
答題判題程序題目集 1~3 的總結(jié)性 Blog
- 前言
1.1 題目集概述
答題判題程序 - 1:
字符串解析:題目內(nèi)容和答題內(nèi)容都是按照特定格式給出的字符串,程序需要能正確地拆分和解析這些字符串,然后進行匹配。
對象和類的使用:為了更好地管理題目和答題信息,我們可以設(shè)計合適的類。每個題目可以作為一個對象,存儲它的編號、內(nèi)容、標準答案,以及對應(yīng)的答題者答案,方便后續(xù)的判題和處理。
邏輯判斷:程序需要根據(jù)答卷中的答案和標準答案逐一對比,判斷答對與否,并輸出結(jié)果(比如 true/false)。
處理輸入順序和題號不一致的情況:有時候輸入的題目順序可能不是按照題號排列的,為了保證判題結(jié)果準確,程序需要先根據(jù)題號排序,然后再進行匹配和判斷。
題量與難度的靈活性:
題量可調(diào):程序必須具備處理任意數(shù)量題目和答案的能力,不管是幾道題都要能正常工作。
實現(xiàn)難度:整體實現(xiàn)難度適中,主要考察你在字符串處理、數(shù)據(jù)結(jié)構(gòu)使用和邏輯判斷方面的能力。雖然不會特別復(fù)雜,但需要你在細節(jié)上做到嚴謹,比如輸入的解析和判題邏輯的準確性。
總結(jié)一下,這部分內(nèi)容強調(diào)的是字符串操作、合理使用類來管理數(shù)據(jù),以及靈活應(yīng)對不同題量的能力。雖然不算特別難,但也需要認真考慮題目排序和答案匹配等細節(jié)。
答題判題程序 - 2:
在答題判題程序1的基礎(chǔ)上引入了試卷編號、題目編號和分值的關(guān)聯(lián),這就要求我們用一個合適的數(shù)據(jù)結(jié)構(gòu)來保存這些信息。這樣就需要使用List列表或者哈希表來存儲試卷號和試卷中的題目及其分值。這樣做的好處是,當(dāng)我們需要查詢某張試卷的題目和分值時,能快速定位和處理。
為了確保程序的穩(wěn)健性,加入了一些異常情況的處理。比如,如果試卷的總分不等于100分,程序會給出一個警告提示“alert: full score of test paper1 is not 100 points”反之當(dāng)試卷總分等于100分時不提示消息。此外,如果答卷中使用的試卷號根本不存在,程序也會給出相應(yīng)的錯誤提示“The test paper number does not exist”。這個過程需要額外的驗證和檢測,確保所有輸入數(shù)據(jù)都是合理的。
其次,在第二題中,答卷里的答案數(shù)量可以和試卷上的題目數(shù)量不一致。比如,如果答卷上的答案少于題目數(shù)量,程序需要輸出 answer is null,表示這道題沒有答案,當(dāng)然該輸出會根據(jù)答卷的輸入順序來輸出結(jié)果。如果答案超過題目的數(shù)量,程序會自動忽略多余的答案。這個邏輯需要對答題的長度進行檢查,并根據(jù)情況靈活處理。
每道題現(xiàn)在有了分值,所以在判題的時候,答對了要加上相應(yīng)的分數(shù)。如果題目數(shù)量較多,總分的計算就會更復(fù)雜,程序需要小心處理。此外,輸出的格式也有了更多要求,除了正確與否的判斷,還需要把分數(shù)和總分按要求展示出來,這部分涉及到如何拼接和格式化輸出字符串。
