
Redis能抗住百萬(wàn)并發(fā)的秘密
前言
今天想和大家深入聊聊Redis為什么能夠輕松抗住百萬(wàn)級(jí)別的并發(fā)請(qǐng)求。
有些小伙伴在工作中可能遇到過(guò)這樣的場(chǎng)景:系統(tǒng)訪問(wèn)量一上來(lái),數(shù)據(jù)庫(kù)就扛不住了,這時(shí)候大家第一時(shí)間想到的就是Redis。
但你有沒(méi)有想過(guò),為什么Redis能夠承受如此高的并發(fā)量?它的底層到底做了什么優(yōu)化?
今天我們就從淺入深,一步步揭開(kāi)Redis高性能的神秘面紗。
1. Redis高并發(fā)的核心架構(gòu)
1.1 單線程模型的威力
有些小伙伴可能會(huì)疑惑:Redis是單線程的,為什么還能支持這么高的并發(fā)?
這里需要澄清一個(gè)概念,Redis的"單線程"指的是網(wǎng)絡(luò)IO和鍵值對(duì)讀寫(xiě)是由一個(gè)線程來(lái)完成的,但Redis的整個(gè)系統(tǒng)并不是只有一個(gè)線程。
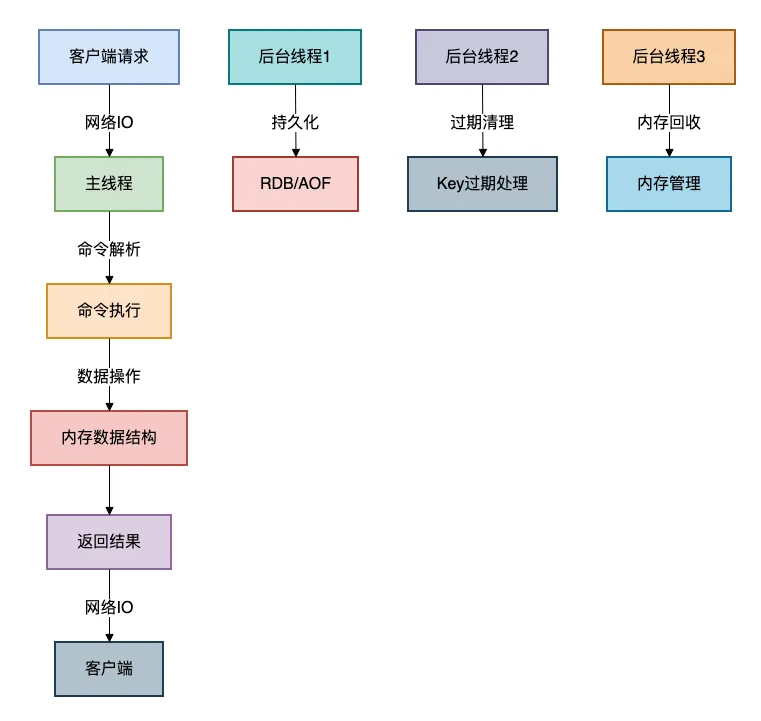
為什么單線程反而更快?
