pos_car_save);
% 設置子圖標題
title('pole位置');
0Z_016m

 浙公網安備 33010602011771號
浙公網安備 33010602011771號