后端思維之高并發(fā)處理方案
我有話想說
這篇文章的構(gòu)思始于2023年,受限于個人經(jīng)驗與知識積累,初稿拖延至2025年1月才最終完成。在此過程中,許多同行大佬慷慨提供了審稿意見與建議,對此我深表感謝。
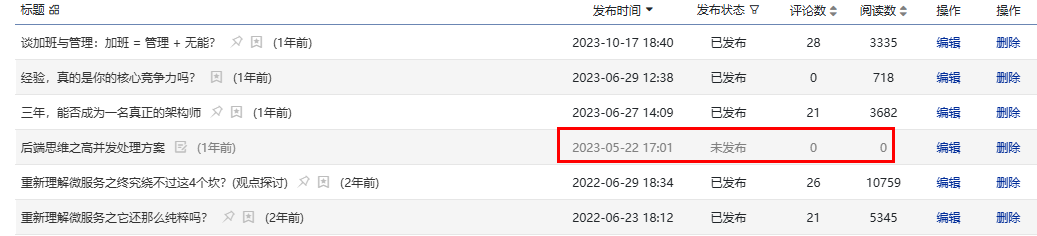
這是接近一篇萬字長文,為方便大家閱讀,我整理了文章的大綱并以思維導(dǎo)圖的形式展示。你可以根據(jù)自己的興趣點選擇性閱讀,希望這篇文章能為你應(yīng)對高并發(fā)場景提供啟發(fā)與幫助。
特別鳴謝:韓楠、王君、杜小非、冼潤偉、李鴻庭(排名不分先后)
前言
在互聯(lián)網(wǎng)時代,高并發(fā)已經(jīng)成為后端開發(fā)者繞不開的話題。無論是電商平臺的秒殺活動、搶購系統(tǒng),還是社交應(yīng)用的高頻互動,高并發(fā)場景的出現(xiàn)往往伴隨著巨大的技術(shù)挑戰(zhàn)。
如何在流量激增的同時,確保系統(tǒng)穩(wěn)定運行、快速響應(yīng)?這不僅是對技術(shù)能力的考驗,更是對架構(gòu)設(shè)計和資源優(yōu)化的綜合考量。
在多年的工作實踐中,我有幸接觸并解決了許多高并發(fā)場景的實際問題。因此,在這篇文章中,我將結(jié)合理論與實踐,深入剖析高并發(fā)的本質(zhì)、應(yīng)對策略,以及實際案例,希望能夠為你揭開高并發(fā)背后的技術(shù)奧秘。
文中提到的高并發(fā)“標(biāo)準(zhǔn)”、三字真言——“砍、緩、多”,以及七大處理手段,均是我在工作中總結(jié)出的經(jīng)驗。這些方法并非涵蓋所有可能的解決方案,但我希望它們能為你提供思路,同時也歡迎大家補(bǔ)充和交流。
什么是高并發(fā)?
百度百科:通俗來講,高并發(fā)是指在同一個時間點,有很多用戶同時訪問同一API接口或者Url地址。它經(jīng)常會發(fā)生在有大活躍用戶量,用戶高聚集的業(yè)務(wù)場景中
簡單的說,高并發(fā)是指系統(tǒng)在同一時間內(nèi)接受到大量的客戶端請求訪問,需要系統(tǒng)(服務(wù)端)能夠快速響應(yīng)并處理請求的能力。在咱們互聯(lián)網(wǎng)應(yīng)用中,例如電商、游戲等在做活動或者促銷的時候,這些熱點業(yè)務(wù)就非常大可能同時被大量用戶訪問,并造成系統(tǒng)較大的負(fù)載。高并發(fā)一般伴隨著數(shù)據(jù)增長、流量增加,這種現(xiàn)象可能是短時間的內(nèi)的峰值,也可能是持續(xù)不斷負(fù)載壓力,因此需要開發(fā)在架構(gòu)設(shè)計、技術(shù)選型、性能監(jiān)控等多個方面進(jìn)行優(yōu)化、調(diào)整以提高系統(tǒng)的并發(fā)處理能力。
并發(fā)與并行的區(qū)別是什么?
并發(fā)和并行都涉及到同一時刻處理多個任務(wù),但它們的概念和實現(xiàn)方式略有不同。
并發(fā),指的是多個事情,在同一時間段內(nèi)同時發(fā)生了。 并行,指的是多個事情,在同一時間點上同時發(fā)生了。
并發(fā),是指一個系統(tǒng)能夠同時處理多個任務(wù)或者請求,并且看起來好像這些任務(wù)是同時執(zhí)行的。實際上,這些任務(wù)只是在最短時間內(nèi)交替執(zhí)行,因為計算機(jī)的處理速度非常快,例如在一個 CPU 上同時運行多個應(yīng)用程序或是處理多個網(wǎng)絡(luò)請求。
并行,是指一個系統(tǒng)可以真正意義上同時處理多個任務(wù)或請求,因為它有多個執(zhí)行單元,可以同時執(zhí)行多個任務(wù)或請求。例如在擁有多個 CPU 或多個核心的服務(wù)器上,可以同時處理多個請求或任務(wù),這就是并行處理。

雖然兩者一字之差,但是我的觀點是,他們屬于不同層面上的概念:
并發(fā)的結(jié)果可能會并行,并發(fā)是一個更廣義的概念,而并行是并發(fā)的一種特殊情況。可以簡單理解為:
- 并發(fā)屬于是表達(dá)了指令發(fā)起端到指令執(zhí)行端的請求情況(系統(tǒng)外部),關(guān)注的是邏輯層面上的“同時性”;
- 并行屬于是描述了系統(tǒng)(應(yīng)用)執(zhí)行任務(wù)時的模式(系統(tǒng)內(nèi)部),關(guān)注的是物理層面上的“同時性”。
因此,并發(fā)不一定會導(dǎo)致并行,但并行一定是并發(fā)的一種結(jié)果體現(xiàn)。
用通俗例子說明,以搶購商品的場景為例:
- 多個 APP 客戶端同時發(fā)起搶購請求,同一時間多端打開商品頁面,這個現(xiàn)象可以稱為并發(fā),因為多個任務(wù)在同一時間段被發(fā)起。
- 隨后,多個客戶端同時查詢商品庫存,由于系統(tǒng)未使用悲觀鎖,這些查詢操作可以在物理層面上同時執(zhí)行,因此這一階段可以看作是并發(fā)導(dǎo)致的并行。
- 接下來,用戶同時點擊【確認(rèn)下單】按鈕,系統(tǒng)進(jìn)入并發(fā)搶購的狀態(tài)。由于庫存需要增減,而操作受到悲觀鎖的約束,導(dǎo)致多個請求無法同時修改庫存。悲觀鎖會鎖住資源,確保每個請求在修改庫存時不會發(fā)生沖突,因此這一階段的請求只能串行執(zhí)行,無法實現(xiàn)并行處理。
高并發(fā)的怎樣才算高?
