
《MSSQL2008技術(shù)內(nèi)幕:T-SQL語言基礎》讀書筆記(上)
 Microsoft SQL Server 2008 T-SQL語言基礎是微軟數(shù)據(jù)庫技術(shù)內(nèi)幕系列的一本,全面深入的介紹了T-SQL的基本元素,以及SQL Server 2008中新增加的一些特性。主要包括SQL的基礎理論、邏輯查詢處理、SELECT查詢、連接和子查詢、表表達式、過濾和分組、透視轉(zhuǎn)換、修改數(shù)據(jù)、事物和一致性的處理、可編程對象等內(nèi)容。同時,它也是我的2016讀書計劃中的一本,因此我也將我學習過程中記錄的一些點匯總成此文,與各位園友分享,本篇為上篇,主要介紹查詢、表表達式以及集合運算。最后,我也向各位推薦這本書,值得各位.NET程序員看看。
Microsoft SQL Server 2008 T-SQL語言基礎是微軟數(shù)據(jù)庫技術(shù)內(nèi)幕系列的一本,全面深入的介紹了T-SQL的基本元素,以及SQL Server 2008中新增加的一些特性。主要包括SQL的基礎理論、邏輯查詢處理、SELECT查詢、連接和子查詢、表表達式、過濾和分組、透視轉(zhuǎn)換、修改數(shù)據(jù)、事物和一致性的處理、可編程對象等內(nèi)容。同時,它也是我的2016讀書計劃中的一本,因此我也將我學習過程中記錄的一些點匯總成此文,與各位園友分享,本篇為上篇,主要介紹查詢、表表達式以及集合運算。最后,我也向各位推薦這本書,值得各位.NET程序員看看。
索引:
二、查詢
三、表表達式
四、集合運算
八、可編程對象
一、SQL Server體系結(jié)構(gòu)
1.1 數(shù)據(jù)庫的物理布局
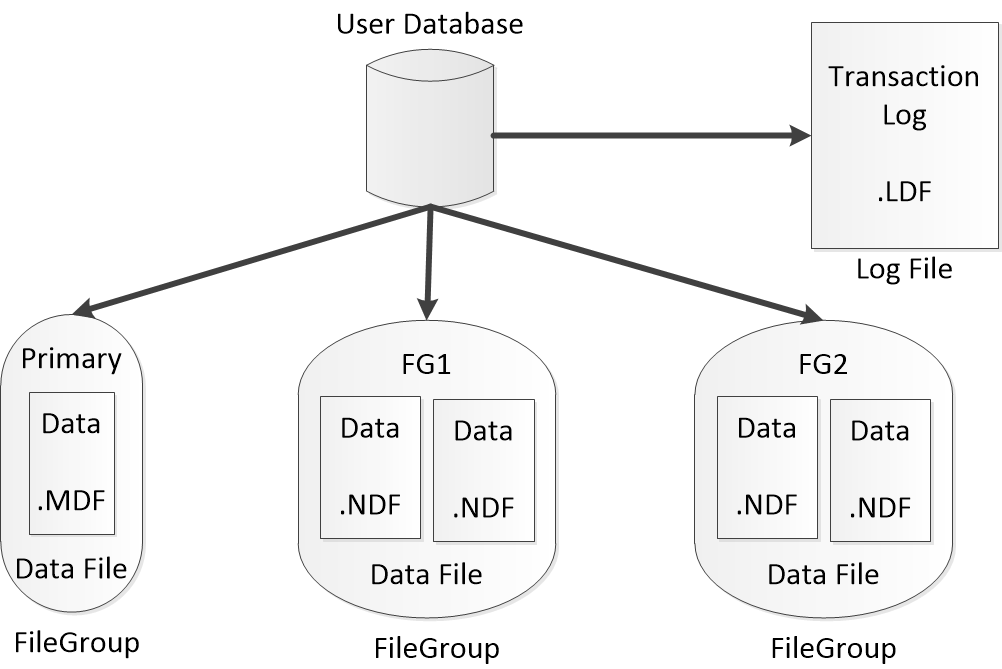
數(shù)據(jù)庫在物理上由數(shù)據(jù)文件和事務日志文件組成,每個數(shù)據(jù)庫必須至少有一個數(shù)據(jù)文件和一個日志文件。
(1)數(shù)據(jù)文件用于保存數(shù)據(jù)庫對象數(shù)據(jù)。數(shù)據(jù)庫必須至少有一個主文件組(Primary),而用戶定義的文件組則是可選的。Primary文件組包括 主數(shù)據(jù)文件(.mdf),以及數(shù)據(jù)庫的系統(tǒng)目錄(catalog)。可以選擇性地為Primary增加多個輔助數(shù)據(jù)文件(.ndf)。用戶定義的文件組只能包含輔助數(shù)據(jù)文件。
(2)日志文件則用于保存SQL Server為了維護事務而需要的信息。雖然SQL Server可以同時寫多個數(shù)據(jù)文件,但同一時刻只能以順序方式寫一個日志文件。
.mdf、.ldf和.ndf
.mdf代表Master Data File,.ldf代表Log Data File,而.ndf代表Not Master Data File(非主數(shù)據(jù)文件)
1.2 架構(gòu)(Schema)和對象
一個數(shù)據(jù)庫包含多個架構(gòu),而每個架構(gòu)又包括多個對象。可以將架構(gòu)看作是各種對象的容器,這些對象可以是表(table)、視圖(view)、存儲過程(stored procedure)等等。
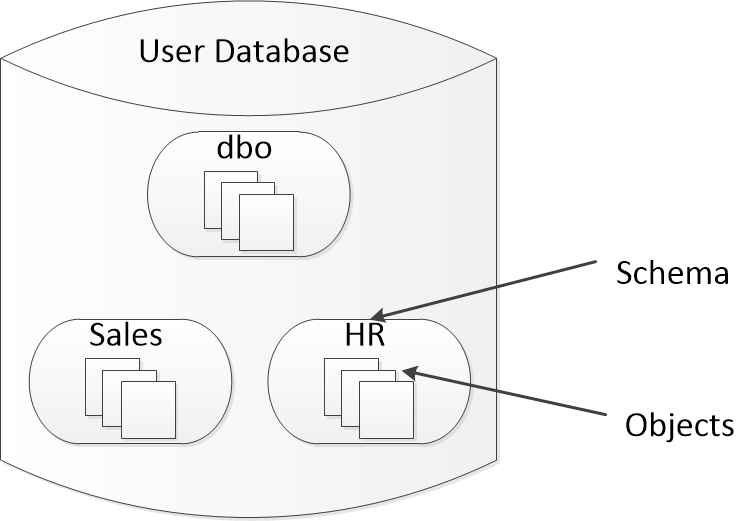
此外,架構(gòu)也是一個命名空間,用作對象名稱的前綴。例如,架設在架構(gòu)Sales中有一個Orders表,架構(gòu)限定的對象名稱是Sales.Orders。如果在引用對象時省略架構(gòu)名稱,SQL Server將采用一定的辦法來分析出架構(gòu)名稱是什么。如果不顯示指定架構(gòu),那么在解析對象名稱時,就會要付出一些沒有意義的額外代價。因此,建議都加上架構(gòu)名稱。
二、查詢
2.1 單表查詢
(1)關(guān)于SELECT子句:使用*號是糟糕的習慣
SELECT * FROM Sales.Shippers;