總結(jié)下來,第二題增加的要求讓程序在數(shù)據(jù)管理、異常處理和邏輯判斷上更加復(fù)雜,但也更考驗程序的靈活性和穩(wěn)健性。
答題判題程序 - 3:
第三次答題判題程序比前兩次增加了眾多內(nèi)容,增加了學(xué)生信息(學(xué)號-姓名);答卷信息增加與學(xué)生學(xué)號的關(guān)聯(lián),每個答卷對應(yīng)一個學(xué)生,若有多個學(xué)生學(xué)號,可以存在若干學(xué)生沒有答卷,只需要將存在的答卷信息進行輸出。當(dāng)然答卷信息中還有需要處理的難題,“#A:2-3”便是答卷中的答案,其中2對應(yīng)的時試卷題目的順序號,3對應(yīng)的是該順序號對應(yīng)的題號的答案。
還有增加的輸入格式——刪除題目信息“#D:N-2”;一行刪除信息僅可刪除一題,但可有多條刪除信息分多行輸入。如何處理要刪除題目的呢,我的思路是將需要刪除的題目號和其他題目號一起存入試卷中,但是要刪除的題目號對應(yīng)的題目是"the question " + num + " invalid",在輸出時遍歷試卷中的所有題目號,進行判斷是否與該content匹配,如果匹配直接輸出the question num invalid~0。
這些都是在前兩題的基礎(chǔ)上增加的輸入格式,當(dāng)然這題還要求程序進行對輸入內(nèi)容的格式檢查,我就想到對每個匹配的內(nèi)容進行正則表達式匹配,如果匹配成功才進行下一步的拆分存儲各Group內(nèi)容。如何進行匹配呢,首先第一個就是對題目的配對格式必須是”#N: +... #Q: +... #A +...”對應(yīng)的三部分內(nèi)容題號、題目內(nèi)容、標準答案,題號必須是整數(shù),其他兩部分可以任意不為空的內(nèi)容。第二個是對試卷的處理,#T:1 1-5 3-8,以”#T”開頭,其他都是\d+的的組合,表示都是整數(shù)的內(nèi)容。第三個是對學(xué)生信息的處理,"#X:"+學(xué)號+" "+姓名+"-"+學(xué)號+" "+姓名....+"-"+學(xué)號+" "+姓名 ,第四個是對學(xué)生答卷的處理,"#S:"+試卷號+" "+學(xué)號+" "+("#A:"+試卷題目的順序號+"-"+答案內(nèi)容)該內(nèi)容可以出現(xiàn)多次即一張試卷會有多個題目。
第五個是對刪除題目信息的處理,"#D:N-"+題目號,只需匹配"#D:N-"開頭內(nèi)容和整數(shù)題目號即可。
2. 設(shè)計與分析
2.1 源碼結(jié)構(gòu)分析
2.1.1 類圖與架構(gòu)設(shè)計(使用 PowerDesigner 繪制)
1、答題判題程序1
組合:Exam 類通過組合的方式持有 Question 對象。
關(guān)聯(lián):Answer 類通過關(guān)聯(lián)方式持有 Exam 對象的引用。
依賴:Main 類依賴 Exam 和 Answer,而 Answer 類依賴 Exam。這使得類之間有一定的耦合關(guān)系,但由于職責(zé)明確,整體設(shè)計較為清晰。