不同的讀者看到這里的時候,心里都會有一個答案:
- 擁有大項目經(jīng)歷的同行肯定想,沒個幾十萬、上百萬的QPS都不叫高并發(fā)吧?
- 萌新可能認(rèn)為,我平常系統(tǒng)峰值最高就兩三千的 QPS,那么起碼也得高一個量級才算吧?
我是這么認(rèn)為的:
高并發(fā)的高并沒有一個具體的量化標(biāo)準(zhǔn)的,并不是必須得多少個萬級別的 QPS 才算是高,因為【高】在物理學(xué)里是相對的概念。
對于小型的系統(tǒng)或ToB系統(tǒng)來說,如果初期架構(gòu)設(shè)計沒考慮好或者資源有限,幾百上千的 QPS 的并發(fā)訪問可能已經(jīng)會對系統(tǒng)造成一定的壓力;
對于大型互聯(lián)網(wǎng)公司或應(yīng)用,每秒鐘數(shù)萬甚至數(shù)十萬的并發(fā)訪問甚至峰值達(dá)到百萬級這都并不罕見。
因此,在討論高并發(fā)時,我們不必將其想象為極端數(shù)量級的并發(fā)情況。關(guān)鍵在于理解特定業(yè)務(wù)場景下,在何種條件(包括人力、技術(shù)力、計算力)下,為了達(dá)到既定目標(biāo)(如穩(wěn)定性、安全性、用戶體驗)而需要處理的并發(fā)量。
基于這些因素,當(dāng)并發(fā)量達(dá)到一定水平,足以影響這些目標(biāo)時,我們通常將這種情況視為高并發(fā)。這樣的判斷并不僅僅基于并發(fā)量的增加是否達(dá)到了某個具體的“高并發(fā)”標(biāo)準(zhǔn)。
高性能等于高并發(fā)嗎?
首先,高并發(fā)與高性能之間確實存在直接的聯(lián)系。高性能指的是系統(tǒng)或應(yīng)用程序能夠迅速處理單一請求的能力,這意味著在相同的時間內(nèi),一個性能更優(yōu)的系統(tǒng)能夠處理更多的請求,從而提升其并發(fā)處理能力。
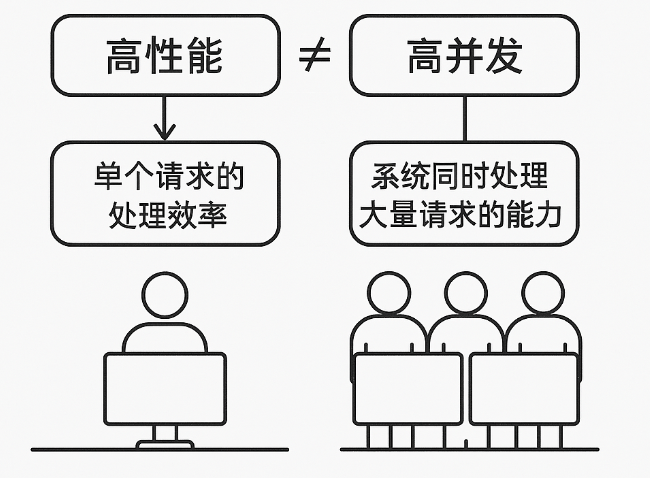
以一個系統(tǒng)接口為例,假設(shè)它在單線程環(huán)境下能夠達(dá)到每秒100次查詢(100QPS),這意味著處理單個請求的時間大約是0.01秒。如果我們將處理速度提升十倍,即每個請求的處理時間縮短到0.001秒,那么理論上的QPS可以提升到1000QPS。這個例子清晰地展示了高性能與高并發(fā)之間的正相關(guān)性。
然而,高性能與高并發(fā)并非完全等同。
- 高性能關(guān)注單個請求的處理效率,
- 高并發(fā)關(guān)注系統(tǒng)同時處理大量請求的能力。
一個系統(tǒng)即使設(shè)計之初就考慮了高并發(fā),能夠同時接收大量請求,但如果單個請求的處理時間較長,其響應(yīng)速度和整體性能可能仍不理想。
例如,某接口通過隊列異步處理請求,雖然能應(yīng)對高并發(fā),但如果隊列設(shè)計不合理或任務(wù)本身耗時較長(如5-8秒),會影響用戶的實時體驗。
綜上所述,盡管高性能與高并發(fā)緊密相關(guān),它們并不是同一概念。實際上,高性能的解決方案可以視為高并發(fā)解決方案的一個重要組成部分,但高并發(fā)系統(tǒng)的設(shè)計還需綜合考慮分布式架構(gòu)、緩存、限流等技術(shù),以優(yōu)化整體性能和用戶體驗。
不滿足高并發(fā)會有什么后果?