-
避免了線程切換的開(kāi)銷(xiāo):多線程環(huán)境下,CPU需要在不同線程間切換,這個(gè)過(guò)程需要保存和恢復(fù)線程上下文,開(kāi)銷(xiāo)很大。
-
避免了鎖競(jìng)爭(zhēng):?jiǎn)尉€程模型下,不需要考慮線程安全問(wèn)題,避免了各種鎖的開(kāi)銷(xiāo)。
-
CPU緩存友好:?jiǎn)尉€程執(zhí)行時(shí),CPU緩存命中率更高,減少了內(nèi)存訪問(wèn)延遲。
讓我們看一個(gè)簡(jiǎn)單的對(duì)比:
// 多線程模式下的偽代碼
public class MultiThreadRedis {
private final Object lock = new Object();
private Map<String, String> data = new HashMap<>();
public String get(String key) {
synchronized(lock) { // 需要加鎖
return data.get(key);
}
}
public void set(String key, String value) {
synchronized(lock) { // 需要加鎖
data.put(key, value);
}
}
}
// Redis單線程模式下的偽代碼
public class SingleThreadRedis {
private Map<String, String> data = new HashMap<>();
public String get(String key) {
return data.get(key); // 無(wú)需加鎖
}
public void set(String key, String value) {
data.put(key, value); // 無(wú)需加鎖
}
}
1.2 事件驅(qū)動(dòng)模型
Redis采用了事件驅(qū)動(dòng)的架構(gòu),基于Reactor模式實(shí)現(xiàn)。
這種模式的核心思想是:用一個(gè)線程來(lái)處理多個(gè)連接的IO事件。
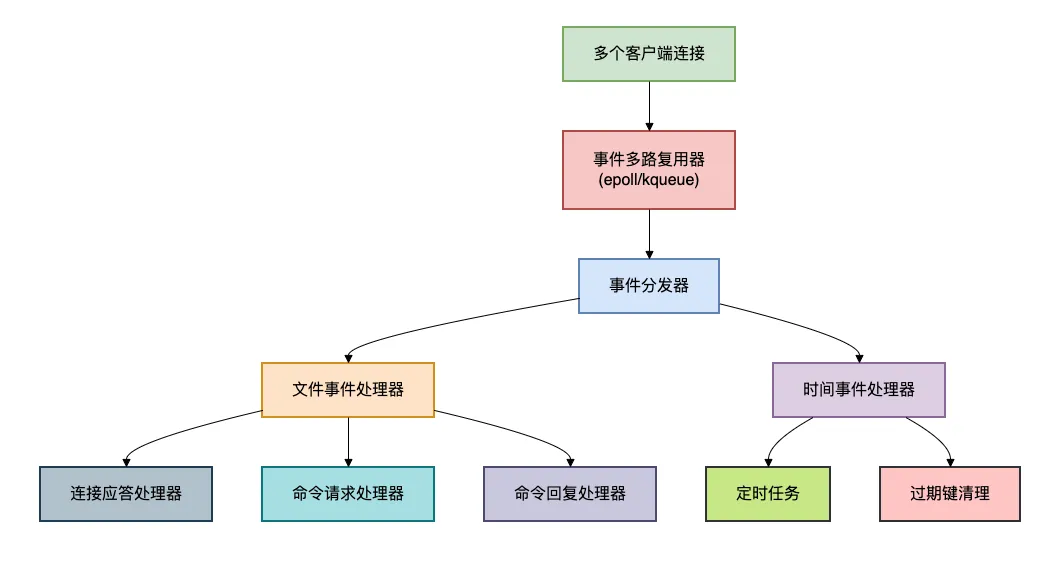
事件驅(qū)動(dòng)的優(yōu)勢(shì):
- 高效的IO多路復(fù)用:一個(gè)線程可以同時(shí)監(jiān)聽(tīng)多個(gè)socket連接
- 非阻塞IO:不會(huì)因?yàn)槟硞€(gè)連接的IO操作而阻塞整個(gè)程序
- 內(nèi)存占用少:相比多線程模型,節(jié)省了大量線程棧空間
2. 內(nèi)存數(shù)據(jù)結(jié)構(gòu)的極致優(yōu)化
2.1 高效的數(shù)據(jù)結(jié)構(gòu)設(shè)計(jì)
Redis的高性能很大程度上得益于其精心設(shè)計(jì)的內(nèi)存數(shù)據(jù)結(jié)構(gòu)。
每種數(shù)據(jù)類(lèi)型都有多種底層實(shí)現(xiàn),Redis會(huì)根據(jù)數(shù)據(jù)的特點(diǎn)自動(dòng)選擇最優(yōu)的存儲(chǔ)方式。

讓我們深入了解幾個(gè)關(guān)鍵的數(shù)據(jù)結(jié)構(gòu):
2.1.1 SDS (Simple Dynamic String)
