AI與.NET技術實操系列(五):向量存儲與相似性搜索在 .NET 中的實現
引言
在當今這個數據爆炸的時代,信息的快速存儲與高效檢索已經成為技術領域的核心挑戰。隨著人工智能(AI)和機器學習(ML)的迅猛發展,向量存儲和相似性搜索技術逐漸嶄露頭角,成為處理海量數據的利器。對于使用 .NET 的開發者來說,掌握這些技術不僅意味著能夠開發出更智能、更高效的應用,更是在信息洪流中保持競爭力的關鍵。借助向量存儲,我們可以將復雜的數據(如文本、圖像或音頻)轉化為高維向量,通過相似性搜索快速找到與查詢最相關的內容,從而大幅提升信息檢索的精度和效率。
向量存儲和相似性搜索的應用潛力令人振奮。從智能推薦系統到圖像檢索工具,再到自然語言處理(NLP)中的語義搜索,這些技術正在重塑我們與數據的交互方式。通過在向量空間中使用距離度量(如余弦相似度或歐氏距離),開發者可以實現高效的匹配機制,為用戶提供個性化的體驗。然而,技術的實現并非一帆風順,高維數據的存儲、計算資源的優化、索引結構的構建以及實時性能的保障,都是開發者需要面對的難題。
本文將通過一個具體的實踐任務——實現一個簡單的文檔相似性搜索系統,深入探討如何在 .NET 中應用向量存儲和相似性搜索技術。我們將從基礎知識入手,逐步介紹向量存儲的選擇與使用,并通過清晰的代碼示例,引導讀者完成一個功能完備的搜索應用。
希望本文能為你打開向量存儲的大門,激發你在 .NET 開發中探索智能技術的熱情。
向量存儲和相似性搜索基礎知識
在進入實踐之前,我們先來梳理向量存儲和相似性搜索的基本概念及其工作原理。
什么是向量存儲?
向量存儲(Vector Store)是一種專門設計用于存儲和檢索高維向量的數據庫系統。在 AI 和 ML 領域,數據通常被轉化為高維向量(稱為 embeddings),以捕捉其語義或特征信息。例如,一段文本可以通過預訓練模型(如 BERT)轉換為一個 384 維的向量,圖像可以通過卷積神經網絡提取特征向量。向量存儲通過優化這些高維數據的存儲結構和查詢機制,支持快速的相似性搜索,幫助開發者高效地找到與查詢最相關的內容。
什么是相似性搜索?
相似性搜索(Similarity Search)是一種旨在找到與查詢項最相似的項的搜索技術。在向量空間中,相似性通常通過距離度量來衡量,常見的度量方法包括:
-
余弦相似度:計算兩個向量夾角的余弦值,反映方向的相似性,廣泛用于文本搜索。 -
歐氏距離:計算兩個向量間的直線距離,常用于圖像和數值數據的匹配。 -
曼哈頓距離:計算向量在各維度上的差值之和,適用于特定場景。
通過這些度量,相似性搜索能夠在海量數據中快速定位與查詢最接近的結果,極大地提升了搜索效率。
向量存儲的工作原理
向量存儲依賴以下核心技術來實現高效的存儲和查詢:
-
索引結構:如 KD-Tree、HNSW(層次可導航小世界圖),用于加速相似性搜索。 -
近似最近鄰(ANN):通過犧牲少量精度換取更高的搜索速度,適用于大規模數據集。 -
分布式架構:支持數據的并行處理和存儲,滿足高并發需求。
這些技術的結合使得向量存儲能夠應對高維數據的挑戰,為實時應用提供強大支持。
選擇和使用向量存儲
在 .NET 中實現向量存儲和相似性搜索,開發者可以選擇多種工具和服務。以下是幾個常見選項:
Milvus
Milvus 是一個開源的向量數據庫,專為高維向量存儲和搜索設計。它支持多種索引類型(如 HNSW、IVF)和距離度量,提供高性能的搜索能力。Milvus 可通過 RESTful API 或客戶端 SDK 與 .NET 集成。
qDrant
qDrant 是一個輕量級向量數據庫,適合中小規模應用。它支持實時數據插入和搜索,提供簡單易用的 API,方便快速上手。