在絕大多數(shù)情況下,使用星號是一種糟糕的編程習慣,在此還是建議大家即使需要查詢表的所有列,也應該顯式地指定它們。
(2)關(guān)于FROM子句:顯示指定架構(gòu)名稱
通過顯示指定架構(gòu)名稱,可以保證得到的對象的確是你原來想要的,而且還不必付出任何額外的代價。
(3)關(guān)于TOP子句:T-SQL獨有關(guān)鍵字
① 可以使用PERCENT關(guān)鍵字按百分比計算滿足條件的行數(shù)
SELECT TOP (1) PERCENT orderid, orderdate, custid, empid FROM Sales.Orders ORDER BY orderdate DESC;
上面這條SQL就會請求最近更新過的前1%個訂單。
② 可以使用WITH TIES選項請求返回所有具有相同結(jié)果的行
SELECT TOP (5) WITH TIES orderid, orderdate, custid, empid FROM Sales.Orders ORDER BY orderdate DESC;
上面這條SQL請求返回與TOP n行中最后一行的排序值相同的其他所有行。
(4)關(guān)于OVER子句:為行定義一個窗口以便進行特定的運算
OVER子句的優(yōu)點在于能夠在返回基本列的同時,在同一行對它們進行聚合;也可以在表達式中混合使用基本列和聚合值列。
例如,下面的查詢?yōu)镺rderValues的每一行計算當前價格占總價格的百分比,以及當前價格占客戶總價格的百分比 。
SELECT orderid, custid, val, 100.0 * val / SUM(val) OVER() AS pctall, 100.0 * val / SUM(val) OVER(PARTITION BY custid) AS pctcust FROM Sales.OrderValues;
(5)子句的邏輯處理順序
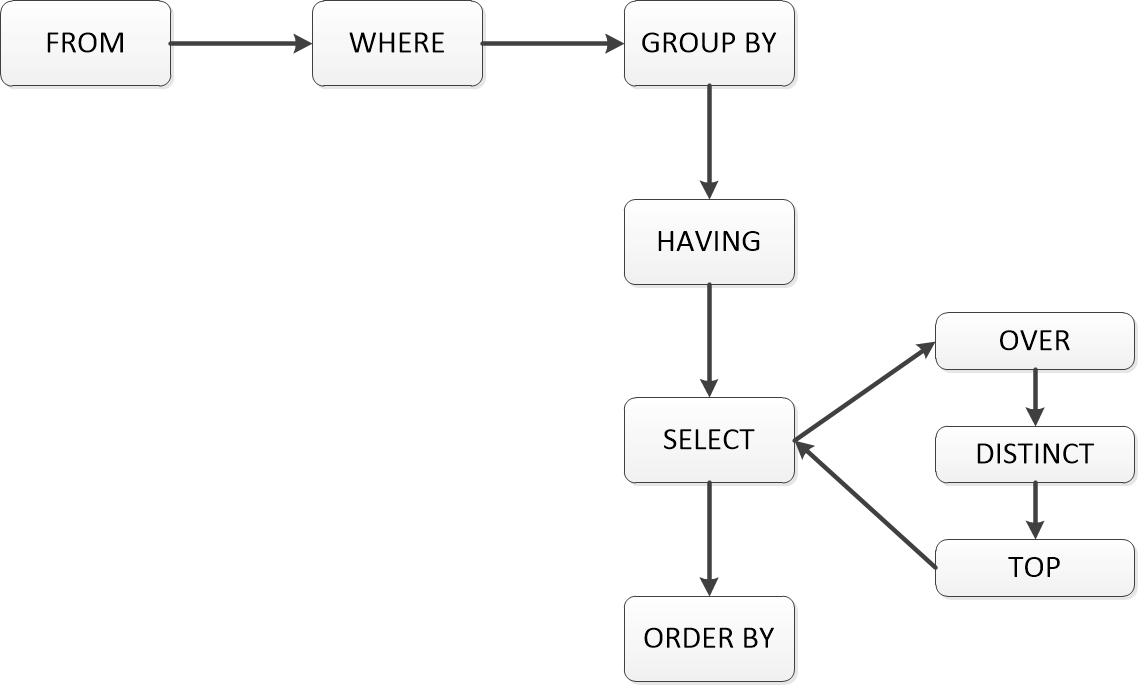
(6)運算符的優(yōu)先級
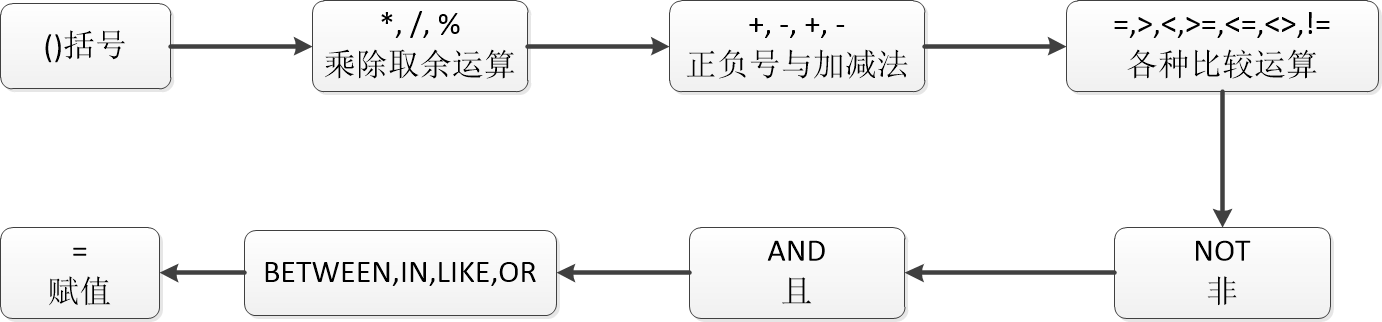
(7)CASE表達式
① 簡單表達式:將一個值與一組可能的取值進行比較,并返回滿足第一個匹配的結(jié)果;
SELECT productid,productname,categoryid,categoryname=( CASE categoryid WHEN 1 THEN 'Beverages' WHEN 2 THEN 'Condiments' WHEN 3 THEN 'Confections' WHEN 4 THEN 'Dairy Products' ELSE 'Unkonw Category' END) FROM Production.Products;
② 搜索表達式:將返回結(jié)果為TRUE的第一個WHEN邏輯表達式所關(guān)聯(lián)的THEN子句中指定的值。如果沒有任何WHEN表達式結(jié)果為TRUE,CASE表達式則返回ELSE子句中出現(xiàn)的值。(如果沒有指定ELSE,則默認返回NULL);
SELECT orderid, custid, val, valuecategory=( CASE WHEN val < 1000.00 THEN 'Less than 1000' WHEN val BETWEEN 1000.00 AND 3000.00 THEN 'Between 1000 and 3000' WHEN val > 3000.00 THEN 'More than 3000' ELSE 'Unknown' END ) FROM Sales.OrderValues
(8)三值謂詞邏輯:TRUE、FALSE與UNKNOWN
SQL支持使用NULL表示缺少的值,它使用的是三值謂詞邏輯,代表計算結(jié)果可以使TRUE、FALSE與UNKNOWN。在SQL中,對于UNKNOWN和NULL的處理不一致,這就需要我們在編寫每一條查詢語句時應該明確地注意到正在使用的是三值謂詞邏輯。