有些小伙伴可能不知道,Redis并沒(méi)有直接使用C語(yǔ)言的字符串,而是自己實(shí)現(xiàn)了SDS。
// Redis SDS結(jié)構(gòu)
struct sdshdr {
int len; // 字符串長(zhǎng)度
int free; // 未使用空間長(zhǎng)度
char buf[]; // 字符串內(nèi)容
};
SDS的優(yōu)勢(shì):
- O(1)時(shí)間復(fù)雜度獲取長(zhǎng)度:直接讀取len字段
- 預(yù)分配空間:減少內(nèi)存重新分配次數(shù)
- 二進(jìn)制安全:可以存儲(chǔ)任意二進(jìn)制數(shù)據(jù)
- 兼容C字符串函數(shù):以空字符結(jié)尾
2.1.2 跳躍表 (Skip List)
跳躍表是Redis中有序集合的核心數(shù)據(jù)結(jié)構(gòu),它的查找效率可以達(dá)到O(log N)。
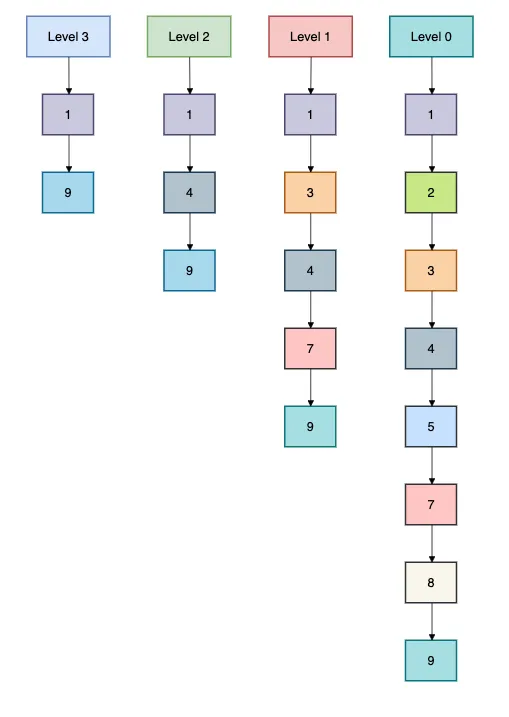
跳躍表的查找過(guò)程:
// 跳躍表查找偽代碼
public Node search(int target) {
Node current = header;
// 從最高層開(kāi)始查找
for (int level = maxLevel; level >= 0; level--) {
// 在當(dāng)前層向右移動(dòng),直到下一個(gè)節(jié)點(diǎn)大于目標(biāo)值
while (current.forward[level] != null &&
current.forward[level].value < target) {
current = current.forward[level];
}
}
// 移動(dòng)到下一個(gè)節(jié)點(diǎn)
current = current.forward[0];
if (current != null && current.value == target) {
return current;
}
return null;
}
2.2 內(nèi)存優(yōu)化策略
2.2.1 壓縮列表 (ziplist)
當(dāng)Hash、List、ZSet的元素較少時(shí),Redis會(huì)使用壓縮列表來(lái)節(jié)省內(nèi)存。

壓縮列表的優(yōu)勢(shì):
- 內(nèi)存緊湊:所有元素連續(xù)存儲(chǔ),減少內(nèi)存碎片
- 緩存友好:連續(xù)內(nèi)存訪問(wèn),CPU緩存命中率高
- 節(jié)省指針開(kāi)銷(xiāo):不需要存儲(chǔ)指向下一個(gè)元素的指針
2.2.2 整數(shù)集合 (intset)
當(dāng)Set中只包含整數(shù)元素時(shí),Redis使用整數(shù)集合來(lái)存儲(chǔ)。
// 整數(shù)集合結(jié)構(gòu)
typedef struct intset {
uint32_t encoding; // 編碼方式
uint32_t length; // 元素?cái)?shù)量
int8_t contents[]; // 元素?cái)?shù)組
} intset;
編碼方式自動(dòng)升級(jí):
// 整數(shù)集合編碼升級(jí)示例
public class IntSetExample {