Azure AI Search
Azure AI Search 是微軟提供的云端搜索服務,支持向量搜索和全文搜索。它與 Azure 生態無縫集成,適合企業級應用。
本文將以 Milvus 為例,展示如何在 .NET 中實現向量存儲和搜索。Milvus 以其高性能和靈活性,成為許多 AI 項目的首選。
實現文檔相似性搜索系統
為了幫助讀者深入理解向量存儲的實際應用,我們將實現一個簡單的文檔相似性搜索系統。該系統能夠將文檔轉換為向量,存儲到 Milvus 中,并支持用戶查詢相似文檔。
系統設計
系統的核心組件包括:
-
文檔向量化:使用預訓練模型將文本轉換為向量。 -
向量存儲:將向量存儲到 Milvus 并構建索引。 -
相似性搜索:根據用戶查詢生成向量并搜索相似結果。 -
結果展示:返回最相似的文檔。
我們將使用 SentenceTransformers 生成向量,并通過 Milvus 實現存儲和搜索。
準備工作
在開始之前,需要完成以下準備:
-
創建Milvus-Test文件夾,并新建如下文件夾:
-
下載milvus-standalone-docker-compose.yml,重命名成docker-compose.yml后移入到剛剛創建好的Milvus-Test文件夾中
-
安裝 Milvus:使用 Docker 部署 Milvus(
docker compose up -d)
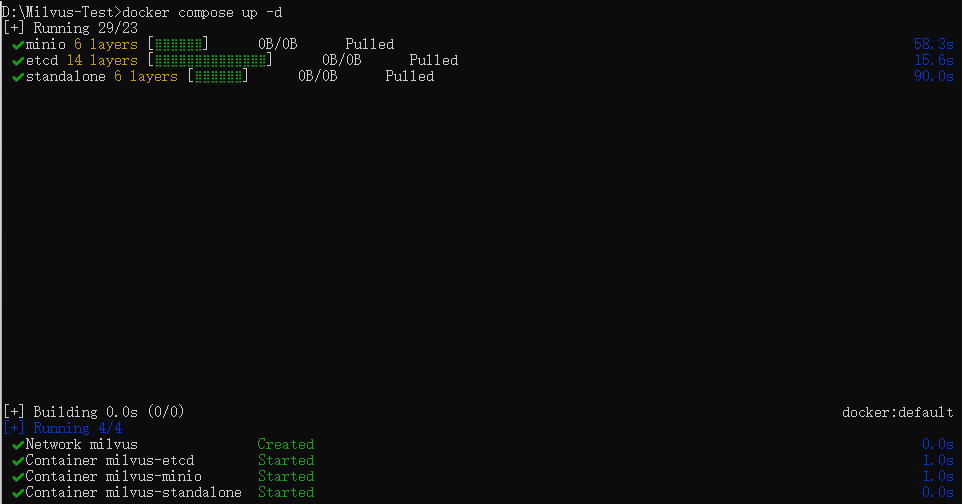

實現步驟
1. 文檔向量化
首先,使用 SentenceTransformers 將文檔轉換為向量(需 Python 環境):
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('all-MiniLM-L6-v2')
documents = ["This is document one.", "This is document two.", "This is document three."]
embeddings = model.encode(documents)embeddings 是包含每個文檔向量的數組(維度為 384)。
2. 存儲向量到 Milvus
安裝Nuget包:
dotnet add package Milvus.Client --version 2.3.0-preview.1使用 C# 檢測 Milvus 是否正常運行的代碼:
MilvusClient milvusClient = new MilvusClient("{Endpoint}", "{Port}", "{Username}", "{Password}", "{Database}(Optional)");
MilvusHealthState result = await milvusClient.HealthAsync();
使用 C# 調用 Milvus 創建集合代碼:
string collectionName = "book";
MilvusCollection collection = milvusClient.GetCollection(collectionName);
//Check if this collection exists
var hasCollection = await milvusClient.HasCollectionAsync(collectionName);
if(hasCollection){
await collection.DropAsync();
Console.WriteLine("Drop collection {0}",collectionName);