例如,我們要請求返回region列不等于WA的所有行,則需要在查詢過濾條件中顯式地增加一個隊NULL值得測試:
SELECT custid, country, region, city FROM Sales.Customers WHERE region <> N'WA' OR region IS NULL;
另外,T-SQL對于NULL值得處理是先輸出NULL值再輸出非NULL值得順序,如果想要先輸出非NULL值,則需要改變一下排序條件,例如下面的請求:
select custid, region from sales.Customers order by (case when region is null then 1 else 0 end), region;
當region列為NULL時返回1,否則返回0。非NULL值得表達式返回值為0,因此,它們會排在NULL值(表達式返回1)的前面。如上所示的將CASE表達式作為第一個拍序列,并把region列指定為第二個拍序列。這樣,非NULL值也可以正確地參與排序,是一個完整解決方案的查詢。
(9)LIKE謂詞的花式用法
① %(百分號)通配符
SELECT empid, lastname FROM HR.Employees WHERE lastname LIKE N'D%';
② _(下劃線)通配符:下劃線代表任意單個字符
下面請求返回lastname第二個字符為e的所有員工
SELECT empid, lastname FROM HR.Employees WHERE lastname LIKE N'_e%';
③ [<字符列>]通配符:必須匹配指定字符中的一個字符
下面請求返回lastname以字符A、B、C開頭的所有員工
SELECT empid, lastname FROM HR.Employees WHERE lastname LIKE N'[ABC]%';
④ [<字符-字符>]通配符:必須匹配指定范圍內(nèi)中的一個字符
下面請求返回lastname以字符A到E開頭的所有員工:
SELECT empid, lastname FROM HR.Employees WHERE lastname LIKE N'[A-E]%';
⑤ [^<字符-字符>]通配符:不屬于特定字符序列或范圍內(nèi)的任意單個字符
下面請求返回lastname不以A到E開頭的所有員工:
SELECT empid, lastname FROM HR.Employees WHERE lastname LIKE N'[^A-E]%';
⑥ ESCAPE轉(zhuǎn)義字符
如果搜索包含特殊通配符的字符串(例如'%','_','['、']'等),則必須使用轉(zhuǎn)移字符。下面檢查lastname列是否包含下劃線:
SELECT empid, lastname FROM HR.Employees WHERE lastname LIKE N'%!_%' ESCAPE '!';
(10)兩種轉(zhuǎn)換值的函數(shù):CAST和CONVERT
CAST和CONVERT都用于轉(zhuǎn)換值的數(shù)據(jù)類型。
SELECT CAST(SYSDATETIME() AS DATE); SELECT CONVERT(CHAR(8),CURRENT_TIMESTAMP,112);
需要注意的是,CAST是ANSI標準的SQL,而CONVERT不是。所以,除非需要使用樣式值,否則推薦優(yōu)先使用CAST函數(shù),以保證代碼盡可能與標準兼容。
2.2 聯(lián)接查詢
(1)交叉聯(lián)接:返回笛卡爾積,即m*n行的結(jié)果集
-- CROSS JOIN select c.custid, e.empid from sales.Customers as c cross join HR.Employees as e; -- INNER CROSS JOIN select e1.empid,e1.firstname,e1.lastname, e2.empid,e2.firstname,e2.lastname from hr.Employees as e1 cross join hr.Employees as e2;