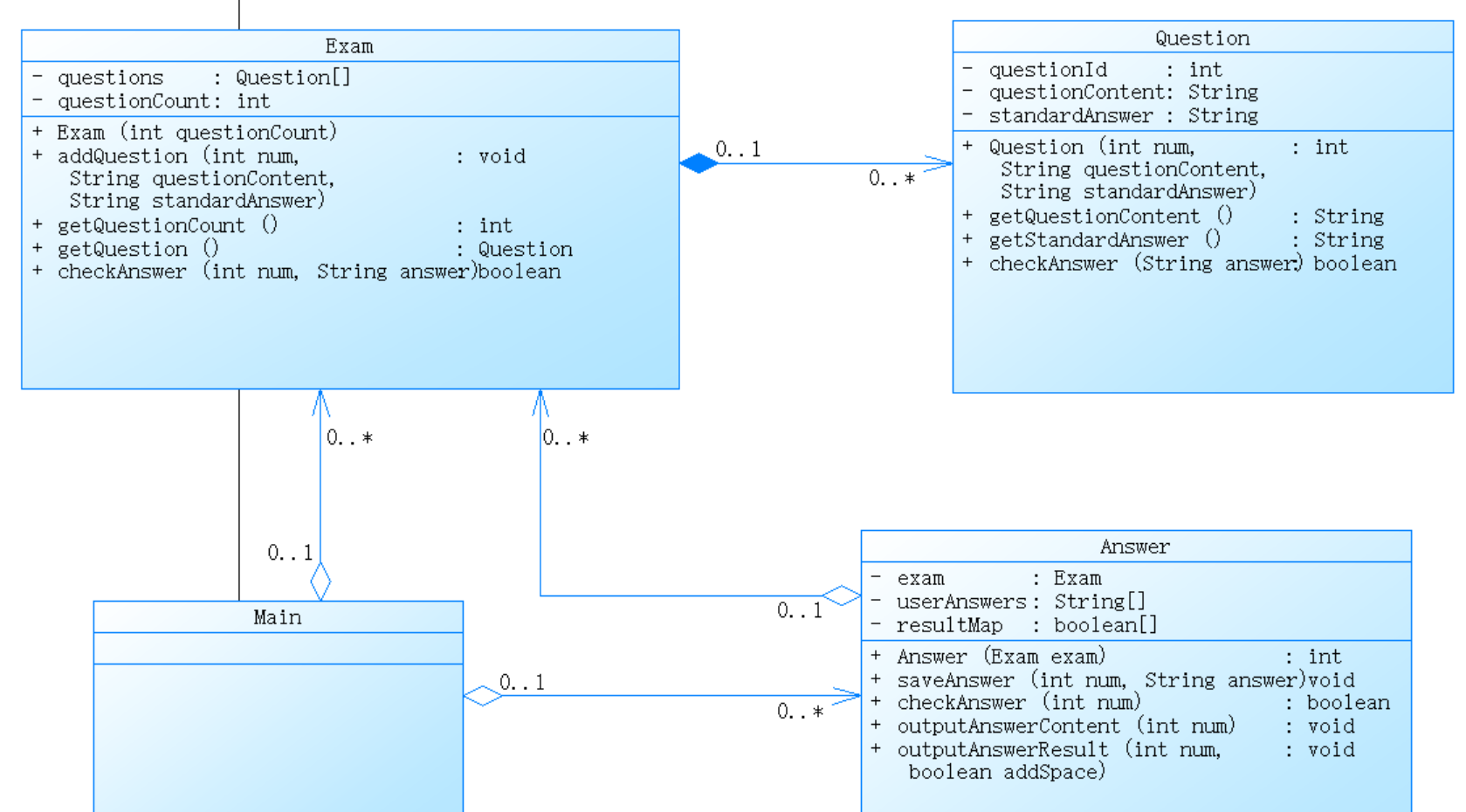
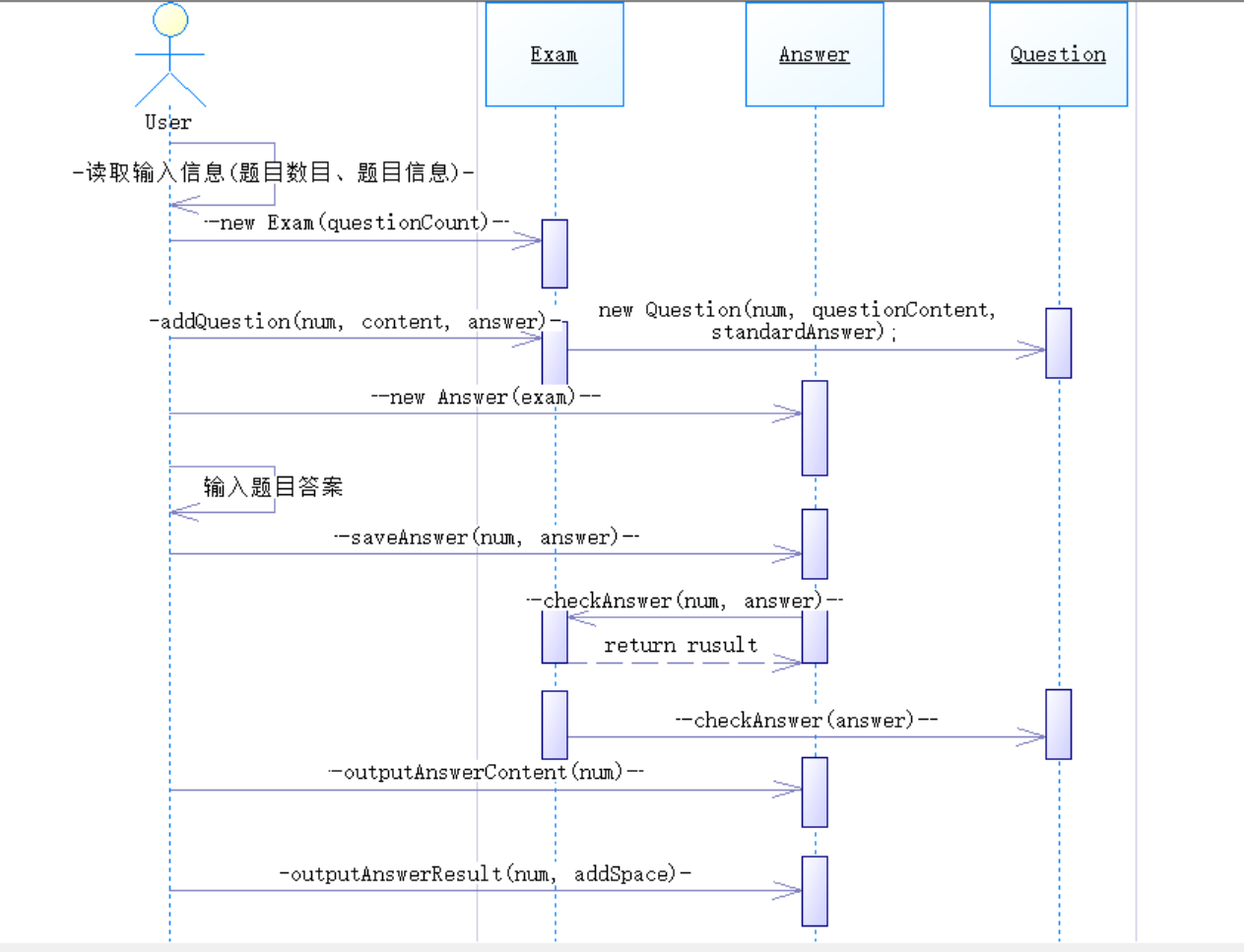
根據(jù)各類之間的關(guān)系設(shè)計了以下順序圖:
2、答題判題程序2
(1)Main 類:
初始化 Exam、testPapers (存儲試卷信息) 和 answerSheets (存儲答卷信息)。
使用 InputHandler 來處理輸入數(shù)據(jù),使用 OutputHandler 來處理結(jié)果輸出。
(2)InputHandler 類:
解析題目信息 (#N: 開頭),并將其存儲在 Exam 對象中。
解析試卷信息 (#T: 開頭),并存儲試卷題號和對應(yīng)的分數(shù)。還會檢查試卷總分是否為 100 分。
解析答卷信息 (#S: 開頭),并根據(jù)試卷中的題目,構(gòu)建 AnswerSheet 對象。
(3)OutputHandler 類:
遍歷所有答卷,輸出每道題的答題情況(是否正確),以及計算并顯示答卷的總分。
(4)輔助類:
QuestionScore:封裝題目編號和分數(shù)。
Exam:存儲題目列表,每道題包括內(nèi)容和標準答案。
Question:包含題目的內(nèi)容和標準答案。
AnswerSheet:存儲答卷的題號、用戶作答、以及輸出題目答案和分數(shù)。
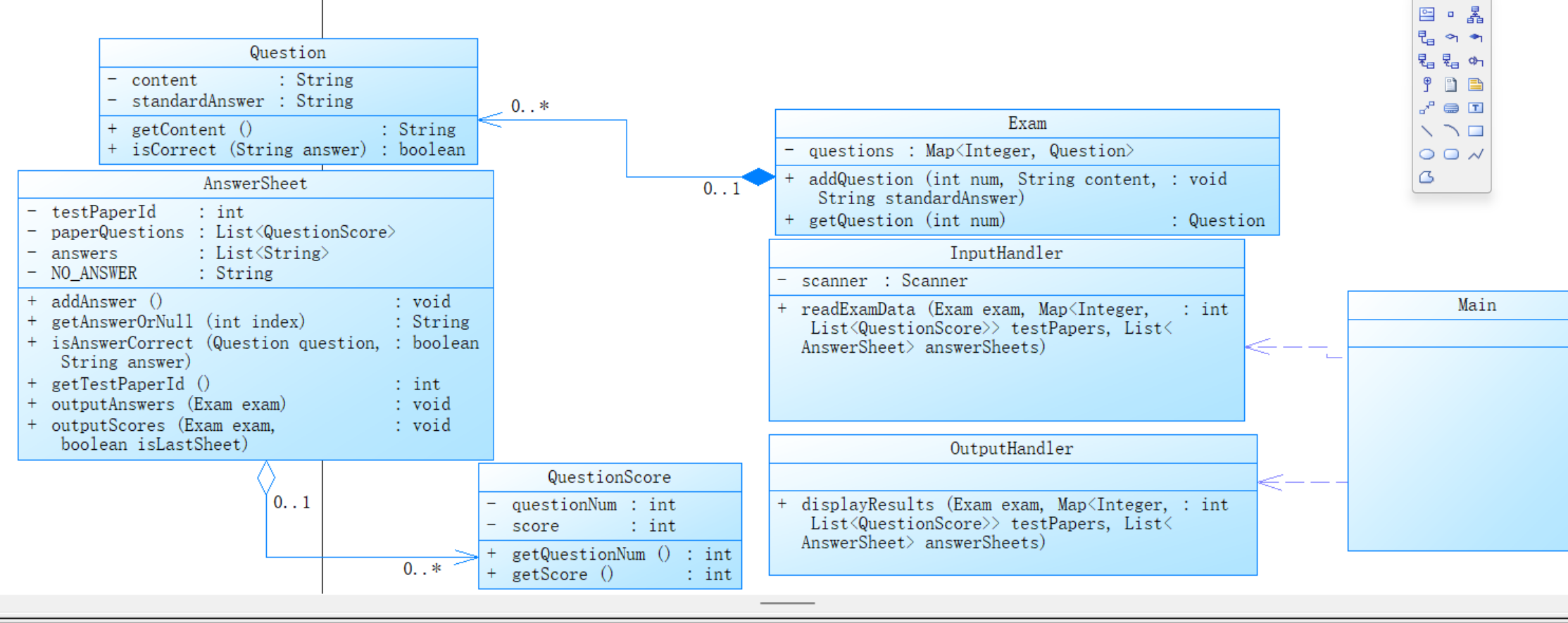
根據(jù)各類之間的關(guān)系設(shè)計了以下順序圖:
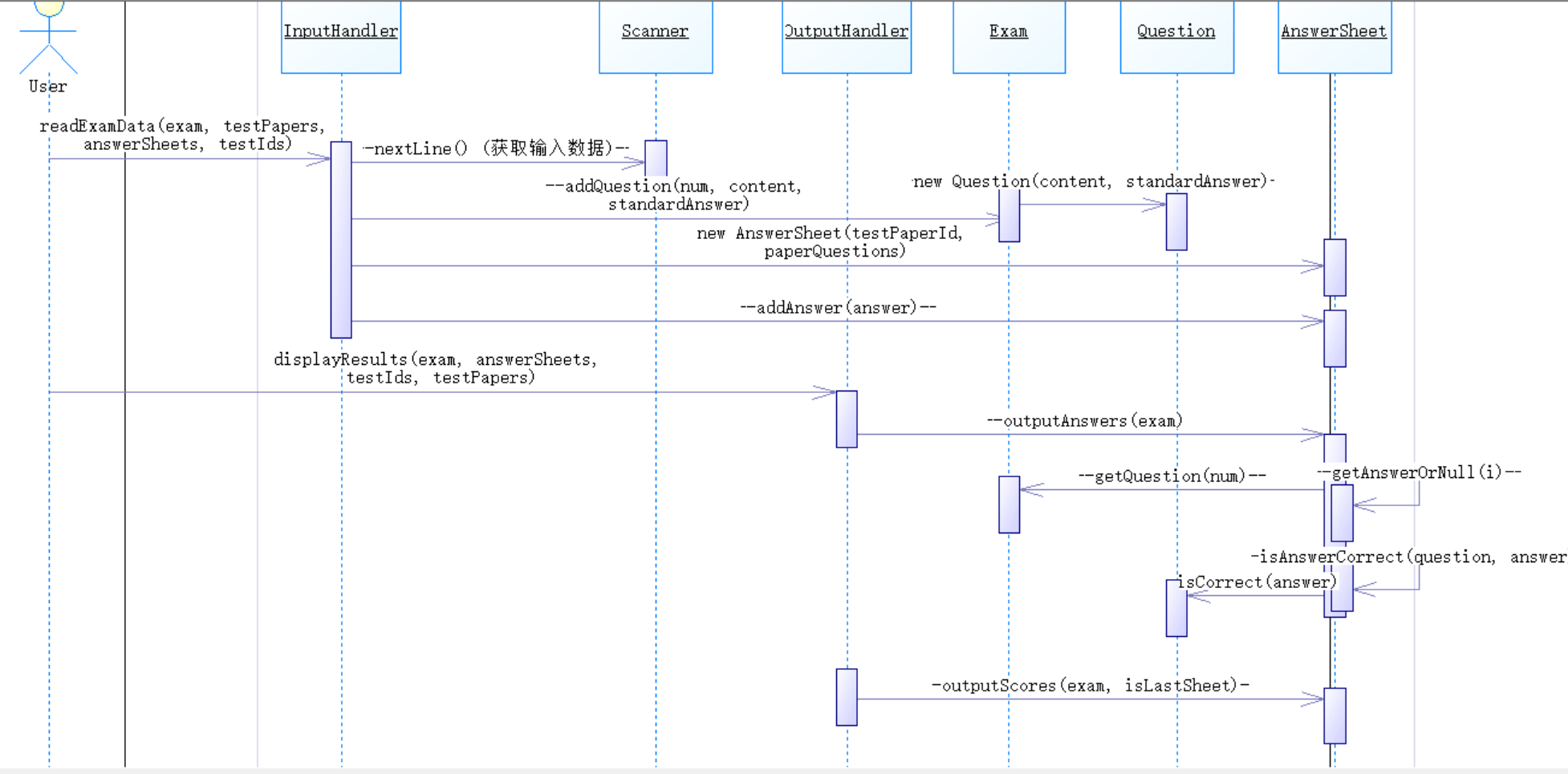
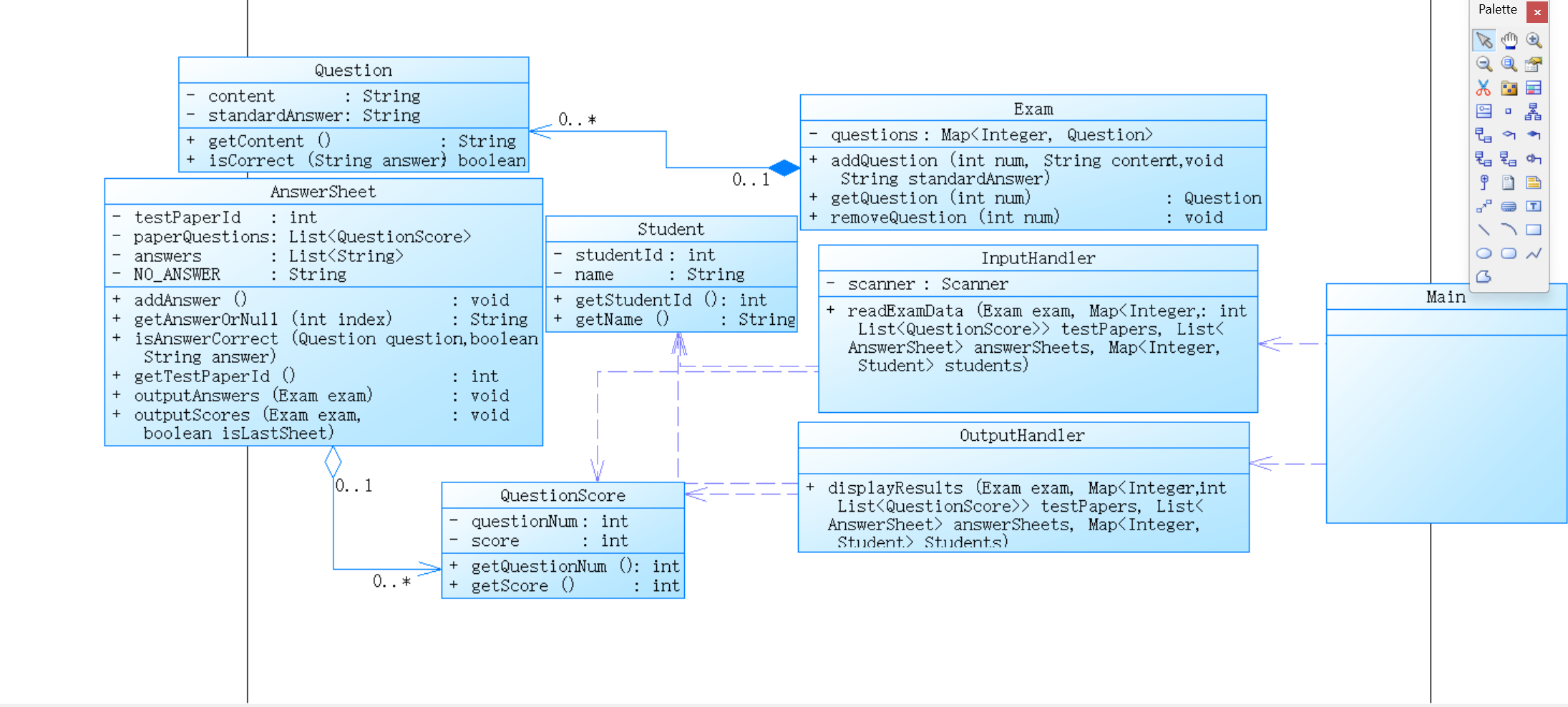
3、答題判題程序3
(1)Main 類:
依賴于 InputHandler 和 OutputHandler 來處理輸入和輸出。
Exam、AnswerSheet、Student、QuestionScore 等類是整個系統(tǒng)的數(shù)據(jù)實體。
(2)InputHandler 類:
依賴關(guān)系:
InputHandler 類依賴于 Scanner 用來讀取輸入。
InputHandler 類依賴于 Exam、AnswerSheet、QuestionScore、Student 等對象,將輸入數(shù)據(jù)解析后存儲到對應(yīng)的類中。
關(guān)聯(lián)關(guān)系:
InputHandler 將學(xué)生信息、題目信息、試卷信息和答卷信息組織起來,關(guān)聯(lián)到相應(yīng)的實體類上。
(3)OutputHandler 類:
依賴關(guān)系:
依賴于 Exam、AnswerSheet、Student 等類來輸出答卷信息和成績。
關(guān)聯(lián)關(guān)系:
OutputHandler 類通過與 AnswerSheet 和 Student 類的關(guān)聯(lián),輸出每個學(xué)生的答卷結(jié)果和成績。
(4)Exam 類:
組合關(guān)系:
Exam 組合了多個 Question 對象,表示每場考試由多個題目組成。
Exam 負責(zé)題目的管理(添加題目、刪除題目等)。
依賴關(guān)系:
Exam 依賴于 Question 類來存儲和管理每個題目的內(nèi)容和標準答案。
(5)AnswerSheet 類:
關(guān)聯(lián)關(guān)系:
每個 AnswerSheet 與多個 QuestionScore 相關(guān)聯(lián),表示某張試卷的題目及其對應(yīng)分數(shù)。
依賴關(guān)系:
AnswerSheet 依賴于 Exam 類來判斷題目的正確與否,并計算分數(shù)。
AnswerSheet 也依賴于 Student 類來與學(xué)生信息關(guān)聯(lián)。
組合關(guān)系:
AnswerSheet 組合了一個 answers Map 用于存儲題目編號和對應(yīng)的學(xué)生答案。
(6)Question 類:
關(guān)聯(lián)關(guān)系:
Question 與 Exam 是一個關(guān)聯(lián)關(guān)系,表示 Exam 管理著一系列 Question。
(7)Student 類:
關(guān)聯(lián)關(guān)系:
Student 類與 AnswerSheet 類通過學(xué)生的答卷信息相關(guān)聯(lián)。
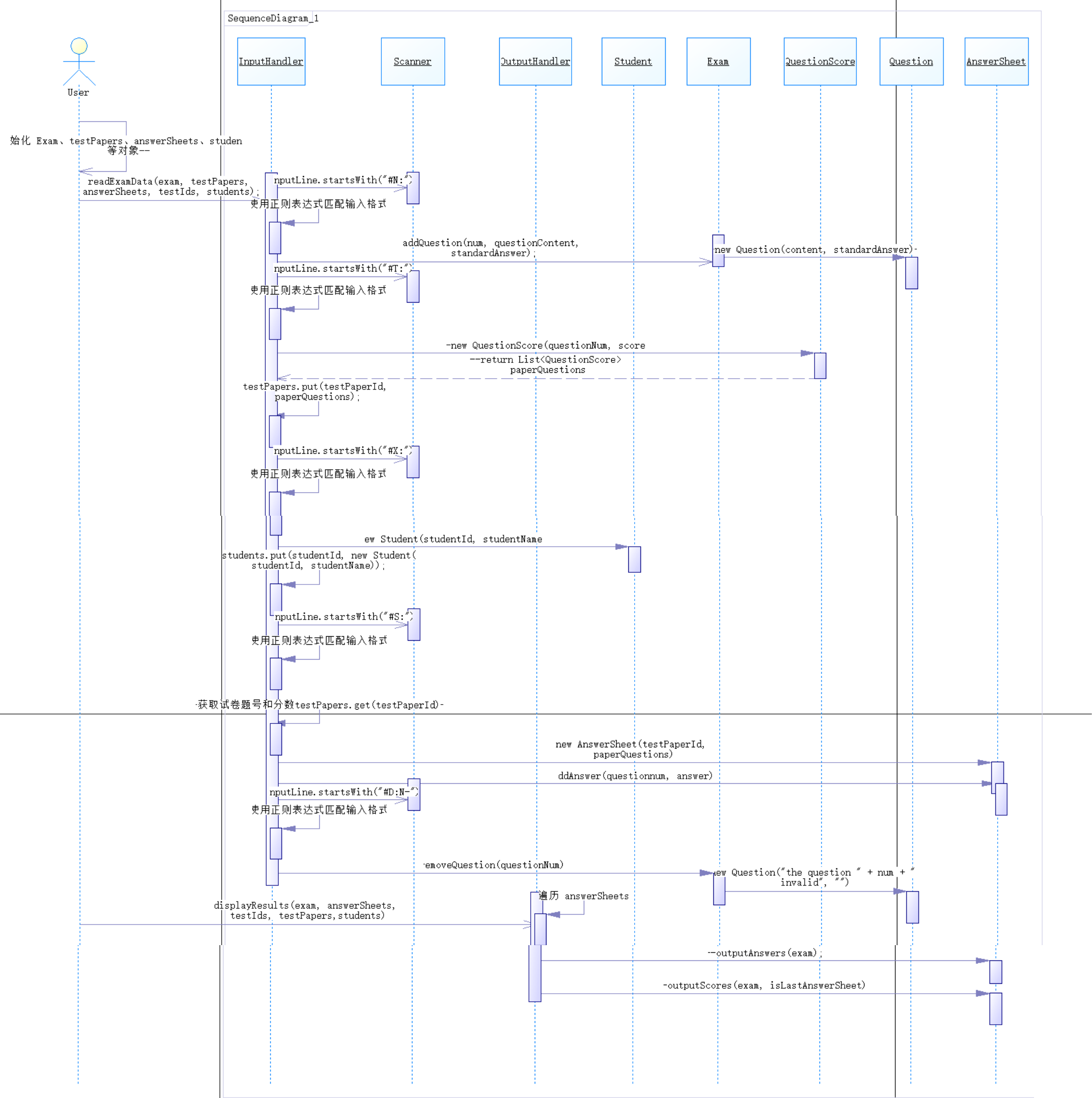
根據(jù)各類之間的關(guān)系設(shè)計了以下順序圖:
2.1.2 源碼分析與復(fù)雜度評估
復(fù)雜度小結(jié)
圈復(fù)雜度:InputHandler和AnswerSheet這兩個類的圈復(fù)雜度較高,因為它們包含了較多條件判斷和循環(huán)。
職責(zé)分工:總體來說職責(zé)劃分清晰,但InputHandler類做的事情有點多。
可讀性:InputHandler類使用了大量的正則表達式和條件判斷,對新讀代碼的人來說稍顯復(fù)雜。
擴展性:要是未來加新題型或答題格式,估計要改InputHandler,因為它一個方法中處理了很多功能。
2.1.3 提交源碼的設(shè)計與分析
這里只詳細針對答題判題程序3來進行解析,因為他在前兩題的基礎(chǔ)上增加了功能,這樣也能突出其他兩題在設(shè)計上的相似之處。
這個 Java 程序的核心目的是能處理題庫、試卷、學(xué)生信息和他們的答卷,還能算出每個學(xué)生的得分。系統(tǒng)主要通過解析輸入字符串來存儲這些信息,并在最后輸出學(xué)生的成績。代碼結(jié)構(gòu)分成幾個部分,具體來說:
主類 Main:主要負責(zé)初始化各類數(shù)據(jù)結(jié)構(gòu),啟動輸入和輸出處理。
輸入處理類 InputHandler**:用來解析輸入字符串,識別不同的標識符(比如 #N: 表示題目,#T: 表示試卷)并存儲數(shù)據(jù)。
// 解析題目信息if (inputLine.startsWith("#N:")) { Pattern questionPattern = Pattern.compile("#N:(\\d+)\\s+(?::(#Q:(.+?))\\s+#A:(.+?))"); Matcher matcher = questionPattern.matcher(inputLine);