}
await milvusClient.CreateCollectionAsync(
collectionName,
new[] {
FieldSchema.Create<long>("book_id", isPrimaryKey:true),
FieldSchema.Create<long>("word_count"),
FieldSchema.CreateVarchar("book_name", 256),
FieldSchema.CreateFloatVector("book_intro", 2L)
}
);使用 C# 調用 Milvus 插入向量代碼:
Random ran = new ();
List<long> bookIds = new ();
List<long> wordCounts = new ();
List<ReadOnlyMemory<float>> bookIntros = new ();
List<string> bookNames = new ();
for (long i = 0L; i < 2000; ++i)
{
bookIds.Add(i);
wordCounts.Add(i + 10000);
bookNames.Add($"Book Name {i}");
float[] vector = new float[2];
for (int k = 0; k < 2; ++k)
{
vector[k] = ran.Next();
}
bookIntros.Add(vector);
}
MilvusCollection collection = milvusClient.GetCollection(collectionName);
MutationResult result = await collection.InsertAsync(
new FieldData[]
{
FieldData.Create("book_id", bookIds),
FieldData.Create("word_count", wordCounts),
FieldData.Create("book_name", bookNames),
FieldData.CreateFloatVector("book_intro", bookIntros),
});
// Check result
Console.WriteLine("Insert count:{0},", result.InsertCount);
3. 構建索引
為加速搜索,需在集合上構建索引:
MilvusCollection collection = milvusClient.GetCollection(collectionName);
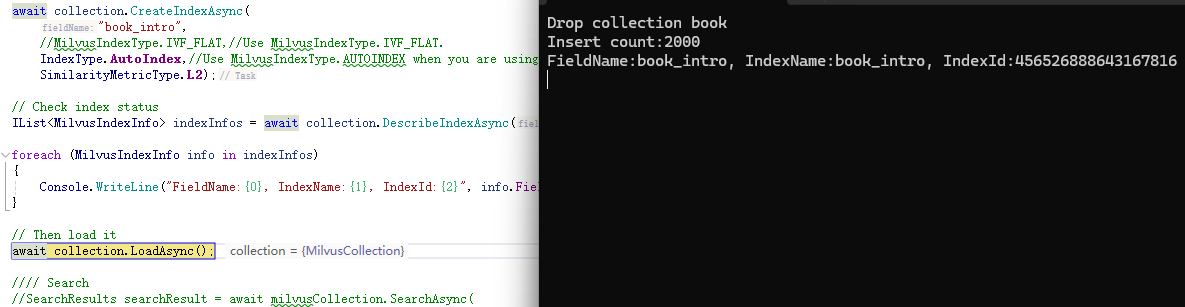
await collection.CreateIndexAsync(
"book_intro",
//MilvusIndexType.IVF_FLAT,//Use MilvusIndexType.IVF_FLAT.
IndexType.AutoIndex,//Use MilvusIndexType.AUTOINDEX when you are using zilliz cloud.
SimilarityMetricType.L2);
// Check index status
IList<MilvusIndexInfo> indexInfos = await collection.DescribeIndexAsync("book_intro");