(2)內(nèi)聯(lián)接:先笛卡爾積,然后根據(jù)指定的謂詞對結(jié)果進行過濾
select e.empid,e.firstname,e.lastname,o.orderid from hr.Employees as e join sales.Orders as o on e.empid=o.empid;
雖然不使用JOIN這種ANSI SQL-92標準語法也可以實現(xiàn)聯(lián)接,但強烈推薦使用ANSI SQL-92標準,因為它用起來更加安全。比如,假如你要寫一條內(nèi)聯(lián)接查詢,如果不小心忘記了指定聯(lián)接條件,如果這時候用的是ANSI SQL-92語法,那么語法分析器將會報錯。

(3)外聯(lián)結(jié):笛卡爾積→對結(jié)果過濾→添加外部行
通過例子來理解外聯(lián)結(jié):根據(jù)客戶的客戶ID和訂單的客戶ID來對Customers表和Orders表進行聯(lián)接,并返回客戶和他們的訂單信息。該查詢語句使用的聯(lián)接類型是左外連接,所以查詢結(jié)果也包括那些沒有發(fā)出任何訂單的客戶;
--LEFT OUTER JOIN select c.custid,c.companyname,o.orderid from sales.Customers as c left outer join sales.Orders as o on c.custid=o.custid;
另外,需要注意的是在對外聯(lián)結(jié)中非保留值得列值進行過濾時,不要再WHERE子句中指定錯誤的查詢條件。
例如,下面請求返回在2007年2月12日下過訂單的客戶,以及他們的訂單。同時也返回在2007年2月12日沒有下過訂單的客戶。這是一個典型的左外連接的案例,但是我們經(jīng)常會犯這樣的錯誤:
select c.custid,c.companyname,o.orderid,o.orderdate from sales.Customers as c left outer join sales.Orders as o on c.custid=o.custid where o.orderdate='20070212';
執(zhí)行結(jié)果如下:
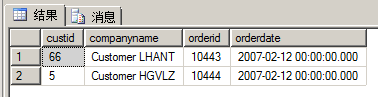
這是因為對于所有的外部行,因為它們在o.orderdate列上的取值都為NULL,所以WHERE子句中條件o.orderdate='20070212'的計算結(jié)果為UNKNOWN,因此WHERE子句會過濾掉所有的外部行。
我們應該將這個條件搬到on后邊:
select c.custid,c.companyname,o.orderid,o.orderdate from sales.Customers as c left outer join sales.Orders as o on c.custid=o.custid and o.orderdate='20070212';
這下的執(zhí)行結(jié)果如下:
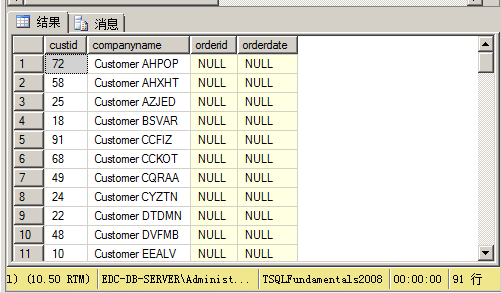
2.3 子查詢
(1)獨立子查詢:不依賴于它所屬的外部查詢
例如下面要查詢Orders表中訂單ID最大的訂單信息,這種叫做獨立標量子查詢,即返回值不能超過一個。
select orderid, orderdate, empid, custid from sales.Orders where empid=(select MAX(o.orderid) from sales.Orders as o);
西面請求查詢返回姓氏以字符D開頭的員工處理過的訂單的ID,這種叫做獨立多值子查詢,即返回值可能有多個。
select orderid from sales.Orders where empid in (select e.empid from hr.Employees as e where e.lastname like N'D%');