在高并發(fā)環(huán)境下,如果系統(tǒng)不能有效處理大量并發(fā)請求,可能會導(dǎo)致多種嚴(yán)重后果,影響系統(tǒng)的性能和用戶體驗。
下圖是系統(tǒng)在高并發(fā)場景下不同的層面的后果表現(xiàn):

然而我們后端開發(fā)關(guān)注的層面更多是偏向于接口、數(shù)據(jù)庫還有服務(wù)器層面,因此我根據(jù)上圖我重新篩選與整理了一份詳細(xì)的表格如下:
|
層級 |
類型 |
問題 |
描述 |
|
應(yīng)用層 |
性能下降 |
響應(yīng)時間增加 |
當(dāng)系統(tǒng)無法處理高并發(fā)請求時,響應(yīng)時間會顯著增加,用戶需要更長時間才能得到反饋 |
|
吞吐量降低 |
系統(tǒng)的整體吞吐量(每秒處理的請求數(shù))會減少,無法充分利用硬件資源 |
||
|
數(shù)據(jù)庫 |
鎖爭用和死鎖 |
鎖爭用 |
在高并發(fā)環(huán)境下,多個事務(wù)可能同時爭用相同的資源,導(dǎo)致鎖爭用問題,影響事務(wù)的執(zhí)行 |
|
死鎖 |
高并發(fā)情況下,多個事務(wù)可能相互等待對方釋放鎖,導(dǎo)致死鎖,進(jìn)而導(dǎo)致事務(wù)無法完成 |
||
|
數(shù)據(jù)不一致 |
數(shù)據(jù)競爭 |
高并發(fā)請求可能導(dǎo)致數(shù)據(jù)競爭問題,多個請求同時修改相同的數(shù)據(jù),導(dǎo)致數(shù)據(jù)不一致 |
|
|
臟讀、不可重復(fù)讀和幻讀 |
在高并發(fā)環(huán)境下,事務(wù)隔離級別不足可能導(dǎo)致臟讀、不可重復(fù)讀和幻讀等問題,影響數(shù)據(jù)的正確性 |
||
|
服務(wù)層 |
資源耗盡 |
CPU過載 |
高并發(fā)請求可能導(dǎo)致CPU使用率過高,影響系統(tǒng)的整體性能 |
|
內(nèi)存耗盡 |
大量并發(fā)請求可能導(dǎo)致內(nèi)存耗盡,尤其是在沒有進(jìn)行有效的內(nèi)存管理和優(yōu)化時 |
||
|
磁盤I/O瓶頸 |
頻繁的磁盤讀寫操作可能導(dǎo)致磁盤I/O瓶頸,進(jìn)一步影響系統(tǒng)性能 |
||
|
服務(wù)器崩潰 |
服務(wù)器過載 |
高并發(fā)請求可能導(dǎo)致服務(wù)器過載,最終導(dǎo)致服務(wù)器崩潰或宕機(jī),無法提供服務(wù) |
|
|
資源泄漏 |
未正確釋放的文件句柄、數(shù)據(jù)庫連接、網(wǎng)絡(luò)連接、鎖資源等會致系統(tǒng)性能下降,甚至系統(tǒng)崩潰 |
有哪些通用的高并發(fā)方案?
通過上述我們清楚的了解到高并發(fā)處理不當(dāng)?shù)膰?yán)重性,那么究竟有沒有拿來即用的方案直接套上去就可以解決了呢?
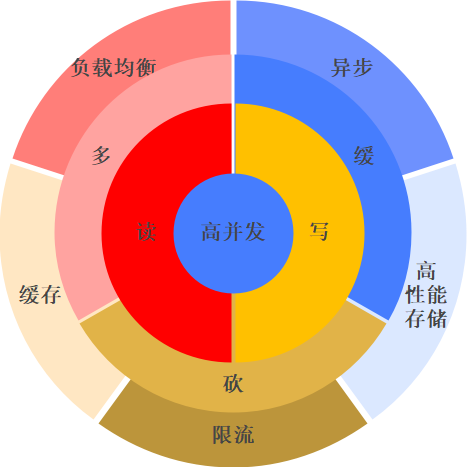
有,我把過往的經(jīng)驗總接了一下,從大方向來看一共三大類:限流、異步、冗余。
這三個詞,我相信大家都不陌生,我也給他們都各用一句話來描述。
- 限流,溢出的流量就不要了
- 異步,不著急的任務(wù)就放緩處理
- 冗余,弄多幾個副本分擔(dān)壓力
因此,高并發(fā)的通用解決方案我認(rèn)為無疑就是三字真言:砍、緩、多。
每個類型其實又細(xì)分共七大處理手段,我整理了一張表格給到各位,毫不夸張說,從我過往經(jīng)驗來看,以下方案可以解決我們?nèi)粘S龅?0%的并發(fā)問題。
|
類型 |
方案 |
描述 |
|
限流 |
業(yè)務(wù)限流 |
根據(jù)具體業(yè)務(wù)場景進(jìn)行限流,例如搶購前答題、活動過量時限購。 |
|
技術(shù)限流 |
使用算法在應(yīng)用層面(API網(wǎng)關(guān))進(jìn)行限流,例如基于漏桶、令牌桶算法等限流。 |
|
|
異步 |
調(diào)度任務(wù) |
先把數(shù)據(jù)暫存下來,定期或者特定條件下(閑時)進(jìn)行批量的處理 |
|
消息隊列 |
削峰:將瞬時高峰流量平滑處理,使得后臺服務(wù)可以按照自己的處理能力逐步處理消息,從而避免系統(tǒng)崩潰 |
|
|
異步化:系統(tǒng)可以將需要長時間處理的任務(wù)(如視頻、音頻處理、數(shù)據(jù)分析等)異步化,避免主線程阻塞,提升系統(tǒng)的響應(yīng)速度和用戶體驗 |
||
|
冗余 |
集群 |
負(fù)載均衡:通過多個服務(wù)器節(jié)點分擔(dān)壓力,避免單個服務(wù)器壓力過載。不局限于API應(yīng)用,也可以是數(shù)據(jù)庫一主多從 |
|
故障轉(zhuǎn)移:如果集群中的某個節(jié)點發(fā)生故障,負(fù)載均衡器可以將請求重新分配給其他健康節(jié)點,從而保證服務(wù)的連續(xù)可用 |
||
|
緩存 |
把熱數(shù)據(jù)存放到高性能存儲系統(tǒng)進(jìn)行讀寫處理,以此降低數(shù)據(jù)庫訪問量,提高系統(tǒng)響應(yīng)速度。 |
|
|
靜態(tài)化 |
將動態(tài)產(chǎn)生的數(shù)據(jù)保存成靜態(tài)文件,或者將固定計算規(guī)則數(shù)據(jù)事先計算好存放。從而降低系統(tǒng)的計算負(fù)荷和數(shù)據(jù)庫訪問壓力。 例如 介紹頁靜態(tài)化、報表數(shù)據(jù)靜態(tài)化。 |
三字真言,七大處理手段固然好使,但是并不代表可以濫用,像限流、集群、緩存等更多屬于短期收益高的應(yīng)急手段。
舉個例子,可能我們的問題其實就是一個慢查詢導(dǎo)致的數(shù)據(jù)庫負(fù)載過高,從而影響了應(yīng)用的工作線程數(shù)阻塞,最后影響到了應(yīng)用服務(wù)器的CPU過載從而導(dǎo)致接口無法響應(yīng),這種情況下我們貿(mào)然的去堆硬件、加緩存而不去優(yōu)化語句,這無疑是飲鴆止渴,還會額外增加成本(硬件、維護(hù))。
如果本質(zhì)問題未得到根本解決,問題終將再次出現(xiàn),時間只是決定它重現(xiàn)的變量。
高并發(fā)有哪些場景?