// 解析試卷信息 else if (inputLine.startsWith("#T:")) { Pattern testPattern = Pattern.compile("#T:(\\d+) ((\\d+-\\d+ ?)+)"); Matcher matcher = testPattern.matcher(inputLine);
// 解析學(xué)生信息 else if (inputLine.startsWith("#X:")) { Pattern studentPattern = Pattern.compile("#X:(.+)"); Matcher matcher = studentPattern.matcher(inputLine);
// 解析答卷信息 else if (inputLine.startsWith("#S:")) { Pattern answerPattern = Pattern.compile("#S:(\\d+) (\\d+)( (#A:\\d+-.+)*)*"); Matcher matcher = answerPattern.matcher(inputLine);
// 解析刪除題目信息 else if (inputLine.startsWith("#D:N-")) { Pattern deletePattern = Pattern.compile("#D:N-(\\d+)"); Matcher matcher = deletePattern.matcher(inputLine);
輸出處理類 OutputHandler:根據(jù)題目信息、答卷和評分標準,輸出每個學(xué)生的答題情況和總分。
點擊查看代碼
// 遍歷所有答卷,并輸出答案和分數(shù)
int flag = 1;
for (Map.Entry<Integer, List<AnswerSheet>> entry : answerSheets.entrySet()) {
int studentId = entry.getKey();
List<AnswerSheet> studentAnswerSheets = entry.getValue();
Student student = students.get(studentId);
for (AnswerSheet answerSheet : studentAnswerSheets) {
int testPaperId = answerSheet.getTestPaperId();
// 檢查 testPaperId 是否存在于 testPapers
if (!testPapers.containsKey(testPaperId)) {
System.out.println("The test paper number does not exist");
continue; // 跳過不存在的試卷
}
// 輸出答卷的答案和分數(shù)
answerSheet.outputAnswers(exam);
if (student == null) {
System.out.println(studentId + " not found");
continue;
}
if (flag == 1){
System.out.print(studentId + " " + student.getName() + ": ");