(2)相關(guān)子查詢:必須依賴于它所屬的外部查詢,不能獨立地調(diào)用它
例如下面的查詢會返回每個客戶的訂單記錄中訂單ID最大的記錄:
select custid, orderid, orderdate, empid from sales.Orders as o1 where orderid=(select MAX(o2.orderid) from sales.Orders as o2 where o2.custid=o1.custid);
簡單地說,對于o1表中的每一行,子查詢負責返回當前客戶的最大訂單ID。如果o1表中某行的訂單ID和子查詢返回的訂單ID匹配,那么o1中的這個訂單ID就是當前客戶的最大訂單ID,在這種情況下,查詢便會返回o1表中的這個行。
(3)EXISTS謂詞:它的輸入是一個查詢,如果子查詢能夠返回任何行,則返回True,否則返回False
例如下面的查詢會返回下過訂單的西班牙客戶:
select custid, companyname from sales.customers as c where c.country=N'Spain' and exists ( select * from sales.Orders as o where o.custid=c.custid);
同樣,要查詢沒有下過訂單的西班牙客戶只需要加上NOT即可:
select custid, companyname from sales.customers as c where c.country=N'Spain' and not exists ( select * from sales.Orders as o where o.custid=c.custid);
對于EXISTS,它采用的是二值邏輯(TRUE和FALSE),它只關(guān)心是否存在匹配行,而不考慮SELECT列表中指定的列,并且無須處理所有滿足條件的行。可以將這種處理方式看做是一種“短路”,它能夠提高處理效率。
另外,由于EXISTS采用的是二值邏輯,因此相較于IN要更加安全,可以避免對NULL值得處理。
(4)高級子查詢
① 如何表示前一個或后一個記錄?邏輯等式:上一個->小于當前值的最大值;下一個->大于當前值的最小值;
-- 上一個訂單ID select orderid, orderdate, empid, custid, ( select MAX(o2.orderid) from sales.Orders as o2 where o2.orderid<o1.orderid ) as prevorderid from sales.Orders as o1;
② 如何實現(xiàn)連續(xù)聚合函數(shù)?在子查詢中連續(xù)計算
-- 連續(xù)聚合 select orderyear, qty, (select SUM(o2.qty) from sales.OrderTotalsByYear as o2 where o2.orderyear<=o1.orderyear) as runqty from sales.OrderTotalsByYear as o1 order by orderyear;
執(zhí)行結(jié)果如下圖所示:
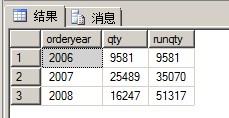
③ 使用NOT EXISTS謂詞取代NOT IN隱式排除NULL值:當對至少返回一個NULL值的子查詢使用NOT IN謂詞時,外部查詢總會返回一個空集。(前面提到,EXISTS謂詞采用的是二詞邏輯而不是三詞邏輯)
-- 隱式排除NULL值 select custid,companyname from sales.Customers as c where not exists (select * from sales.Orders as o where o.custid=c.custid);
又如以下查詢請求返回每個客戶在2007年下過訂單而在2008年沒有下過訂單的客戶:
select custid, companyname from sales.Customers as c where exists (select * from sales.Orders as o1 where c.custid=o1.custid and o1.orderdate>='20070101' and o1.orderdate<'20080101') and not exists (select * from sales.Orders as o2 where c.custid=o2.custid and o2.orderdate>='20080101' and o2.orderdate<'20090101');
三、表表達式
表表達式是一種命名的查詢表達式,代表一個有效地關(guān)系表。可以像其他表一樣,在數(shù)據(jù)處理中使用表表達式。MSSQL中支持4種類型的表表達式:
3.1 派生表
派生表(也稱為表子查詢)是在外部查詢的FROM子句中定義的,只要外部查詢一結(jié)束,派生表也就不存在了。
例如下面代碼定義了一個名為USACusts的派生表,它是一個返回所有美國客戶的查詢。外部查詢則選擇了派生表的所有行。
select * from (select custid, companyname from sales.Customers where country='USA') as USACusts;
3.2 公用表表達式
公用表達式(簡稱CTE,Common Table Expression)是和派生表很相似的另一種形式的表表達式,是ANSI SQL(1999及以后版本)標準的一部分。
舉個栗子,下面的代碼定義了一個名為USACusts的CTE,它的內(nèi)部查詢返回所有來自美國的客戶,外部查詢則選擇了CTE中的所有行:
WITH USACusts AS ( select custid, companyname from sales.Customers where country=N'USA' ) select * from USACusts;
和派生表一樣,一旦外部查詢完成,CTE的生命周期也就結(jié)束了。
3.3 視圖
派生表和CTE都是不可重用的,而視圖和內(nèi)聯(lián)表值函數(shù)卻是可重用,它們的定義存儲在一個數(shù)據(jù)庫對象中,一旦創(chuàng)建,這些對象就是數(shù)據(jù)庫的永久部分。只有用刪除語句顯式地刪除,它們才會從數(shù)據(jù)庫中移除。
下面仍然繼續(xù)上面的例子,創(chuàng)建一個視圖:
IF OBJECT_ID('Sales.USACusts') IS NOT NULL DROP VIEW Sales.USACusts; GO CREATE VIEW Sales.USACusts AS SELECT custid, companyname, contactname, contacttitle, address, city, region, postalcode, country, phone, fax FROM Sales.Customers WHERE country=N'USA'; GO
使用該視圖:
SELECT * FROM Sales.USACusts;
執(zhí)行結(jié)果如下:

3.4 內(nèi)聯(lián)表值函數(shù)
內(nèi)聯(lián)表值函數(shù)能夠支持輸入?yún)?shù),其他方面就與視圖類似了。
下面演示如何創(chuàng)建函數(shù):
IF OBJECT_ID('dbo.fn_GetCustOrders') IS NOT NULL DROP FUNCTION dbo.fn_GetCustOrders; GO CREATE FUNCTION dbo.fn_GetCustOrders (@cid AS INT) RETURNS TABLE AS RETURN SELECT orderid, custid, empid, orderdate, requireddate, shippeddate, shipperid, freight, shipname, shipaddress, shipcity, shipregion, shippostalcode, shipcountry FROM Sales.Orders WHERE custid=@cid; GO
