剛剛,DeepSeek又一重大突破,小身材大智慧玩出新高度

原文:https://mp.weixin.qq.com/s/RWmTAk-SMadqi5BZEy9pqA
全文摘要
DeepSeek-OCR是由DeepSeek-AI提出的、用于探索通過光學2D映射壓縮長上下文可行性的視覺語言模型(VLM),核心包含DeepEncoder(編碼器)和DeepSeek3B-MoE-A570M(解碼器)兩大組件。其中DeepEncoder能在高分辨率輸入下保持低激活值并實現高壓縮比,實驗顯示當文本token數量為視覺token的10倍以內(壓縮比<10×)時,模型OCR精度達97%,壓縮比20×時精度仍約60%;在實用性能上,它在OmniDocBench基準測試中,僅用100個視覺token就超越需256個token的GOT-OCR2.0,用少于800個視覺token超越平均需6000+個token的MinerU2.0,且單A100-40G顯卡日生成20萬+頁LLM/VLM訓練數據,代碼和模型權重已開源(http://github.com/deepseek-ai/DeepSeek-OCR),為LLM長上下文壓縮、記憶遺忘機制研究及實際OCR任務提供重要價值。
論文方法
DeepSeek-OCR概述
- 基本定位:由DeepSeek-AI提出的視覺語言模型(VLM),核心目標是探索通過光學2D映射壓縮長上下文的可行性,為LLM處理長文本的計算挑戰提供解決方案(利用視覺模態作為文本信息的高效壓縮媒介)。
- 核心組件:包含編碼器(DeepEncoder)和解碼器(DeepSeek3B-MoE-A570M),代碼與模型權重已開源(地址:http://github.com/deepseek-ai/DeepSeek-OCR)。
- 核心優勢:兼顧高壓縮比與高OCR精度,同時具備強實用性能,可大規模生成LLM/VLM訓練數據。
核心組件設計
DeepEncoder(編碼器)
- 設計目標:滿足高分辨率處理、高分辨率下低激活、少視覺token、多分辨率支持、參數適中5大需求,解決現有VLM視覺編碼器的缺陷(如token過多、激活量大等)。
- 架構細節:
- 總參數約380M,由SAM-base(80M,窗口注意力主導)、16×卷積壓縮器、CLIP-large(300M,密集全局注意力) 串聯組成。
- 卷積壓縮器:2層卷積(核3×3、步長2、填充1),通道從256→1024,實現視覺token16倍下采樣(如1024×1024圖像輸入,token從4096→256)。
- 分辨率支持:通過位置編碼動態插值實現多分辨率,具體模式如下表:
| 分辨率模式 | 子模式 | 原生分辨率 | 視覺token數 | 處理方式 |
|---|---|---|---|---|
| 原生分辨率 | Tiny | 512×512 | 64 | 直接resize |
| Small | 640×640 | 100 | 直接resize | |
| Base | 1024×1024 | 256 | padding(保留寬高比) | |
| Large | 1280×1280 | 400 | padding(保留寬高比) | |
| 動態分辨率 | Gundam | 640×640+1024×1024 | n×100+256(n∈[2:9]) | 分塊+resize+padding |
| Gundam-M | 1024×1024+1280×1280 | n×256+400(n∈[2:9]) | 分塊+resize+padding |
注:動態分辨率主要用于超高清輸入(如報紙),避免圖像過度碎片化;Gundam-M需在預訓練模型基礎上繼續訓練,平衡訓練速度。
解碼器(DeepSeek3B-MoE-A570M)
- 架構特點:基于DeepSeek3B-MoE,推理時激活64個路由專家中的6個+2個共享專家,激活參數約570M,兼顧3B模型的表達能力與500M小模型的推理效率
- 核心功能:通過非線性映射(\(f_{dec}\))從DeepEncoder輸出的壓縮視覺token重構文本表示。
訓練流程與數據引擎
數據引擎(多樣化訓練數據)
| 數據類型 | 內容細節 | 占比/規模 | 作用 |
|---|---|---|---|
| OCR 1.0數據 | 30M頁多語言PDF(中/英25M+其他5M,含粗/細標注)、3M頁Word、10M頁中/英自然場景圖 | 占總數據70% | 訓練傳統OCR能力(文檔/場景文本識別) |
| OCR 2.0數據 | 10M頁圖表(線圖/柱狀圖等,轉HTML表格)、5M頁化學公式(SMILES格式)、1M頁平面幾何圖 | 含于OCR數據70%內 | 訓練復雜圖像解析能力 |