從大層面來看,高并發(fā)場景可以分為“讀”和“寫”兩類。以典型的互聯(lián)網(wǎng)系統(tǒng)為例,讀寫比例通常為 8:2,即讀多寫少。因此,讀寫場景各自具有不同的特點,采用的優(yōu)化方案也有所區(qū)別。
讀場景
在互聯(lián)網(wǎng)應(yīng)用中,系統(tǒng)通常可以看作是一個資源整合的平臺,因此讀操作占據(jù)了較大的比例。無論是數(shù)據(jù)庫還是接口,讀操作一般具有以下兩個特點:冪等性和負(fù)載均衡性(除非接口設(shè)計得不合理,如讀寫混合的情況)。
冪等性指的是:相同的參數(shù)調(diào)用同一個方法,無論執(zhí)行一次還是多次,響應(yīng)的結(jié)果都是一致的。將這一概念應(yīng)用到讀場景中,意味著對于相同的輸入?yún)?shù)、相同的處理邏輯,最終返回的結(jié)果始終一致。
負(fù)載均衡性
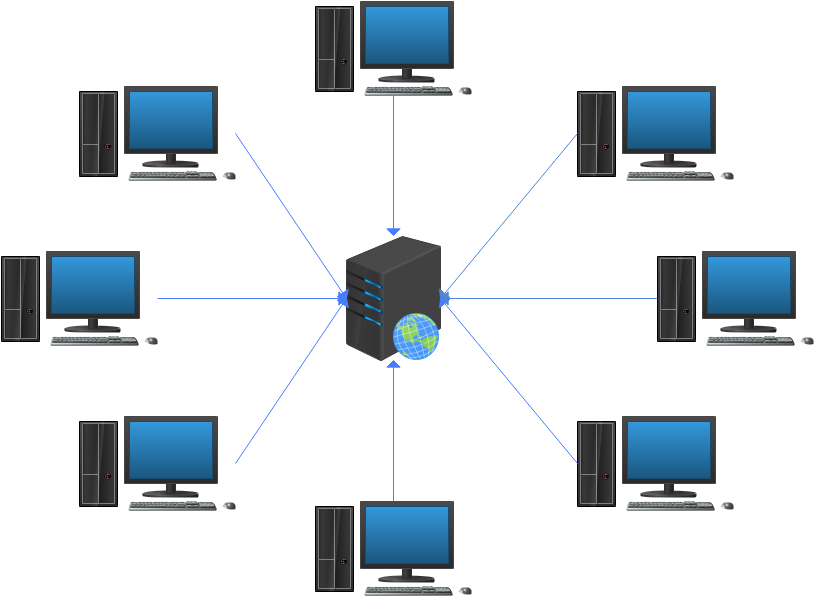
讀操作由于具備天然的冪等性,API 服務(wù)通常傾向于設(shè)計為“無狀態(tài)”。這種設(shè)計使得在面臨負(fù)載瓶頸時,可以通過增加服務(wù)副本實現(xiàn)橫向擴(kuò)展(Scale-Out),無需引入復(fù)雜的邏輯處理。此時,系統(tǒng)的關(guān)注點更多集中在數(shù)據(jù)庫(存儲系統(tǒng))和服務(wù)器的性能及負(fù)載上。
眾所周知,關(guān)系型數(shù)據(jù)庫在處理分布式寫(例如分庫分表)時面臨較大的挑戰(zhàn),但在分布式讀方面具有天然優(yōu)勢。成熟的數(shù)據(jù)庫通常能夠通過簡單的組件實現(xiàn)一主多從架構(gòu),支持讀寫分離。
無論是接口層面的服務(wù)集群,還是數(shù)據(jù)庫層面的一主多從架構(gòu),其核心策略都在于通過【多】副本來分擔(dān)壓力,提升性能與可用性。
然而,這種場景通常假設(shè)數(shù)據(jù)是靜態(tài)的,不涉及復(fù)雜的計算。當(dāng)面對復(fù)雜計算的高并發(fā)場景時,數(shù)據(jù)庫(存儲系統(tǒng))的負(fù)載壓力會更加明顯。
優(yōu)化手段
為應(yīng)對上述問題,可以引入以下優(yōu)化手段:
1. 緩存:將熱數(shù)據(jù)存儲在內(nèi)存(Redis)中,減少對數(shù)據(jù)庫的直接訪問。
2. 靜態(tài)化:將動態(tài)生成的數(shù)據(jù)轉(zhuǎn)換為靜態(tài)(如 HTML 文件、中間表數(shù)據(jù)),在一定時間內(nèi)復(fù)用熱數(shù)據(jù)。
無論是增加服務(wù)副本,還是使用緩存和靜態(tài)化手段,其核心思想都是一致的:冗余。通過冗余數(shù)據(jù)或資源,減少系統(tǒng)在高并發(fā)場景下的負(fù)載壓力。
寫場景
相比讀操作,寫操作在高并發(fā)場景下更復(fù)雜,因其缺乏天生的數(shù)據(jù)冪等性和負(fù)載均衡。寫操作的優(yōu)化主要圍繞數(shù)據(jù)一致性、高性能和異步處理展開。
異步處理
異步處理在高并發(fā)的寫場景中是最直接有效的,其核心思想采用【緩】的策略。隊列和調(diào)度任務(wù)在這里扮演了兩個關(guān)鍵角色:緩沖和延緩。
- 隊列:可作為數(shù)據(jù)的臨時存儲區(qū)域,隊列將高并發(fā)的寫操作轉(zhuǎn)化為串行處理(或少量并行),從而起到緩沖作用,有效減輕后端系統(tǒng)的瞬時壓力。例如:數(shù)據(jù)采集
- 調(diào)度任務(wù):通過控制處理頻率(速度和時間),調(diào)度任務(wù)將非實時性強(qiáng)的操作延遲處理,并在流量低峰期集中批量執(zhí)行,從而實現(xiàn)流量的平滑化。例如:排行榜、季度報表等
然而,異步處理并非萬能,存在一定的場景局限性。并不是所有的寫操作都適合使用隊列。例如,對于時效性要求較高的請求,異步處理可能無法滿足需求,此時需要采用一些特殊手段來彌補(bǔ),例如輪詢查詢、WebSocket 推送等實時機(jī)制。
高性能寫
在高性能存儲場景中,NoSQL —— Redis 是常見的選擇。一個典型的應(yīng)用場景是搶購系統(tǒng),其中針對高并發(fā)寫操作的解決方案通常采用“預(yù)扣減”策略。其處理流程如下:
- 數(shù)據(jù)同步:通過后臺服務(wù)或定時調(diào)度任務(wù),將數(shù)據(jù)庫中的庫存數(shù)據(jù)提前同步到 Redis。
- 庫存判斷:通過 Redis 實現(xiàn)庫存的快速判斷。
- 扣減操作:每次對熱門商品的庫存進(jìn)行扣減時,直接在 Redis 中使用 INCR -N 指令完成。