如何使用函數(shù):
SELECT orderid, custid FROM dbo.fn_GetCustOrders(1) AS CO;
執(zhí)行結(jié)果如下:
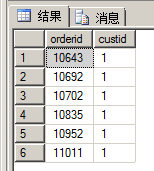
總結(jié):
借助表表達式可以簡化代碼,提高代碼地可維護性,還可以封裝查詢邏輯。
當需要使用表表達式,而且不計劃重用它們的定義時,可以使用派生表或CTE,與派生表相比,CTE更加模塊化,更容易維護。
當需要定義可重用的表表達式時,可以使用視圖或內(nèi)聯(lián)表值函數(shù)。如果不需要支持輸入,則使用視圖;反之,則使用內(nèi)聯(lián)表值函數(shù)。
四、集合運算
4.1 UNION 并集運算
在T-SQL中。UNION集合運算可以將兩個輸入查詢的結(jié)果組合成一個結(jié)果集。需要注意的是:如果一個行在任何一個輸入集合眾出現(xiàn),它也會在UNION運算的結(jié)果中出現(xiàn)。T-SQL支持以下兩種選項:
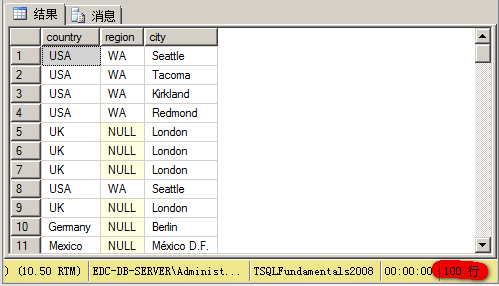
(1)UNION ALL:不會刪除重復行
-- union all select country, region, city from hr.Employees union all select country, region, city from sales.Customers;
結(jié)果得到100行:
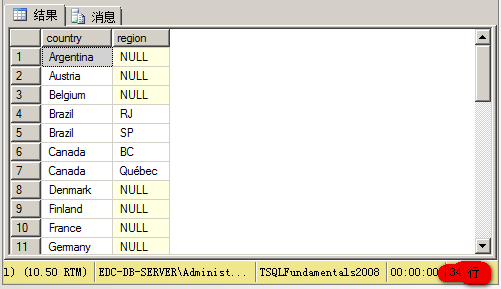
(2)UNION:會刪除重復行
-- union select country, region from hr.Employees union select country, region from sales.Customers;
結(jié)果得到34行:
4.2 INTERSECT 交集運算
在T-SQL中,INTERSECT集合運算對兩個輸入查詢的結(jié)果取其交集,只返回在兩個查詢結(jié)果集中都出現(xiàn)的行。
INTERSECT集合運算在邏輯上會首先刪除兩個輸入集中的重復行,然后返回只在兩個集合中中都出現(xiàn)的行。換句話說:如果一個行在兩個輸入集中都至少出現(xiàn)一次,那么交集返回的結(jié)果中將包含這一行。
例如,下面返回既是官員地址,又是客戶地址的不同地址:
-- intersect select country, region, city from hr.Employees intersect select country, region, city from sales.Customers;
執(zhí)行結(jié)果如下圖所示:
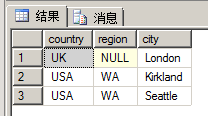
這里需要說的是,集合運算對行進行比較時,認為兩個NULL值相等,所以就返回該行記錄。
4.3 EXCEPT 差集運算
在T-SQL中,集合之差使用EXCEPT集合運算實現(xiàn)的。它對兩個輸入查詢的結(jié)果集進行操作,反會出現(xiàn)在第一個結(jié)果集中,但不出現(xiàn)在第二個結(jié)果集中的所有行。
EXCEPT結(jié)合運算在邏輯上首先刪除兩個輸入集中的重復行,然后返回只在第一個集合中出現(xiàn),在第二個結(jié)果集中不出現(xiàn)的所有行。換句話說:一個行能夠被返回,僅當這個行在第一個輸入的集合中至少出現(xiàn)過一次,而且在第二個集合中一次也沒出現(xiàn)過。
此外,相比UNION和INTERSECT,兩個輸入集合的順序是會影響到最后返回結(jié)果的。