// 初始狀態(tài):所有元素都是16位整數(shù)
// encoding = INTSET_ENC_INT16
// contents = [1, 2, 3, 4, 5]
// 添加一個(gè)32位整數(shù)
public void addLargeNumber() {
// 自動(dòng)升級(jí)為32位編碼
// encoding = INTSET_ENC_INT32
// 重新分配內(nèi)存,轉(zhuǎn)換所有現(xiàn)有元素
}
}
3. 網(wǎng)絡(luò)IO優(yōu)化
3.1 IO多路復(fù)用技術(shù)
Redis在不同操作系統(tǒng)上使用不同的IO多路復(fù)用技術(shù):
- Linux: epoll
- macOS/FreeBSD: kqueue
- Windows: select

epoll的優(yōu)勢(shì):
- 事件驅(qū)動(dòng):只有當(dāng)socket有事件時(shí)才會(huì)通知應(yīng)用程序
- 高效輪詢:不需要遍歷所有文件描述符
- 支持邊緣觸發(fā):減少系統(tǒng)調(diào)用次數(shù)
3.2 客戶端輸出緩沖區(qū)
Redis為每個(gè)客戶端維護(hù)輸出緩沖區(qū),避免慢客戶端影響整體性能。
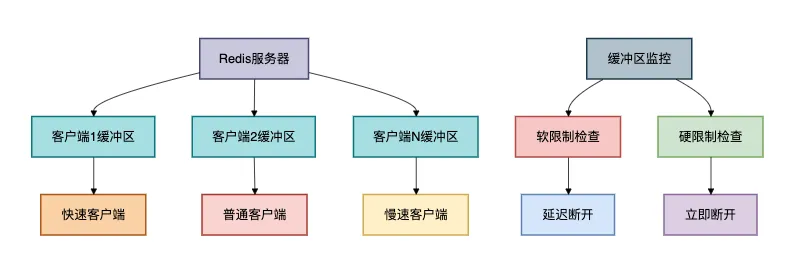
緩沖區(qū)配置示例:
# redis.conf配置
# 普通客戶端緩沖區(qū)限制
client-output-buffer-limit normal 0 0 0
# 從服務(wù)器緩沖區(qū)限制
client-output-buffer-limit replica 256mb 64mb 60
# 發(fā)布訂閱客戶端緩沖區(qū)限制
client-output-buffer-limit pubsub 32mb 8mb 60
4. 內(nèi)存管理優(yōu)化
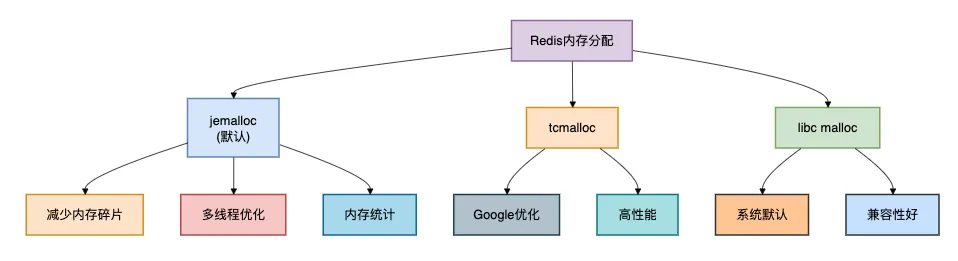
4.1 內(nèi)存分配器選擇
Redis支持多種內(nèi)存分配器,默認(rèn)使用jemalloc,這是一個(gè)專(zhuān)門(mén)為多線程應(yīng)用優(yōu)化的內(nèi)存分配器。
4.2 過(guò)期鍵刪除策略
Redis采用惰性刪除和定期刪除相結(jié)合的策略來(lái)處理過(guò)期鍵。
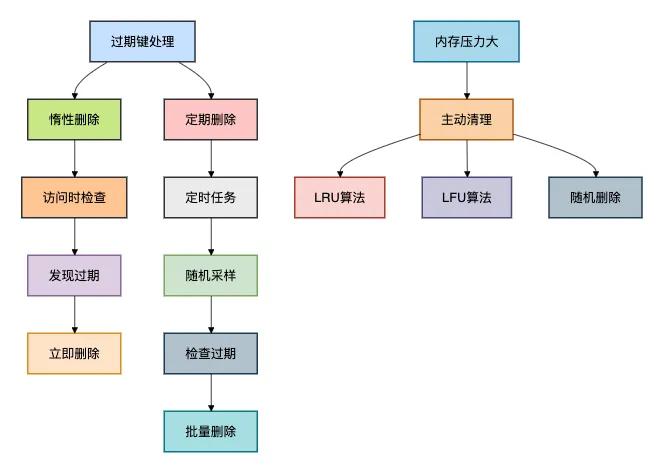
定期刪除算法:
// Redis定期刪除偽代碼
public void activeExpireCycle() {
int maxIterations = 16; // 最大檢查數(shù)據(jù)庫(kù)數(shù)
int maxChecks = 20; // 每個(gè)數(shù)據(jù)庫(kù)最大檢查鍵數(shù)
for (int i = 0; i < maxIterations; i++) {
RedisDb db = server.db[i];
int expired = 0;
for (int j = 0; j < maxChecks; j++) {
String key = db.expires.randomKey();
if (key != null && isExpired(key)) {
deleteKey(key);
expired++;
}
}