這種方法有效避免了數(shù)據(jù)庫在高并發(fā)寫入場景下因鎖機(jī)制導(dǎo)致的性能瓶頸,同時充分利用 Redis 的高吞吐能力,顯著提升了系統(tǒng)的響應(yīng)效率。
限流
在互聯(lián)網(wǎng)領(lǐng)域,流量被視為至關(guān)重要的資源,因此有一句話廣為流傳:“流量為王”,因為流量直接關(guān)系到用戶接觸度和潛在的商業(yè)價值。
盡管流量的增加在理論上是有利的,但在資源有限的現(xiàn)實環(huán)境中,過量的流量可能會成為系統(tǒng)的負(fù)擔(dān),甚至導(dǎo)致系統(tǒng)崩潰。
因此,為了避免系統(tǒng)因流量激增而超出承載能力,我們通常采用限流策略,其核心思想是通過“砍”的方式對流量進(jìn)行控制。限流策略可以分為技術(shù)限流和業(yè)務(wù)限流兩種方式。
技術(shù)限流
技術(shù)限流通過技術(shù)手段對訪問流量進(jìn)行控制,確保系統(tǒng)在其負(fù)載能力范圍內(nèi)平穩(wěn)運行。通常,這類限流措施會在流量入口(如 API 網(wǎng)關(guān))處實現(xiàn)。常見的技術(shù)限流策略包括:
- 速率限制(Rate Limiting):限制用戶在單位時間內(nèi)的最大請求次數(shù)。
- 令牌桶(Token Bucket):通過令牌分發(fā)機(jī)制控制請求速率,允許一定程度的突發(fā)流量。
- 漏桶(Leaky Bucket):將請求以固定速率排出,平滑流量波動。
- 熔斷器(Circuit Breaker):在系統(tǒng)檢測到異常或過載時,主動中斷請求鏈路,保護(hù)系統(tǒng)免于崩潰。
業(yè)務(wù)限流
業(yè)務(wù)限流從業(yè)務(wù)層面出發(fā),通過調(diào)整業(yè)務(wù)策略來控制流量,不僅可以減輕系統(tǒng)負(fù)擔(dān),還能優(yōu)化用戶體驗。常見的業(yè)務(wù)限流策略包括:
- 用戶分級服務(wù):根據(jù)用戶等級或類型實施差異化的訪問策略,例如,VIP 用戶享有更高的請求優(yōu)先級或更大的訪問額度。
- 預(yù)約機(jī)制:針對流量激增的場景,通過預(yù)約制度控制用戶訪問。例如,在特定時間段內(nèi)限制服務(wù)人數(shù),分批次提供服務(wù)。
我遇到的高并發(fā)優(yōu)化場景
在之前的討論中,我們探討了許多高并發(fā)場景的理論知識。接下來,我將分享一些實際工作中的優(yōu)化案例。
無狀態(tài)讓API服務(wù)"力大飛磚"
多年來,我司主要通過 Redis 和 服務(wù)集群 來優(yōu)化系統(tǒng)性能。隨著用戶數(shù)量和日活躍度的持續(xù)增長,API服務(wù)的CPU壓力逐漸增大。為應(yīng)對這一挑戰(zhàn),我們從設(shè)計之初便采用了 無狀態(tài)服務(wù),并引入 Nginx 實現(xiàn)負(fù)載均衡,使服務(wù)能夠根據(jù)流量需求進(jìn)行 橫向擴(kuò)展,從而實現(xiàn)集群化部署。
問題背景
近期,由于合作方投流,平臺流量進(jìn)一步增長,特別是在晚高峰時,部分API服務(wù)節(jié)點出現(xiàn)滿負(fù)載情況,而數(shù)據(jù)庫負(fù)載卻保持正常。通過監(jiān)控和代碼分析發(fā)現(xiàn),問題出在某些接口的實現(xiàn)上。這些接口每次讀取大量數(shù)據(jù),并通過 Foreach 進(jìn)行逐條查詢和計算。由于查詢是基于主鍵的,數(shù)據(jù)庫壓力不大,但數(shù)據(jù)量過大直接導(dǎo)致單次請求執(zhí)行時間過長。當(dāng)晚高峰多名用戶并發(fā)請求時,這些接口瞬間占滿API服務(wù)的工作線程,導(dǎo)致 CPU負(fù)載飆升。
臨時應(yīng)對
為應(yīng)對流量高峰,我們通過 API橫向擴(kuò)容 的方式,臨時增加了多臺節(jié)點機(jī),緩解了服務(wù)壓力,確保平臺能夠穩(wěn)定運行,抓住這波流量。
緩存很有用,但姿勢要對
為了優(yōu)化性能,我們幾乎對所有核心業(yè)務(wù)(如首頁數(shù)據(jù)、推薦位、排行榜、作品內(nèi)容等)都采用了 緩存策略。
這種方法在過去幾年中效果顯著:只要出現(xiàn)性能瓶頸,引入緩存幾乎總能解決問題。尤其是首頁業(yè)務(wù),這類數(shù)據(jù)通常是每隔數(shù)小時更新一次的偽靜態(tài)數(shù)據(jù),使用緩存完全合理。
然而,這也引出了一個值得思考的問題:緩存是否能解決所有性能問題?