foreach(var info in indexInfos){
Console.WriteLine("FieldName:{0}, IndexName:{1}, IndexId:{2}", info.FieldName , info.IndexName,info.IndexId);
}
// Then load it
await collection.LoadAsync();
}
4. 實現相似性搜索
根據用戶查詢搜索相似文檔:
List<string> search_output_fields = new() { "book_id" };
List<List<float>> search_vectors = new() { new() { 0.1f, 0.2f } };
SearchResults searchResult = await collection.SearchAsync(
"book_intro",
new ReadOnlyMemory<float>[] { new[] { 0.1f, 0.2f } },
SimilarityMetricType.L2,
limit: 2);
// Query
string expr = "book_id in [2,4,6,8]";
QueryParameters queryParameters = new ();
queryParameters.OutputFields.Add("book_id");
queryParameters.OutputFields.Add("word_count");
IReadOnlyList<FieldData> queryResult = await collection.QueryAsync(
expr,
queryParameters);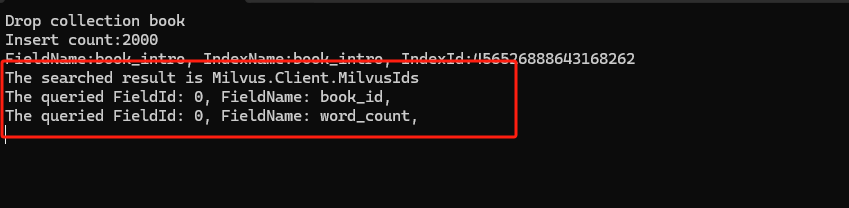
5. 集成到應用
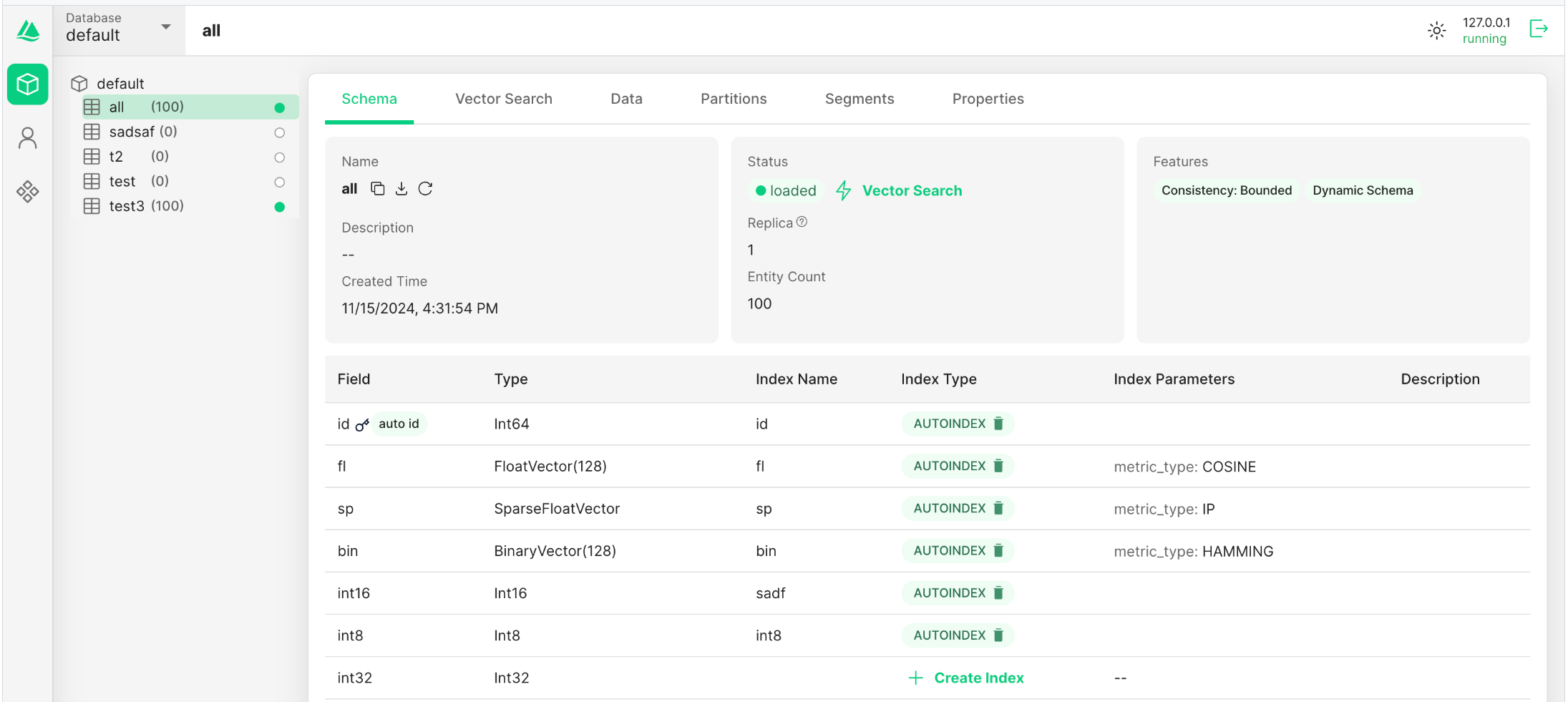
?后面要做的事情就很多了,大家可以自行發揮,當然有興趣的朋友還可以安裝attu ui界面作為 Milvus的客戶端,小編并沒有安裝,因此我截取官方圖片讓大家看一下,地址為:https://github.com/zilliztech/attu/releases。
實際應用中的意義與挑戰
意義
-
提升用戶體驗:語義搜索提供更精準的結果。 -
多模態支持:可擴展到圖像、音頻等領域。 -
效率優化:加速信息檢索和決策。
挑戰
-
資源需求:高維數據需要大量計算和存儲資源。 -
索引優化:需平衡速度與精度。 -
實時性:高并發場景下的性能保障。
結語
本文通過理論與實踐結合,展示了在 .NET 中實現向量存儲和相似性搜索的方法。希望你能從中獲得啟發,在智能應用的浪潮中找到自己的位置。向量存儲的潛力無限,讓我們共同探索這一領域,在技術的海洋里盡情馳騁!
參考鏈接:
-
https://www.nuget.org/packages/Milvus.Client/ -
https://github.com/zilliztech/attu/blob/main/.github/images/collection_overview.png
本文來自博客園,作者:AI·NET極客圈,轉載請注明原文鏈接:http://www.rzrgm.cn/code-daily/p/18761132

歡迎關注我們的公眾號,作為.NET工程師,我們聚焦人工智能技術,探討 AI 的前沿應用與發展趨勢,為你立體呈現人工智能的無限可能,讓我們共同攜手共同進步。

 浙公網安備 33010602011771號
浙公網安備 33010602011771號