// 如果過(guò)期鍵比例小于25%,跳出循環(huán)
if (expired < maxChecks / 4) {
break;
}
}
}
5. 持久化優(yōu)化
5.1 RDB持久化
RDB是Redis的默認(rèn)持久化方式,它會(huì)在指定的時(shí)間間隔內(nèi)生成數(shù)據(jù)集的時(shí)點(diǎn)快照。
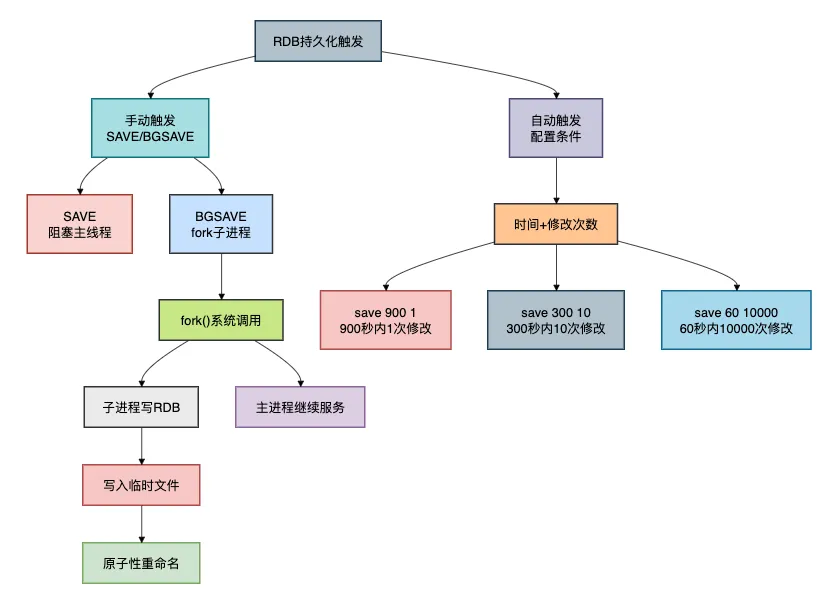
RDB的優(yōu)勢(shì):
- 緊湊的文件格式:適合備份和災(zāi)難恢復(fù)
- 快速重啟:恢復(fù)速度比AOF快
- 對(duì)性能影響小:使用子進(jìn)程進(jìn)行持久化
5.2 AOF持久化
AOF通過(guò)記錄服務(wù)器執(zhí)行的所有寫(xiě)操作命令來(lái)實(shí)現(xiàn)持久化。

AOF重寫(xiě)優(yōu)化:
// AOF重寫(xiě)示例
public class AOFRewrite {
// 原始AOF文件可能包含:
// SET key1 value1
// SET key1 value2
// SET key1 value3
// DEL key2
// SET key2 newvalue
// LPUSH list a
// LPUSH list b
// LPUSH list c
// 重寫(xiě)后的AOF文件:
// SET key1 value3
// SET key2 newvalue
// LPUSH list c b a
public void rewriteAOF() {
// 遍歷所有數(shù)據(jù)庫(kù)
for (RedisDb db : server.databases) {
// 遍歷所有鍵
for (String key : db.dict.keys()) {
Object value = db.dict.get(key);
// 根據(jù)值的類(lèi)型生成對(duì)應(yīng)的命令
generateCommand(key, value);
}
}
}
}
6. 集群和分片優(yōu)化
6.1 Redis Cluster
Redis Cluster是Redis的官方集群解決方案,采用無(wú)中心化的架構(gòu)。

哈希槽分配算法:
public class RedisClusterSlot {
private static final int CLUSTER_SLOTS = 16384;
public int calculateSlot(String key) {
// 檢查是否有哈希標(biāo)簽
int start = key.indexOf('{');
if (start != -1) {
int end = key.indexOf('}', start + 1);
if (end != -1 && end != start + 1) {
key = key.substring(start + 1, end);
}
}
// 計(jì)算CRC16校驗(yàn)和
int crc = crc16(key.getBytes());
return crc % CLUSTER_SLOTS;
}
// CRC16算法實(shí)現(xiàn)
private int crc16(byte[] data) {
int crc = 0x0000;
for (byte b : data) {
crc ^= (b & 0xFF);