緩存雖然能夠顯著提升數(shù)據(jù)讀取性能,但對于復(fù)雜計算、接口設(shè)計缺陷以及高并發(fā)場景下的線程占用問題,緩存并非萬能。我們需要結(jié)合具體場景,從代碼優(yōu)化、接口設(shè)計、數(shù)據(jù)庫查詢效率等多方面入手,才能真正解決性能瓶頸。
在一年的最后一天,我們發(fā)現(xiàn)了一個嚴(yán)重問題。12月31日午夜12點,咱們數(shù)據(jù)庫的CPU使用率突然從20%激增至100%。通過檢查接口日志和數(shù)據(jù)庫阻塞日志,問題鎖定在一條長期使用的排行榜SQL語句。按理說,這部分?jǐn)?shù)據(jù)應(yīng)有緩存,為何系統(tǒng)會崩潰?經(jīng)過代碼審查,問題如下:
問題分析
偽代碼如下:
// 緩存策略模式 - cache-aside var redisKey = "rankinglist:" + DateTime.Now.ToString("yyyyMMdd"); var rankingListCache = redis.Get(redisKey); // 從緩存獲取數(shù)據(jù) if (rankingListCache != null) return rankingListCache; var data = db.RankingList.GetList(); // 從數(shù)據(jù)庫獲取數(shù)據(jù),復(fù)雜查詢 if (data.Any()) { redis.Set(redisKey, data, 3600); // 寫入緩存 return data; } return new List();
1. 緩存鍵設(shè)計問題
緩存鍵基于 DateTime.Now.ToString("yyyyMMdd") 生成,導(dǎo)致跨年、跨月、跨日時,年度榜、月榜、周榜在午夜12點立即失效,觸發(fā)所有請求直接訪問數(shù)據(jù)庫。
2. 緩存穿透問題
僅當(dāng) data.Any()`為真時才會更新緩存。如果數(shù)據(jù)庫查詢結(jié)果為空,則不會寫入緩存,導(dǎo)致每次請求都直接訪問數(shù)據(jù)庫。
臨時優(yōu)化
針對上述問題,我們進(jìn)行了以下優(yōu)化:
var redisKey = "rankinglist:" + type; // 改為基于榜單類型的緩存鍵 var rankingListCache = redis.Get(redisKey); // 從緩存獲取數(shù)據(jù) if (rankingListCache != null) return rankingListCache; var data = db.RankingList.GetList(); // 從數(shù)據(jù)庫獲取數(shù)據(jù) if (data.Any()) { redis.Set(redisKey, data, 3600); // 緩存有效數(shù)據(jù) return data; } else { redis.Set(redisKey, new List(), 60); // 緩存空數(shù)據(jù)1分鐘 return new List(); }
1. 緩存鍵設(shè)計優(yōu)化
去掉基于日期的緩存鍵,改為按榜單類型(如年度榜、月榜、周榜)生成緩存鍵,避免因日期變更導(dǎo)致緩存大規(guī)模失效。
2. 緩存穿透防護(hù)
即使數(shù)據(jù)庫查詢結(jié)果為空,也緩存空數(shù)據(jù)(有效期1分鐘),避免頻繁查詢數(shù)據(jù)庫。
通過以上優(yōu)化,臨時解決了Redis引發(fā)的緩存穿透和緩存雪崩問題。
長期優(yōu)化
從數(shù)據(jù)庫架構(gòu)設(shè)計角度,我們進(jìn)一步采取了 主從分離策略,將首頁只讀業(yè)務(wù)和復(fù)雜查詢遷移至從庫。遷移后,通過 Zabbix 監(jiān)控發(fā)現(xiàn),主庫CPU負(fù)載高峰現(xiàn)象徹底解決,主庫負(fù)載降低了50%,主從庫運行穩(wěn)定,性能大幅提升。
異步與靜態(tài)化
一個工作日的早晨,系統(tǒng)再次報警,部分用戶反饋無法訪問平臺功能。問題持續(xù)約 20 分鐘后逐漸恢復(fù)。通過日志和監(jiān)控分析發(fā)現(xiàn),問題源于從庫 CPU 負(fù)載達(dá)到 100%,由類報表功能的復(fù)雜查詢引發(fā)。
前一天啟動的活動吸引了大量用戶次日參與,但部分緩存失效導(dǎo)致相關(guān)功能查詢直接落庫。由于查詢語句執(zhí)行時間較長(5-10 秒),結(jié)果無法及時寫入 Redis,后續(xù)用戶的請求均直接查詢數(shù)據(jù)庫,導(dǎo)致 CPU 瞬間飆升至 100%。這種現(xiàn)象稱為緩存擊穿。高并發(fā)下的查詢超時進(jìn)一步加劇了無法緩存的情況,形成惡性循環(huán)。
得益于主從分離策略,本次僅部分功能受影響,但復(fù)雜查詢在高并發(fā)場景下對數(shù)據(jù)庫負(fù)載的壓力較大,亟需優(yōu)化。