flag ++;
}
boolean isLastAnswerSheet = answerSheet == studentAnswerSheets.get(studentAnswerSheets.size() - 1);
answerSheet.outputScores(exam, isLastAnswerSheet);
}
}
其他核心類:包括 Exam、Question、QuestionScore、AnswerSheet 和 Student,它們分別代表題庫、單個題目、題目分數(shù)、答卷和學(xué)生信息。
程序有幾個關(guān)鍵設(shè)計
正則表達式解析輸入數(shù)據(jù):InputHandler 用正則表達式識別不同類型的數(shù)據(jù)輸入,但復(fù)雜的正則解析可能會影響性能。
數(shù)據(jù)映射:使用了 Map 和 List 來管理題目、試卷和學(xué)生答卷信息,方便通過題號、試卷號快速找到相應(yīng)數(shù)據(jù)。
答題和評分邏輯:AnswerSheet 里有方法負責(zé)輸出題目答題情況和評分,評分會根據(jù)是否答對來計算得分。
優(yōu)化建議
優(yōu)化正則表達式:可以分解復(fù)雜的正則解析,提升代碼可讀性。
答卷映射改進:可以考慮優(yōu)化 AnswerSheet 中的答題號獲取方式,避免出現(xiàn)題號偏移的錯誤。
評分和輸出邏輯抽象:可以把評分和輸出邏輯抽到一個專門的類里,比如 ScoreCalculator,讓 AnswerSheet 只關(guān)注答卷數(shù)據(jù),代碼結(jié)構(gòu)更清晰。
設(shè)計思路
模塊化和解耦:通過輸入和輸出的分離,降低了主類的復(fù)雜性,并將題目、試卷和答卷分別封裝成不同類,符合單一職責(zé)原則。
異常處理:當(dāng)前程序的異常處理較簡單,可以針對不同錯誤給出更具體的提示,提升用戶體驗。
- 采坑心得
3.1 源碼提交過程中的問題
3.1.1 編譯和運行問題
遇到的問題:提交代碼的時候,有時會出現(xiàn)編譯報錯或者運行時崩潰的情況,常見的就是輸入時為匹配正確的格式或者變量未能正確的進行傳參和被使用,導(dǎo)致提交中提示非零返回。還有輸入順序可能影響程序的正常運行,在輸入順序為亂序時,程序應(yīng)能正確處理題號和對應(yīng)的題目跟答案將這些存入Map或者List數(shù)組中。
一些具體例子:
比如正則表達式?jīng)]有設(shè)計好,導(dǎo)致錯誤內(nèi)容被錯誤接收并處理;
還有對于未出現(xiàn)的試卷Id要進行統(tǒng)一處理這和處理按輸入順序處理的答卷信息一樣在OuputHandler類中進行處理。
// 檢查 testPaperId 是否存在于 testPapers if (!testPapers.containsKey(testPaperId)) { System.out.println("The test paper number does not exist"); continue; // 跳過不存在的試卷 }
3.1.2 正確性與邏輯錯誤
問題描述:還有一些邏輯上的小錯誤,比如評分的時候,沒有處理題目被刪除的情況,導(dǎo)致得分不對。
如何解決:
通過單步調(diào)試找到問題,然后在評分邏輯里加入題目有效性的檢查,保證只有有效題目才能計分。
優(yōu)化后的代碼:通過引入一個題目檢查的方法來判斷題目是否有效,解決了錯誤計分的問題。
- 改進建議
4.1. 代碼重構(gòu)和模塊化
- 提取公共方法:OutputHandler 和 InputHandler 中有很多重復(fù)的代碼,比如字符串解析和驗證,可以把這些重復(fù)的邏輯提取到一個公共方法里,方便以后改動時一處改動,全局生效。
- 優(yōu)化錯誤處理:現(xiàn)在的 try-catch 塊有點冗長。可以把錯誤處理的邏輯封裝到一個獨立的類,這樣 readExamData 方法的邏輯會更清晰。
- 引入業(yè)務(wù)邏輯層:可以把主要的業(yè)務(wù)邏輯分離出來,比如創(chuàng)建 ExamService 和 StudentService 類,把考試和學(xué)生管理的邏輯從 Exam、Student、AnswerSheet 等類中抽離,這樣代碼更容易理解和維護。
4.2. 增強數(shù)據(jù)的可擴展性
- 使用枚舉代替字符串常量:現(xiàn)在代碼里用到很多固定字符串,比如 #N:、#T: 等。可以用枚舉來代替,減少硬編碼的字符串,這樣要擴展時也更靈活。
- 改進數(shù)據(jù)存儲結(jié)構(gòu):如果需要處理大量試卷或答卷,HashMap 可能不夠用。可以考慮用數(shù)據(jù)庫存儲數(shù)據(jù),這樣查詢和數(shù)據(jù)管理會更方便。
4.3. 改進正則表達式處理
- 增強正則的健壯性:正則匹配可能出錯,可以考慮用一個正則解析器類來集中管理所有正則邏輯。這樣出錯時能有清晰的提示。
- 簡化正則結(jié)構(gòu):可以分步驟匹配,減少正則表達式的復(fù)雜性和出錯率。
4.4. 提升代碼的可讀性
- 使用流式 API 和 Optional:Java 的 Stream API 和 Optional 可以讓代碼更簡潔,比如在 outputScores 里用 Stream 來計算總分,代碼會更簡潔。
- 優(yōu)化控制結(jié)構(gòu):檢查行首前綴時,switch 語句比一堆 if-else 更清晰,也更高效。
4.5. 多態(tài)和接口使用
- 接口隔離職責(zé):可以為 OutputHandler 和 InputHandler 定義接口,讓它們的功能更通用。比如,用 DataParser 接口處理數(shù)據(jù)解析,這樣如果輸入格式有變化,只需要實現(xiàn)新的解析類,不需要改原有代碼。
- 繼承和多態(tài):可以創(chuàng)建不同類型的 Question 類,比如 SingleChoiceQuestion 和 EssayQuestion,來支持不同題型,增強系統(tǒng)的擴展性。
4.6. 提升測試和維護便利性
- 增加測試覆蓋率:可以寫單元測試來驗證每個類和方法的行為,比如 InputHandler 處理的各種輸入類型,這樣能更快發(fā)現(xiàn)錯誤,提高代碼質(zhì)量。
- 添加注釋和文檔:在關(guān)鍵代碼處添加注釋,特別是解釋特定輸入格式和復(fù)雜邏輯的地方,這樣以后維護或團隊協(xié)作時更容易理解。
4.7. 優(yōu)化性能