for (int i = 0; i < 8; i++) {
if ((crc & 0x0001) != 0) {
crc = (crc >> 1) ^ 0xA001;
} else {
crc = crc >> 1;
}
}
}
return crc & 0xFFFF;
}
}
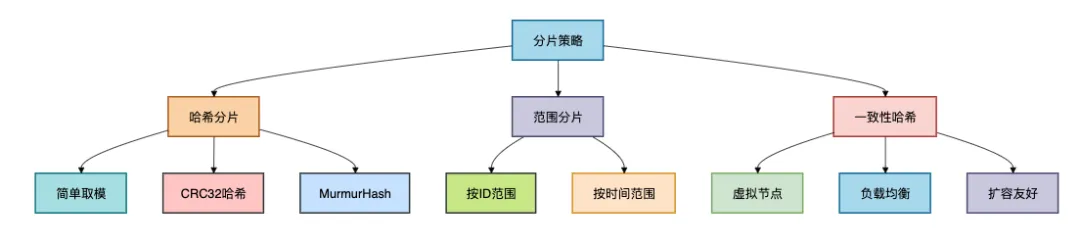
6.2 分片策略
有些小伙伴在設(shè)計(jì)分片策略時(shí),可能會(huì)遇到數(shù)據(jù)傾斜的問(wèn)題。
Redis提供了多種分片方式:
7. 性能監(jiān)控和調(diào)優(yōu)
7.1 關(guān)鍵性能指標(biāo)

性能監(jiān)控命令:
# 查看Redis信息
INFO all
# 監(jiān)控實(shí)時(shí)命令
MONITOR
# 查看慢查詢?nèi)罩?SLOWLOG GET 10
# 查看客戶端連接
CLIENT LIST
# 查看內(nèi)存使用情況
MEMORY USAGE keyname
# 查看延遲統(tǒng)計(jì)
LATENCY LATEST
7.2 性能調(diào)優(yōu)建議
內(nèi)存優(yōu)化:
# redis.conf優(yōu)化配置
# 啟用內(nèi)存壓縮
hash-max-ziplist-entries 512
hash-max-ziplist-value 64
list-max-ziplist-size -2
list-compress-depth 0
set-max-intset-entries 512
zset-max-ziplist-entries 128
zset-max-ziplist-value 64
# 內(nèi)存淘汰策略
maxmemory-policy allkeys-lru
# 啟用內(nèi)存壓縮
rdbcompression yes
網(wǎng)絡(luò)優(yōu)化:
# TCP相關(guān)優(yōu)化
tcp-keepalive 300
tcp-backlog 511
# 客戶端超時(shí)
timeout 0
# 輸出緩沖區(qū)限制
client-output-buffer-limit normal 0 0 0
client-output-buffer-limit replica 256mb 64mb 60
client-output-buffer-limit pubsub 32mb 8mb 60
8. 故障處理和高可用
8.1 故障檢測(cè)機(jī)制

8.2 數(shù)據(jù)一致性保證
主從復(fù)制機(jī)制:
// Redis主從復(fù)制流程
public class RedisReplication {
// 全量同步
public void fullResync() {
// 1. 從服務(wù)器發(fā)送PSYNC命令
// 2. 主服務(wù)器執(zhí)行BGSAVE生成RDB文件
// 3. 主服務(wù)器將RDB文件發(fā)送給從服務(wù)器
// 4. 從服務(wù)器載入RDB文件
// 5. 主服務(wù)器將緩沖區(qū)的寫(xiě)命令發(fā)送給從服務(wù)器
}
// 增量同步
public void partialResync() {
// 1. 從服務(wù)器發(fā)送PSYNC runid offset
// 2. 主服務(wù)器檢查復(fù)制偏移量