考慮到相關(guān)數(shù)據(jù)短時間內(nèi)不會變化,我們對架構(gòu)進(jìn)行了調(diào)整:
- 靜態(tài)化數(shù)據(jù)處理:將實時 SQL 查詢改為通過調(diào)度任務(wù)定時執(zhí)行,將查詢結(jié)果壓縮后存儲至中間表。
- 接口調(diào)整:修改接口邏輯,直接從中間表讀取數(shù)據(jù)。
這種策略有效降低了數(shù)據(jù)庫對復(fù)雜查詢的計算壓力,同時顯著提高了接口的并發(fā)處理能力。
復(fù)雜 SQL 在高并發(fā)場景下對數(shù)據(jù)庫影響較大,尤其配置不足時更易成為瓶頸。通過靜態(tài)化處理和中間表設(shè)計,既緩解了數(shù)據(jù)庫壓力,又優(yōu)化了用戶體驗。
限制不住,就扛下來
俗話說:“人怕出名,豬怕壯”隨著平臺不斷發(fā)展壯大,關(guān)注度提高的同時,挑戰(zhàn)也隨之而來,如盜版和競爭對手使用爬蟲抓取數(shù)據(jù)。這些爬蟲不僅可能將商業(yè)數(shù)據(jù)發(fā)布到免費網(wǎng)站,損害平臺利益,還會通過頻繁請求導(dǎo)致系統(tǒng)壓力激增。
雖然“流量為王”,但惡意爬蟲的流量對平臺毫無價值。為此,我們迅速在網(wǎng)關(guān)層面實施限流策略,從 IP、Cookies、UA 等多個維度限制密集請求,有效應(yīng)對了基礎(chǔ)、粗暴的爬蟲攻擊。
然而,某日搜索庫服務(wù)器 CPU 使用率驟然飆升。分析后發(fā)現(xiàn),黑客通過模擬客戶端身份并以分布式方式繞過限流策略發(fā)起攻擊。為長期防御此類問題,我們需要從前后端入手,增加校驗規(guī)則、更換密鑰、加強(qiáng)客戶端防護(hù)等多方面提升系統(tǒng)安全性。
但我們也深知,沒有絕對完美的安全策略,后端服務(wù)必須具備一定的抗壓能力。
非常遺憾的是,我們用Like做搜索作為技術(shù)債務(wù)保留了下來,也是這次事故的兇手,為解決這一問題,我們引入了 ElasticSearch,通過定時任務(wù)定期同步搜索庫數(shù)據(jù)至 ElasticSearch,并調(diào)整接口邏輯指向 ElasticSearch。這一優(yōu)化顯著提升了搜索性能,使系統(tǒng)在高并發(fā)場景下更穩(wěn)定,也更從容地應(yīng)對爬蟲流量攻擊。
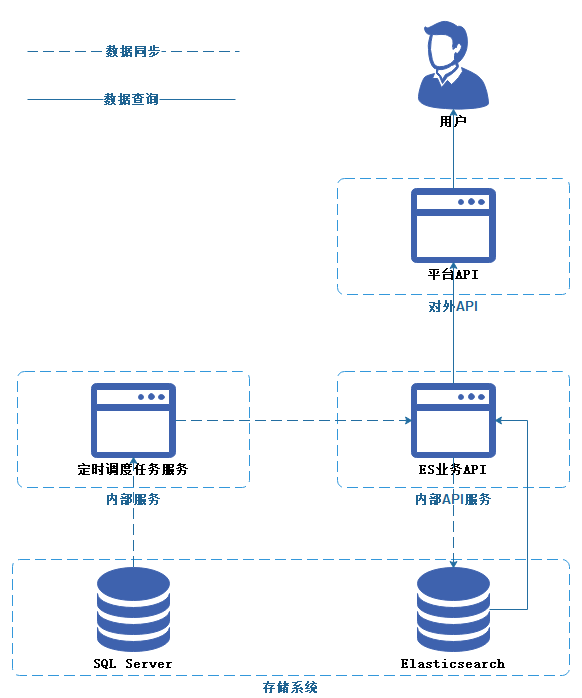
怎么應(yīng)對火熱搶購?
雖然我們公司主營文娛類業(yè)務(wù),但任何形式的優(yōu)惠或免費活動都能吸引大量用戶,類似電商平臺的搶購活動。
以平臺推出的福利商城為例,用戶通過完成任務(wù)或參與活動獲得虛擬幣,用于兌換“代券”免費觀看作品。代券每天限量,每晚12點系統(tǒng)自動刷新庫存,開啟新一輪兌換。
在一次五一活動中,我們吸引了大量用戶參與。然而活動結(jié)束后的第二天凌晨,主庫 CPU 負(fù)載突然飆升至 100%,持續(xù)約 15 分鐘。經(jīng)過分析發(fā)現(xiàn),問題出在用戶集中搶兌代券時,SQL 執(zhí)行遇到高并發(fā)鎖競爭。盡管庫存扣減的 SQL 語句很簡單:
UPDATE TableA SET Stock = Stock - 1 WHERE Stock > 0;
問題的根源在于并發(fā)環(huán)境下共享數(shù)據(jù)產(chǎn)生的鎖競爭。
鎖競爭的高負(fù)載原因:
1.自旋鎖的忙等:自旋鎖在鎖被占用時,線程會不斷循環(huán)嘗試獲取鎖而不掛起,導(dǎo)致CPU持續(xù)執(zhí)行無效操作,顯著增加CPU負(fù)載。2.頻繁的上下文切換:高并發(fā)下,線程競爭鎖未果時會被掛起并進(jìn)入等待隊列,鎖釋放后再被喚醒。頻繁的掛起和喚醒引發(fā)大量上下文切換,消耗CPU資源,提升負(fù)載。3.死鎖檢測的開銷:在高并發(fā)場景中,數(shù)據(jù)庫或操作系統(tǒng)需要掃描等待圖或事務(wù)依賴關(guān)系以檢測死鎖,這種復(fù)雜計算會顯著增加CPU負(fù)擔(dān)。
為解決這一問題,我提出了兩種優(yōu)化方案:
- 調(diào)整庫存刷新時間
建議將庫存刷新時間改為凌晨 4-5 點的低峰期,避開用戶集中“蹲點”兌換的高峰時段。這是成本最低的解決方案,但團(tuán)隊認(rèn)為用戶已習(xí)慣現(xiàn)有模式,調(diào)整可能影響用戶體驗。 - 預(yù)扣庫存方案
針對高并發(fā)問題,設(shè)計了基于 Redis 的預(yù)扣庫存機(jī)制: - 庫存同步至 Redis:后臺對熱門商品新增或編輯時,將庫存同步到 Redis。
- Redis 扣減邏輯:客戶端請求兌換時,系統(tǒng)先檢查 Redis 中的庫存,若庫存量大于 0,使用 INCR 命令扣減庫存。只有扣減成功,才生成兌換記錄。
- 庫存回寫數(shù)據(jù)庫:當(dāng) Redis 庫存扣減至 0 時,將庫存同步回數(shù)據(jù)庫,并更新庫存狀態(tài)供客戶端展示。
通過 Redis 的高性能讀取和寫入操作,避免了數(shù)據(jù)庫的鎖競爭問題,同時顯著降低了 CPU 負(fù)載。
搶購可以使用隊列處理么?