- 惰性加載:對于數(shù)據(jù)量較大的 questions、testPapers 等,可以只在需要時才加載,避免不必要的內(nèi)存占用。
- 并行處理:如果有大量的答卷,可以用并行流處理評分輸出 (outputAnswers 和 outputScores),這樣速度會更快。
- 總結(jié)
5.1 本階段的知識總結(jié)
算法和數(shù)據(jù)結(jié)構(gòu):加深了對 HashMap、ArrayList 等數(shù)據(jù)結(jié)構(gòu)的理解,并學(xué)會了在不同場景下如何選擇和應(yīng)用它們。另外,像排序、查找和字符串解析這些基礎(chǔ)算法也都有練習(xí),幫助我們慢慢建立算法的思維方式。
面向?qū)ο笤O(shè)計:通過實踐面向?qū)ο缶幊蹋莆樟讼穹庋b、繼承和多態(tài)這些核心概念。比如,在題庫管理系統(tǒng)的代碼中,我們學(xué)會了如何把題目、學(xué)生、試卷等不同角色分成獨立的類,這樣設(shè)計讓代碼結(jié)構(gòu)更清晰,也更好維護。
問題分析和代碼優(yōu)化:練習(xí)了如何把復(fù)雜的問題分解成更小的步驟來解決。學(xué)會了基本的代碼優(yōu)化技巧,比如消除重復(fù)代碼、提取公共方法、簡化邏輯結(jié)構(gòu)等,讓代碼更簡潔高效。
效率提升:也接觸到了基本的性能優(yōu)化,認識到如何通過選擇合適的數(shù)據(jù)結(jié)構(gòu)和算法來提升代碼的執(zhí)行速度。
5.2 未來學(xué)習(xí)方向
高級算法和數(shù)據(jù)結(jié)構(gòu):進一步了解像圖、堆、樹這樣的高級數(shù)據(jù)結(jié)構(gòu),以及動態(tài)規(guī)劃、貪心算法等復(fù)雜的算法技巧,這些有助于我們解決更難的問題。
性能優(yōu)化和并行計算:學(xué)習(xí)如何通過多線程和并行計算來加快代碼的運行速度,比如學(xué)會使用惰性加載和并行流等優(yōu)化方法,適應(yīng)更大規(guī)模的數(shù)據(jù)需求。
設(shè)計模式:可以多學(xué)一些常見的設(shè)計模式,比如工廠模式、觀察者模式、單例模式等等,提升代碼的復(fù)用性、擴展性和可維護性。
測試和代碼質(zhì)量:多學(xué)習(xí)不同的測試方法,包括單元測試和集成測試等,確保代碼的穩(wěn)定性和質(zhì)量。
5.3 對教師、課程、作業(yè)及組織方式的建議
教學(xué)方式:希望增加項目實踐和小組討論的機會,這樣能更好地幫助大家在實際操作中鞏固知識。還可以多分享一些代碼范例和完整項目,讓大家能更好地理解知識點的應(yīng)用。
作業(yè)難度:作業(yè)難度可以分為基礎(chǔ)和進階兩部分,基礎(chǔ)的用于鞏固課堂知識,進階的讓大家有更多的空間思考和探索,不同水平的同學(xué)都能有適合的任務(wù)。
課下資源:建議可以提供更多的在線學(xué)習(xí)資源,比如一些編程學(xué)習(xí)網(wǎng)站和技術(shù)文檔,幫助大家在課后有更多的自學(xué)途徑。

 浙公網(wǎng)安備 33010602011771號
浙公網(wǎng)安備 33010602011771號