// 3. 如果偏移量在復(fù)制積壓緩沖區(qū)內(nèi),執(zhí)行增量同步
// 4. 主服務(wù)器將緩沖區(qū)中的數(shù)據(jù)發(fā)送給從服務(wù)器
}
}
總結(jié)
通過(guò)以上深入分析,我們可以看到Redis能夠抗住10萬(wàn)并發(fā)的核心原因包括:
架構(gòu)層面
- 單線程模型:避免了線程切換和鎖競(jìng)爭(zhēng)的開(kāi)銷(xiāo)
- 事件驅(qū)動(dòng):基于epoll的IO多路復(fù)用,高效處理大量連接
- 內(nèi)存存儲(chǔ):所有數(shù)據(jù)存儲(chǔ)在內(nèi)存中,訪問(wèn)速度極快
數(shù)據(jù)結(jié)構(gòu)層面
- 高效的數(shù)據(jù)結(jié)構(gòu):針對(duì)不同場(chǎng)景優(yōu)化的數(shù)據(jù)結(jié)構(gòu)
- 內(nèi)存優(yōu)化:壓縮列表、整數(shù)集合等節(jié)省內(nèi)存的設(shè)計(jì)
- 智能編碼:根據(jù)數(shù)據(jù)特點(diǎn)自動(dòng)選擇最優(yōu)存儲(chǔ)方式
網(wǎng)絡(luò)層面
- IO多路復(fù)用:?jiǎn)尉€程處理多個(gè)連接
- 客戶端緩沖區(qū):避免慢客戶端影響整體性能
- 協(xié)議優(yōu)化:簡(jiǎn)單高效的RESP協(xié)議
持久化層面
- 異步持久化:不阻塞主線程的持久化機(jī)制
- 多種策略:RDB和AOF滿足不同場(chǎng)景需求
- 增量同步:高效的主從復(fù)制機(jī)制
集群層面
- 水平擴(kuò)展:通過(guò)分片支持更大規(guī)模
- 高可用:主從復(fù)制和故障轉(zhuǎn)移
- 負(fù)載均衡:智能的數(shù)據(jù)分布算法
有些小伙伴在工作中可能會(huì)問(wèn):"既然Redis這么強(qiáng)大,是不是可以完全替代數(shù)據(jù)庫(kù)?"答案是否定的。
Redis更適合作為緩存和高速數(shù)據(jù)存儲(chǔ),而不是主要的數(shù)據(jù)存儲(chǔ)。
正確的做法是將Redis與傳統(tǒng)數(shù)據(jù)庫(kù)結(jié)合使用,發(fā)揮各自的優(yōu)勢(shì)。
最后,要想真正發(fā)揮Redis的性能,不僅要了解其原理,更要在實(shí)際項(xiàng)目中不斷實(shí)踐和優(yōu)化。
希望這篇文章能夠幫助大家更好地理解和使用Redis。
最后說(shuō)一句(求關(guān)注,別白嫖我)
如果這篇文章對(duì)您有所幫助,或者有所啟發(fā)的話,幫忙關(guān)注一下我的同名公眾號(hào):蘇三說(shuō)技術(shù),您的支持是我堅(jiān)持寫(xiě)作最大的動(dòng)力。
求一鍵三連:點(diǎn)贊、轉(zhuǎn)發(fā)、在看。
關(guān)注公眾號(hào):【蘇三說(shuō)技術(shù)】,在公眾號(hào)中回復(fù):進(jìn)大廠,可以免費(fèi)獲取我最近整理的10萬(wàn)字的面試寶典,好多小伙伴靠這個(gè)寶典拿到了多家大廠的offer。
本文收錄于我的技術(shù)網(wǎng)站:http://www.susan.net.cn

 浙公網(wǎng)安備 33010602011771號(hào)
浙公網(wǎng)安備 33010602011771號(hào)