針對“搶購”類業(yè)務(wù)場景,可以考慮引入隊列機(jī)制來緩解熱點數(shù)據(jù)更新導(dǎo)致的高負(fù)載問題。隊列的先進(jìn)先出(FIFO)特性和串行處理機(jī)制能夠有效降低數(shù)據(jù)庫壓力,避免高并發(fā)寫入引發(fā)的性能瓶頸。然而,隊列的引入往往意味著異步處理用戶請求,這對需要即時反饋的場景帶來了新的挑戰(zhàn)。
例如,類似【智行火車票】APP的排隊下單系統(tǒng)(盡管未明確其是否使用隊列),其邏輯與隊列機(jī)制非常相似:
- 用戶下單后進(jìn)入排隊頁面(中間頁),頁面通過定時刷新更新訂單狀態(tài)。
- 處理完成后,頁面展示支付按鈕供用戶操作。
- 支付完成但尚未出票時,用戶會跳轉(zhuǎn)到訂單詳情頁,出票后則以通知形式告知用戶。
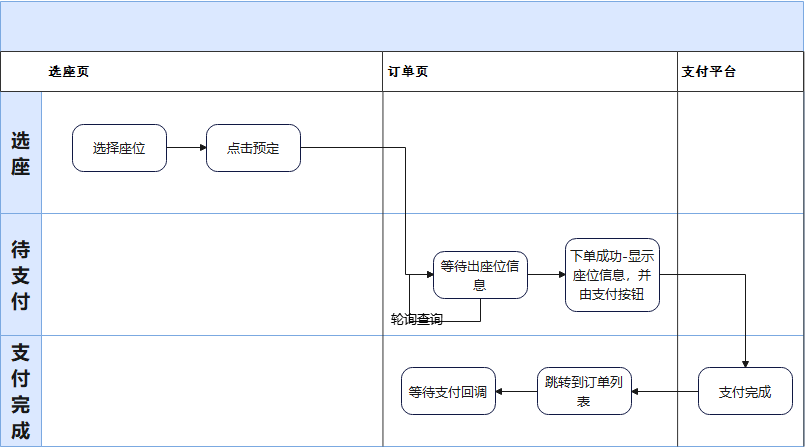
再舉個例子,以上面說的福利商城的“搶購”業(yè)務(wù)為例:
- 用戶點擊【兌換】按鈕后,系統(tǒng)將請求放入隊列中,隊列逐步消費這些請求。用戶此時會進(jìn)入一個中間等待頁面,等待兌換結(jié)果。
- 由于并發(fā)情況下庫存數(shù)據(jù)未能實時同步扣減,最終兌換結(jié)果可能失敗。
- 對于結(jié)果通知的方式,可以選擇通過 WebSocket 實時推送,也可以在中間頁由客戶端輪詢獲取結(jié)果。
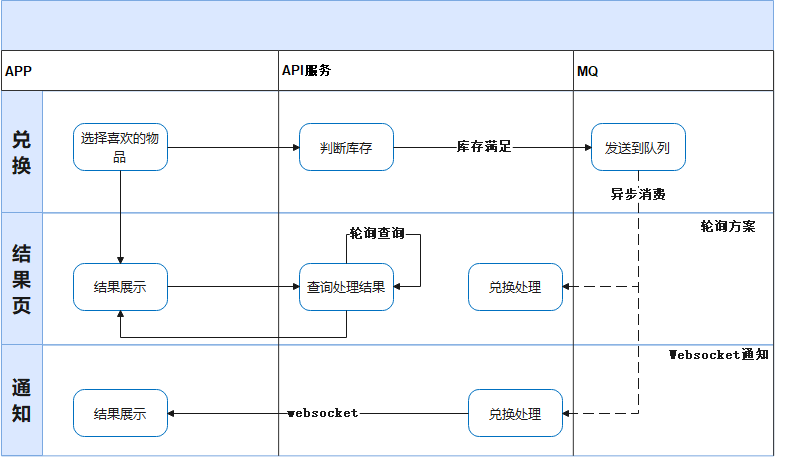
然而,這種改造方式需要前后端協(xié)同配合,且需要調(diào)整用戶交互邏輯,改造成本相對較高。
針對“搶購”類業(yè)務(wù)場景,優(yōu)化方案有多種選擇。具體方案應(yīng)根據(jù)系統(tǒng)的實際體量和業(yè)務(wù)需求,選擇最優(yōu)的處理方式。
隊列適用場景分析
在我們的平臺上,隊列適用于以下寫入場景:
- 客戶端行為日志采集
用戶操作頻繁、請求量大,但對響應(yīng)時間要求不高。日志采集主要用于生成報告供內(nèi)部分析,因此無需實時寫入數(shù)據(jù)庫。通過隊列異步處理,可有效緩解高并發(fā)寫入壓力。 - 個推數(shù)據(jù)處理
個推數(shù)據(jù)雖需基于用戶行為進(jìn)行實時推薦,但本質(zhì)上是偽實時場景。推薦算法的響應(yīng)時間通常在 0.01 秒到 3 秒之間波動,當(dāng)無法即時生成推薦結(jié)果時,可使用公共推薦庫作為替代。隊列能夠?qū)⑼扑]計算轉(zhuǎn)移至后臺,分散系統(tǒng)壓力,提升整體性能。 - 公共數(shù)據(jù)統(tǒng)計
用戶觀看廣告后,平臺會贈送代金券,同時廣告的總觀看次數(shù)需要更新。在晚高峰時,大量用戶集中操作會對廣告數(shù)據(jù)表造成寫入壓力,甚至引發(fā)鎖競爭或死鎖問題。為優(yōu)化性能,可將“廣告觀看次數(shù) +1”的操作通過消息隊列(MQ)異步處理。用戶領(lǐng)取獎勵后,系統(tǒng)將更新請求寫入隊列,由后臺異步更新數(shù)據(jù)庫,避免高并發(fā)直接寫入。
高并發(fā)不是終點
高并發(fā)不是終點,而是一場持續(xù)的“攻防戰(zhàn)”。優(yōu)化高并發(fā)系統(tǒng)需要從技術(shù)與業(yè)務(wù)雙重角度出發(fā),既要平衡用戶體驗、系統(tǒng)性能與資源成本,又要根據(jù)具體場景靈活應(yīng)用各種策略。無論是三字真言“砍、緩、多”,還是七大處理手段,都沒有絕對的萬能解法——正如軟件工程的經(jīng)典原則所言:【沒有銀彈】。真正的高并發(fā)優(yōu)化核心,不僅在于提升系統(tǒng)性能與穩(wěn)定性,更在于如何在有限的資源條件下,以最優(yōu)成本滿足業(yè)務(wù)需求。
高并發(fā)不是終點,而是開發(fā)者不斷突破技術(shù)邊界的新起點。希望本文的經(jīng)驗與總結(jié),能夠為你應(yīng)對高并發(fā)場景提供啟發(fā)與幫助。
作 者:
陳珙
出 處:http://www.rzrgm.cn/skychen1218/
關(guān)于作者:專注于微軟平臺的項目開發(fā)。如有問題或建議,請多多賜教!
版權(quán)聲明:本文版權(quán)歸作者和博客園共有,歡迎轉(zhuǎn)載,但未經(jīng)作者同意必須保留此段聲明,且在文章頁面明顯位置給出原文鏈接。
聲援博主:如果您覺得文章對您有幫助,可以點擊文章右下角推薦一下。您的鼓勵是作者堅持原創(chuàng)和持續(xù)寫作的最大動力!

 浙公網(wǎng)安備 33010602011771號
浙公網(wǎng)安備 33010602011771號