| 通用視覺數據 | 圖像描述、目標檢測、接地等任務數據(參考DeepSeek-VL2) | 占總數據20% | 保留通用視覺接口 |
| 純文本數據 | 內部數據,統一處理為8192token長度 | 占總數據10% | 保障模型語言能力 |
注:OCR 1.0細標注含2M頁中/英數據,用PP-DocLayout(布局)、MinerU2.0/GOT-OCR2.0(識別)構建;小語種數據通過“模型飛輪”生成600K樣本。
訓練流程
- 階段1:獨立訓練DeepEncoder
- 數據:所有OCR 1.0/2.0數據+100M采樣自LAION的通用數據
- 配置:AdamW優化器,余弦退火調度器,學習率5e-5,批大小1280,訓練2輪,序列長度4096
- 階段2:訓練DeepSeek-OCR
- 平臺:HAI-LLM平臺
- 并行策略:4段管道并行(DeepEncoder占2段,解碼器占2段),20節點(每節點8張A100-40G),數據并行40,全局批大小640
- 配置:AdamW優化器,步長調度器,初始學習率3e-5;純文本數據訓練速度90B token/天,多模態數據70B token/天
論文實驗
核心實驗性能
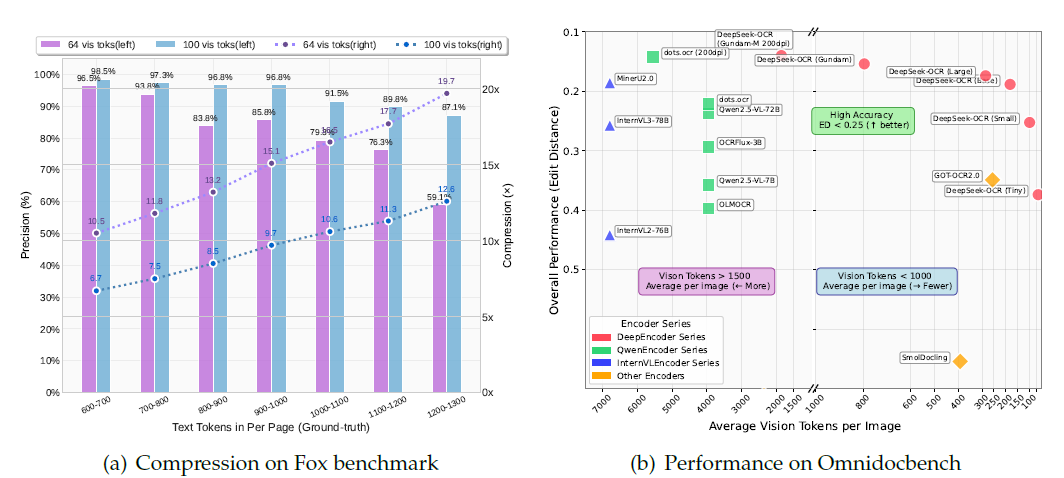
Fox基準測試(文本token600-1300,英文文檔,驗證壓縮-解壓縮能力)
| 文本token范圍 | 視覺token=64(Tiny模式) | 視覺token=100(Small模式) | 測試頁數 | ||
|---|---|---|---|---|---|
| 精度 | 壓縮比 | 精度 | 壓縮比 | ||
| 600-700 | 96.5% | 10.5× | 98.5% | 6.7× | 7 |
| 700-800 | 93.8% | 11.8× | 97.3% | 7.5× | 28 |
| 800-900 | 83.8% | 13.2× | 96.8% | 8.5× | 28 |
| 900-1000 | 85.9% | 15.1× | 96.8% | 9.7× | 14 |
| 1000-1100 | 79.3% | 16.5× | 91.5% | 10.6× | 11 |
| 1100-1200 | 76.4% | 17.7× | 89.8% | 11.3× | 8 |
| 1200-1300 | 59.1% | 19.7× | 87.1% | 12.6× | 4 |
- 關鍵結論:壓縮比<10×時,精度≈97%;壓縮比20×時,精度≈60%;實際精度因輸出與標注格式差異會更高。
OmniDocBench基準測試(真實文檔解析,指標為編輯距離,越小越好)
| 模型/模式 | 視覺token數(有效token) | 整體編輯距離 | 關鍵對比結論 |
|---|---|---|---|
| GOT-OCR2.0 | 256 | - | DeepSeek-OCR(100token)超越它 |
| MinerU2.0 | 6000+(平均) | - | DeepSeek-OCR(<800token)超越它 |
| DeepSeek-OCR(Small) | 100 | 0.205 | - |
| DeepSeek-OCR(Base) | 256(182) | 0.156 | - |
| DeepSeek-OCR(Gundam) | 795 | 0.083 | 接近SOTA性能 |
實用價值
- 大規模訓練數據生成:單張A100-40G顯卡每日可生成20萬+頁LLM/VLM訓練數據;20節點(每節點8張A100-40G)每日可生成3300萬+頁。
- 多場景OCR能力:
- 語言支持:可處理近100種語言,小語種文檔支持布局/非布局輸出。
- 深度解析:支持圖表(轉HTML表格)、化學公式(轉SMILES)、平面幾何圖(結構化輸出)、自然圖像(密集描述)的深度解析。
- 通用視覺理解:保留圖像描述、目標檢測、接地等通用視覺能力,可通過提示激活。
總結和展望
- 總結:
- 為LLM長上下文壓縮提供新范式(光學壓縮,7-20×token reduction);
- 為LLM記憶遺忘機制研究提供思路(模擬人類記憶衰減,通過逐步縮小圖像分辨率實現多級別壓縮);
- 為VLMtoken分配優化提供實證指導。
- 未來方向:
- 開展數字-光學文本交錯預訓練;
- 進行“大海撈針”(needle-in-a-haystack)測試,驗證長上下文處理能力;
- 進一步優化光學上下文壓縮的精度與效率。

 浙公網安備 33010602011771號
浙公網安備 33010602011771號