

| 博客班級 | https://edu.cnblogs.com/campus/fzzcxy/2018CS |
| ---- | ---- | ---- |
| 作業要求 | https://edu.cnblogs.com/campus/fzzcxy/2018CS/homework/11732 |
| 作業目標 | 爬取《在一起》的所有評論,分詞處理后制作出詞云圖 |
| 作業源代碼 | https://github.com/zoeisred/first-personal-work |
| 學號 | 211806148 |
時間記錄
| 步驟 | 具體操作 | 花費時間 |
|---|---|---|
| 1. 進行數據采集 | 編寫代碼爬取當前時間的所有評論 | 4h |
| 2.數據處理 | 將爬取的評論jiebe分詞處理保存到comment.json文件 | 3h |
| 3.數據分析 | 將提取出的信息制作成詞云圖 | 2h |
| 4.上傳代碼 | 將代碼上傳到GitHub | 1h |
| 一、爬取《在一起》評論數據 | ||
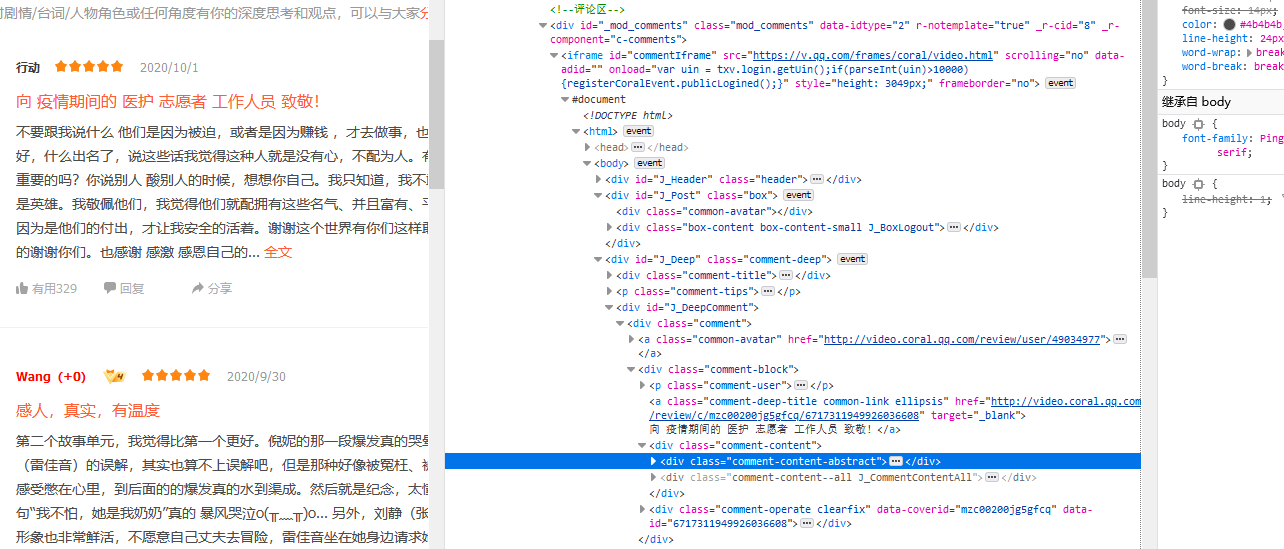
| 在開頭爬取數據就遇到困難,之前學的爬蟲知識有一些模糊了,于是花了幾個小時去復習了正則表達和異步加載的知識,底子比較薄,花了大把時間復習鞏固。 | ||
 |
||
 |
||
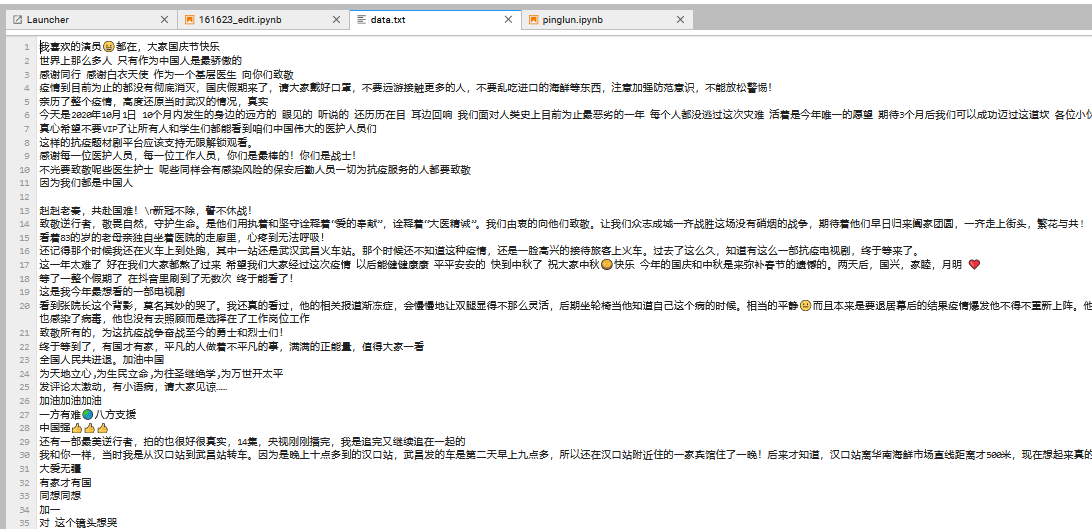
| 爬取的評論 | ||
 |
||
| 然后數據處理jieba分詞,pip install jieba 安裝庫, | ||
 |
||
| 二.數據可視化 | ||
| 下載完echarts.js和echarts-wordcloud.js之后處理完之后圖片:這塊內容是完全沒有接觸到過的,所以上手很慢,也去問了好多同學。 | ||
 |
||
| 上傳代碼 | ||
 |
||
 |
||
 |
||
 |
||
 |
||
| 結果 | ||
 |
·作業感想
此次作業有兩題,第一題爬蟲就讓我覺得有難度了,分析題目查閱資料了解相關知識后開剛,這次作業還是比較難的,花費了很多時間,但現在做完想想也覺得值得,在這個過程中學到了很多的東西,也清楚自身知識儲備很不足,尤其在github的使用方面,有點小白,在今后應該更加認真的學習,學無止境。
·參考資料
https://www.liaoxuefeng.com/wiki/896043488029600

 浙公網安備 33010602011771號
浙公網安備 33010602011771號