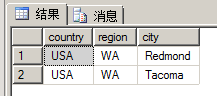
例如,借助EXCEPT運算,我們可以方便地實現(xiàn)屬于A但不屬于B的場景,下面返回屬于員工抵制,但不屬于客戶地址的地址記錄:
-- except select country, region, city from hr.Employees except select country, region, city from sales.Customers;
執(zhí)行結(jié)果如下圖所示:
4.4 集合運算優(yōu)先級
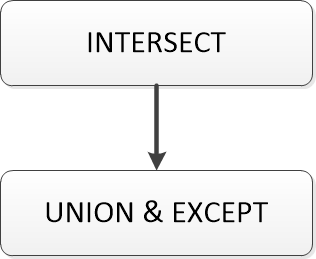
SQL定義了集合運算之間的優(yōu)先級:INTERSECT最高,UNION和EXCEPT相等。
換句話說:首先會計算INTERSECT,然后按照從左至右的出現(xiàn)順序依次處理優(yōu)先級相同的運算。
-- 集合運算的優(yōu)先級 select country, region, city from Production.Suppliers except select country, region, city from hr.Employees intersect select country, region, city from sales.Customers;
上面這段SQL代碼,因為INTERSECT優(yōu)先級比EXCEPT高,所以首先進行INTERSECT交集運算。因此,這個查詢的含義是:返回沒有出現(xiàn)在員工地址和客戶地址交集中的供應商地址。
4.5 使用表表達式避開不支持的邏輯查詢處理
集合運算查詢本身并不持之除ORDER BY意外的其他邏輯查詢處理階段,但可以通過表表達式來避開這一限制。
解決方案就是:首先根據(jù)包含集合運算的查詢定義一個表表達式,然后在外部查詢中對表表達式應用任何需要的邏輯查詢處理。
(1)例如,下面的查詢返回每個國家中不同的員工地址或客戶地址的數(shù)量:
select country, COUNT(*) as numlocations from (select country, region, city from hr.Employees union select country, region, city from sales.Customers) as U group by country;
(2)例如,下面的查詢返回由員工地址為3或5的員工最近處理過的兩個訂單:
select empid,orderid,orderdate from (select top (2) empid,orderid,orderdate from sales.Orders where empid=3 order by orderdate desc,orderid desc) as D1 union all select empid,orderid,orderdate from (select top (2) empid,orderid,orderdate from sales.Orders where empid=5 order by orderdate desc,orderid desc) as D2;
參考資料

[美] Itzik Ben-Gan 著,成保棟 譯,《Microsoft SQL Server 2008技術(shù)內(nèi)幕:T-SQL語言基礎》
考慮到很多人買了這本書,卻下載不了這本書的配套源代碼和示例數(shù)據(jù)庫,特意上傳到了百度云盤中,點此下載
強烈建議大家閱讀完每一章節(jié)后,練習一下課后習題,相信或多或少都會有一些收獲。
作者:周旭龍
出處:http://www.rzrgm.cn/edisonchou/
本文版權(quán)歸作者和博客園共有,歡迎轉(zhuǎn)載,但未經(jīng)作者同意必須保留此段聲明,且在文章頁面明顯位置給出原文鏈接。


 浙公網(wǎng)安備 33010602011771號
浙公網(wǎng)安備 33010602011771號